 電子發燒友App
電子發燒友App



作者簡介:Vlad Shimanskiy是Qualcomm公司GPU計算解決方案團隊的高級工程師。他一直致力于開發和原型設計Snapdragon上OpenCL 2.x新的標準特性,改進Adreno GPU架構,用于計算和加速重要線性代數算法,包括GPU上的矩陣乘法。
由于近來依賴于卷積的深度學習引起廣泛關注,矩陣乘法(MM)運算也在GPU上變得流行起來。我們也收到開發人員的反饋,希望利用配備Adreno?GPU的Qualcomm?Snapdragon?處理器加速深度學習(DL)應用。
本文由我們Adreno工程師Vladislav Shimanskiy撰寫,分為兩個部分。本篇文章中的概念和下一篇文章中的OpenCL代碼清單,表示Adreno 4xx和5xx GPU系列設備端矩陣乘法內核函數和主機端參考代碼的優化實現。我們希望本系列文章將幫助和鼓勵您使用這些想法和代碼示例寫出自己的OpenCL代碼。
像Adreno GPU這樣的并行計算處理器是加速線性代數運算的理想選擇。然而,MM算法在密集并行問題中具有其獨特性,因為它需要在各個計算工作項之間共享大量的數據。在要相乘的矩陣中,例如A和B,每個元素對結果矩陣C的不同分量貢獻多次。因此,為Adreno優化MM算法需要我們利用GPU內存子系統。
關于GPU 上的矩陣乘法存在哪些困難?
當我們嘗試在GPU上加速MM時,上面提到的數據共享問題又可以拆分為幾個相關問題:
- MM對相同的值進行重復運算,但是矩陣越大,越有可能必須到內存中讀取(緩慢)已有值替換緩存中的值,這樣做效率低下。
- 在MM的簡單實現中,很自然的將標量矩陣元素映射到單獨的工作項。但是,讀寫標量的效率很低,因為GPU上的存儲器子系統和算術邏輯單元(ALU)被優化用于向量運算。
- 同時加載大矩陣A和B的元素有可能導致緩存沖突和存儲器總線爭用的風險。
- 內存復制很慢,因此我們需要找到一個更好的方法,使數據對CPU和GPU同時可見。
這些問題使MM的主要任務復雜化,即多次讀取相同的值并共享數據。
矩陣乘法的OpenCL 優化技術
我們詳細說明了一個OpenCL實現,其中包括解決每個問題的技術。
1. 平鋪(Tiling)
第一個眾所周知的問題是將從內存(比如高級緩層或DDR)中重復緩慢讀取相同矩陣元素的次數降到最低。我們必須嘗試對內存訪問(讀取和寫入)進行分組,以使它們在地址空間彼此接近。
我們改進數據重用的技術是將輸入和輸出矩陣拆分為稱為tile的子矩陣。然后,我們強制執行內存運算指令,使得矩陣乘法得到的點積在整個tile中部分完成,之后我們將讀取指針移動到tile邊界之外。
我們的算法確認兩個層次的平鋪:micro-tile和macro-tile。下圖表示如何映射矩陣,使矩陣A中的分量乘以矩陣B中的分量,得到矩陣C中的單點積:
圖1:平鋪
micro-tile——{dx,dy}是矩陣內的矩形區域,由內核函數單個工作項處理。每個工作項是SIMD子組中的單線程,反過來又形成OpenCL工作組。通常,micro-tile擁有4×8 = 32個分量,稱之為像素(pixel)。
macro-tile——{wg_size_x,wg_size_y},通常是由一個或多個micro-tile組成并且對應于工作組的更大矩形區域。在工作組中,我們完全在macro-tile范圍內運算。
要計算矩陣C中的4×8micro-tile,我們將重點放在矩陣A和B中分別擁有4×8和4×4大小的區域。我們從pos = 0開始,計算部分結果或點積,并將其存儲在該micro-tile臨時緩沖區。同時,相同macro-tile中的其他工作項使用從矩陣A或矩陣B加載的相同數據并行計算部分結果。矩陣A行中所有數據被共享。同樣,矩陣B的列中所有數據在同一列的工作項之間共享。
我們計算macro-tile中的所有micro-tile的部分結果,然后在A中水平地增加pos,同時在B中垂直地增加pos。通過進行針對tile的計算并使pos逐漸遞增,我們可以最大程度地重復利用緩存中的已有數據。micro-tile繼續積累或卷積部分結果,將其增加到點積。
所以,在macro-tile內的所有位置完成所有的部分計算后,我們才移動位置。我們可以完成整個micro-tile,從左到右和從上到下移動pos,然后前進,但是這樣做效率不高,因為我們需要的相同數據已經被緩存清除。關鍵是我們在一個由工作組限制的區域工作,有若干工作項目在同時運行。此方法保證來自并行工作項的所有內存請求均在有邊界的地址區域內發出。
平鋪(Tiling)通過專注于內存中的特定區域(工作組)來優化運算,這樣,我們可以以緩存友好的方式進行工作。與跨越大塊內存、必須到DDR中讀取不再存于緩存中的值相比,效率得到了極大的提升。
