什么是深度強化學習? 眾所周知,人類擅長解決各種挑戰性的問題,從低級的運動控制(如:步行、跑步、打網球)到高級的認知任務。
2023-07-01 10:29:50 2122
2122 
,在實踐操作中往往涉及多方人員,其結果對開源項目發展影響深遠,因此,開源指南針的愿景是:通過開源指南針, 我們幫助需要對社區進行數據分析的人。包括但不限于 OSPOs、社區管理人員、學術研究人員、項目
2023-02-17 16:15:44
據英國《每日郵報》6月25日報道,研究人員發現,在面部數量達百萬級的測試中,飽受爭議的面部識別技術并不像聲稱地那么準確。 人工智能可以在數千張面孔中識別出你的面孔,準確率近乎百分之百,,但當其
2016-06-28 14:10:07
解決許多技術的和非技術的挑戰,如提高智能體的自主性、處理復雜環境互動的能力及確保行為的倫理和安全性。
未來的研究需要將視覺、語音和其他傳感技術與機器人技術相結合,以探索更加先進的知識表示和記憶模塊,利用強化學習進一步優化決策過程。
2024-12-20 19:17:04
是實現人工智能的一個途徑,即以機器學習為手段解決人工智能中的問題。1.在維基百科中,機器學習有下面幾種定義:機器學習是一門人工智能的科學,該領域的主要研究對象是人工智能,特別是如何在經驗學習中改善具體算法
2017-06-23 13:51:15
多智能體系統深度強化學習:挑戰、解決方案和應用的回顧摘要介紹背景:強化學習前提貝爾曼方程RL方法深度強化學習:單智能體深度Q網絡DQN變體深度強化學習:多智能體挑戰與解決方案MADRL應用結論和研究
2021-07-12 08:44:43
關鍵字: 太陽能電池 玻璃纖維 光纖 來自日本的研究人員開發出一種“纖維狀無TCO染料敏化太陽電池
2009-04-14 14:23:10
有沒有搞機器學習、人工智能相關的算法研究的啊?自己一個人搞感覺挺難的,希望找到志同道合的朋友,相互探討。
2016-02-26 09:56:00
如題,希望找到一些同樣研究機器學習,人工智能算法研究的朋友,相互探討,共同進步。自己一個人搞感覺挺難的,希望可以一起討論,跟貼聯系。
2016-02-26 09:58:54
通過使用基于光子的THz電路來橋接光纖和無線電的世界,以實現超高數據速率。但是,不管要實現什么樣的系統,信號復用和解復用系統(復用器/解復用器)都是基本要求。研究人員使用兩個平行的金屬板的波導系統,把
2018-08-31 15:58:59
測試)三、主講內容1:課程一、強化學習簡介課程二、強化學習基礎課程三、深度強化學習基礎課程四、多智能體深度強化學習課程五、多任務深度強化學習課程六、強化學習應用課程七、仿真實驗課程八、輔助課程四、主講
2021-01-10 13:42:26
發現硅壓阻式壓力傳感器系統設計和制造工藝缺陷是解決上述問題的根本。但是,MEMS器件可靠性標準的缺乏和研究人員對MEMS器件的可靠性研究不足, 限制了它的使用,以及可靠性的提高。因此, 為保證產品在
2018-11-05 15:37:57
據物理學家組織網報道,美國普渡大學和哈佛大學的研究人員推出了一項極為應景的新發明:一種外形如同一顆圣誕樹一樣的新型晶體管,其重要組件“門”(柵極)的長度縮減到了突破性的20納米。這個被稱為“4維
2013-02-03 20:30:28
文中先對BP 算法進行了分析,然后針對標準BP 算法的不足進行了改進,通過對作用函數進行修正、自動調節學習率以及選擇初始權值后得到了改進的BP 算法,并給出了在車牌識別
2010-01-22 16:06:28 0
0 人員行為智能分析系統主要包含行為分析和特征識別。人員行為智能分析系統以機器學習+邊緣計算視覺分析為依托,對人員徘徊、人員集聚、物件遺留、打架斗毆、跌倒檢測、安全帽佩戴識別、反光衣識別、區域人數統計
2024-07-24 22:43:10
法國研究人員開發出新型智能晶體管
法國研究人員最新開發出一種新型智能晶體管,它能夠模仿神經系統的運行模式,對圖像進行識別,幫助電腦完成更加復
2010-01-27 10:43:27608 本內容提出了音樂旋律匹配算法的改進研究,希望對大家學習上有所幫助
