") 如何在NVIDIA Jetson AGX Thor上通過Docker高效部署vLLM推理服務
如何在NVIDIA Jetson AGX Thor上通過Docker高效部署vLLM推理服務

繼系統(tǒng)安裝與環(huán)境配置后,本期我們將繼續(xù)帶大家深入NVIDIAJetson AGX Thor的開發(fā)教程之旅,了解如何在 Jetson AGX Thor 上,通過 Docker 高效部署 vLLM 推理服務。
具體內(nèi)容包括:
vLLM 簡介與優(yōu)勢
vLLM Docker 容器構(gòu)建
使用 vLLM 在線下載模型
使用 vLLM 運行本地模型
使用 Chatbox 作為前端調(diào)用 vLLM 運行的模型
一、vLLM 簡介與優(yōu)勢
1什么是 vLLM?
vLLM 是一個高效的大語言模型推理和服務引擎,專門優(yōu)化了注意力機制和內(nèi)存管理,能夠提供極高的吞吐量。
2在 Jetson AGX Thor 上運行 vLLM 的優(yōu)勢:
PagedAttention 技術:顯著減少內(nèi)存碎片,提高 GPU 利用率
Continuous Batching 機制:能夠連續(xù)動態(tài)處理不同長度的請求
開源生態(tài):支持主流開源模型(Llama、Qwen、ChatGLM 等)
