推薦語: 近期,代碼的大型語言模型 (LM)在完成代碼和從自然語言描述合成代碼方面顯示出巨大的潛力。然而,當前最先進的代碼 LM(例如 Codex (Chen et al., 2021))尚未
2022-08-16 15:46:16 2709
2709 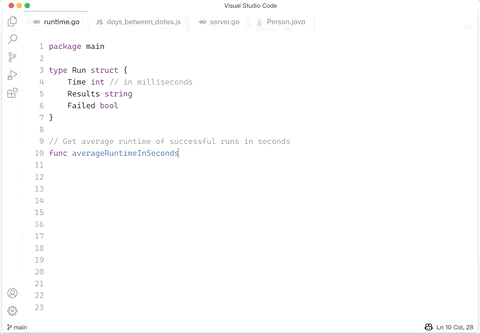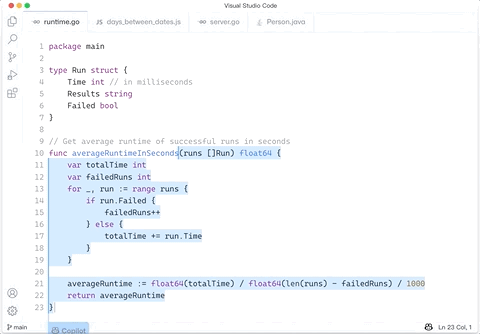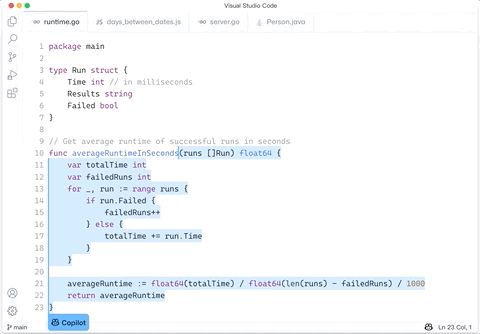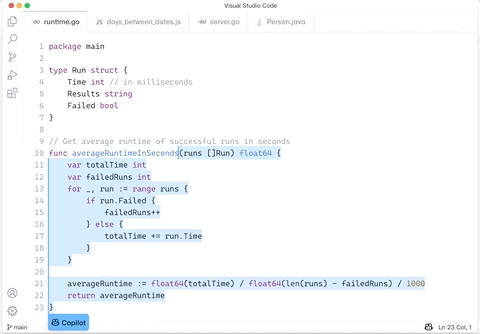
將模型稱為 “視覺語言” 模型是什么意思?一個結(jié)合了視覺和語言模態(tài)的模型?但這到底是什么意思呢?
2023-03-03 09:49:371578 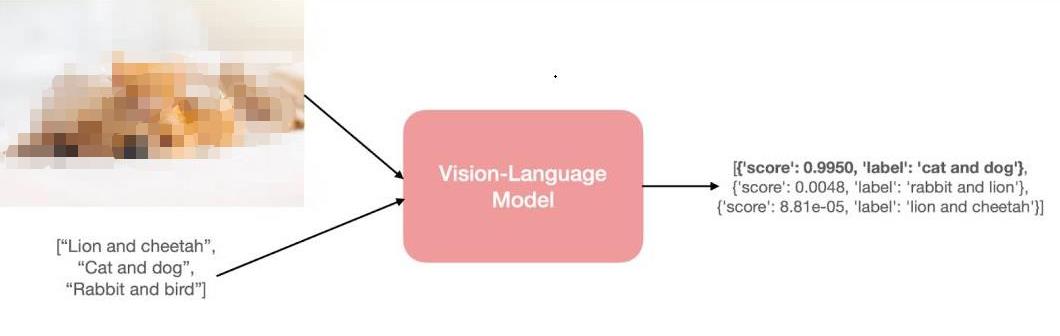
熟悉愛芯通元NPU的網(wǎng)友很清楚,從去年開始我們在端側(cè)多模態(tài)大模型適配上一直處于主動緊跟的節(jié)奏。先后適配了國內(nèi)最早開源的多模態(tài)大模MiniCPM V 2.0,上海人工智能實驗室的書生多模態(tài)大模型
2025-04-21 10:56:462691 
新階段,此次發(fā)布的一系列成果包括“悟道·天鷹”(Aquila)語言大模型系列、天秤(FlagEval)開源大模型評測體系與開放平臺、“悟道 · 視界”視覺大模型系列,以及一系列多模態(tài)模型成果。 ? 悟道3.0 全面開源意味著什么 ? 悟道·天鷹語言大模型是首
2023-06-14 00:06:002753 
。 ? 2023年,大語言模型及其在人工智能領(lǐng)域的應用已然成為全球科技研究的熱點,其在規(guī)模上的增長尤為引人注目,參數(shù)量已從最初的十幾億躍升到如今的一萬億。參數(shù)量的提升使得模型能夠更加精細地捕捉人類語言微妙之處,更加深入地理解人類語
2024-01-02 09:28:334637 有沒有開源的Labview(類似的圖形語言),而且跨平臺的???