2011-05-26 15:56:1647 美國研究人員日前開發出一種新型“自旋極化”OLED技術,改進后的OLED與普通LED相比具有更多的優點。
2012-07-20 09:28:561278 基于反向學習與Levy飛行的改進蜂群算法_趙挺
2017-03-19 19:19:350 與監督機器學習不同,在強化學習中,研究人員通過讓一個代理與環境交互來訓練模型。當代理的行為產生期望的結果時,它得到正反饋。例如,代理人獲得一個點數或贏得一場比賽的獎勵。簡單地說,研究人員加強了代理人的良好行為。
2018-07-13 09:33:0025158 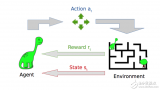
深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
2018-06-29 18:36:0028671 由美國軍方資助的研究人員正在開發能刺激大腦治療精神疾病的人工智能技術。這些是“閉環”腦植入術, 使用算法來檢測與情緒紊亂相關的模式, 然后傳遞電脈沖以回應一個人的感覺和行為。
2017-12-28 08:48:454627 在本篇論文中,研究人員使用流行的異步進化算法(asynchronous evolutionary algorithm)的正則化版本,并將其與非正則化的形式以及強化學習方法進行比較。
2018-02-09 14:47:414352 
傳統上,強化學習在人工智能領域占據著一個合適的地位。但強化學習在過去幾年已開始在很多人工智能計劃中發揮更大的作用。
2018-03-03 14:16:564677 隨著內存消耗的控制,模擬速度將成為主要焦點。 例如,在Jülich的超級計算機JUQUEEN上運行的由5.8萬億突觸連接的5.2億神經元大型模擬需要28.5分鐘來計算一秒鐘的生物時間。研究人員計算,使用改進的算法,時間將縮短到僅5.2分鐘。
2018-03-29 15:16:234675 強化學習是智能系統從環境到行為映射的學習,以使獎勵信號(強化信號)函數值最大,強化學習不同于連接主義學習中的監督學習,主要表現在教師信號上,強化學習中由環境提供的強化信號是對產生動作的好壞作一種評價
2018-05-30 06:53:001741 為了達到人類學習的速率,斯坦福的研究人員們提出了一種基于目標的策略強化學習方法——SOORL,把重點放在對策略的探索和模型選擇上。
2018-06-06 11:18:235925 
這些具有一定難度的任務 OpenAI 自己也在研究,他們認為這是深度強化學習發展到新時代之后可以作為新標桿的算法測試任務,而且也歡迎其它機構與學校的研究人員一同研究這些任務,把深度強化學習的表現推上新的臺階。
2018-08-03 14:27:265370 物聯網安全研究人員滲透進了某智能燈泡,獲取到了Mesh網絡內傳輸的WiFi信息(包括WiFi密碼)。盡管在該案例中WiFi密碼被加密,但是研究人員依然通過獲取設備的底層固件,得到了加密算法和密鑰信息
2018-08-21 10:57:541770 研究人員借助人工智能(AI)可以基本確定被觀察對象是否屬于神經質、友好、外向、認真和好奇等性格特征。
2018-08-23 17:39:133066 對于新的研究人員來說,能夠根據既定方法快速對其想法進行基準測試非常重要。因此,我們為 Arcade 學習環境支持的 60 個游戲提供四個智能體的完整培訓數據,可用作 Python pickle 文件
2018-08-31 10:55:305376 艾倫人工智能研究所和華盛頓大學的研究人員正在使用可以根據上下文來確定英文單詞含義的神經網絡。
2018-09-12 15:52:142821 按照以往的做法,如果研究人員要用強化學習算法對獎勵進行剪枝,以此克服獎勵范圍各不相同的問題,他們首先會把大的獎勵設為+1,小的獎勵為-1,然后對預期獎勵做歸一化處理。雖然這種做法易于學習,但它也改變了智能體的目標。
2018-09-16 09:32:036329 日前,據外媒報道,Deezer的研究人員已經成功開發出能識別歌曲中情緒的人工智能。