二、vLLM Docker 容器構(gòu)建
在上一期NVIDIA Jetson AGX Thor Developer Kit 開發(fā)環(huán)境配置教程中,我們已經(jīng)完成了 Docker 的安裝與配置,現(xiàn)在,只需要使用 Docker 拉取 vLLM 鏡像即可。

當前 Docker 版本
1. 參照上期教程介紹的方法,注冊并登錄 NGC 之后,搜索 vLLM 進入容器頁面,點擊“Get Container”,復制鏡像目錄。
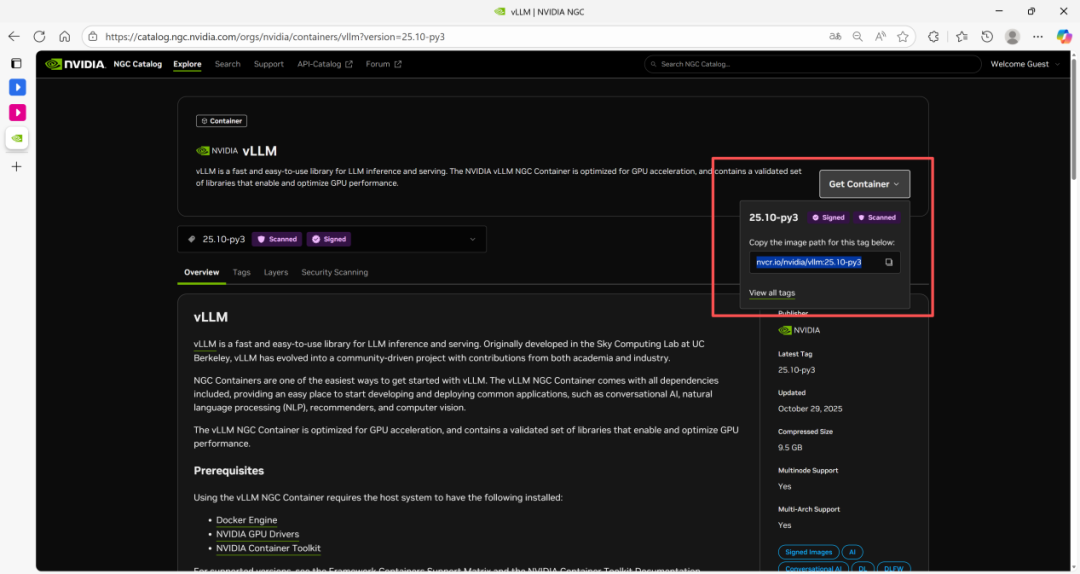
2. 在命令行運行docker pull nvcr.io/nvidia/vllm:25.10-py3下載鏡像。

3. 下載完成后,運行容器,創(chuàng)建啟動命令。
sudodocker run -d -t --net=host --gpusall --ipc=host --name vllm -v /data:/data --restart=unless-stopped nvcr.io/nvidia/vllm:25.10-py3
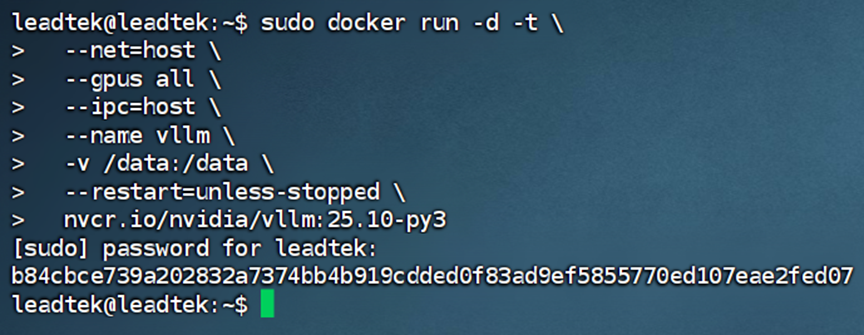
注:關鍵參數(shù)說明
-d (detach):后臺運行容器