2013-11-03 10:40:36
1、ollama平臺搭建
ollama可以快速地部署開源大模型,網(wǎng)址為https://ollama.com, 試用該平臺,可以在多平臺上部署 Deepseek-R1, Qwen3, Llama
2025-07-19 15:45:24
上周收到《大語言模型應用指南》一書,非常高興,但工作項目繁忙,今天才品鑒體驗,感謝作者編寫了一部內(nèi)容豐富、理論應用相結(jié)合、印刷精美的著作,也感謝電子發(fā)燒友論壇提供了一個讓我了解大語言模型和機器學習
2024-07-21 13:35:17
的信息,提供更全面的上下文理解。這使得模型能夠更準確地理解復雜問題中的多個層面和隱含意義。
2. 語義分析
模型通過訓練學習到語言的語義特征,能夠識別文本中的命名實體、句法結(jié)構(gòu)和語義關(guān)系等信息。這些
2024-08-02 11:03:41
向量可以隨著任務更新、調(diào)整。這類語言模型一般分為靜態(tài)詞向量語言模型(如Word2vec、GloVe)和動態(tài)詞向量語言模型(如ELMo、GPT、BERT)。靜態(tài)詞向量語言模型中每個詞學到的詞向量是靜態(tài)
2024-05-05 12:17:03
類任務上表現(xiàn)出色,甚至在零樣本條件下也能取得良好效果。另一類則需要逐步推理才能完成的任務,類似于人類的系統(tǒng)2,如數(shù)字推理等。然而,隨著參數(shù)量的增加,大語言模型在這類任務上并未出現(xiàn)質(zhì)的飛躍,除非有精心
2024-05-07 17:21:45
地提升工作效率。大語言模型的代碼類評測任務包括:1)代碼生成評估,如生成逆轉(zhuǎn)字符串的Python函數(shù);2)代碼糾錯評估,如識別并修正JavaScript代碼中的錯誤;3)代碼解釋評估,如解釋冒泡排序算法
2024-05-07 17:12:40
大語言模型的核心特點在于其龐大的參數(shù)量,這賦予了模型強大的學習容量,使其無需依賴微調(diào)即可適應各種下游任務,而更傾向于培養(yǎng)通用的處理能力。然而,隨著學習容量的增加,對預訓練數(shù)據(jù)的需求也相應
2024-05-07 17:10:27
《大語言模型》是一本深入探討人工智能領(lǐng)域中語言模型的著作。作者通過對語言模型的基本概念、基礎(chǔ)技術(shù)、應用場景分析,為讀者揭開了這一領(lǐng)域的神秘面紗。本書不僅深入討論了語言模型的理論基礎(chǔ),還涉及自然語言
2024-04-30 15:35:24
《大語言模型“原理與工程實踐”》是關(guān)于大語言模型內(nèi)在機理和應用實踐的一次深入探索。作者不僅深入討論了理論,還提供了豐富的實踐案例,幫助讀者理解如何將理論知識應用于解決實際問題。書中的案例分析有助于
2024-05-07 10:30:50
的進步,大語言模型的應用范圍和影響力將持續(xù)擴大,成為AI領(lǐng)域的重要推動力。其中,GPT系列模型的發(fā)展尤為引人注目,從GPT到GPT-2,再到如今的GPT-4,其創(chuàng)新速度和影響力不斷攀升。這些模型采用
2024-05-04 23:55:44
請問有沒有大佬知道labview支不支持越南語語言啊,我開了unicode輸入越南語還是會亂碼,可以顯示出越南語但是輸入到具體結(jié)構(gòu)里面就會亂碼。請問有大佬知道怎么解決嗎
2022-09-27 15:57:29
前言
深度學習是機器學習的分支,而大語言模型是深度學習的分支。機器學習的核心是讓計算機系統(tǒng)通過對數(shù)據(jù)的學習提高性能,深度學習則是通過創(chuàng)建人工神經(jīng)網(wǎng)絡處理數(shù)據(jù)。近年人工神經(jīng)網(wǎng)絡高速發(fā)展,引發(fā)深度學習
2024-05-13 00:09:37
種語言模型進行預訓練,此處預訓練為自然語言處理領(lǐng)域的里程碑
分詞技術(shù)(Tokenization)
Word粒度:我/賊/喜歡/看/大語言模型
character粒度:我/賊/喜/歡/看/大/語/言
2024-05-12 23:57:34
自然語言處理——53 語言模型(數(shù)據(jù)平滑)
2020-04-16 11:11:25
C語言2.0
2006-04-08 02:04:16 54
54 模型動力電學實驗室2.0
2006-04-10 21:36:5352 唇語識別中的話題相關(guān)語言模型研究_王淵
2017-03-19 11:28:160 自然語言處理常用模型使用方法一、N元模型二、馬爾可夫模型以及隱馬爾可夫模型及目前常用的自然語言處理開源項目/開發(fā)包有哪些?
