引言 目前,大多數自由文本搜索技術采用類似于Lucene的策略,通過解析搜索文本為各個組成部分來定位關鍵詞。這種方法在處理少量關鍵詞時表現良好。但當搜索的關鍵詞數量達到10萬個或更多時,這種方法
2024-08-26 15:55:47 1795
1795 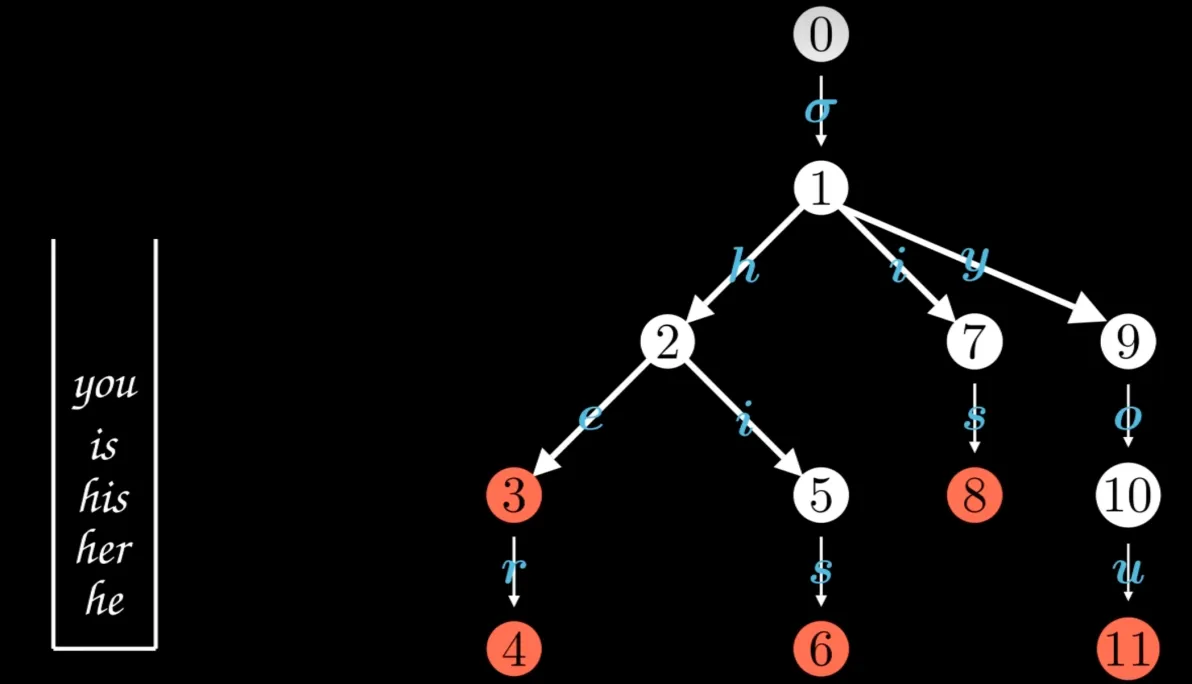
FPGA 年度關鍵詞,我的想法是“標準化”;今年的工作中遇到了不少同事的issues,本身都是小問題或者很細節的東西但是卻反復出現問題,目前想到的最好的辦法是做好設計規則的標準化才能避免,不知道大家有沒有更好的建議?
2023-12-06 20:31:23
·支持中文分詞(N-最短路分詞、CRF分詞、索引分詞、用戶自定義詞典、詞性標注),命名實體識別(中國人名、音譯人名、日本人名、地名、實體機構名識別),關鍵詞提取,自動摘要,短語提取,拼音轉換
2019-04-24 10:05:03
TextRank算法的具體細節,在實際應用中可能不合理。因為會存在:現有統計信息不足以讓TextRank支持 某個詞 的重要性,算法有局限性。可見:TextRank提取關鍵詞是受到分詞結果的影響的;其次
2018-11-05 10:41:25
。一篇文本中不是所有詞都很重要,我們只需找出起到關鍵作用、決定文本主要內容的詞進行分析即可。目前幾大主流的分詞技術可移步到這篇博客中:中文分詞技術小結、幾大分詞引擎的介紹與比較筆者采用的是HanLP分詞
2019-01-11 14:32:15
如何在一段文本之中提取出相應的關鍵詞呢? 之前我有想過用機器學習的方法來進行詞法分析,但是在項目中測試時正確率不夠。于是這時候便有了 HanLP-漢語言處理包 來進行提取關鍵詞的想法。下載:.jar
2018-11-09 14:54:48
的過程HanLP參考博客:詞性標注層疊HMM-Viterbi角色標注模型下的機構名識別分詞在HMM與分詞、詞性標注、命名實體識別中說:分詞:給定一個字的序列,找出最可能的標簽序列(斷句符號:[詞尾或[非
2018-12-05 10:52:43
的過程HanLP參考博客:詞性標注層疊HMM-Viterbi角色標注模型下的機構名識別分詞在HMM與分詞、詞性標注、命名實體識別中說:分詞:給定一個字的序列,找出最可能的標簽序列(斷句符號:[詞尾]或
2018-10-29 11:35:41
與DoubleArrayTrie或BinTrie中的自定義詞進行合并,最終返回輸出結果HanLP作者在HanLP issue783:上面說:詞典不等于分詞、分詞不等于自然語言處理;推薦使用語料而不是詞典去修正
2018-11-02 11:05:07
HanLP是由一系列模型與算法組成的Java工具包,目標是促進自然語言處理在生產環境中的應用。HanLP具備功能完善、性能高效、架構清晰、語料時新、可自定義的特點。HanLP能提供以下功能:關鍵詞
2018-11-07 09:21:44
= 4c396f3039230ddfcef20865264512b1Portable 版同步升級到 v1.7.0HanLP v1.7.1 更新內容:新增可自定義用戶詞典的維特比分詞器 @AnyListen利用
2019-03-22 09:56:52
。昨天正好看到的這篇關于關于1.7.0版本hanlp分詞在spark中的使用介紹的文章,順便分享給大家一起學習一下!以下為分享的文章內容:HanLP分詞,如README中所說,如果沒有特殊需求,可以通過
2019-03-11 15:38:38
CRFLexicalAnalyzer的構造函數即可創建分詞器,同時HanLP會自動創建二進制緩存.txt.bin,下次加載耗時將控制在數百毫秒內。預測可通過如下方式加載:CRFSegmenter segmenter
