 NVIDIA Nemotron Nano 2推理模型發布
NVIDIA Nemotron Nano 2推理模型發布

NVIDIA 正式推出準確、高效的混合 Mamba-Transformer 推理模型系列NVIDIA Nemotron Nano 2。
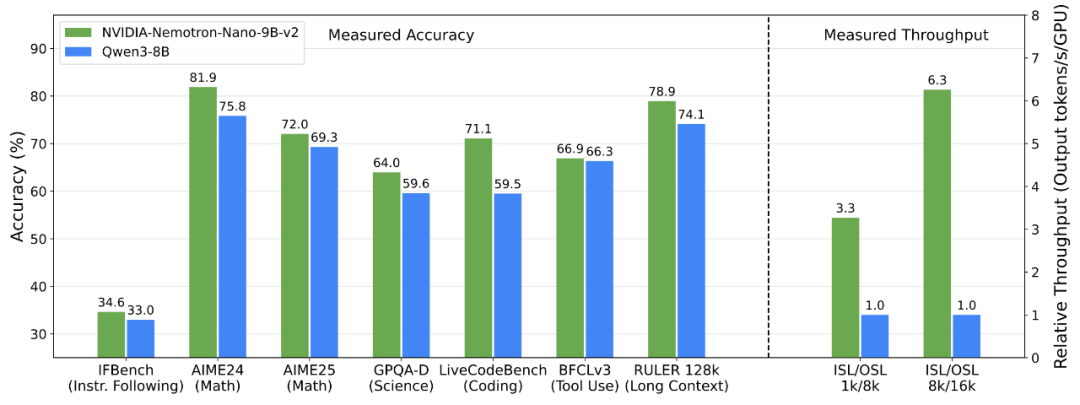
*圖中,ISL 與 OSL 分別代表輸入和輸出序列長度,吞吐量數據均在單顆 NVIDIA GPU 上以 bfloat16 精度測得。
如“NVIDIA Nemotron Nano 2:準確、高效的混合 Mamba-Transformer 推理模型”技術報告所示,推理模型 NVIDIA-Nemotron-Nano-v2-9B 在復雜推理基準測試中,實現了與領先的同規模開源模型 Qwen3-8B 相當乃至更佳的準確率,吞吐量較后者至高提升6倍。
我們在 Hugging Face 上發布了以下三個模型,它們均支持 128K 上下文長度:
NVIDIA-Nemotron-Nano-9B-v2:經過對齊和剪枝的推理模型
NVIDIA-Nemotron-Nano-9B-v2-Base:經過剪枝的基礎模型
NVIDIA-Nemotron-Nano-12B-v2-Base:未經過對齊或剪枝的基礎模型
數據集
此外,作為行業領先開源模型的首次嘗試,我們公開了在預訓練中使用的大部分數據。
Nemotron-Pre-Training-Dataset-v1 數據集包含6.6萬億個 Token,涵蓋高質量網絡爬取、數學、代碼、SFT 和多語言問答數據,分為以下四個類別:
Nemotron-CC-v2:基于 Nemotron-CC(Su 等人,2025 年)的后續版本,新增了 2024 至 2025 年間的八個 Common Crawl 快照數據集。數據集經過整體去重處理,并使用 Qwen3-30B-A3B 對其進行了合成重述。此外,該數據集還包含15 種語言的合成多樣化問答,可支持強大的多語言邏輯推理和通用知識預訓練。
Nemotron-CC-Math-v1:一個以數學為重點的數據集,包含1,330 億個 Token。該數據集使用NVIDIALynx + LLM 管線從 Common Crawl 中提取數據,在保留方程和代碼格式的同時,將數學內容統一標準化為 LaTex 的編輯形式,確保了關鍵數學內容和代碼片段完整無損,生成的預訓練數據在基準測試中顯著優于現有數學數據集。
