") NVIDIA Jetson TX2 將深度學(xué)習(xí)推理提升至兩倍
NVIDIA Jetson TX2 將深度學(xué)習(xí)推理提升至兩倍

在舊金山的一個(gè) AI 會(huì)議上, NVIDIA 發(fā)布了 Jetson TX2 和 Jetpack3 。 0AI SDK 。 Jetson 是世界領(lǐng)先的低功耗嵌入式平臺(tái),為所有邊緣設(shè)備提供服務(wù)器級(jí) AI 計(jì)算性能。 Jetson TX2 具有集成的 256 核 NVIDIA Pascal GPU 、十六進(jìn)制內(nèi)核 ARMv8 64 位 CPU 復(fù)合體和 8GB LPDDR4 內(nèi)存和 128 位接口。 CPU 復(fù)合物結(jié)合了雙核心的丹佛 2 號(hào)和四核臂 Cortex-A57 。圖 1 所示的 Jetson TX2 模塊適合于 50 x 87 毫米、 85 克和 7 。 5 瓦的小尺寸、重量和功率(交換)占用空間。
物聯(lián)網(wǎng)( IoT )設(shè)備通常充當(dāng)簡(jiǎn)單的中繼數(shù)據(jù)網(wǎng)關(guān)。他們依靠云連接來完成繁重的工作和數(shù)字運(yùn)算。邊緣計(jì)算是一種新興的范式,它使用本地計(jì)算來實(shí)現(xiàn)數(shù)據(jù)源的分析。 TX2 具有超過 TFLOP / s 的性能,非常適合將高級(jí)人工智能部署到互聯(lián)網(wǎng)連接較差或昂貴的遠(yuǎn)程現(xiàn)場(chǎng)。 Jetson TX2 還為需要任務(wù)關(guān)鍵型自治的智能機(jī)器提供近實(shí)時(shí)響應(yīng)和最小延遲密鑰。
Jetson TX2 基于 16nm NVIDIA Tegra “ Parker ”系統(tǒng)片上系統(tǒng)( SoC )(圖 2 顯示了一個(gè)框圖)。 Jetson TX2 在深度學(xué)習(xí)推理方面的能效是其前代產(chǎn)品 Jetson TX1 的兩倍,并提供比 Intel Xeon 服務(wù)器 CPU 更高的性能。效率的提高重新定義了將先進(jìn)的人工智能從云端擴(kuò)展到邊緣的可能性。
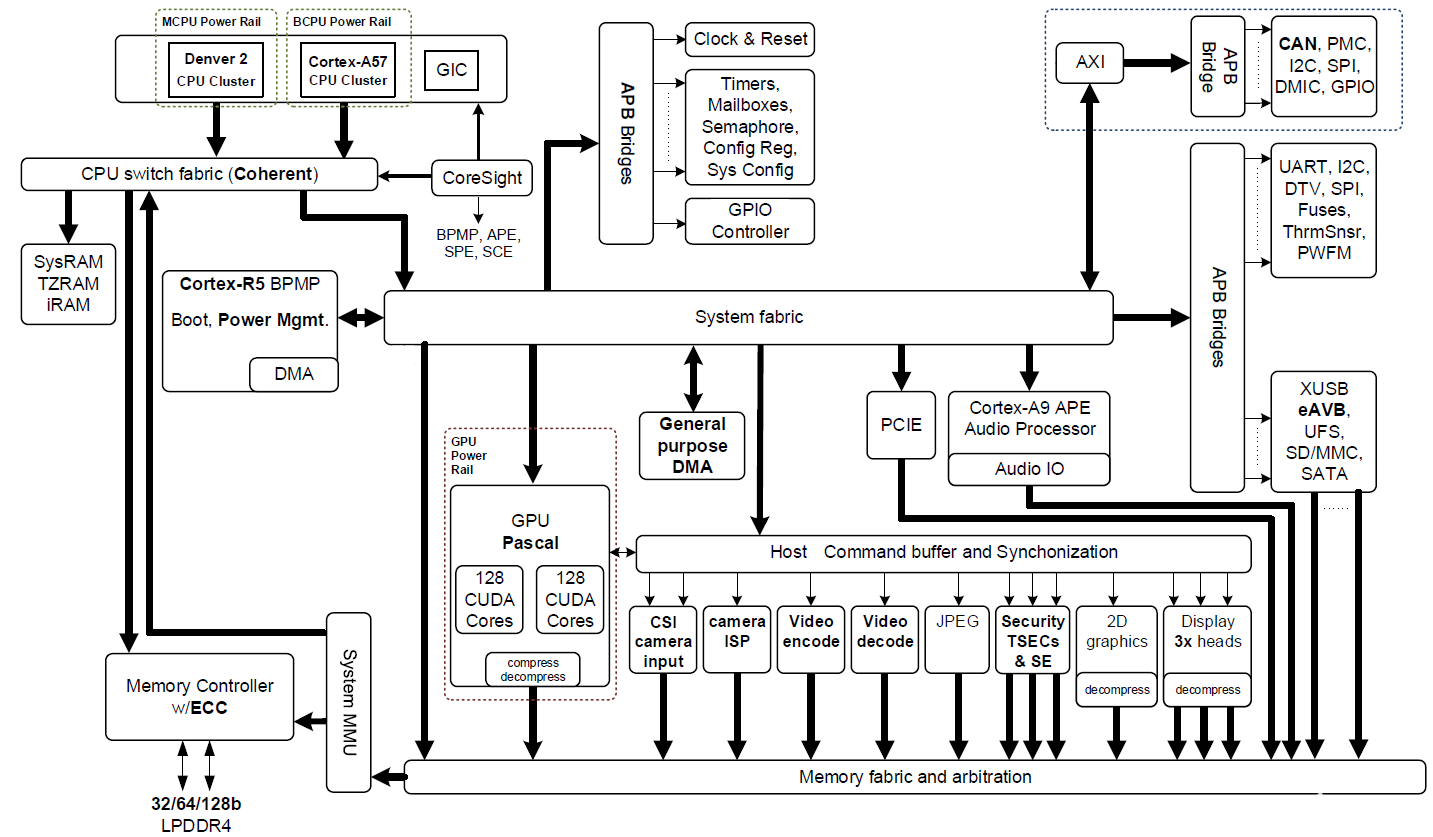
圖 2 : NVIDIA Jetson TX2 Tegra “ Parker ” SoC 框圖,具有集成的 NVIDIA Pascal GPU 、 NVIDIA Denver 2 + Arm Cortex-A57 CPU 集群和多媒體加速引擎(點(diǎn)擊圖片獲取完整分辨率)。
Jetson TX2 有多個(gè)多媒體流引擎,通過減輕傳感器采集和分發(fā)的負(fù)擔(dān),使其 Pascal GPU 能夠獲得數(shù)據(jù)。這些多媒體引擎包括六個(gè)專用的 MIPI CSI-2 攝像頭端口,每通道提供高達(dá) 2 。 5gb / s 的帶寬和 1 。 4gb / s 的雙圖像服務(wù)處理器( ISP )處理,以及支持 H 。 265 、每秒 4k60 幀的視頻編解碼器。