2018-09-29 10:10:091297 研究人員挑選出各個器官(包括腦、心臟、胰腺和胸腺等)的細胞,然后開展單細胞RNA測序,以獲取每個細胞的轉錄組。研究人員指出,FACS方法和微流體方法在大量基因表達譜上基本一致。
2018-10-11 11:08:405255 之前接觸的強化學習算法都是單個智能體的強化學習算法,但是也有很多重要的應用場景牽涉到多個智能體之間的交互。
2018-11-02 16:18:1522830 11月1日,Facebook開源了Horizon,一個由Facebook的AI研究人員、推薦系統專家和工程師共同搭建的強化學習平臺,其框架的構建工作開始于兩年半前,在過去一年中一直被Facebook內部使用。
2018-11-05 09:34:171140 本文作者通過簡單的方式構建了強化學習模型來訓練無人車算法,可以為初學者提供快速入門的經驗。
2018-11-12 14:47:395434 OpenAI 近期發布了一個新的訓練環境 CoinRun,它提供了一個度量智能體將其學習經驗活學活用到新情況的能力指標,而且還可以解決一項長期存在于強化學習中的疑難問題——即使是廣受贊譽的強化算法在訓練過程中也總是沒有運用監督學習的技術。
2019-01-01 09:22:003047 
研究中的研究人員使用增強現實技術來改變主動感知行為與其產生的感官反饋之間的聯系,并更多地了解該過程的工作原理。
2018-12-29 15:11:313452 北京時間1月17日消息,美國佛蒙特大學的研究人員近日發明了一種全新的技術,可以通過分析青少年的活動情況來識別他們的焦慮和抑郁心理。
2019-02-04 17:20:002984 在傳統的多智體學習過程當中,有研究者在對其他智能體建模 (也即“對手建模”, opponent modeling) 時使用了遞歸推理,但由于算法復雜和計算力所限,目前還尚未有人在多智體深度強化學習 (Multi-Agent Deep Reinforcement Learning) 的對手建模中使用遞歸推理。
2019-03-05 08:52:435713 MIT的研究人員開發出一種新型 “光子” 芯片,它使用光而不是電,并且在此過程中消耗相對較少的功率。
2019-06-12 09:23:464519 在谷歌最新的論文中,研究人員提出了“非政策強化學習”算法OPC,它是強化學習的一種變體,它能夠評估哪種機器學習模型將產生最好的結果。
2019-06-22 11:16:292926 這一研究的目標是通過單張圖像輸入,對圖像中的物體進行檢測、獲取不同物體的類別、掩膜和對應的三維網格,并對真實世界中的復雜模型進行有效處理。在2D深度網絡的基礎上,研究人員改進并提出了新的架構。
2019-08-02 15:51:224571 
阿貢實驗室研究人員Shashi Aithal和Prasanna Balaprakash利用ALCF(Argonne Leadership Computing Facility)的超級計算資源,為
2019-09-20 11:03:532852 研究人員創建了一個自動圖像分析系統,旨在改善無法負擔Pap測試和其他診斷工具的國家中子宮頸癌的篩查。
2019-10-23 09:31:58962 來自慕尼黑的Helmholtz ZentrumMünchen和慕尼黑大學LMU的大學醫院的研究人員首次顯示,在對急性髓性白血病(AML)患者的血液樣本進行分類時,深度學習算法的性能與人類專家相似。
2019-11-28 09:28:321322 近日,滑鐵盧大學研究人員開發了一種新的人工智能工具,該工具使用深度學習的AI算法來確定帖子中的故事是否得到同一主題的其他帖子故事的支持,這可以幫助社交媒體網絡和新聞機構鑒別并清除虛假新聞。
2019-12-17 16:09:153673 惰性是人類的天性,然而惰性能讓人類無需過于復雜的練習就能學習某項技能,對于人工智能而言,是否可有基于惰性的快速學習的方法?本文提出一種懶惰強化學習(Lazy reinforcement learning, LRL) 算法。
2020-01-16 17:40:001238 現在,在研究人員開發出一種稱為“黑暗仿真器”的人工智能工具后,可以在幾秒鐘內研究宇宙如何產生其空隙和細絲。