Nemotron-Pretraining-Code-v1:基于 GitHub 構建的大規模精選代碼數據集。該數據集經過多階段去重、許可證強制執行和啟發式質量檢查過濾,包含11 種編程語言的 LLM 生成代碼問答對。
Nemotron-Pretraining-SFT-v1:覆蓋STEM、學術、邏輯推理和多語言領域的合成生成數據集。該數據集包含復雜的多選題和解析題,這些問題源自高質量數學和科學素材、研究生級的學術文本以及經過指令微調的 SFT 數據(涵蓋數學、代碼、通用問答和邏輯推理任務)。
Nemotron-Pretraining-Dataset-sample:數據集的精簡采樣版本,包含10 個代表性子集,內容涵蓋高質量問答數據、專注于數學領域的提取內容、代碼元數據及 SFT 風格指令數據。
技術亮點
數據集的亮點包括:
Nemotron-CC-Math:通過文本瀏覽器 (Lynx) 渲染網頁并結合大語言模型 (phi-4) 進行后處理,首次實現在大規模網頁下正確保留各種數學格式的方程和代碼的處理流程(包括長尾格式)。相較于過去基于啟發式的方法,這是一次突破性改進。內部預訓練實驗表明,使用 Nemotron-CC-Math 數據集訓練的模型在 MATH 測試上較最強基線提升了 4.8 至 12.6 分,在 MBPP+ 代碼生成任務上提升了 4.6 至 14.3 分。
Nemotron-CC-v2:此前研究表明,從高質量英文網頁爬取數據生成的合成多樣化問答數據,能顯著提升大語言模型 (LLM) 通用能力(如 MMLU 等基準測試顯示)。在此基礎上,我們通過將此數據集翻譯成 15 種語言,把這一發現擴展到更多語言。消融實驗顯示,加入翻譯過的多樣化問答數據后,Global-MMLU 平均準確率比僅使用多語言 Common Crawl 數據提升了 10.0 分。
Nemotron-Pretraining-Code:除 1,751 億個高質量合成代碼數據 Token 外,我們還發布了元數據,使用戶能夠復現一個精心整理、寬松授權的代碼數據集(規模達 7,474 億 Token)。
模型的亮點包括:
預訓練階段:Nemotron-Nano-12B-v2-Base 采用Warmup-Stable-Decay 學習率調度器在 20 萬億個 Token 上以 FP8 精度進行預訓練。隨后,通過持續的預訓練長上下文擴展階段,可在不降低其他基準性能的情況下支持 128k 上下文長度。