Jetson TX2 使用 NVIDIA cuDNN 和 TensorRT 庫(kù)加速尖端深度神經(jīng)網(wǎng)絡(luò)( DNN )架構(gòu),并支持 遞歸神經(jīng)網(wǎng)絡(luò) 、 長(zhǎng)短期記憶網(wǎng)絡(luò) 和在線 強(qiáng)化學(xué)習(xí) 。它的雙 CAN 總線控制器使自動(dòng)駕駛儀集成到控制機(jī)器人和無人機(jī),這些機(jī)器人和無人機(jī)使用 DNN 感知周圍的世界,并在動(dòng)態(tài)環(huán)境中安全運(yùn)行。 Jetson TX2 的軟件通過 NVIDIA 的 噴氣背包 3 。 0 和 Linux for Tegra ( L4T ) Board Support Package ( BSP )提供。
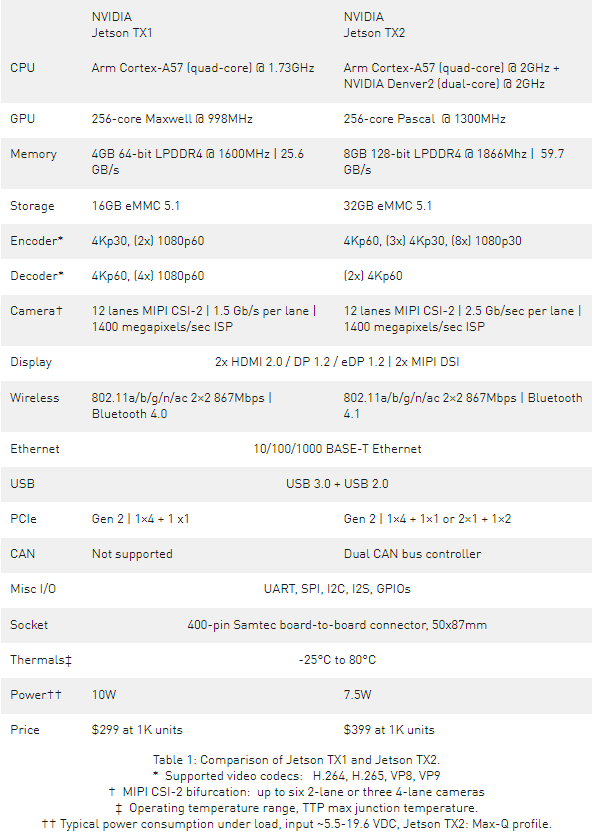
表 1 比較了 Jetson TX2 與上一代 Jetson TX1 的特性。
兩倍的性能,兩倍的效率
在我的 在 JetPack 2 。 3 上發(fā)布 中,我演示了 NVIDIA TensorRT 如何提高 Jetson TX1 深度學(xué)習(xí)推理性能,效率比桌面類 CPU 高 18 倍。 TensorRT 通過使用 graph 優(yōu)化、內(nèi)核融合、 半精度浮點(diǎn)計(jì)算( FP16 ) 和架構(gòu)自動(dòng)調(diào)整來優(yōu)化生產(chǎn)網(wǎng)絡(luò)以顯著提高性能。除了利用 Jetson TX2 對(duì) FP16 的硬件支持之外, NVIDIA TensorRT 還能夠批量同時(shí)處理多個(gè)圖像,從而獲得更高的性能。
Jetson TX2 和 JetPack 3 。 0 將 Jetson 平臺(tái)的性能和效率提升到一個(gè)全新的水平,為用戶提供了在 AI 應(yīng)用中獲得兩倍或最多兩倍于 Jetson TX1 性能的選項(xiàng)。這種獨(dú)特的功能使 Jetson TX2 成為邊緣需要高效人工智能的產(chǎn)品和邊緣附近需要高性能的產(chǎn)品的理想選擇。 Jetson TX2 還與 Jetson TX1 兼容,為使用 Jetson TX1 設(shè)計(jì)的產(chǎn)品提供了一個(gè)簡(jiǎn)單的升級(jí)機(jī)會(huì)。
為了測(cè)試 Jetson TX2 和 JetPack 3 。 0 的性能,我們將其與服務(wù)器類 CPU 、 Intel Xeon E5-2690 v4 進(jìn)行比較,并使用 GoogLeNet 深度圖像識(shí)別網(wǎng)絡(luò)測(cè)量深度學(xué)習(xí)推理吞吐量(每秒圖像數(shù))。如圖 3 所示, Jetson TX2 在低于 15W 的功率下運(yùn)行的性能優(yōu)于在接近 200W 的情況下運(yùn)行的 CPU ,從而使數(shù)據(jù)中心級(jí)的 AI 能力處于邊緣。
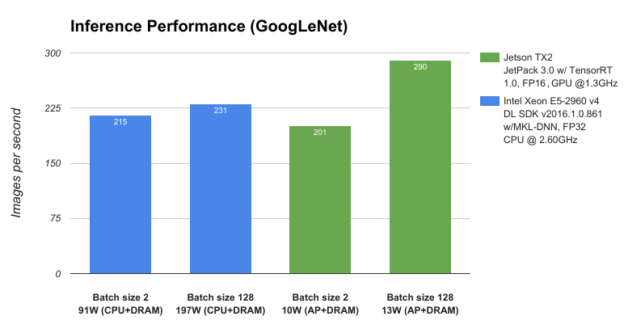