2020-03-06 10:16:211055 從電信技術改造而來的技術有望實現更有效的癌癥治療。墨爾本研究人員發現,藥物可以通過聲波傳遞到各個細胞中。
2020-03-11 09:38:58640 格里菲斯大學(Griffith University)的研究人員在世界上首屈一指,已使用人工智能方法更好地預測RNA二級結構,希望可以將其開發成為更好地了解RNA如何與多種疾病(例如癌癥)相關的工具。
2020-03-13 09:25:011229 賓夕法尼亞州立大學的研究人員和東北大學的研究人員宣布,他們已經開發出一種高靈敏度、可穿戴的氣體傳感器,用于環境和人類健康監測。
2020-03-17 17:07:143608 近年來隨著強化學習的發展,使得智能體選擇恰當行為以實現目標的能力得到迅速地提升。目前研究領域主要使用兩種方法:一種是無模型(model-free)的強化學習方法,通過試錯的方式來學習預測成功的行為
2020-03-26 11:41:122388 根據 Nature 雜志發表的一項研究,斯坦福大學研究人員開發了一種機器學習方法,能夠實現早期肺癌患者的鑒別篩查。
2020-03-27 16:06:041150 來自劍橋大學和紐卡斯爾大學的研究人員設計了一種新的方法,通過向電池發送電脈沖并測量其響應來監測電池。然后,他們利用機器學習算法對測量數據進行處理,以預測電池的健康狀況和使用壽命。
2020-04-09 11:18:221570 預計COVID-19研究人員將開始使用人工智能(AI)和機器學習來挖掘有關COVID-19的新線索和新見解。
2020-04-15 10:48:32999 研究人員通過一種特殊的神經網絡模型,它以“基本塊”(計算指令的基本摘要)形式訓練標記的數據,以自動預測其持續時間使用給定的芯片執行以前看不見的基本塊。結果表明,這種神經網絡模型的性能要比傳統的手動調整模型精確得多。
2020-04-15 16:42:452178 在過去的幾年中,Microsoft深度學習研究人員在開發算法方面達到了人類同等的里程碑,該算法的性能與研究基準一樣好,可以測試會話語音識別,閱讀理解,新聞文章翻譯和其他具有挑戰性的語言理解能力任務。現在,這些AI研究突破的好處正逐漸滲透到從Azure到Bing的產品中。
2020-04-20 15:28:112451 Facebook在一篇博文中表示,卡耐基梅隆大學的研究人員“不會與Facebook分享個人調查反饋,Facebook也不會與研究人員分享關于你是誰的信息。”該公司還表示,將通過其疾病預防地圖計劃(Disease Prevention Maps program),為流行病學家提供新的類別的數據。
2020-04-22 10:58:393659 研究人員開發了一種機器學習模型,該模型可以使機器人安全地治療與神經退行性疾病相關的手部震顫。
2020-04-29 17:29:231240 這個由來自哈佛醫學院,克利夫蘭診所,梅奧診所等眾多研究人員的研究人員組成的多機構團隊對來自3,052名參與者的數據進行了AI訓練。其中,1,531例患有癌癥,1,521例沒有。
2020-05-21 10:17:502254 盡管AI系統已取得長足進步,但它們仍然無法應對混沌或不可預測性。現在,研究人員想教授AI物理學以解決此類問題。
2020-06-30 16:47:362467 該算法背后的研究人員在波特蘭的俄勒岡健康與科學大學工作。《自然新陳代謝》正在免費全面運行他們的發現
2020-07-03 10:46:412071 許多現代的AI系統都在神經網絡上運行,而我們僅了解其基礎知識,因為算法本身很少提供解釋方式。缺乏解釋性通常被稱為AI系統的“黑匣子”。研究人員將注意力集中在神經網絡如何工作的細節上
2020-07-14 16:31:562269 正如研究人員在AlphaZero項目中發現的那樣,設計精良的深度學習模型在遇到定義明確、但又不受人類固有規則束縛的問題時,往往能夠快速開辟出前所未有的解決思路。