2017-12-28 15:42:306424 
華為鴻蒙操作系統(tǒng)(Harmony OS 2.0)已于2020年9月10日在華為開發(fā)者大會上正式發(fā)布和對外開源了,這意味著開發(fā)者可以拿到Harmony OS 2.0的源代碼了。雖然已經(jīng)離開源發(fā)布有整整
2020-10-26 14:23:437508 ,對詞級粒度、詞干級粒度、最大詞干級粒度、詞干詞綴級粒度、詞干-詞尾級粒度的漢維平行語料庫進行對比實驗,研究不同粒度的維吾爾語對漢維機器翻譯中的詞語對齊質(zhì)量和語言模型質(zhì)量的影響。實驗結(jié)果表明,在上述5種粒度的維
2021-05-11 15:34:119 Intelligent Technology – VIT)基于最先進的深度學習和語音識別技術(shù),是一款完整的喚醒詞/語音命令解決方案。 VIT在MCUXpresso SDK中支持的恩智浦設備上免費提供,目前已經(jīng)可以支持英語,而中文、土耳其語、西班牙語等其他語言也正如火如荼地開發(fā)測試當中。 VIT功能包括 喚醒詞引擎
2021-05-18 14:31:213052 
OpenHarmony 2.0 Canary代碼托管平臺已經(jīng)上線 gitee 開源,OpenHarmony是華為自主研發(fā)、不兼容安卓的全領(lǐng)域下一代開源操作系統(tǒng)。 開放原子開源基金會(以下簡稱“基金會
2021-06-22 09:58:512858 阿布扎比先進技術(shù)研究委員會旗下的全球研究中心和應用研究支柱部門技術(shù)創(chuàng)新研究所(TII)今天宣布推出NOOR語言處理模型,這是迄今為止全球規(guī)模居首的阿拉伯語自然語言處理(NLP)模型。
2022-04-12 11:53:562380 電子發(fā)燒友網(wǎng)站提供《外置BFO V2.0通孔版開源分享.zip》資料免費下載
2022-07-25 09:21:280 電子發(fā)燒友網(wǎng)站提供《HHKB Lite 2 Teensy 2.0控制器開源.zip》資料免費下載
2022-07-28 11:53:131 電子發(fā)燒友網(wǎng)站提供《DIY PCB BassWasp HAT 2.0開源分享.zip》資料免費下載
2022-08-22 14:23:521 諸如 NVIDIA Megatron LM 和 OpenAI GPT-2 和 GPT-3 等語言模型已被用于提高人類生產(chǎn)力和創(chuàng)造力。具體而言,這些模型已被用作編寫、編程和繪制的強大工具。相同的架構(gòu)
2022-10-11 09:32:281532 
電子發(fā)燒友網(wǎng)站提供《編輯機器人2.0開源分享.zip》資料免費下載
2022-10-20 14:21:000 電子發(fā)燒友網(wǎng)站提供《監(jiān)測植物的壓力2.0開源分享.zip》資料免費下載
2022-11-02 11:06:150 電子發(fā)燒友網(wǎng)站提供《孟加拉語語音識別開源分享.zip》資料免費下載
2022-11-02 15:06:290 電子發(fā)燒友網(wǎng)站提供《REEE機器v2.0開源分享.zip》資料免費下載
2022-11-10 11:21:570 BigCode 是一個開放的科學合作組織,致力于開發(fā)大型語言模型。近日他們開源了一個名為 SantaCoder 的語言模型,該模型擁有 11 億個參數(shù)
2023-01-17 14:29:531365 “大數(shù)據(jù)+大算力+強算法=大模型”是當前人工智能發(fā)展的主要技術(shù)路徑。語言大模型ChatGPT成為現(xiàn)象級應用,人工智能進入普及應用的新時期。 智源研究院2020年搭建大模型攻關(guān)團隊,2021年6月推出
