 自動駕駛中常提的離線強化學習是什么?
自動駕駛中常提的離線強化學習是什么?

[首發于智駕最前沿微信公眾號]在之前談及自動駕駛模型學習時,詳細聊過強化學習的作用,由于強化學習能讓大模型通過交互學到策略,不需要固定的規則,從而給自動駕駛的落地創造了更多可能。

強化學習示意圖,圖片源自:網絡
但強化學習本身是需要不斷試錯的,如果采用這種學習方式在真實道路中不斷嘗試,一定會導致不可控的事故。于是就有人提出一種猜測,能不能利用已經存在的大量行駛日志、仿真記錄和人類駕駛數據,在訓練過程中完全不與真實環境交互,從而訓練出一個靠譜的決策模塊?
離線強化學習就是基于此提出的方案。離線強化學習先收集一大堆過去的經驗(含狀態、動作、后果/獎勵等),然后把這些經驗當成教材,讓模型在離線狀態下學習策略,而不是去真實交通場景中試錯。這樣做的好處是安全、低成本、能重復利用現有數據;但也帶來了不少問題,我們后面會詳細說。

離線強化學習的技術挑戰
離線強化學習在訓練階段只能訪問一個固定的數據集,這個數據集是由若干次交互生成的記錄集合;訓練算法不能再向環境發出動作來采集新的樣本。這個改變會帶來分布覆蓋問題、估值偏差問題以及評估難題。
離線強化學習訓練大模型時,提供的歷史數據來源于某些已有的行為策略或人為駕駛習慣,數據中可能壓根沒有某些狀態-動作對。如果訓練出的策略在部署時選擇了數據中極少或根本沒有覆蓋的動作,算法對這些動作的價值估計將會非常不可靠。
在離線數據里,有些動作要么出現得很少,要么干脆沒出現過。按理說,模型對這些動作應該非常謹慎才對。但強化學習算法在估計動作價值(Q值)時,會因為缺少真實數據支撐,反而會把這些動作估得特別好。導致的結果就是,模型會覺得這個操作收益很高,然后在學策略時越來越偏向這些現實中并不安全、甚至根本不可行的行為。
除此之外,離線強化學習在訓練時無法在真實交通環境中驗證策略,只能依賴離線的估計方法或仿真,這使得對學習到的策略的可靠性驗證變得更復雜。為了解決分布偏差和估值問題,離線強化學習算法還必須加入保守項、不確定性估計、行為約束等,這些都會增加實現難度與調參成本。

離線強化學習的主流思路
現階段,離線強化學習使用較多的實現方式就是行為克隆,即把問題轉成監督學習,直接用歷史狀態去預測歷史動作,學會“模仿人類駕駛”。行為克隆實現簡單、訓練穩定,但它的上限被數據中人類駕駛的質量限制,且無法處理數據中沒有覆蓋到的新場景。
為了解決行為克隆存在的問題,出現了以價值估計為核心、但帶有保守性約束的離線強化學習算法,主要有“行為約束”及“保守估值”兩種策略。行為約束也就是在優化策略時,直接限制新策略不能偏離已有數據太遠;保守估值策略是在估計行動價值時,對數據中不存在的行動進行刻意懲罰。這些做法都是為了壓低不切實際的樂觀估計,讓學習過程更可靠。
還有一種思路是先學習一個環境動力學模型,然后在模型中進行規劃或策略優化,這一思路的關鍵在于如何讓模型在不確定或預測不可靠的區域加入懲罰或不信任度折扣,避免因模型錯誤導致的危險動作。
此外,還有一些如ensemble(集成)不確定性估計、用置信區間控制決策、或把離線學習作為預訓練基座,然后在受控的仿真或沙箱里做有限的在線微調的方法用于實現模型學習。
在實際應用中,這些方法常會被組合使用,行為克隆可作為穩定的初始策略;保守Q學習或批量約束方法能進一步提升策略性能;而基于模型的規劃與不確定性估計則充當風險控制的補充。需要強調的是,無論采用何種方法,數據的多樣性與質量始終是決定成效的根本,如果缺乏對某些場景的覆蓋,任何算法都難以實現安全可靠的泛化。

