 新一代超大模型訓練引擎XTuner V1開源
新一代超大模型訓練引擎XTuner V1開源

9月8日,上海人工智能實驗室(上海AI實驗室)開源書生大模型新一代訓練引擎XTuner V1。
XTuner V1是伴隨上海AI實驗室“通專融合”技術路線的持續演進,以及書生大模型研發實踐而成長起來的新一代訓練引擎。相較于傳統的3D并行訓練引擎,XTuner V1不僅能應對更加復雜的訓練場景,還具備更快的訓練速度,尤其在超大規模稀疏混合專家(MoE,mixture of experts)模型訓練中優勢顯著。
同時,為了進一步探究XTuner V1訓練方案的上限,研究團隊與昇騰團隊在昇騰384超節點(Atlas 900 A3 SuperPoD)上進行聯合優化,充分利用昇騰384超節點硬件特性,實現更高的模型算力利用率(MFU,model FLOPS utilization)。相比業界其他產品,昇騰384超節點的訓練吞吐提升5%以上,MFU提升20%以上,該項研究成果技術報告也將于近期發布。
除了訓練框架,書生大模型研發中使用的AIOps工具DeepTrace與ClusterX也將一并開源,為大規模分布式訓練提供全方位保障。
XTuner V1:
https://github.com/InternLM/xtuner
DeepTrace:
https://github.com/DeepLink-org/DeepTrace
ClusterX:
https://github.com/InternLM/clusterx
目前開源社區主流的訓練方案主要分為兩類:
DeepSpeed/PyTorch FSDP(完全分片數據并行,Fully Shard Data Parallel):通信量大但使用簡單,尤其適合稠密型模型訓練,開發者無需具備專業的AI Infra知識,也能開發出接近最優性能的訓練系統;
3D并行:通信量小但使用復雜,開發者需要具備專業的AI Infra知識,針對不同硬件和訓練場景進行針對性調優,尤其適用MoE模型訓練。
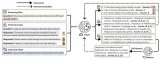
為了同時兼顧易用性、高性能與超大模型訓練,XTuner V1基于PyTorch FSDP進行開發,并針對FSDP通信量大的固有缺陷,進行了系列優化,可支持1T參數量級MoE模型訓練,并首次在200B以上量級的混合專家模型上,實現訓練吞吐超越傳統的3D并行訓練方案。
針對當前主流的MoE后訓練需求,XTuner V1未通過序列并行方式,實現200B量級MoE模型單次forward-backward可處理64k序列長度,更適合當下流行的強化學習訓練場景;對專家并行依賴小,長序列訓練時受專家不均衡影響小,200B量級MoE無需專家并行,600B MoE只需節點內專家并行,更適合現代MoE Dropless訓練模式;大規模長短序列混訓場景提速2倍以上,數據并行負載均衡,大幅減小因需序列長度不均衡導致的計算空泡。
多維度技術優化
專為“超大模型”而生
XTuner V1之所以能在超大模型訓練中展現出卓越的性能,核心在于它在顯存、通信、負載等多個維度進行了系統性優化。這些優化協同作用,不僅帶來了性能的跨越式提升,還兼顧了易用性、通用性與擴展性。
顯存優化:Pytorch FSDP與3D并行最大的差異在于重計算。針對計算損失函數時的計算圖,XTuner V1基于Liger-Kernel中的Chunk-wise Loss,擴展支持了更多種類的損失函數,能夠支持昇騰NPU;針對重計算保留的激活值,XTuner V1借鑒了昇騰MindSpeed中的Async Checkpointing Swap。最終,無需借助序列并行技術,實現200B參數量級MoE模型訓練64K長度序列。
通信掩蓋:得益于極致的顯存優化,XTuner V1可以讓單次迭代的最大序列長度提升數倍,從而增加每層計算的耗時,掩蓋參數聚合的通信耗時。針對因顯存或通信帶寬受限,無法實現通信掩蓋的訓練場景,XTuner V1通過Intra-Node Domino-EP來降低每一層聚合參數的通信量,同時掩蓋因引入專家并行帶來的額外通信開銷。