2023-03-01 15:10:071344 Dolly 2.0 是一個基于 EleutherAI pythia 模型系列的 12B 參數(shù)語言模型,并在透明且免費提供的數(shù)據(jù)集上進行了微調(diào);該數(shù)據(jù)集稱為 databricks-dolly-15k,也已開源發(fā)布。
2023-04-14 09:33:122358 在針對英語、中文、法語、阿拉伯語、西班牙語、印度語這 6 種語言的評測中,GPT-4 的勝率為 54.75%,BLOOMChat 的勝率為 45.25%,稍弱于 GPT-4。但與其它 4 種主流的開源聊天 LLM 相比
2023-05-25 11:14:401647 
為推動大模型在產(chǎn)業(yè)落地和技術(shù)創(chuàng)新,智源研究院發(fā)布“開源商用許可語言大模型系列+開放評測平臺” 2 大重磅成果,打造“大模型進化流水線”,持續(xù)迭代、持續(xù)開源開放。 01 悟道·天鷹(Aquila
2023-06-27 16:37:27867 ?? 大型語言模型(LLM) 是一種深度學習算法,可以通過大規(guī)模數(shù)據(jù)集訓練來學習識別、總結(jié)、翻譯、預測和生成文本及其他內(nèi)容。大語言模型(LLM)代表著 AI 領(lǐng)域的重大進步,并有望通過習得的知識改變
2023-07-05 10:27:352808 簡單來說,語言模型能夠以某種方式生成文本。它的應用十分廣泛,例如,可以用語言模型進行情感分析、標記有害內(nèi)容、回答問題、概述文檔等等。但理論上,語言模型的潛力遠超以上常見任務。
2023-07-14 11:45:401398 
大模型技術(shù)和工業(yè)實踐。會議還匯聚了騰訊AI Lab、百度等科技企業(yè),學術(shù)界和工業(yè)界的研究學者與從業(yè)人員,分享各自研究成果和實踐經(jīng)驗,推動了大模型和自然語言生成領(lǐng)域的技術(shù)創(chuàng)新與研究成果轉(zhuǎn)化。 中譯語通作為NLGIW戰(zhàn)略合作伙伴參會展示 本屆會議組織單位為中國中文
2023-07-27 09:44:381077 
來源: DeepHub IMBA 大型語言模型(llm)是一種人工智能(AI),在大量文本和代碼數(shù)據(jù)集上進行訓練。它們可以用于各種任務,包括生成文本、翻譯語言和編寫不同類型的創(chuàng)意內(nèi)容。 今年開始
2023-07-28 12:20:021214 
親愛的朋友,歡迎收看河套IT WALK總第91期。 今日全 球重大技術(shù)新聞目錄: · Google 的 RT-2: 當人工智能遇上機器人 ·IBM聯(lián)手NASA: 開源地理空間AI模型,助力氣候科學
2023-08-04 18:45:011437 
AI大模型的開源算法介紹 什么是開源?簡單來說就是不收取任何費用,免費提供給用戶的軟件或應用程序。開源是主要用于軟件的術(shù)語,除了免費用戶還可以對開源軟件的源代碼進行更改,并根據(jù)自身的使用情況進行
2023-08-08 17:25:013144 大型語言模型(llm)是一種人工智能(AI),在大量文本和代碼數(shù)據(jù)集上進行訓練。它們可以用于各種任務,包括生成文本、翻譯語言和編寫不同類型的創(chuàng)意內(nèi)容。今年開始,人們對開源LLM越來越感興趣。這些模型
2023-08-01 00:21:271468 
電子發(fā)燒友網(wǎng)站提供《恩智浦NCI2.0 MCUXpresso示例指南.pdf》資料免費下載
2023-08-17 14:26:513 最近,AI大模型測評火熱,尤其在大語言模型領(lǐng)域,“聰明”的上限 被 不斷刷新。 商湯與上海AI實驗室等聯(lián)合打造的大語言模型“書生·浦語”(InternLM)也表現(xiàn)出色,分別在 智源FlagEval
2023-08-25 13:00:021124 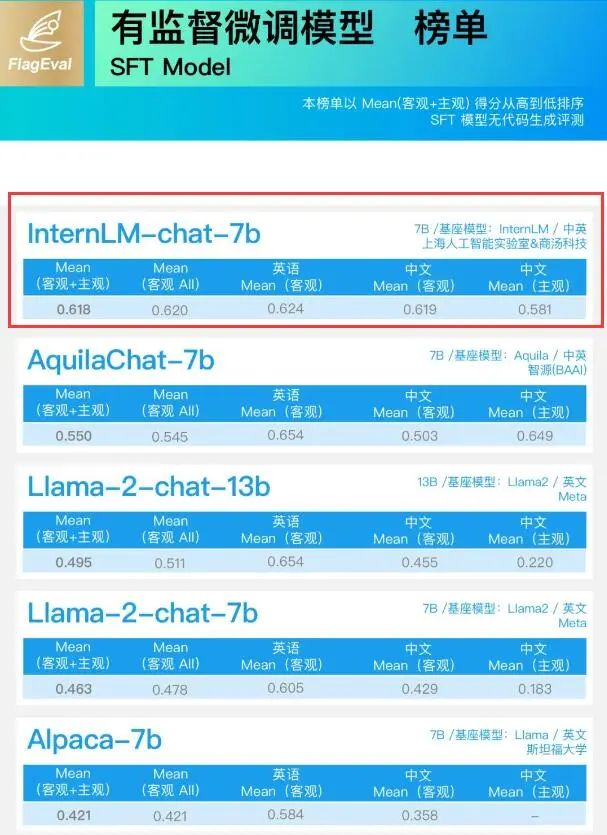