圖 3 : GoogLeNet 網(wǎng)絡(luò)架構(gòu)在 NVIDIA Jetson TX2 和 Intel Xeon E5-2960 v4 上的性能。
Jetson TX2 的卓越 AI 性能和效率源于新的 Pascal GPU 架構(gòu)和動(dòng)態(tài)能量配置文件( Max-Q 和 Max-P )、 JetPack 3 。 0 附帶的優(yōu)化深度學(xué)習(xí)庫(kù)以及大內(nèi)存帶寬的可用性。
Max-Q 和 Max-P
Jetson TX2 設(shè)計(jì)用于 7 。 5W 功率下的峰值處理效率。這一性能水平被稱為 Max-Q ,代表功率/吞吐量曲線的峰值。模塊上的每個(gè)組件(包括電源)都經(jīng)過優(yōu)化,以提供最高的效率。 GPU 的最大 Q 頻率為 854 MHz ,而 Arm A57 CPU 的最大 Q 頻率為 1 。 2 GHz 。 JetPack 3 。 0 中的 L4T BSP 包括用于將 Jetson TX2 設(shè)置為 Max-Q 模式的預(yù)設(shè)平臺(tái)配置。 Jetpack3 。 0 還包括一個(gè)名為 nvpmodel 的新命令行工具,用于在運(yùn)行時(shí)切換配置文件。
雖然動(dòng)態(tài)電壓和頻率縮放( DVFS )允許 Jetson TX2 的 Tegra “ Parker ” SoC 在運(yùn)行時(shí)根據(jù)用戶負(fù)載和功耗調(diào)整時(shí)鐘速度,但 Max-Q 配置設(shè)置了時(shí)鐘上限,以確保應(yīng)用程序僅在最有效的范圍內(nèi)運(yùn)行。表 2 顯示了在運(yùn)行 GoogLeNet 和 AlexNet 深度學(xué)習(xí)基準(zhǔn)測(cè)試時(shí), Jetson TX2 和 Jetson TX1 的性能和能效。在 Max-Q 模式下運(yùn)行的 Jetson TX2 的性能與在最大時(shí)鐘頻率下運(yùn)行的 Jetson TX1 的性能相似,但只消耗一半的功率,因此能量效率提高了一倍。
盡管功率預(yù)算有限的大多數(shù)平臺(tái)將從 Max-Q 行為中受益最大,但其他平臺(tái)可能更喜歡使用最大時(shí)鐘來達(dá)到峰值吞吐量,盡管這樣做會(huì)導(dǎo)致更高的功耗和更低的效率。 DVFS 可以配置為在其他時(shí)鐘速度范圍內(nèi)運(yùn)行,包括欠時(shí)鐘和超頻。 Max-P 是另一種預(yù)設(shè)平臺(tái)配置,可在不到 15W 的時(shí)間內(nèi)實(shí)現(xiàn)最大系統(tǒng)性能。啟用 Arm A57 群集或啟用丹佛 2 群集時(shí), GPU 的 Max-P 頻率為 1122 MHz , CPU 的 Max-P 頻率為 2 GHz ,當(dāng)兩個(gè)群集都啟用時(shí), Max-P 頻率為 1 。 4 GHz 。您還可以創(chuàng)建具有中頻目標(biāo)的自定義平臺(tái)配置,以便在應(yīng)用程序的峰值效率和峰值性能之間實(shí)現(xiàn)平衡。下表 2 顯示了從 Max-Q 到 Max-P 的性能如何提高,以及如何在效率逐漸降低的情況下提高 GPU 時(shí)鐘頻率。
