 格靈深瞳多模態大模型Glint-ME讓圖文互搜更精準
格靈深瞳多模態大模型Glint-ME讓圖文互搜更精準

在電商、安防等場景下,圖文互搜應用廣泛。隨著以CLIP為代表的多模態表征方法相繼提出,過去單一模態搜索(文搜文、圖搜圖)被突破,模型可以同時理解文本、圖像、音頻乃至視頻,實現跨模態檢索。
與此同時,CLIP框架也存在多種技術局限性。10月25日,在由DataFun技術社區策劃的DACon數智大會分論壇上,格靈深瞳技術副總裁、靈感實驗室負責人馮子勇博士分享專題演講:《多模態特征嵌入的數據生成和技術前沿》,介紹多模態基礎模型的應用場景、技術短板,以及靈感團隊的解題方法與技術細節——靈感圖文多模態表征模型系列(Glint-ME)。
“大模型前沿技術探索”分論壇現場
數據生成:豐富又優質的多模態表征數據
多模態模型訓練需文本和圖片成對出現,但現有數據文本質量不佳。為此,靈感團隊提出了一個多樣化描述生成框架,將Transformer的有效并行訓練與RNN的有效推理相結合,利用大型語言模型來精煉原始文本、合成字幕和檢測標簽等信息,以產生語義豐富的描述文本。
為解決訓練數據冗余的問題,靈感團隊提出了一種簡單但有效的圖像語義平衡方法,能夠在保持卓越性能的同時,從LAION 400M數據集中移除43.7%的圖像-文本對。
為挖掘現實中大量未配對的多模態數據,例如圖文交織的文檔,靈感團隊提出了一種有效且可擴展的多模態交錯文檔轉換范式,構建了RealSyn數據集,可以將此類數據用于CLIP預訓練。
團隊首先建立了一套真實數據提取流程,能夠從圖文交錯的文檔中提取高質量的圖像和文本。在此基礎上,構建了檢索增強生成框架,基于高質量的文本和圖片庫,為每一張圖片匹配現實文本和合成文本。
RealSyn數據集包含15M、30M、100M三個規模。大量實驗證明:RealSyn具有良好的數據縮放和模型縮放能力,相關數據、代碼和模型均已開源:
技術報告:
https://arxiv.org/abs/2502.12513
代碼:
https://github.com/deepglint/RealSyn
項目主頁:
https://garygutc.github.io/RealSyn/
數據集:
https://huggingface.co/datasets/Kaichengalex/RealSyn100M
多模態特征嵌入模型:更強大的跨模態表達能力
盡管最近的多模態大型語言模型(MLLMs)在通用視覺-語言理解方面取得了顯著進展,但在學習可遷移的多模態表征方面,潛力尚未充分發揮。
為此,靈感團隊提出了一個面向MLLMs的兩階段訓練框架UniME(Universal Multimodal Embedding,通用多模態嵌入),并優化迭代至V2版本——聚焦如何借助MLLMs強大的理解能力來助力統一多模態表征學習。
經過MMEB基準測試和在多個檢索任務(包括長短文本跨模態檢索和組合檢索)上的大量實驗,結果表明UniME-V2在多項任務中均實現了穩定的性能提升,展現了卓越的判別能力和組合理解能力。
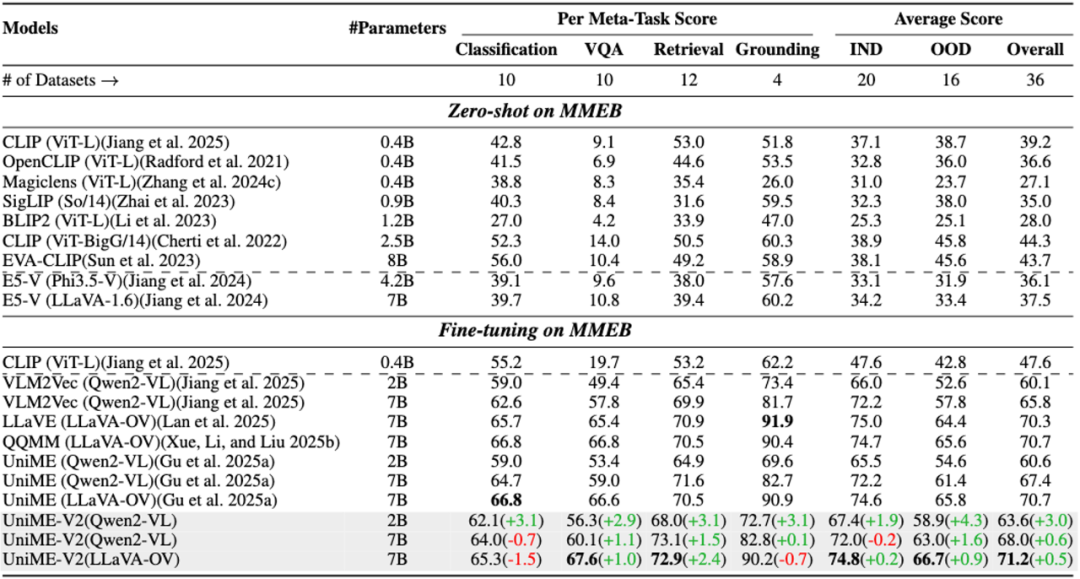
UniME-V2在MMEB Benchmark的表現
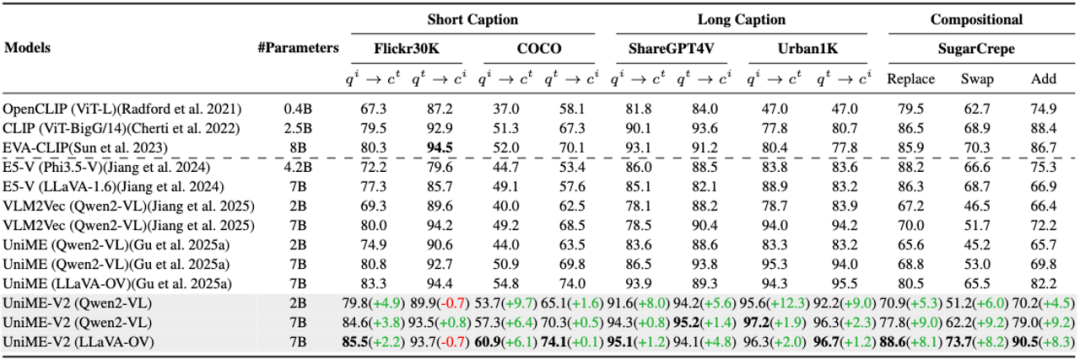