騰訊發(fā)布混元大語言模型 騰訊全球數(shù)字生態(tài)大會上騰訊正式發(fā)布了混元大語言模型,參數(shù)規(guī)模超千億,預訓練語料超2萬億tokens。 作為騰訊自研的通用大語言模型,混元大語言模型具有中文創(chuàng)作能力、任務執(zhí)行
2023-09-07 10:23:541586 ) 開源首發(fā)。 同時,書生·浦語面向大模型研發(fā)與應用的全鏈條工具鏈全線升級,與InternLM-20B一同繼續(xù)全面開放,向企業(yè)和開發(fā)者提供 免費商用授權(quán) 。 今年6月首次發(fā)布以來,書生·浦語歷多輪升級,在開源社區(qū)和產(chǎn)業(yè)界產(chǎn)生廣泛影響。 InternLM-20B模型性能先進且應用便捷,以不足三分之一的參
2023-09-20 16:45:021617 
11月27日,浪潮信息發(fā)布"源2.0"基礎(chǔ)大模型,并宣布全面開源。源2.0基礎(chǔ)大模型包括1026億、518億、21億等三種參數(shù)規(guī)模的模型,在編程、推理、邏輯等方面展示出了先進的能力。
2023-11-28 09:10:141359 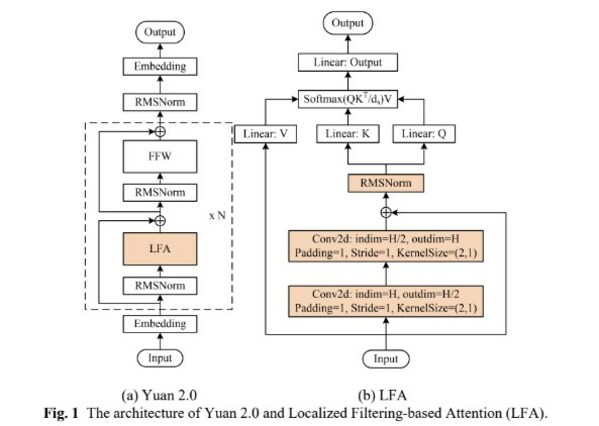
本文基于亞馬遜云科技推出的大語言模型與生成式AI的全家桶:Bedrock對大語言模型進行介紹。大語言模型指的是具有數(shù)十億參數(shù)(B+)的預訓練語言模型(例如:GPT-3, Bloom, LLaMA)。這種模型可以用于各種自然語言處理任務,如文本生成、機器翻譯和自然語言理解等。
2023-12-04 15:51:461470 在科技飛速發(fā)展的當今時代,人工智能技術(shù)成為社會進步的關(guān)鍵推動力之一。在廣泛關(guān)注的人工智能領(lǐng)域中,大語言模型以其引人注目的特性備受矚目。 大語言模型的定義及發(fā)展歷史 大語言模型是一類基于深度學習技術(shù)
2023-12-21 17:53:593103 在信息爆炸的時代,我們渴望更智能、更高效的語言處理工具。GPT-3.5等大語言模型的崛起為我們提供了前所未有的機會。這不僅是技術(shù)的進步,更是人與機器共舞的一幕。本篇文章將帶你走進這個奇妙的語言王國
2023-12-29 14:18:591167 隨著開源預訓練大型語言模型(Large Language Model, LLM )變得更加強大和開放,越來越多的開發(fā)者將大語言模型納入到他們的項目中。其中一個關(guān)鍵的適應步驟是將領(lǐng)域特定的文檔集成到預訓練模型中,這被稱為微調(diào)。
2024-01-04 12:32:391367 
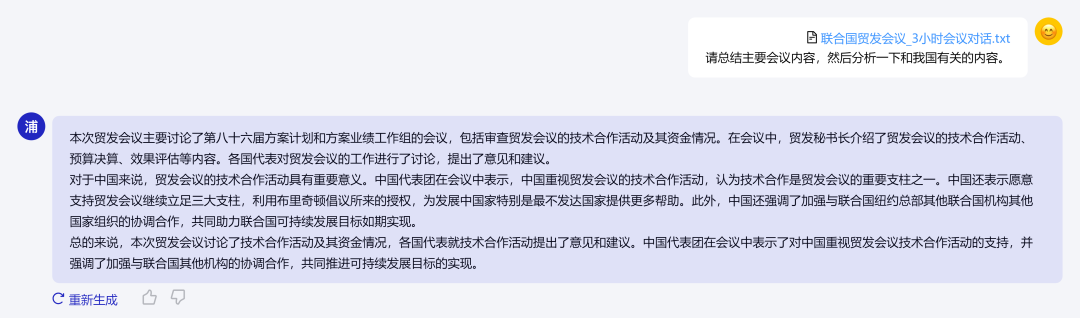
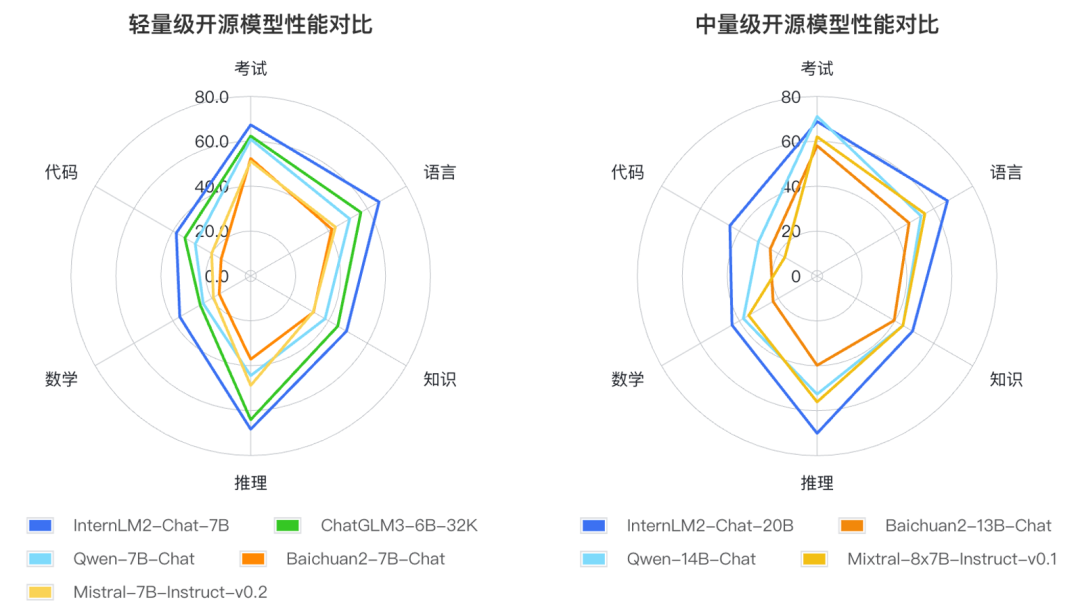
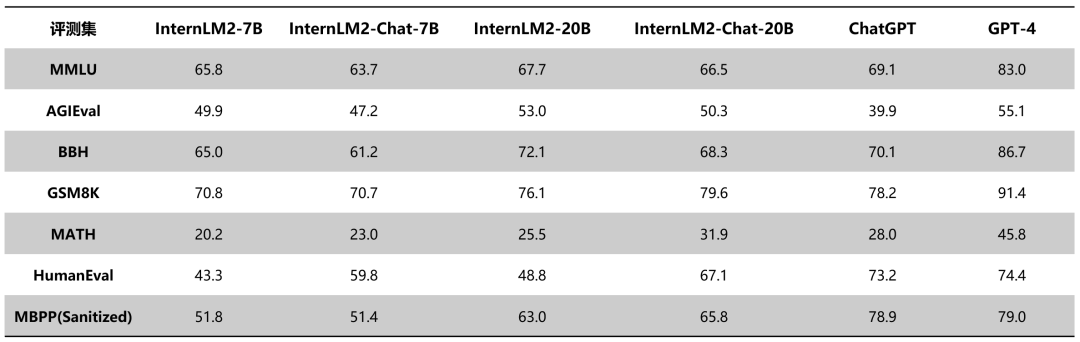
1月17日,商湯科技與上海AI實驗室聯(lián)合香港中文大學和復旦大學正式發(fā)布新一代大語言模型書?·浦語2.0(InternLM2)。
2024-01-17 15:03:571578 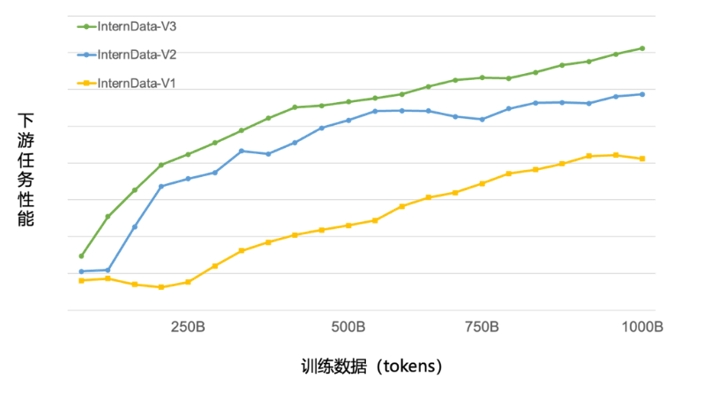
ByteDance Research 基于開源的多模態(tài)語言視覺大模型 OpenFlamingo 開發(fā)了開源、易用的 RoboFlamingo 機器人操作模型,只用單機就可以訓練。
2024-01-19 11:43:08944 
對此,ByteDance Research 基于開源的多模態(tài)語言視覺大模型 OpenFlamingo 開發(fā)了開源、易用的 RoboFlamingo 機器人操作模型,只用單機就可以訓練。使用簡單、少量的微調(diào)就可以把 VLM 變成 Robotics VLM,從而適用于語言交互的機器人操作任務。