2020-07-17 15:15:314003 7月23日消息 蘋果于當地時間周三啟動了其安全研究設備計劃,計劃向安全研究人員提供特殊版的 iPhone。該特殊 iPhone 提供了一般 iPhone 中受限部分的 SSH 權限。 圖源于蘋果
2020-07-23 16:40:27850 研究人員正在應用人工智能技術,旨在延長電池的使用壽命并監測電池的健康,為下一代電動汽車和消費電子產品提供動力。
2020-07-27 10:21:251564 Viet Nguyen就是其中一個。這位來自德國的程序員表示自己只玩到了第9個關卡。因此,他決定利用強化學習AI算法來幫他完成未通關的遺憾。
2020-07-29 09:30:163424 這項工作發表在《NPJ計算材料》上,是南卡羅來納大學工程與計算機學院的研究人員與貴州大學(位于中國貴陽的研究型大學)的研究人員之間的合作。
2020-09-10 11:45:062729 Arm和PragmatIC的研究人員最近使用低成本的柔性芯片制造了機器學習(ML)處理引擎,該引擎可用于構建具有先進數據處理能力的各種智能設備。
2020-09-11 11:28:472585 此外,研究人員還對無負極電池進行測試,以評估其安全性。他們根據研究結果設計出的電解質可以優化電池性能,并將其壽命延長至充放電循環次數可達200次。研究人員表示,他們將繼續進行研究,使無負極電池達到實際應用水平。
2020-09-12 09:37:252885 傳感器應用韓國科學技術高等研究院(KAIST)研究人員提供了一種深度學習供電的單應變電子皮膚傳感器,可以從遠處捕獲人體運動。 韓國科學技術高等研究院(KAIST)研究人員提供了一種深度學習供電的單
2020-09-22 14:28:312392 研究人員正在進行兩類實驗,對蜜蜂的大腦進行“逆向工程”——了解蜜蜂與大黃蜂如何可靠地飛行數公里,學習這些能讓它們返回蜂巢的特性。
2020-12-07 11:11:562018 醫療技術應當對所有人都有所幫助,為了應對這一挑戰,改善糖尿病視網膜病變篩查,人們已經做出了很多努力。Google AI的研究人員們就利用機器學習和計算機視覺領域的最新進展,開發了一種能夠通過眼部掃描圖像判斷患者的視網膜是否發生了病變的深度學習算法。
2020-11-16 09:15:292159 據外媒報道,美國加州大學洛杉磯分校(UCLA)、加州理工學院(Caltech)和福特汽車公司的一組研究人員改進了燃料電池技術,而且讓該技術在效率、穩定性和功率方面都超過了美國能源部(DOE)設定的目標,而且目前還沒有其他燃料電池同時在此類方面達到同樣的里程碑。
2020-11-30 10:09:102675 加州大學伯克利分校的研究人員創造了一種設備,使用可穿戴傳感器和人工智能軟件來識別一個人打算做出什么手勢。傳感器和人工智能能夠根據前臂的電信號模式來判斷一個人打算做出的手勢。研究人員表示,該設備為改進假肢控制和與電子設備的互動鋪平了道路。
2020-12-23 11:27:542074 蘋果在 7 月宣布推出新的蘋果安全研究設備計劃,該計劃旨在為研究人員提供特別配置的 iPhone,這些 iPhone 配備了獨特的代碼執行和遏制策略,以支持安全研究。 ? 蘋果公司從今天開始通知
2020-12-23 14:29:292049 蘇黎世ETH的研究人員首次通過將流體力學與人工智能相結合,成功地使湍流建模自動化。他們的項目依賴于在CSCSS超級計算機Piz Daint上通過湍流模擬進行擴增強化學習算法。
2021-01-07 10:46:226908 一個國際研究人員團隊開發了一種用于光子處理器的新方法和體系結構,可加快機器學習領域的復雜數學任務。
2021-01-08 14:00:082420 我們這些凡人在國際象棋上已經很久沒有真正與人工智能競爭了。距人類在國際象棋比賽中征服計算機已有15年了。但是,近日,一組研究人員開發了一種AI國際象棋engine,它的出現并不是打算碾壓我們這些弱小
2021-02-23 09:38:582106 近日,兩個由 OpenAI 的研究人員開發的一模一樣的機械臂愛麗絲和鮑勃,可以在模擬情景中通過對弈互相學習,而不需要人為輸入文本。