-t (tty):分配一個偽終端,方便日志輸出
--name vllm:為容器指定名稱"vllm"
--net=host:使用主機網(wǎng)絡模式,容器與主機共享網(wǎng)絡命名空間
--gpus all:將所有可用的 GPU 設備暴露給容器
--ipc=host:使用主機的 IPC 命名空間,改善進程間通信性能
-v /data:/data:將主機的 /data 目錄掛載到容器的 /data 目錄,后面可用于持久化模型文件、配置文件等數(shù)據(jù)
--restart=unless-stopped:Docker 容器的重啟策略參數(shù),表示容器在非人工主動停止時(如崩潰、宿主機重啟),會自動重啟,但若被手動停止,則不會自動恢復
4. 容器創(chuàng)建成功后,使用docker exec -it vllm /bin/bash命令進入此容器。

三、使用 vLLM 在線下載模型
1. 從 Hugging Face 上下載模型權(quán)重:
通常默認的模型下載目錄為:.cache/huggingface/hub/,通過設置環(huán)境變量,我們將指定模型下載到:export HF_HOME=/data/huggingface目錄,然后執(zhí)行vllm serve "Qwen/Qwen2.5-Math-1.5B-Instruct",此命令會從 Hugging Face 上在線拉取下載模型并開始運行。