2024-01-23 16:02:171291 
Meta發(fā)布CodeLlama70B開源大模型 Meta發(fā)布了開源大模型CodeLlama70B,號稱是CodeLlama系列體量最大、性能最強的大模型。 Code Llama 70B 有一個很出色
2024-01-31 10:30:181895 近日,上海人工智能實驗室(上海AI實驗室)聯(lián)手多所知名高校及科技公司共同研發(fā)出新一代書生·視覺大模型(InternVL)。
2024-02-04 11:25:581790 近日,大模型開源開放評測體系司南(OpenCompass2.0)正式發(fā)布,旨在為大語言模型、多模態(tài)模型等各類模型提供一站式評測服務。OpenCompass2.0的發(fā)布,將為模型技術(shù)創(chuàng)新提供重要的技術(shù)支撐。
2024-02-05 11:28:121816 昆侖萬維科技今日震撼發(fā)布全新升級的「天工2.0」MoE大語言模型以及配套的新版「天工AI智能助手」APP。此次更新標志著國內(nèi)首個搭載MoE架構(gòu)的千億級參數(shù)大語言模型AI應用正式面向廣大C端用戶免費
2024-02-06 16:19:511833 在人工智能領(lǐng)域,谷歌可以算是開源的鼻祖。今天幾乎所有的大語言模型,都基于谷歌在 2017 年發(fā)布的 Transformer 論文;谷歌的發(fā)布的 BERT、T5,都是最早的一批開源 AI 模型。
2024-02-22 18:14:34999 
NVIDIA 宣布使用 NVIDIA TensorRT-LLM 加速微軟最新的 Phi-3 Mini 開源語言模型。TensorRT-LLM 是一個開源庫,用于優(yōu)化從 PC 到云端的 NVIDIA GPU 上運行的大語言模型推理。
2024-04-28 10:36:081584 近期,大模型開源開放評測體系司南(OpenCompass 2.0)公布了2024年4月大語言模型最新評測榜單,智譜AI的GLM-4繼續(xù)保持國產(chǎn)大模型第一的領(lǐng)先身位。 大模型開源開放評測體系司南
2024-05-22 12:44:481394 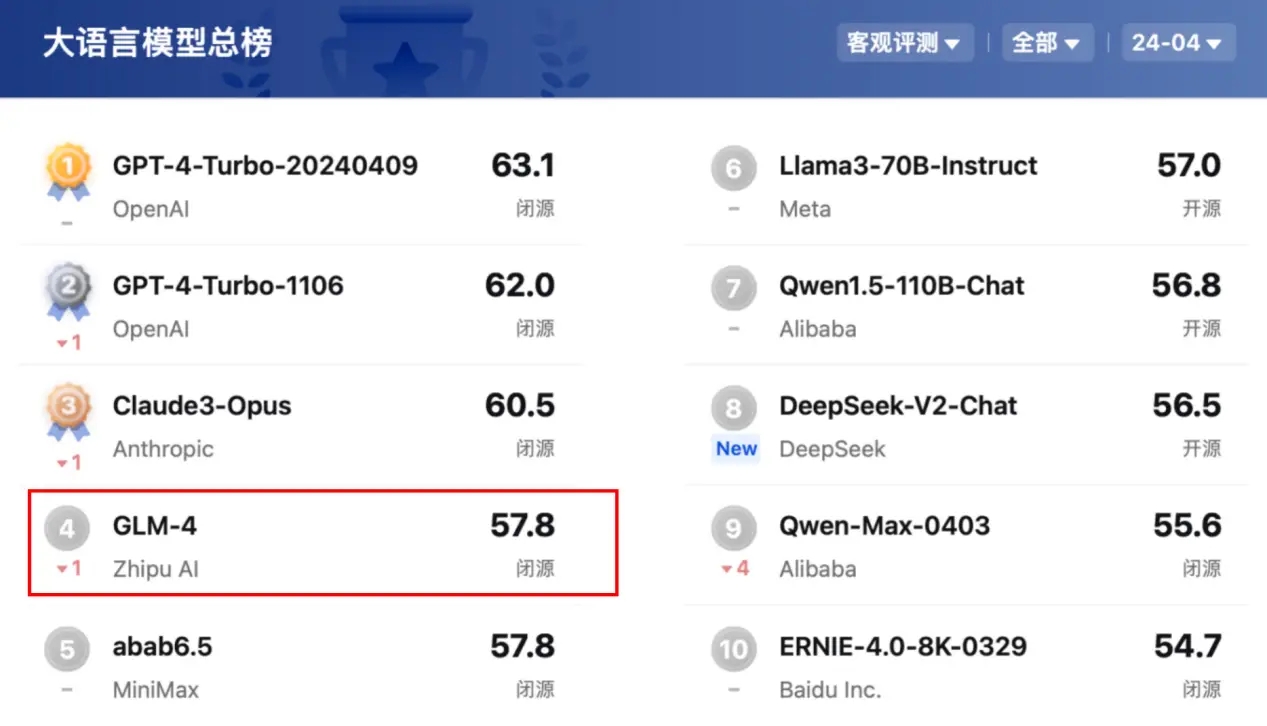
浪潮信息近日推出了革命性的“源2.0-M32”開源大模型。該模型在源2.0系列基礎(chǔ)上,引入了“基于注意力機制的門控網(wǎng)絡”技術(shù),構(gòu)建了一個包含32個專家的混合專家模型(MoE),有效提升了模型算力效率。
2024-05-29 09:08:221163 5月28日,浪潮信息發(fā)布“源2.0-M32”開源大模型。“源2.0-M32”在基于”源2.0”系列大模型已有工作基礎(chǔ)上,創(chuàng)新性地提出和采用了“基于注意力機制的門控網(wǎng)絡”技術(shù)
2024-05-29 09:34:591427 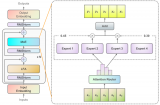
自2022年,ChatGPT發(fā)布之后,大語言模型(LargeLanguageModel),簡稱LLM掀起了一波狂潮。作為學習理解LLM的開始,先來整體理解一下大語言模型。一、發(fā)展歷史大語言模型的發(fā)展
2024-06-04 08:27:472712 浪潮信息近日發(fā)布了一款全新的開源大模型——“源2.0-M32”。這款大模型在“源2.0”系列大模型的基礎(chǔ)上,進行了深度的技術(shù)創(chuàng)新與升級。
2024-06-05 14:50:341311 近日,智譜AI在人工智能領(lǐng)域取得重大突破,成功推出全新開源模型GLM-4-9B。這款模型以其卓越的多模態(tài)能力,再次刷新了業(yè)界對于大型語言模型的認識。
