 如何去解決文本到圖像生成的跨模態對比損失問題?
如何去解決文本到圖像生成的跨模態對比損失問題?

Google提出了一個跨模態對比學習框架來訓練用于文本到圖像合成的 GAN 模型,用于研究解決生成的跨模態對比損失問題。
從文本到圖像的自動生成,如何訓練模型僅通過一段文本描述輸入就能生成具體的圖像,是一項非常具有挑戰性的任務。
與其它指導圖像創建的輸入類型相比,描述性句子是一種更直觀、更靈活的視覺概念表達方式。強大的自動文本到圖像的生成系統可以成為快速、有效的內容生產、制作工具,用于更多具有創造性的應用當中。
在CVPR 2021中,Google提出了一個跨模態對比生成對抗網絡(XMC-GAN),訓練用于文本到圖像合成的 GAN 模型,通過模態間與模態內的對比學習使圖像和文本之間的互信息最大化,解決文本到圖像生成的跨模態對比損失問題。
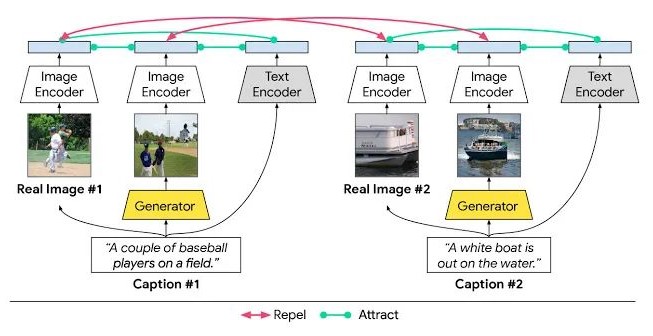
XMC-GAN 文本到圖像合成模型中的模態間和模態內對比學習
XMC-GAN 被成功應用于三個具有挑戰性的數據集:一個是MS-COCO 圖像描述集合,另外兩個是用Localized Narratives注釋的數據集,一個是包括MS-COCO 圖像(稱為LN-COCO) ,另一個描述開放圖像數據 (LN-OpenImages)。結果顯示 XMC-GAN生成圖像所描繪的場景相比于使用其它技術生成的圖像質量更高,在每個方面都達到了最先進的水平。
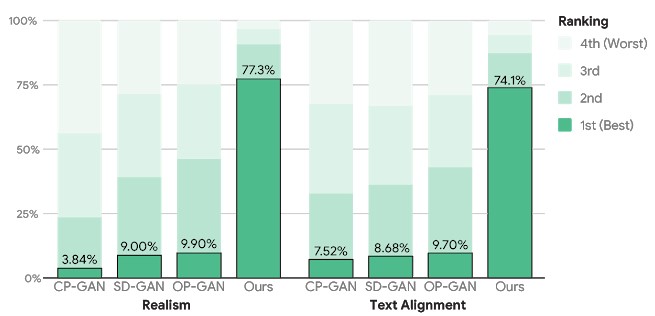
MS-COCO對圖像質量和文本對齊的人工評估
此外,XMC-GAN還在 LN-OpenImages 上進行了一系列訓練和評估,這相比于 MS-COCO 更具有挑戰性,由于數據集更大,圖像涵蓋主題范圍更加廣泛且復雜。
對于人類評估和定量指標,XMC-GAN 在多個數據集模型中相較之前有顯著的改進。可以生成與輸入描述非常匹配的高質量圖像,包括更長,更詳細的敘述,同時端到端模型的復雜度也相對較為簡單,這代表了從自然語言描述生成圖像的創造性應用的重大進步。
責任編輯:lq6
-
圖像
+關注
關注
2文章
1096瀏覽量
42326 -
GaN
+關注
關注
21文章
2366瀏覽量
82238
原文標題:XMC-GAN:從文本到圖像的跨模態對比學習
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
全球首個最大規模跨本體視觸覺多模態數據集白虎-VTouch發布
格靈深瞳多模態大模型Glint-ME讓圖文互搜更精準

亞馬遜云科技上線Amazon Nova多模態嵌入模型

米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
淺析多模態標注對大模型應用落地的重要性與標注實例
基于米爾瑞芯微RK3576開發板的Qwen2-VL-3B模型NPU多模態部署評測
中國科學院自動化研究所攜手中科曙光打造高性能工具鏈解決方案
無法使用OpenVINO?在 GPU 設備上運行穩定擴散文本到圖像的原因?
利用NVIDIA 3D引導生成式AI Blueprint控制圖像生成
如何使用離線工具od SPSDK生成完整圖像?
把樹莓派打造成識別文本的“神器”!

一種多模態駕駛場景生成框架UMGen介紹
端到端自動駕駛多模態軌跡生成方法GoalFlow解析

使用OpenVINO GenAI和LoRA適配器進行圖像生成



 工商網監
工商網監
評論