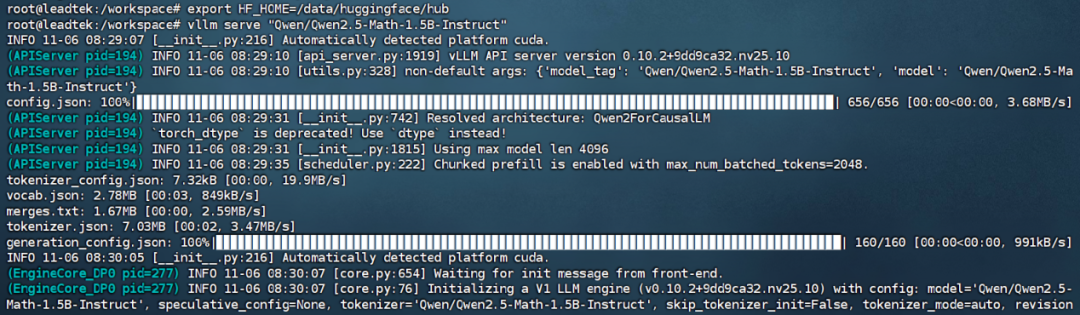
2. 等待模型文件下載完成(需科學上網(wǎng))。
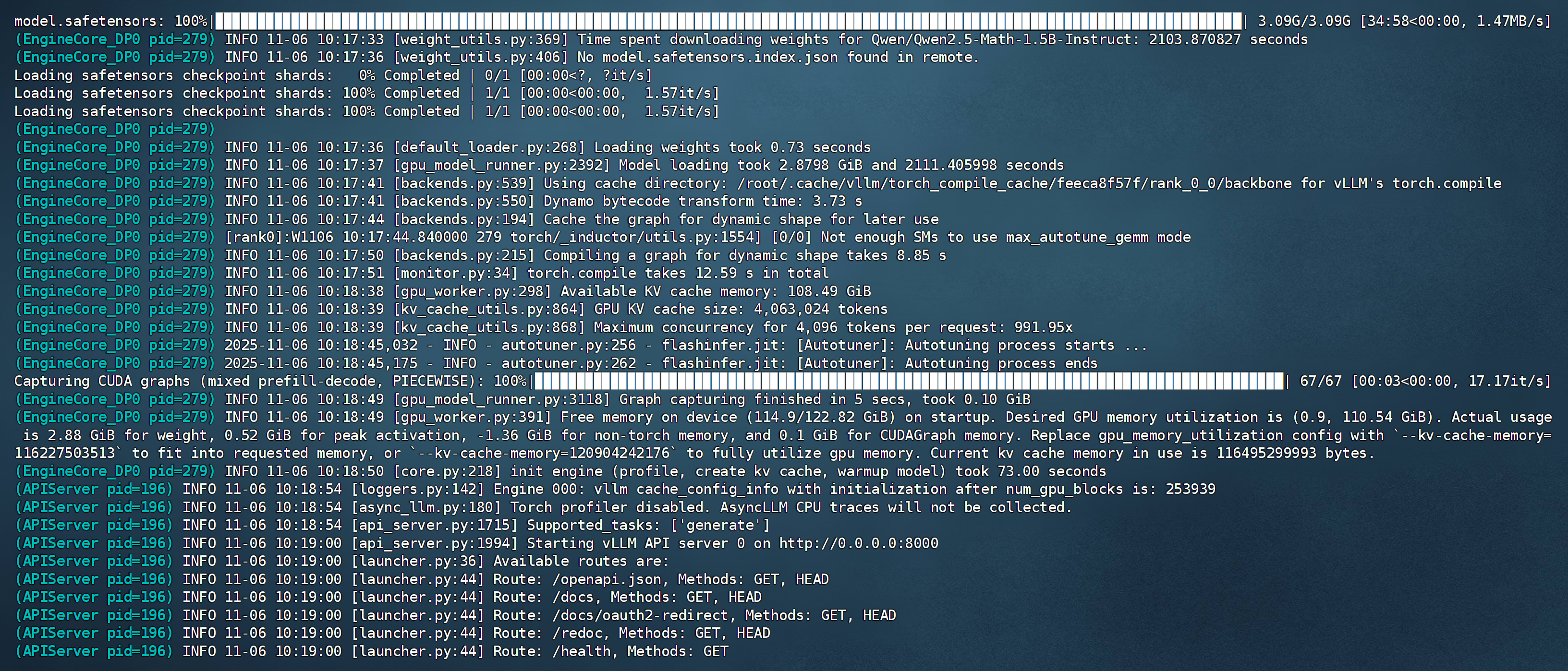
注:為方便后續(xù)調(diào)用,建議通過本地終端確認模型已下載到預設目錄(如下圖所示)。
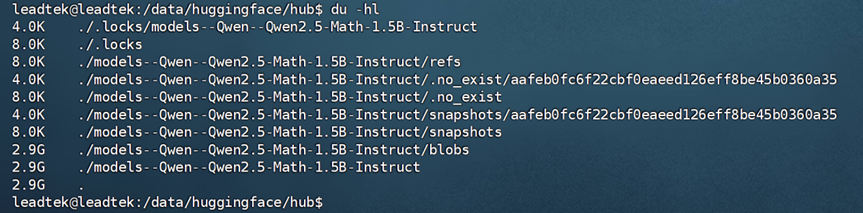
在沒有前端的情況下,可以通過 curl 命令向 vLLM 服務發(fā)送聊天請求。
curl http://localhost:8000/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model":"Qwen/Qwen2.5-Math-1.5B-Instruct",
"messages": [{"role":"user","content":"12*17"}],
"max_tokens":500
}'

注:關鍵參數(shù)說明
curl:命令行工具,用于傳輸數(shù)據(jù)
http://localhost:8000:本地服務器地址和端口
/v1/chat/completions:OpenAI 兼容的聊天補全 API 端點