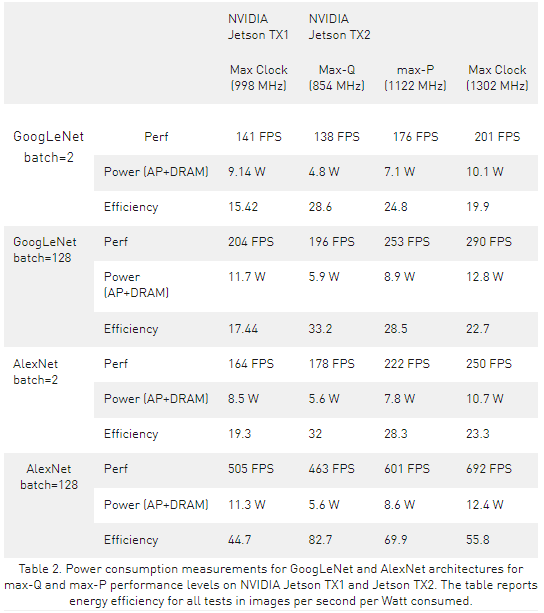
Jetson TX2 執(zhí)行 GoogLeNet 推理的速度高達(dá) 33 。 2 圖像/秒/瓦,幾乎是 Jetson TX1 的兩倍,效率比 Intel Xeon 高出近 20 倍。
端到端人工智能應(yīng)用
兩個(gè) Pascal 流式多處理器( SMs )是 Jetson TX2 高效性能的重要組成部分,每個(gè)處理器有 128 個(gè) CUDA 核。 Pascal GPU 架構(gòu) 提供了重大的性能改進(jìn)和電源優(yōu)化。 TX2 的 CPU 復(fù)合體包括雙核 7 路超標(biāo)量 NVIDIA Denver 2 ,用于動(dòng)態(tài)代碼優(yōu)化的高單線程性能,以及用于多線程處理的四核 Arm Cortex-A57 。
相干的丹佛 2 和 A57 CPU 都有一個(gè) 2MB 的二級(jí)緩存,并通過由 NVIDIA 設(shè)計(jì)的高性能互連結(jié)構(gòu)進(jìn)行連接,以在異構(gòu)多處理器( HMP )環(huán)境中實(shí)現(xiàn)兩個(gè) CPU 的同時(shí)操作。一致性機(jī)制允許根據(jù)動(dòng)態(tài)性能需求自由地對(duì)任務(wù)進(jìn)行 MIG 評(píng)級(jí),以減少開銷的方式有效地利用 CPU 核心之間的資源。
Jetson TX2 是自主機(jī)端到端 AI 管線的理想平臺(tái)。 Jetson 有線傳輸實(shí)時(shí)高帶寬數(shù)據(jù):在處理 GPU 數(shù)據(jù)后,可同時(shí)接收多個(gè)傳感器的數(shù)據(jù),執(zhí)行媒體解碼/編碼、組網(wǎng)和低級(jí)命令控制協(xié)議。圖 4 顯示了使用高速接口陣列(包括 CSI 、 PCIe 、 USB3 和千兆以太網(wǎng))連接傳感器的常見管道配置。 CUDA 預(yù)處理和后處理階段通常包括色域轉(zhuǎn)換(成像 DNN 通常使用 BGR 平面格式)和對(duì)網(wǎng)絡(luò)輸出的統(tǒng)計(jì)分析。
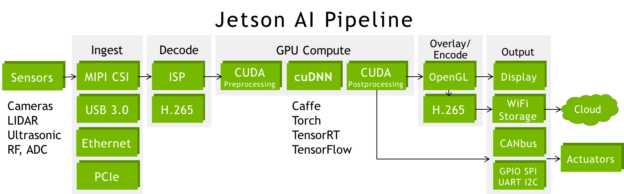
圖 4 :端到端人工智能管道,包括傳感器采集、處理、指揮和控制。
由于內(nèi)存和帶寬是 Jetson TX1 的兩倍, Jetson TX2 能夠同時(shí)捕獲和處理額外的高帶寬數(shù)據(jù)流,包括立體攝像機(jī)和 4K 超高清輸入和輸出。通過管道,深度學(xué)習(xí)和計(jì)算機(jī)視覺將來自不同來源和光譜域的多個(gè)傳感器融合在一起,從而增強(qiáng)了自動(dòng)導(dǎo)航期間的感知能力和態(tài)勢(shì)感知能力。
Jetson TX2 開發(fā)工具包入門