2021-02-23 10:40:312395 強化學習( Reinforcement learning,RL)作為機器學習領域中與監督學習、無監督學習并列的第三種學習范式,通過與環境進行交互來學習,最終將累積收益最大化。常用的強化學習算法分為
2021-04-08 11:41:5811 強化學習是人工智能領域中的一個研究熱點。在求解強化學習問題時,傳統的最小二乘法作為一類特殊的函數逼近學習方法,具有收斂速度快、充分利用樣本數據的優勢。通過對最小二乘時序差分算法
2021-04-23 15:03:035 利用深度強化學習技術實現路口信號控制是智能交通領域的硏究熱點。現有硏究大多利用強化學習來全面刻畫交通狀態以及設計有效強化學習算法以解決信號配時問題,但這些研究往往忽略了信號燈狀態對動作選擇的影響以及
2021-04-23 15:30:5321 近日,研究人員提出,希望將深度學習技術引入細胞成像和分析中,可以將混亂的生物學問題轉化為可解決的計算。該研究以「Small images, big picture: Artificial
2021-05-06 11:27:382639 一種新型的多智能體深度強化學習算法
2021-06-23 10:42:4736 伊利諾伊大學厄巴納-香檳分校的研究人員開發了 GPU 加速軟件,以模擬一個20億原子的細胞,該細胞像活細胞一樣代謝和生長。
2022-03-20 15:37:512354 普渡大學的研究人員開發了一種新技術,可以降低 CMOS 芯片所需的功率,從而延長電子設備的電池壽命。
2022-08-18 16:04:59710 定標記訓練數據的情況下獲得正確的輸出 無監督學習(UL):關注在沒有預先存在的標簽的情況下發現數據中的模式 強化學習(RL) : 關注智能體在環境中如何采取行動以最大化累積獎勵 通俗地說,強化學習類似于嬰兒學習和發現世界,如果有獎勵(正強化),嬰兒可能會執行一個行
2022-12-20 14:00:021683 作者:Siddhartha Pramanik 來源:DeepHub IMBA 目前流行的強化學習算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。這些算法
2023-02-03 20:15:061744 強化學習(RL)是人工智能的一個子領域,專注于決策過程。與其他形式的機器學習相比,強化學習模型通過與環境交互并以獎勵或懲罰的形式接收反饋來學習。
2023-06-09 09:23:23930 的情況下獲得正確的輸出無監督學習(UL):關注在沒有預先存在的標簽的情況下發現數據中的模式強化學習(RL):關注智能體在環境中如何采取行動以最大化累積獎勵通俗地說,強
2023-01-05 14:54:051714 
作者:SiddharthaPramanik來源:DeepHubIMBA目前流行的強化學習算法包括Q-learning、SARSA、DDPG、A2C、PPO、DQN和TRPO。這些算法已被用于在游戲
2023-02-06 15:06:384620 電子發燒友網站提供《人工智能強化學習開源分享.zip》資料免費下載
2023-06-20 09:27:281 摘要:基于強化學習的目標檢測算法在檢測過程中通常采用預定義搜索行為,其產生的候選區域形狀和尺寸變化單一,導致目標檢測精確度較低。為此,在基于深度強化學習的視覺目標檢測算法基礎上,提出聯合回歸與深度
2023-07-19 14:35:020 研究人員利用深度學習技術提高了直接集成在 CMOS 成像芯片上的超透鏡相機(左)的圖像質量。超透鏡利用 1000 納米高的圓柱形氮化硅納米柱陣列(右圖)操縱光線。 研究人員利用深度學習技術提高了超
2024-06-11 06:34:46905 
強化學習(Reinforcement Learning, RL)是一種機器學習方法,它通過與環境的交互來學習如何做出決策,以最大化累積獎勵。PyTorch 是一個流行的開源機器學習庫,它提供了靈活
2024-11-05 17:34:281519
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論