后訓練階段:Nemotron Nano 2 通過監督式微調 (SFT)、組相對策略優化 (GRPO)、直接偏好優化 (DPO) 和基于人類反饋的強化學習 (RLHF) 進行后訓練。其中約 5% 的數據包含故意截斷的邏輯推演,使推理時能夠精細控制思考預算。
壓縮:最后,我們對基礎模型和對齊后的模型進行了壓縮,使其能夠在單顆 NVIDIA GPU(22 GiB 內存,bfloat16 精度)上實現 128k Token 上下文長度的推理。此結果通過擴展基于 Minitron 的壓縮策略以壓縮受約束的邏輯推理模型實現。
數據示例
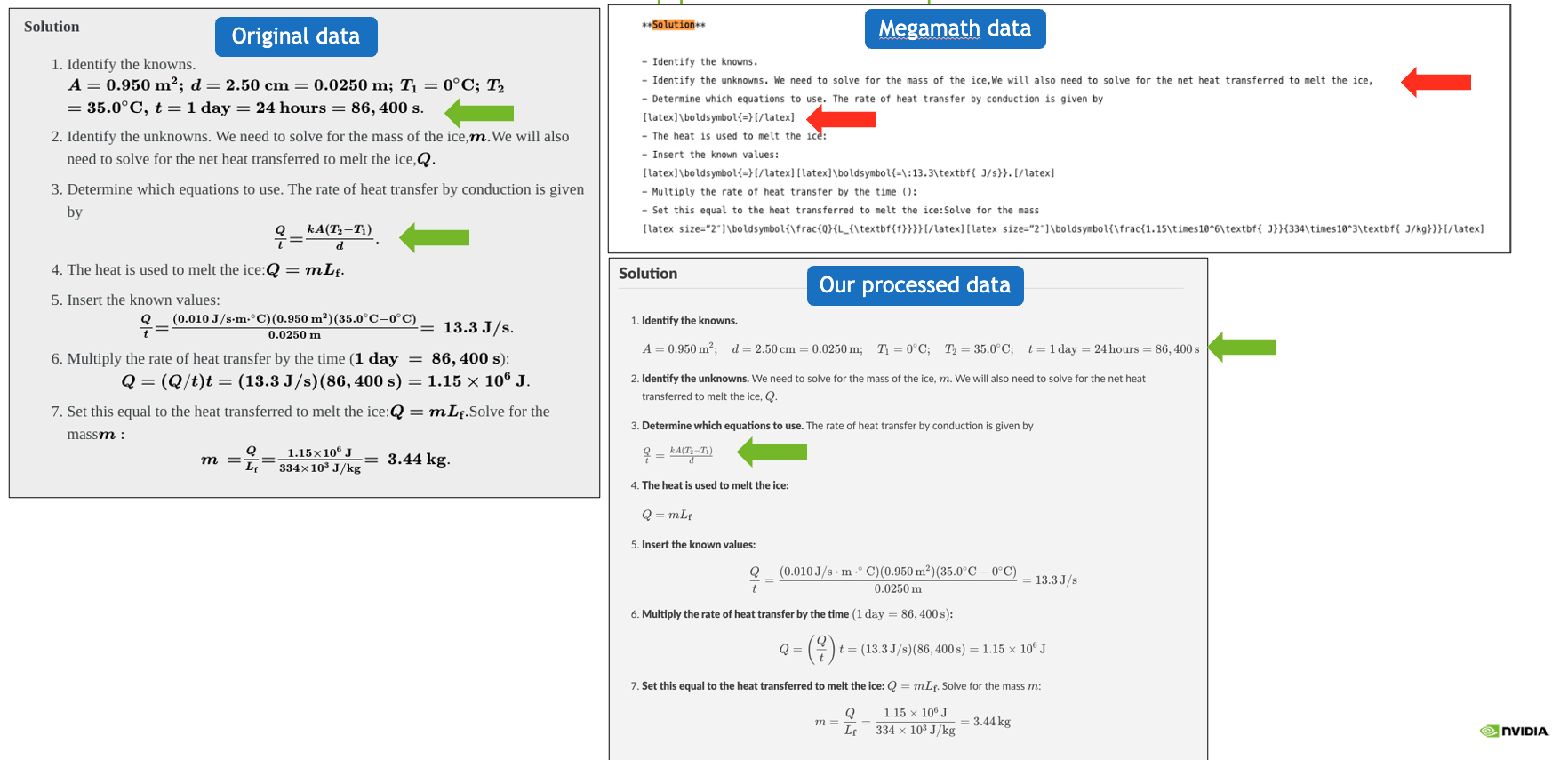
示例 1:我們的處理流程能夠同時保留數學公式和代碼,而之前的預訓練數據集通常會丟失或損壞數學公式。
引用
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano2: An AccurateandEfficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109716 -
gpu
+關注
關注
28文章
5194瀏覽量
135427 -
模型
+關注
關注
1文章
3751瀏覽量
52099 -
數據集
+關注
關注
4文章
1236瀏覽量
26189
原文標題:NVIDIA Nemotron Nano 2 及 Nemotron 預訓練數據集 v1
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
利用NVIDIA Nemotron開放模型構建智能文檔處理系統
商湯科技正式開源多模態自主推理模型SenseNova-MARS

阿里巴巴發布通義千問旗艦推理模型Qwen3-Max-Thinking

LLM推理模型是如何推理的?

NVIDIA 推出 Alpamayo 系列開源 AI 模型與工具,加速安全可靠的推理型輔助駕駛汽車開發

NVIDIA 推出 Nemotron 3 系列開放模型

NVIDIA推動面向數字與物理AI的開源模型發展
什么是AI模型的推理能力
澎峰科技完成OpenAI最新開源推理模型適配
利用NVIDIA推理模型構建AI智能體

企業使用NVIDIA NeMo微服務構建AI智能體平臺
詳解 LLM 推理模型的現狀

英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺




 工商網監
工商網監
評論