首先, NVIDIA 為 Jetson TX2 開發(fā)工具包 提供了一個(gè)參考的小型 ITX 載體板( 170 毫米 x 170 毫米)和一個(gè) 500 萬像素的 MIPI CSI-2 相機(jī)模塊。開發(fā)工具包包括文檔和設(shè)計(jì)示意圖以及 JetPack-L4T 的免費(fèi)軟件更新。圖 5 顯示了開發(fā)工具包,顯示了 Jetson TX2 模塊和標(biāo)準(zhǔn) PC 連接,包括 USB3 、 HDMI 、 RJ45 千兆以太網(wǎng)、 SD 卡和 PCIe x4 插槽,這使得 Jetson 的應(yīng)用程序開發(fā)更加容易。
要超越開發(fā)到定制部署平臺(tái),您可以修改開發(fā)工具包載體板和相機(jī)模塊的參考設(shè)計(jì)文件,以創(chuàng)建自定義設(shè)計(jì)。或者, Jetson 生態(tài)系統(tǒng)合作伙伴為部署 Jetson TX1 和 Jetson TX2 模塊提供現(xiàn)成的解決方案,包括微型載體、外殼和攝像頭。 NVIDIA Developer Forums 為 Jetson 建造者和 NVIDIA 工程師社區(qū)提供技術(shù)支持和協(xié)作之家。表 3 列出了主要文件和有用的資源。

Jetson TX2 開發(fā)工具包可通過 NVIDIA 在線商店 以 599 美元的價(jià)格預(yù)訂。 3 月 14 日開始在北美和歐洲發(fā)貨,其他地區(qū)也將陸續(xù)發(fā)貨。 Jetson TX2 教育折扣 還提供: 299 美元用于學(xué)術(shù)機(jī)構(gòu)的附屬機(jī)構(gòu)。 NVIDIA 已將 Jetson TX1 開發(fā)工具包的價(jià)格降至 499 美元。
JetPack 3 。 0 SDK 開發(fā)包
最新的 NVIDIA JetPack 3.0 支持 Jetson TX2 使用業(yè)界領(lǐng)先的 AI 開發(fā)工具和硬件加速 API(見表4),包括 NVIDIA CUDA 工具包版本8.0、cuDNN、TensorRT、VisionWorks、GStreamer 和 OpenCV,這些都是在 Linux 內(nèi)核v4.4、L4T R27.1 BSP 和 Ubuntu 16.04 LTS 的基礎(chǔ)上構(gòu)建的。Jetpack3.0 包括用于交互式分析和調(diào)試的Tegra系統(tǒng)探查器和Tegra圖形調(diào)試器工具。Tegra多媒體API包括低級(jí)攝像頭捕獲和Video4Linux2(V4L2)編解碼器接口。在閃爍的同時(shí),JetPack會(huì)自動(dòng)使用所選的軟件組件配置Jetson TX2,從而實(shí)現(xiàn)開箱即用的完整環(huán)境

Jetson 是一個(gè)高性能的嵌入式解決方案,用于部署 Caffe 、 Torch 、 Theano 和 TensorFlow 等深度學(xué)習(xí)框架。這些和許多其他深度學(xué)習(xí)框架已經(jīng)將 NVIDIA 的 cuDNN 庫(kù)與 GPU 加速集成在一起,并且只需要很少的 MIG 定量工作就可以在 Jetson 上部署。 KZV3 的軟件和應(yīng)用程序通常在云計(jì)算中心和服務(wù)器上無縫部署[KZV3]軟件和應(yīng)用程序。
還有兩天就要演示了
