") 騰訊發(fā)布開源MoE大語言模型Hunyuan-Large
騰訊發(fā)布開源MoE大語言模型Hunyuan-Large

近日,騰訊公司宣布成功推出業(yè)界領(lǐng)先的開源MoE(Mixture of Experts,專家混合)大語言模型——Hunyuan-Large。這款模型不僅在參數(shù)量上刷新了業(yè)界紀(jì)錄,更在效果上展現(xiàn)出了卓越的性能,標(biāo)志著騰訊在自然語言處理領(lǐng)域邁出了重要的一步。
據(jù)了解,Hunyuan-Large的總參數(shù)量高達(dá)389B(即3890億),這一數(shù)字遠(yuǎn)超當(dāng)前許多主流的大語言模型。而其激活參數(shù)也達(dá)到了驚人的52B(即520億),這意味著模型在處理復(fù)雜任務(wù)時能夠展現(xiàn)出更強的學(xué)習(xí)能力和泛化性能。
除了參數(shù)量上的優(yōu)勢,Hunyuan-Large在訓(xùn)練數(shù)據(jù)上也下足了功夫。據(jù)悉,該模型訓(xùn)練時所使用的token數(shù)量達(dá)到了7T(即7萬億),這確保了模型能夠充分學(xué)習(xí)到語言的多樣性和復(fù)雜性。同時,Hunyuan-Large還支持最大上下文長度為256K的文本輸入,這一特性使得模型在處理長文本或?qū)υ拡鼍皶r能夠更準(zhǔn)確地捕捉上下文信息,從而生成更加連貫和自然的回復(fù)。
騰訊此次推出的Hunyuan-Large大語言模型,不僅展示了其在人工智能領(lǐng)域的深厚技術(shù)積累,也為整個自然語言處理領(lǐng)域的發(fā)展注入了新的活力。
-
人工智能
+關(guān)注
關(guān)注
1817文章
50102瀏覽量
265509 -
騰訊
+關(guān)注
關(guān)注
7文章
1684瀏覽量
50928 -
語言模型
+關(guān)注
關(guān)注
0文章
571瀏覽量
11322 -
自然語言
+關(guān)注
關(guān)注
1文章
292瀏覽量
13991
發(fā)布評論請先 登錄
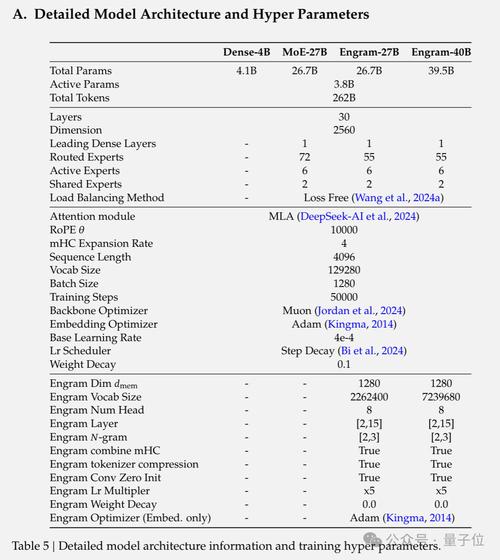
DeepSeek開源Engram:讓大模型擁有"過目不忘"的類腦記憶
今日看點:小米正式發(fā)布并開源新模型 MiMo-V2-Flash;磷酸鐵鋰開啟漲價潮
NVIDIA Grace Blackwell平臺實現(xiàn)MoE模型性能十倍提升

NVIDIA ACE現(xiàn)已支持開源Qwen3-8B小語言模型
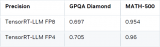
大規(guī)模專家并行模型在TensorRT-LLM的設(shè)計

3萬字長文!深度解析大語言模型LLM原理

【「DeepSeek 核心技術(shù)揭秘」閱讀體驗】基于MOE混合專家模型的學(xué)習(xí)和思考-2
如何在NVIDIA Blackwell GPU上優(yōu)化DeepSeek R1吞吐量
Arm率先適配騰訊混元開源模型,助力端側(cè)AI創(chuàng)新開發(fā)
硬件與應(yīng)用同頻共振,英特爾Day 0適配騰訊開源混元大模型
OpenAI發(fā)布2款開源模型
華為宣布開源盤古7B稠密和72B混合專家模型
摩爾線程率先支持騰訊混元-A13B模型
華為正式開源盤古7B稠密和72B混合專家模型
NVIDIA使用Qwen3系列模型的最佳實踐




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論