-H:設置 HTTP 請求頭
"Content-Type:application/json":指定請求體為 JSON 格式
-d:設置請求數(shù)據(jù)
"model":"Qwen/Qwen2.5-Math-1.5B-Instruct":指定要使用的模型,這個名稱應該與 vLLM 服務啟動時指定的模型名稱一致
"messages:[{"role": "user", "content": "12*17"}]:定義對話歷史和當前消息
消息對象字段:"role" 指消息角色;"user"指用戶消息,"Content"指消息具體內(nèi)容;"12*17"指用戶提出的數(shù)學問題
"max_tokens":500:限制模型生成的最大 token 數(shù)量
四、使用 vLLM 運行本地模型
如前所述,模型已下載保存至本地指定目錄,可以直接通過其路徑啟動服務。
以上方“Qwen/Qwen2.5-Math-1.5B-Instruct”為例,該模型權(quán)重路徑為:
“/data/huggingface/hub/models--Qwen--Qwen2.5-Math-1.5B-Instruct/snapshots/aafeb0fc6f22cbf0eaeed126eff8be45b0360a35”。

執(zhí)行以下命令,即可正常運行本地模型。
vllmserve /data/huggingface/hub/models--Qwen--Qwen2.5-Math-1.5B-Instruct/snapshots/aafeb0fc6f22cbf0eaeed126eff8be45b0360a35
五、使用 Chatbox 作為前端調(diào)用 vLLM 運行的模型
1. 局域網(wǎng)內(nèi)訪問 Chatbox 官網(wǎng)(https://chatboxai.app),下載并安裝Windows版本。
2. 點擊“設置提供方” — “添加”,輸入名稱,再次點擊“添加”。
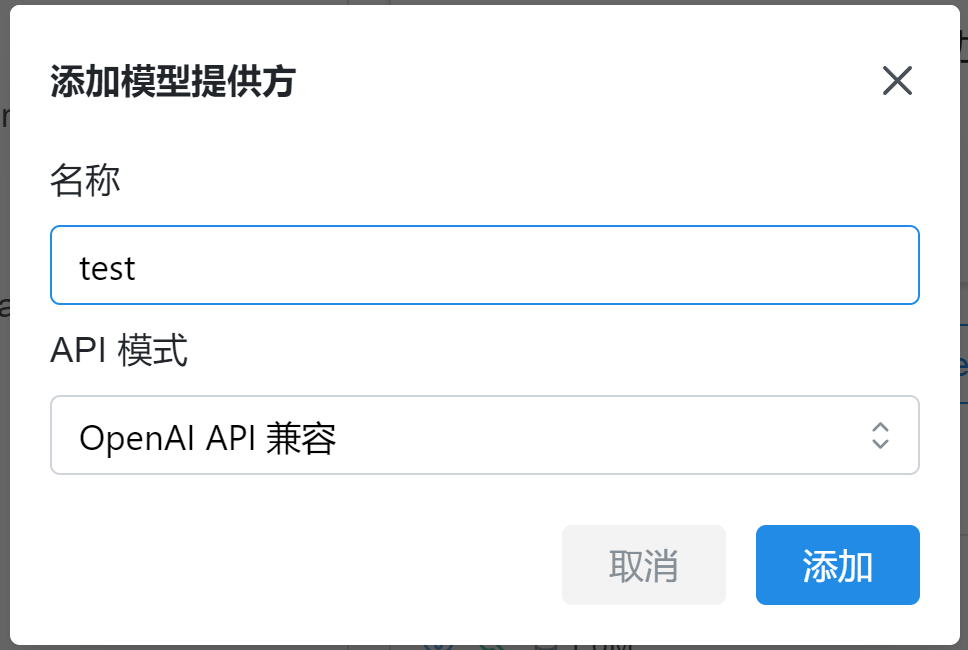
上下滑動 點擊查看
3. API 主機可輸入 Jetson AGX Thor 主機 IP 以及 vLLM 服務端口號。
(例:http://192.168.23.107:8000)
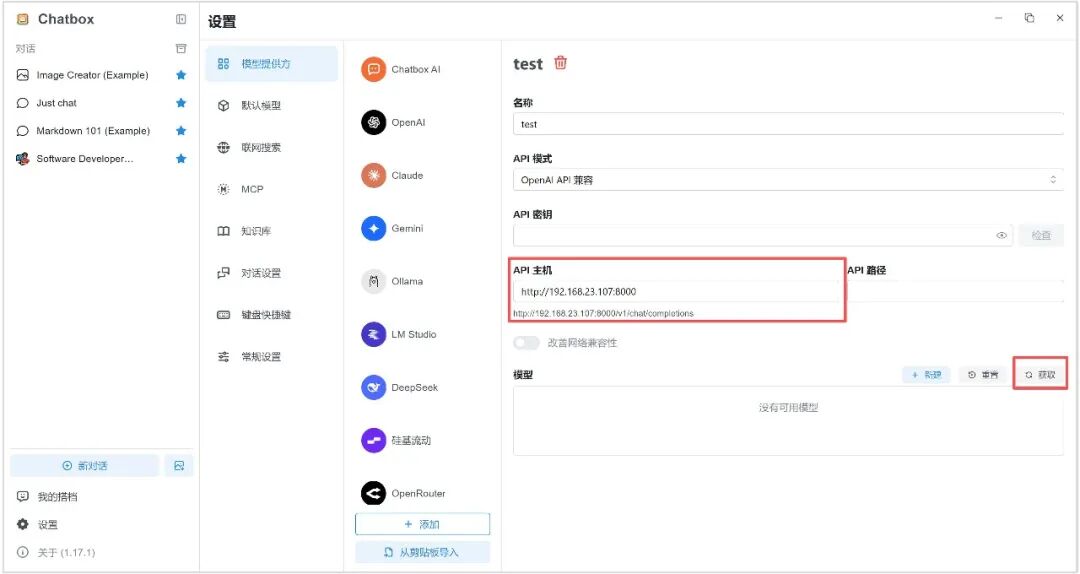
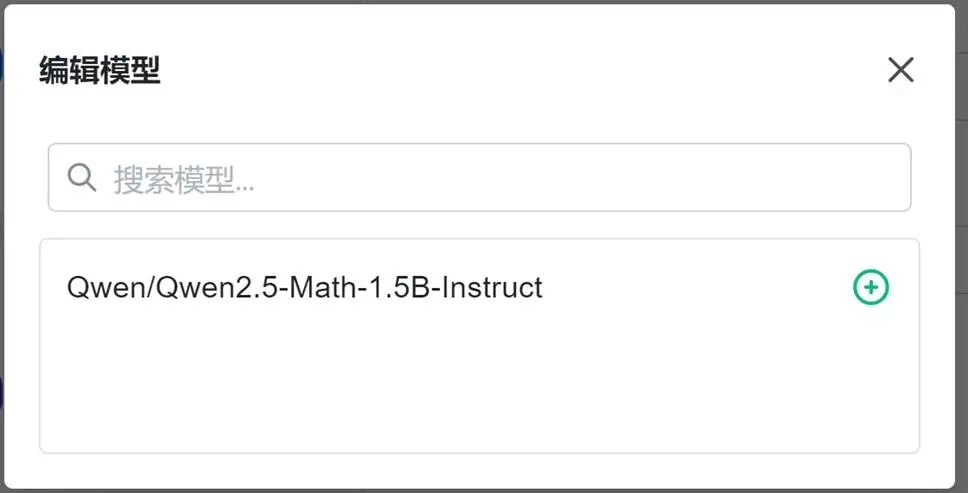
4. 選擇 vLLM 運行的模型,點擊“+”。
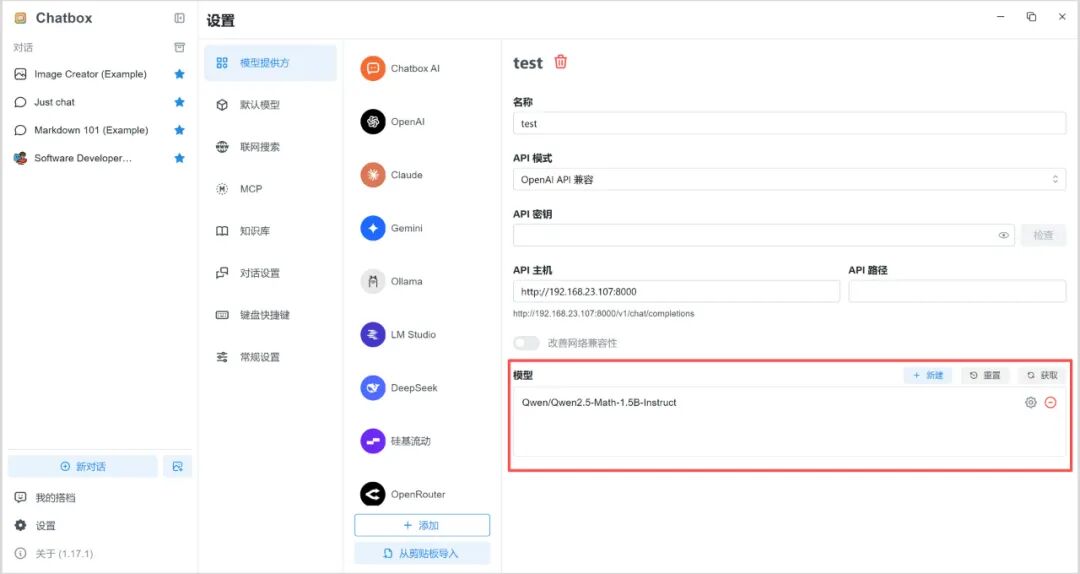
5. 點擊“新對話”,右下角選擇該模型即可開啟對話。