DP負載均衡:由于XTuner V1中沒有引入TP、PP等并行策略,相同卡數下,數據并行的維度會遠大于3D并行。為了緩解變長注意力帶來的計算空泡,并盡可能不影響數據的訓練順序,會對每n個step內的已拼接好的序列進行排序,讓每次計算時,不同DP的最長子序列長度是接近的。
基于昇騰384超節點深度優化
訓練效率超業界產品
為了進一步探究XTuner V1訓練方案的上限,上海人工智能實驗室XTuner團隊聯合昇騰技術團隊在超節點上進行深度優化,充分利用昇騰384超節點硬件特性,實現了更高MFU。
昇騰384超節點通過高速總線連接多顆NPU,突破互聯瓶頸,讓超節點像一臺計算機一樣工作,更加適合FSDP訓練:
更高的通信帶寬:最大可實現384顆NPU點到點超大帶寬互聯,FSDP All Gather耗時僅為業界產品的1/4~1/3,更容易實現計算-通信掩蓋
計算通信解耦:通過專用硬化調度和傳輸卸載,實現不占用計算核的高效數據通信,FSDP計算通信掩蓋時不會影響計算速度
超節點高速互連:CPU和NPU通過高速總線互聯,實現更大帶寬,Checkpointing Swap的開銷更小
除硬件固有優勢外,昇騰還從通信、內存、計算、框架、工具等維度對基于昇騰384超節點的MoE訓練進行了全方位的加持:
Cube調優:對于模型中集中了大量計算任務的GroupedMatmul算子進行分析,發現內部搬運帶寬已經擁塞但cube利用率還有提升空間。針對此問題,聯合研發團隊重點優化GroupedMatmul算子分塊邏輯,根據不同輸入進行動態分塊Tiling策略優化搬運效率。同時,根據場景的不同細化Cache策略,提高Cache命中率從而提升性能。
QoS調優:QoS(Quality of Service)即服務質量。在有限的帶寬資源下,QoS為各種業務分配帶寬,為業務提供端到端的服務質量保證。大規模訓練過程中,計算流、通信流、swap流都會存在內存訪問,并發的訪問會導致內存帶寬擁塞,從而影響整體性能。通過適當調低通信的內存訪存優先級,可以減少計算的搬運時間,從而優化端到端性能。
跨流內存復用:在FSDP計算流和通信流異步重疊的場景中,Ascend Extension for PyTorch(PTA)中默認的跨流內存優化會導致顯存不能及時釋放,需要開啟PTA中進階版的跨流內存復用機制(MULTI_STREAM_MEMORY_REUSE=2),可以顯著降低顯存峰值。
集群性能工具高效診斷:借助MindStudio全流程工具鏈中的msprof-analyze性能分析工具與MindStudio Insight可視化工具,開發者可以充分利用其強大的數據分析與可視化能力,在分鐘級時間內精準識別訓練過程中的“快慢卡”現象根因,快速定位出性能瓶頸,顯著提升大集群調優效率。
書生大模型工具鏈研發團隊現已將Xtuner V1的工作全部開源,希望為學術界與工業界提供高性能、低門檻、易擴展的大模型訓練方案,豐富開源社區的訓練工具生態,為超大模型研發和應用提供堅實易用的基礎設施。
未來,在研究范式創新及模型能力提升的基礎上,上海AI實驗室將持續推進書生大模型及其全鏈條工具體系的開源,支持免費商用,同時提供線上開放服務,與各界共同擁抱更廣闊的開源生態,共促大模型產業繁榮。
-
華為
+關注
關注
218文章
36138瀏覽量
262538 -
開源
+關注
關注
3文章
4293瀏覽量
46369 -
大模型
+關注
關注
2文章
3725瀏覽量
5257
原文標題:新一代超大模型訓練引擎XTuner V1開源,昇騰384超節點訓練效率突破上限!
文章出處:【微信號:HWS_yunfuwu,微信公眾號:華為數字中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
智譜新一代旗艦模型GLM-5.1上線華為云
昆侖芯率先完成智譜新一代旗艦模型GLM-5.1深度支持
Nullmax推出新一代基于世界模型的閉環仿真系統

為什么 VisionFive V1 板上的 JH7100 中并存 NVDLA 引擎和神經網絡引擎?
智譜AI正式上線并開源全新一代大模型GLM-5
曦云C系列GPU Day 0 適配智譜全新一代大模型GLM-5

百度正式發布并開源新一代文檔解析模型PaddleOCR-VL-1.5

摩爾線程新一代大語言模型對齊框架URPO入選AAAI 2026



 工商網監
工商網監
評論