NVIDIA Two Days to a Demo 是一個(gè)幫助任何人開始部署深度學(xué)習(xí)的倡議。 NVIDIA 提供計(jì)算機(jī)視覺原語,包括圖像識(shí)別、目標(biāo)檢測(cè)+定位和分割,以及用 DIGITS 訓(xùn)練的 神經(jīng)網(wǎng)絡(luò) 模型。您可以將這些網(wǎng)絡(luò)模型部署到 Jetson 上,以便使用 NVIDIA TensorRT 進(jìn)行有效的深度學(xué)習(xí)推斷。“兩天一個(gè)演示”提供了示例流式應(yīng)用程序,以幫助您體驗(yàn)實(shí)時(shí)攝像頭提要和真實(shí)世界的數(shù)據(jù)。
兩天的演示代碼是 在 GitHub 上提供 ,以及易于遵循的測(cè)試和重新訓(xùn)練網(wǎng)絡(luò)模型的分步指導(dǎo),為您的定制主題擴(kuò)展了視覺原語。這些教程演示了數(shù)字工作流的強(qiáng)大概念,向您展示了如何在云端或 PC 機(jī)上迭代地訓(xùn)練網(wǎng)絡(luò)模型,然后將其部署到 Jetson 上進(jìn)行運(yùn)行時(shí)推斷和進(jìn)一步的數(shù)據(jù)收集。
通過使用預(yù)先訓(xùn)練的網(wǎng)絡(luò)和轉(zhuǎn)移學(xué)習(xí),此工作流使您可以輕松地使用自定義對(duì)象類來定制基礎(chǔ)網(wǎng)絡(luò)以滿足您的任務(wù)。一旦一個(gè)特定的網(wǎng)絡(luò)體系結(jié)構(gòu)被證明適用于某個(gè)原語或應(yīng)用程序,那么針對(duì)特定的用戶定義的應(yīng)用程序(例如包含新對(duì)象的訓(xùn)練數(shù)據(jù))對(duì)其進(jìn)行重新調(diào)整或重新訓(xùn)練通常會(huì)非常容易。
正如在 這個(gè)平行的 博客文章中所討論的, NVIDIA 在數(shù)字 5 上增加了對(duì)分段網(wǎng)絡(luò)的支持,現(xiàn)在可以在 Jetson TX2 上使用,演示時(shí)間為兩天。分割原語使用完全卷積 Alexnet 架構(gòu)( FCN-Alexnet )對(duì)視野中的單個(gè)像素進(jìn)行分類。由于分類發(fā)生在像素級(jí),與圖像識(shí)別中的圖像級(jí)不同,分割模型能夠提取對(duì)周圍環(huán)境的全面了解。這克服了自主導(dǎo)航機(jī)器人和無人機(jī)所面臨的重大障礙,這些機(jī)器人和無人機(jī)可以直接使用分割區(qū)域進(jìn)行路徑規(guī)劃和障礙物回避。
分段制導(dǎo)的自由空間探測(cè)使地面車輛能夠安全地在地面上導(dǎo)航,而無人機(jī)則通過視覺識(shí)別和跟蹤地平線和天空平面,以避免與障礙物和地形發(fā)生碰撞。感知和避免功能是智能機(jī)器與環(huán)境安全交互的關(guān)鍵。在 Jetson TX2 上使用 TensorRT 處理要求計(jì)算量大的分段網(wǎng)絡(luò),對(duì)于避免事故所需的低響應(yīng)延遲至關(guān)重要。