UniME-V2在長短文本跨模態檢索和組合檢索上優于UniME-V1和其他模型
UniME系列論文、代碼、權重均已開源:
UniME-V1
技術報告:
https://arxiv.org/abs/2504.17432
代碼:
https://github.com/deepglint/UniME
模型:
https://huggingface.co/DeepGlint-AI/UniME-LLaVA-OneVision-7B
項目主頁:
https://garygutc.github.io/UniME/
UniME-V2
技術報告:
https://arxiv.org/abs/2504.17432
代碼:
https://github.com/GaryGuTC/UniME-v2
模型:
https://huggingface.co/collections/TianchengGu/unime-v2-68ef708ac48066353b4a0806
項目主頁:
https://garygutc.github.io/UniME-v2/
近期,靈感實驗室聯合LMMs-Lab發布了全流程開源的多模態大模型LLaVA-OneVision-1.5,復現路徑清晰,8B模型預訓練只需4天、1.6萬美元。
LLaVA-OneVision-1.5
技術報告:
https://arxiv.org/abs/2509.23661
代碼:
https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
模型:
https://huggingface.co/lmms-lab/LLaVA-OneVision-1.5-8B-Instruct
Demo:
https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
數據集:
Pretrain Data:https://huggingface.co/datasets/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
Instruct Data:https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-1.5-Insturct-Data
未來,靈感實驗室將持續聚焦視覺及多模態特征表達與應用,推動多模態技術在多元化應用場景的落地與創新。歡迎關注團隊的最新技術進展。
-
格靈深瞳
+關注
關注
1文章
94瀏覽量
6004 -
大模型
+關注
關注
2文章
3726瀏覽量
5257
原文標題:AI 如何學會“看圖說話”?多模態大模型 Glint-ME 讓圖文互搜更精準 | Glint Tech
文章出處:【微信號:shentongzhineng,微信公眾號:格靈深瞳】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
格靈深瞳亮相2026 ITES深圳工業展
格靈深瞳聯合氪信科技推出多模態AI金融安全一體機
格靈深瞳邀您相約百度世界2025大會
格靈深瞳與奧瑞德達成戰略合作
格靈深瞳視覺基礎模型Glint-MVT的發展脈絡



 工商網監
工商網監
評論