2. 矢量化
由于內存子系統在硬件層面為矢量運算進行過優化,所以最好使用數據向量而不是標量來運算,并且使每個工作項處理一個micro-tile和一個全矢量。因此,我們可以使用每次向量讀取操作時獲得的所有值。
例如,在32位浮點矩陣的情況下,我們的內核函數使用float4類型的矢量,而不僅僅是一個浮點類型。這樣,如果我們想從矩陣中讀取一些東西,我們不僅讀取矩陣的單個浮點分量,而且讀取整個數據塊。這一點很重要,因為它同總線設計方式是一致的。因此我們從矩陣中讀取4個元素的分量,并使內存帶寬飽和。相應地,micro-tile 的大小均為4的倍數。
如果我們在CPU上工作,我們可能一次讀取一個2-D數組一個標量元素,但GPU上的OpenCL提供了更好的方法。為使讀寫更加高效,我們使用數據類型float4或float4的倍數變量進行操作。
3. 紋理管道( Texture Pipe)
兩個矩陣使用獨立緩存(L2 direct和Texture Pipe / L1),如下圖所示,允許我們避免大多數爭用和并行讀取操作,以便矩陣A和矩陣B的數據在同一時間得到加載。涉及L1有助于大大減少到L2的讀取流量。
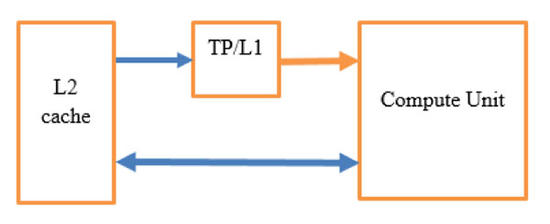
圖2:紋理管道(Texture Pipe)
Adreno和許多其他GPU一樣,每個計算單元具??有到紋理管道(TP)單元的獨立連接。TP具有其自己的L1緩存,并獨立連接到L2緩存。
我們增加帶寬的技巧是通過TP加載一個矩陣,通過直接加載/存儲管道加載另一個矩陣。因為我們在矩陣乘法中重用了這么多的分量,所以我們還獲得了L1緩存的優勢。最終,從TP/L1到計算單元的流量遠高于從L2到L1的流量。該區塊顯著降低了流量。如果不利用TP,只是連接到L2,就不會有太大幫助,因為在兩個總線之間有很多爭用和仲裁。
結果導致直接連接上產生大量流量,而從TP/L1到L2流量卻很少。這有助于我們增加總內存帶寬,平衡ALU運算,實現更高的性能。我們等待數據從緩存返回的時間幾乎和ALU運算相同,我們可以對其采用管道化方式,使它們不致成為瓶頸。
4. 內存復制預防
我們的OpenCL實現有兩個部分:運行在GPU上的內核函數和運行在CPU上的主機代碼,并由主機代碼控制內核函數的執行。如果我們實現一個GPU加速庫(如BLAS)來做矩陣乘法,那么輸入矩陣將在CPU虛擬內存空間,并且乘法結果也必須在CPU內存中可用。為了加速GPU上的矩陣乘法,矩陣必須首先被傳輸到GPU內存。
傳統方法是將矩陣復制到GPU地址空間,讓GPU執行其計算,然后再將結果復制回CPU。但是,復制大矩陣所需的時間可能抵得上在GPU上總的計算時間,因此,我們希望避免使用低效率的CPU內存復制。Adreno GPU具有共享Snapdragon處理器內存硬件的優勢,我們可以加以利用,而不是顯式復制內存。
那么,為什么不簡單地分配在CPU和GPU之間自動共享的內存?可惜,這樣并不可行,因為我們需要解決諸如對齊等等限制。只有使用OpenCL驅動程序例程正確完成分配,才能使用共享內存。
結果
下圖顯示了Adreno各版本單精度一般矩陣乘法(SGEMM)的性能提升:
圖3:Adreno GPU 4xx和530的性能數據
該圖基于常用浮點運算數據。使用不同數據類型(8位、16位、固定點等)的其他MM內核函數可以根據我們在SGEMM采用的相同原理進行有效實現。
一般來說,我們對Adreno GPU優化的MM實現比簡單實現至少快兩個數量級。
接下來?
在下一篇文章中,我將給出這些概念背后的OpenCL代碼清單。
矩陣乘法是卷積神經網絡中一個重要的基本線性代數運算。尤其是DL算法性能與MM相關,因為DL卷積的所有變化均可以簡化為乘法矩陣。
上面描述的概念和您在下一篇文章中看到的代碼并不是計算卷積的唯一方法。但事實上,很多流行的DL框架,比如Caffe,Theano和谷歌的TensorFlow往往將卷積運算分解為MM,因此沿著這個方向思考不失為一個好辦法。敬請關注第2部分中的代碼示例。
相關閱讀:
Qualcomm Adreno GPU 如何獲得更好的OpenCL性能——內存優化篇
經驗分享:Silk Labs 如何以極低的成本,獲得軟硬件開發資源
如何開始使用Adreno SDK for Vulkan
Vulkan開發系列視頻教程
更多Qualcomm開發內容請詳見: Qualcomm開發者社區?。






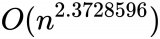

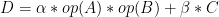




 工商網監
工商網監
評論