兩天的演示包括一個(gè)使用 FCN Alexnet 的空中分割模型(圖 7 ),以及相應(yīng)的 horizon 第一人稱視圖( FPV )數(shù)據(jù)集。空中分割模型可作為無人機(jī)和自主導(dǎo)航的范例。您可以使用自定義數(shù)據(jù)輕松擴(kuò)展模型,以識(shí)別用戶定義的類,如著陸平臺(tái)和工業(yè)設(shè)備。一旦以這種方式增強(qiáng),你就可以把它部署到裝備了 Jetson 的無人機(jī)上,比如 Teal 和 Aerialtronics 的無人機(jī)。
為了鼓勵(lì)開發(fā)更多的自主飛行控制模式,我在 GitHub 上發(fā)布了空中訓(xùn)練數(shù)據(jù)集、分段模型和工具。 NVIDIA Jetson TX2 和 Two Days to a Demo 使在該領(lǐng)域開始使用先進(jìn)的深度學(xué)習(xí)解決方案比以往任何時(shí)候都更容易。
Jetson 生態(tài)系統(tǒng)
Jetson TX2 的模塊化外形使其能夠部署到各種環(huán)境和場(chǎng)景中。 NVIDIA 的開源參考載波設(shè)計(jì)來自于 Jetson TX2 開發(fā)工具包,為縮小或修改單個(gè)項(xiàng)目需求的設(shè)計(jì)提供了一個(gè)起點(diǎn)。一些小型化的載體與 Jetson 模塊本身具有相同的 50x87mm 的占地面積,從而實(shí)現(xiàn)了緊湊的組裝,如圖 8 所示。使用 NVIDIA 提供的文檔和設(shè)計(jì)輔助資料,或嘗試現(xiàn)成的解決方案。今年 4 月, NVIDIA 將推出 Jetson TX1 和 TX2 模塊,價(jià)格分別為 299 美元和 399 美元,數(shù)量為 1000 臺(tái)或更多。

圖 8 : ConnectTech
Sprocket
緊湊型托架組件,適用于 Jetson TX2 和 Jetson TX1 ,售價(jià) 99 美元。
生態(tài)系統(tǒng)合作伙伴{ ConnectTech ? Auvidea ?提供與 Jetson TX1 和 TX2 共享插座兼容的可部署微型載體和外殼,如圖 8 所示。 Image partners & 豹紋成像 ? 山脊跑 提供攝像頭和多媒體支持。加固專家 阿巴科系統(tǒng) ↓ 沃爾夫先進(jìn)技術(shù) ?為在惡劣環(huán)境下操作提供 MIL 規(guī)范的資質(zhì)。
除了用于部署到野外的緊湊型載體和外殼外, Jetson 的生態(tài)系統(tǒng)覆蓋范圍超出了典型的嵌入式應(yīng)用。 Jetson TX2 的多核 Arm / GPU 體系結(jié)構(gòu)和卓越的計(jì)算效率也讓高性能計(jì)算( HPC )行業(yè)備受關(guān)注。高密度 1U 機(jī)架式服務(wù)器現(xiàn)已提供萬兆以太網(wǎng)和多達(dá) 24 個(gè) Jetson 模塊。圖 9 顯示了一個(gè)可伸縮陣列服務(wù)器的示例。 Jetson 的低功耗和被動(dòng)冷卻對(duì)于輕量級(jí)、可擴(kuò)展的云任務(wù)(包括低功耗的 web 服務(wù)器、多媒體處理和分布式計(jì)算)很有吸引力。視頻分析和代碼轉(zhuǎn)換后端通常與部署在現(xiàn)場(chǎng)的智能攝像機(jī)和物聯(lián)網(wǎng)設(shè)備上的 Jetson 配合工作,可以從 Jetson TX2 增加的每個(gè)處理器支持的同步數(shù)據(jù)流和視頻編解碼器的比率中獲益。