2024-06-07 09:17:161488 近日,英偉達宣布開源了一款名為Nemotron-4 340B的大型模型,這一壯舉為開發(fā)者們打開了通往高性能大型語言模型(LLM)訓練的新天地。該系列模型不僅包含高達3400億參數(shù),而且通過其獨特的架構(gòu),為醫(yī)療保健、金融、制造、零售等多個行業(yè)的商業(yè)應用提供了強大的支持。
2024-06-17 14:53:491203 在人工智能領(lǐng)域,大語言模型一直是研究的熱點。近日,全球科技巨頭谷歌宣布,面向全球研究人員和開發(fā)人員,正式發(fā)布了其最新研發(fā)的大語言模型——Gemma 2。這款模型以其高效能和低成本的特點,引起了業(yè)界的廣泛關(guān)注。
2024-06-29 09:48:32966 隨著人工智能技術(shù)的飛速發(fā)展,大語言模型(LLM)已成為自然語言處理領(lǐng)域的核心工具,廣泛應用于智能客服、文本生成、機器翻譯等多個場景。然而,大語言模型的高計算復雜度和資源消耗成為其在實際應用中面臨
2024-07-04 17:32:041976 視語坤川大模型智能體平臺兼容多種多尺寸的大語言模型及多模態(tài)模型,并可以使用訓推平臺組件進行模型微調(diào),以適配不同的應用場景。平臺還具備外掛知識庫的功能,能夠理解非結(jié)構(gòu)化數(shù)據(jù)和多模態(tài)數(shù)據(jù),并提供特定領(lǐng)域行業(yè)和企業(yè)的知識回答,確保數(shù)據(jù)安全。
2024-07-09 14:38:20658 
隨著人工智能技術(shù)的飛速發(fā)展,自然語言處理(NLP)作為人工智能領(lǐng)域的一個重要分支,取得了顯著的進步。其中,大語言模型(Large Language Model, LLM)憑借其強大的語言理解和生成
2024-07-11 10:11:521581 是一款先進的大語言模型(LLM),擁有一流的推理、知識和代碼編寫能力,在設計中即支持幾十種語言,包括英語、法語、德語、西班牙語、意大利語、中文、日語、韓語、葡萄牙語、荷蘭語、
2024-07-26 08:07:00731 “Intel借助開源大賽在全國的影響力,吸引更多開發(fā)者加入大語言模型及其在人工智能領(lǐng)域的創(chuàng)新應用。”負責BigDL-LLM賽題運營的Intel工作人員表示。
2024-09-24 10:38:071331 近日,浪潮信息宣布其開源大模型源2.0已全面適配百度PaddleNLP。這一舉措標志著大模型開發(fā)生態(tài)正加速進化,為用戶提供了更加便捷、高效的大模型應用體驗。
2024-10-17 18:15:461261 「重磅通知」 :PerfXCloud 再度華麗升級,現(xiàn)已全面支持迄今為止 最為卓越的開源視覺模型 Qwen2-VL-7B 。這一重大突破將為用戶帶來更加震撼的視覺體驗,進一步拓展創(chuàng)意的邊界,快來
2024-10-23 11:07:541185 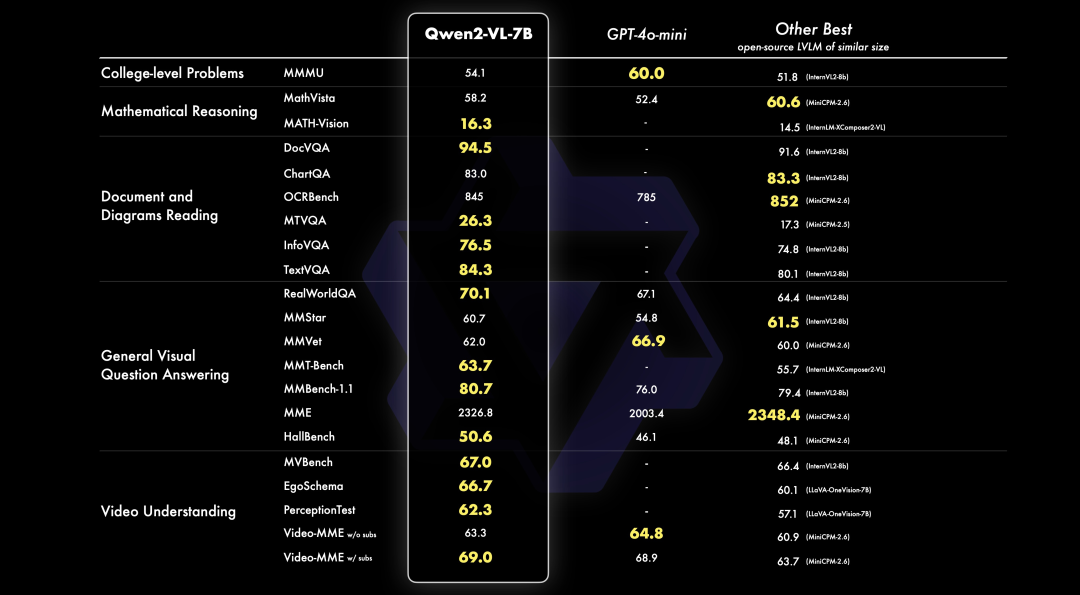
,科大訊飛以其一貫的創(chuàng)新精神,開創(chuàng)性地發(fā)布了星火多語言大模型。這一創(chuàng)新之舉不僅進一步鞏固了科大訊飛在中文和英文處理領(lǐng)域的領(lǐng)先地位,更將語言的支持范圍大幅擴展,涵蓋了俄語、日語、阿拉伯語、韓語、法語、西班牙語、葡萄牙語以及
2024-10-24 13:58:431288 本文我們將總結(jié)5種搭建開源大語言模型服務的方法,每種都附帶詳細的操作步驟,以及各自的優(yōu)缺點。
2024-10-29 09:17:091225 大語言模型的開發(fā)是一個復雜且細致的過程,涵蓋了數(shù)據(jù)準備、模型架構(gòu)設計、訓練、微調(diào)和部署等多個階段。以下是對大語言模型開發(fā)步驟的介紹,由AI部落小編整理發(fā)布。