自動駕駛如何用好離線強化學習?
自動駕駛如何用好離線強化學習?首先要做的是要規劃好數據收集體系。除了日常駕駛日志,還要主動合成和收集如夜間、逆光、大雨、大霧、臨時施工場景、行人異常行為等邊緣情況的樣本。仿真在這里的作用非常重要,它可以彌補現實場景中稀缺的數據,但必須和真實數據結合。
接著就是要做好分階段訓練流程,在大模型學習的整個鏈路中,可以把離線強化學習當作預訓練的手段,可以先在大規模歷史數據上訓練出一個“穩健基線”;然后在高保真仿真里對該策略做更多場景覆蓋測試;最后就是進行受控上線(比如先在特定區域、低速、有人監控的條件下運行),在實際運行中以“shadowmode(影子模式)”不斷記錄策略決策與真實駕駛者行為的差異,收集新數據用于后續離線微調。
在進行大模型部署時,一定要有強制的安全層和退回機制。不管策略多完善,都要有獨立的安全監控,當感知或決策模塊檢測到高不確定性、模型越界或可能造成人員傷害的風險時,系統應降級到更保守的控制邏輯,或者直接交由人為接管。
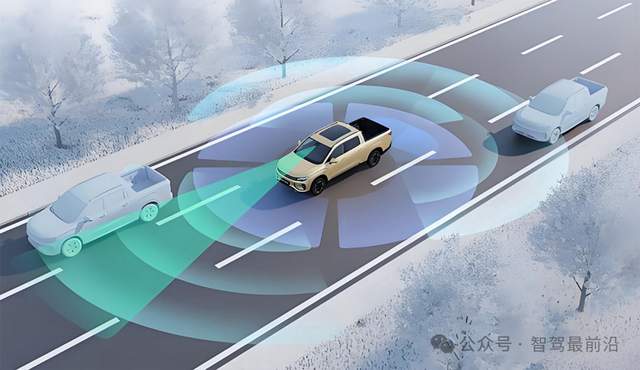
圖片源自:網絡
評估和指標體系的設定也要更加嚴謹。單靠訓練時的“平均回報”或離線估計不足以判斷部署的安全性,其中需要包括不確定性分布、最差-k%情況、OPE(離線策略評估)方法、以及通過仿真和小規模上線驗證得到的指標等多維度指標。
對于自動駕駛來說,監管與責任框架必須要預先設計好。在真實交通環境中,任何決策一旦出問題,就會牽扯到責任認定、修復補救和合規審查,離線強化學習的訓練日志與決策解釋將是重要證據。因此,要保證數據可追溯、策略版本可回滾、并保留充分的審計記錄。
最后的話
雖然離線強化學習面臨著“數據決定上限”與“分布外泛化難”的問題,但其給現實世界應用,尤其是自動駕駛這類安全敏感任務,提供了一個非常有價值的實現路徑。它緩和了“強化學習的潛力”與“現實世界的安全約束”之間的矛盾,使我們能利用海量歷史經驗去訓練智能策略。
審核編輯 黃宇
-
自動駕駛
+關注
關注
794文章
14953瀏覽量
181111
發布評論請先 登錄
自動駕駛中常提的占用網絡檢測存在哪些問題?
自動駕駛中常提的“深度估計”是個啥?

強化學習會讓自動駕駛模型學習更快嗎?

自動駕駛中常提的模仿學習是什么?
自動駕駛中常提的世界模型是什么?
如何訓練好自動駕駛端到端模型?

大模型中常提的快慢思考會對自動駕駛產生什么影響?

自動駕駛中常提的“強化學習”是個啥?

自動駕駛中常提的“專家數據”是個啥?
自動駕駛中常提的ODD是個啥?
自動駕駛中常提的硬件在環是個啥?
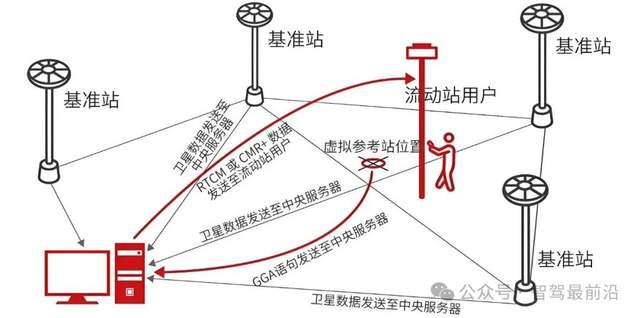
自動駕駛中常提的RTK是個啥?
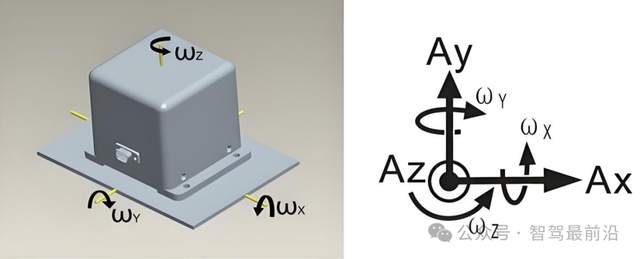
自動駕駛中常提的慣性導航系統是個啥?可以不用嗎?
自動駕駛中常提的世界模型是個啥?
自動駕駛中常提的“點云”是個啥?



 工商網監
工商網監
評論