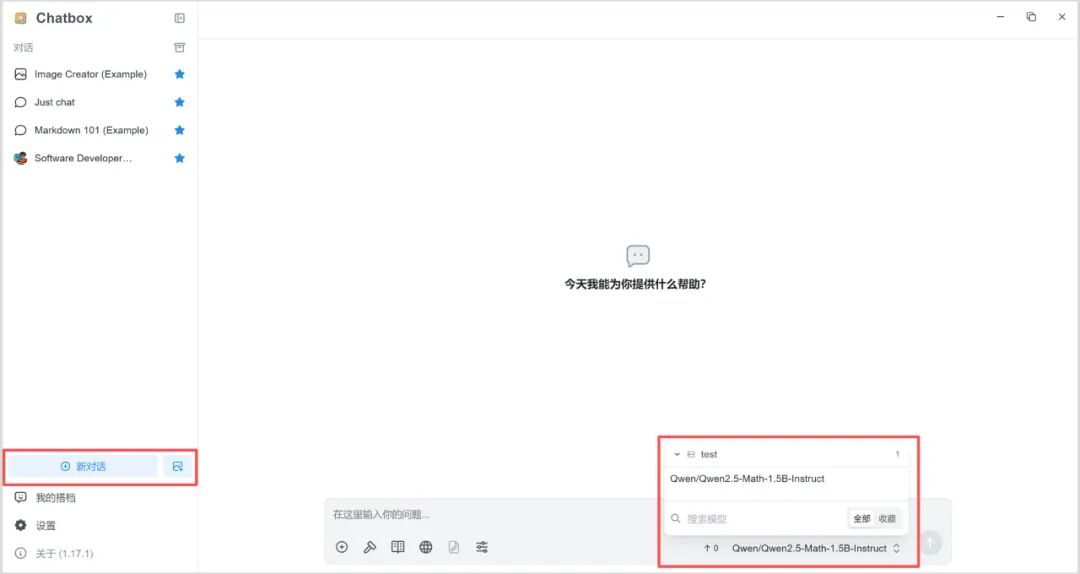
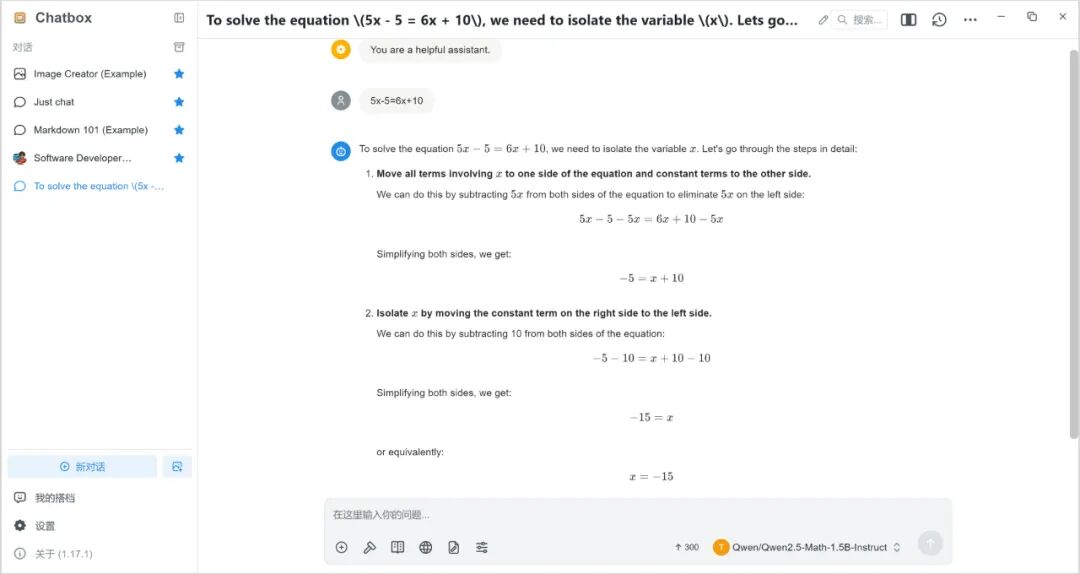
6. 運行示例
由于 Qwen2.5-Math 是一款數(shù)學專項大語言模型,我們在此示例提問一個數(shù)學問題,運行結(jié)果如下:
更多精彩教程,敬請期待!
-
NVIDIA
+關注
關注
14文章
5513瀏覽量
109200 -
模型
+關注
關注
1文章
3658瀏覽量
51804 -
開發(fā)環(huán)境
+關注
關注
1文章
254瀏覽量
17562 -
Docker
+關注
關注
0文章
527瀏覽量
14062
原文標題:輕松部署!在 NVIDIA Jetson AGX Thor 上使用 Docker 部署 vLLM 推理服務
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
NVIDIA Jetson AGX Thor Developer Kit開發(fā)環(huán)境配置指南
京東和美團已選用NVIDIA Jetson AGX Xavier 平臺
NVIDIA Jetson介紹
怎么做才能通過Jetson Xavier AGX構(gòu)建android圖像呢?