AI 在邊緣
Jetson TX2 無與倫比的嵌入式計(jì)算能力將尖端 DNN 和下一代人工智能帶到板上邊緣設(shè)備上。 Jetson TX2 提供服務(wù)器級(jí)的高能效性能。它的原始深度學(xué)習(xí)性能比 Intel Xeon 高出 1 。 25 倍,計(jì)算效率提高了近 20 倍。 Jetson 緊湊的占地面積、計(jì)算能力和具有深度學(xué)習(xí)功能的 JetPack 軟件堆棧使開發(fā)人員能夠使用 AI 解決 21 世紀(jì)的挑戰(zhàn)。
關(guān)于作者
Dustin Franklin 是 NVIDIA 的 Jetson 團(tuán)隊(duì)的開發(fā)人員布道者。 Dustin 擁有機(jī)器人和嵌入式系統(tǒng)方面的背景,他樂于在社區(qū)中提供幫助,并與 Jetson 一起參與項(xiàng)目。你可以在 NVIDIA Developer Forums 或 Github 上找到他。
審核編輯:郭婷
-
嵌入式
+關(guān)注
關(guān)注
5198文章
20442瀏覽量
333986 -
人工智能
+關(guān)注
關(guān)注
1817文章
50094瀏覽量
265295 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5598瀏覽量
124396
發(fā)布評(píng)論請(qǐng)先 登錄
如何在NVIDIA Jetson AGX Thor上部署1200億參數(shù)大模型

如何在NVIDIA Jetson Thor上提升機(jī)器人感知效率
如何在NVIDIA Jetson AGX Thor上通過Docker高效部署vLLM推理服務(wù)

NVIDIA Jetson AGX Thor Developer Kit開發(fā)環(huán)境配置指南
通過NVIDIA Jetson AGX Thor實(shí)現(xiàn)7倍生成式AI性能
NVIDIA TensorRT LLM 1.0推理框架正式上線
BPI-AIM7 RK3588 AI與 Nvidia Jetson Nano 生態(tài)系統(tǒng)兼容的低功耗 AI 模塊
ADI借助NVIDIA Jetson Thor平臺(tái)加速人形機(jī)器人研發(fā)進(jìn)程
NVIDIA Jetson AGX Thor開發(fā)者套件重磅發(fā)布
NVIDIA Nemotron Nano 2推理模型發(fā)布

基于 NVIDIA Blackwell 的 Jetson Thor 現(xiàn)已發(fā)售,加速通用機(jī)器人時(shí)代的到來




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論