2024-11-04 10:14:43955 近日,騰訊公司宣布成功推出業(yè)界領(lǐng)先的開源MoE(Mixture of Experts,專家混合)大語言模型——Hunyuan-Large。這款模型不僅在參數(shù)量上刷新了業(yè)界紀錄,更在效果上展現(xiàn)出了卓越
2024-11-06 10:57:131014 在人工智能領(lǐng)域,大語言模型(Large Language Models, LLMs)背后,離不開高效的開發(fā)語言和工具的支持。下面,AI部落小編為您介紹大語言模型開發(fā)所依賴的主要編程語言。
2024-12-04 11:44:411150 大語言模型開發(fā)框架是指用于訓練、推理和部署大型語言模型的軟件工具和庫。下面,AI部落小編為您介紹大語言模型開發(fā)框架。
2024-12-06 10:28:43926 開源AI模型庫是指那些公開源代碼、允許自由訪問和使用的AI模型集合。這些模型通常經(jīng)過訓練,能夠執(zhí)行特定的任務。以下,是對開源AI模型庫的詳細介紹,由AI部落小編整理。
2024-12-14 10:33:331399 要充分發(fā)揮語言模型的潛力,有效的語言模型管理非常重要。以下,是對語言模型管理作用的分析,由AI部落小編整理。
2025-01-02 11:06:37618 當大家討論為什么 DeepSeek 能夠形成全球刷屏之勢,讓所有廠商、平臺都集成之時,「開源」成為了最大的關(guān)鍵詞之一,圖靈獎得主 Yann LeCun 稱其是「開源的勝利」。模型開源一直備受關(guān)注,從
2025-02-19 09:48:162544 
OpenAI開源了兩款高性能權(quán)重語言模型gpt-oss-120b和gpt-oss-20b,OpenAI CEO Sam Altman表示:「gpt-oss 發(fā)布了!我們做了一個開放模型,性能達到
2025-08-06 14:25:12938 近日,由書生大模型社區(qū)、沐曦、魔樂社區(qū)、算豐和 DaoCloud 道客等聯(lián)合打造的「書生大模型實戰(zhàn)營沐曦魔樂專場 MeetUP 暨頒獎儀式」在上海漕河涇國際孵化中心圓滿落幕。
2025-08-20 11:33:12988 9月8日,上海人工智能實驗室(上海AI實驗室)開源書生大模型新一代訓練引擎XTuner V1。
2025-09-10 10:55:11984 NVIDIA 現(xiàn)已開源 Audio2Face 模型與 SDK,讓所有游戲和 3D 應用開發(fā)者都可以構(gòu)建并部署帶有先進動畫的高精度角色。NVIDIA 開源 Audio2Face 的訓練框架,任何人都可以針對特定用例對現(xiàn)有模型進行微調(diào)與定制。
2025-10-21 11:11:08675 
為助力打造實時、動態(tài)的 NPC 游戲角色,NVIDIA ACE 現(xiàn)已支持開源 Qwen3-8B 小語言模型(SLM),可實現(xiàn) PC 游戲中的本地部署。
2025-10-29 16:59:331133 小米正式發(fā)布并開源新模型 MiMo-V2-Flash 近日小米正式發(fā)布并開源新模型 MiMo-V2-Flash。Xiaomi MiMo-V2-Flash 是小米專為極致推理效率自研的總參數(shù) 309B
2025-12-17 09:42:582371 中文、英語、日語等常見語種,也包含捷克語、馬拉地語、愛沙尼亞語、冰島語等小語種。目前兩個模型均已在騰訊混元官網(wǎng)上線,在Github和Huggingface等開源社區(qū)也可直接下載使用。壁仞科技壁礪 166M產(chǎn)品采用vLLM推理框架已完成Tencent-HY-MT1.5-1.8B模型的Day0適配。
2026-01-05 15:39:48119 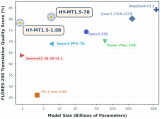
 電子發(fā)燒友App
電子發(fā)燒友App








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論