NVIDIA Jetson AGX Orin提升邊緣AI標桿
使用NVIDIA Jetson AGX Xavier部署新的自主機器
NVIDIA 推出 Jetson AGX Orin 工業(yè)級模塊助力邊緣 AI
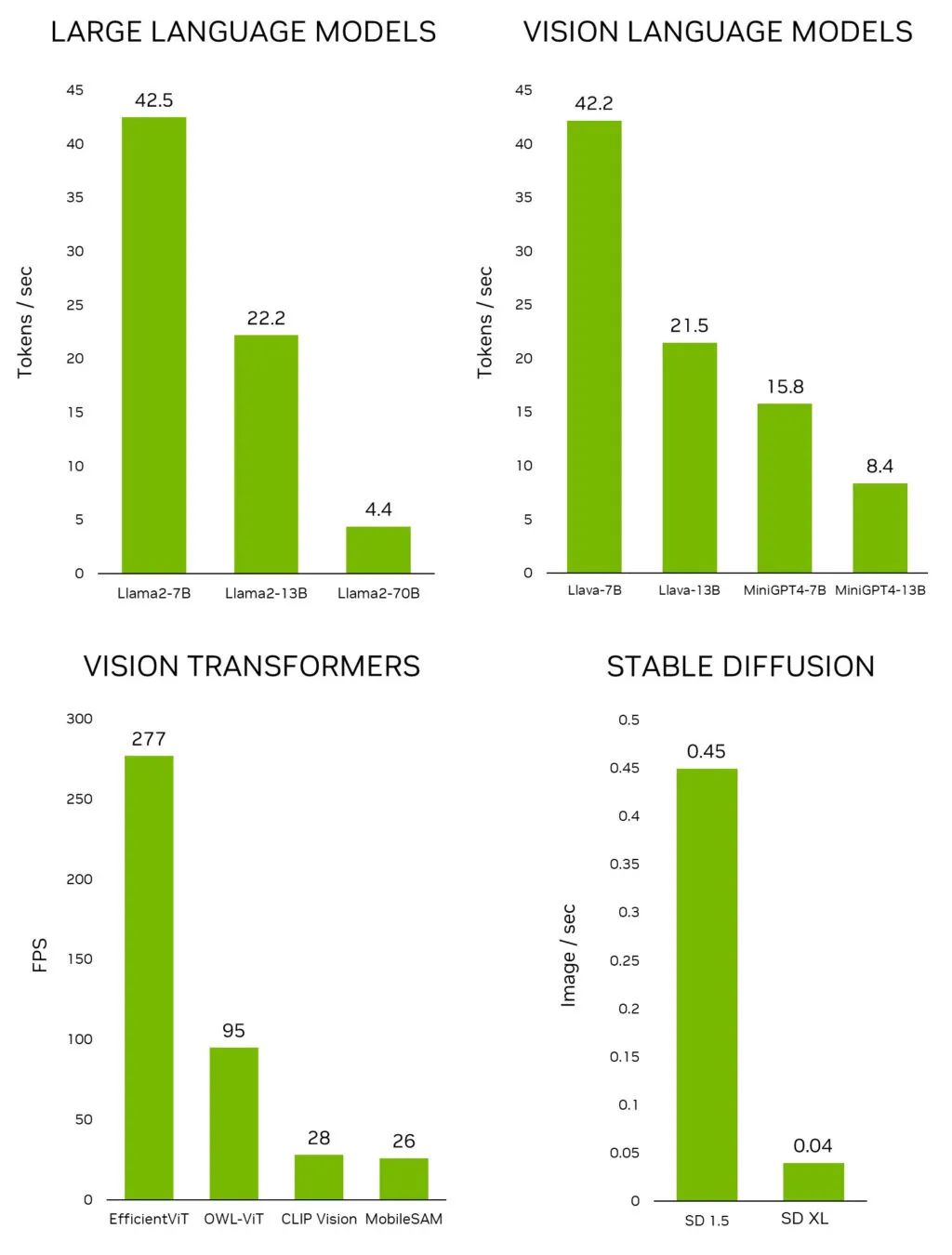
利用 NVIDIA Jetson 實現(xiàn)生成式 AI
NVIDIA Jetson AGX Thor開發(fā)者套件概述
基于 NVIDIA Blackwell 的 Jetson Thor 現(xiàn)已發(fā)售,加速通用機器人時代的到來






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論