2019-02-18 15:28:50
。為了縮短時間,首先進行分詞,一個詞輸出為一行方便統計,分詞工具選擇的是HanLp。然后,將一個領域的文檔合并到一個文件中,并用“$$”標識符分割,方便記錄文檔數。下面是選擇的領域語料(PATH目錄
2018-11-14 10:03:44
雙數組Trie樹(DoubleArrayTrie)儲存,得到了一個高性能的中文分詞器。開源項目本文代碼已集成到HanLP中開源CRF簡介CRF是序列標注場景中常用的模型,比HMM能利用更多的特征,比
2018-10-19 11:46:21
;關鍵字提取:");28getMainIdea();29System.out.println("\n");3031 System.out.println("自動摘要
2018-11-30 13:11:16
分詞器Jcseg 是基于 mmseg 算法的一個輕量級中文分詞器,同時集成了關鍵字提取,關鍵短語提取,關鍵句子提取和文章自動摘要等功能,并且提供了一個基于 Jetty 的 web 服務器,方便各大語言
2018-10-12 11:23:25
本篇分享一個hanlp分詞工具應用的案例,簡單來說就是做一圖庫,讓商家輕松方便的配置商品的圖片,最好是可以一鍵完成配置的。先看一下效果圖吧: 商品單個推薦效果:匹配度高的放在最前面這個想法很好,那
2019-08-07 11:47:57
。接下來驗證一下,分詞器的宣傳語是否得當吧。jieba 中文分詞thulac 中文分詞fool 中文分詞HanLP 中文分詞中科院分詞 nlpir哈工大ltp 分詞以上可以看出分詞的時間,為了方便比較進行
2019-02-26 15:00:18
),命名實體識別(中國人民、音譯人民、日本人民,地名,實體機構名識別),關鍵詞提取,自動摘要,短語提取,拼音轉換,簡繁轉換,文本推薦,依存句法分析(MaxEnt依存句法分析、神經網絡依存句法分析)。提供
2019-01-02 14:43:15
矩陣模型,以一個詞的起始位置作為行,終止位置作為列,可以得到一個二維矩陣。例如:“他說的確實在理”這句話 圖詞的存儲方法:一種是的DynamicArray法,一種是快速offset法。Hanlp代碼中
2018-11-07 10:56:12
),也就是說,lsi+tfidf模型對詞細粒度大、分詞少的分詞器不友好,所以最后hanlp出錯率更大。jieba與hanlp都是很不錯的分詞器,結巴使用更方便。hanlp準確度要高一些(感覺),而且
2019-02-18 10:29:06
的方法,都是需要我們慢慢的去挖掘在已有的基礎上面去拓展思維。東莞seo博客總結,我們想要做好關鍵詞優化排名,那么我們需要對于關鍵詞進行合理的布局和思考,運用以上為大家介紹的一些方法去實時的操作,還需要再
2019-08-11 01:19:18
IOException速度目前感知機分詞是所有“由字構詞”的分詞器實現中最快的,比自己寫的CRF解碼快1倍。新版CRF詞法分析器框架復用了感知機的維特比解碼算法,所以速度持平。l 測試時需關閉詞法分析器
2019-04-03 11:28:47
`功能介紹1、圖片列表展示2、輸入文本3、分詞4、通用文字識別5、結果展示效果演示使用說明在"請輸入關鍵詞"下面的輸入框中輸入需要分詞的關鍵詞,點擊【開始通用文字
2021-04-14 22:38:35
功能介紹1、圖片列表展示2、輸入文本3、分詞4、通用文字識別5、結果展示效果演示使用說明在"請輸入關鍵詞"下面的輸入框中輸入需要分詞的關鍵詞,點擊【開始通用文字識別】按鈕進行關鍵詞搜索圖片,您將會在"搜索結果"下方看到包含關鍵詞的圖片。
2021-04-14 22:35:43
從零學Elasticsearch系列——集成中文分詞器IK
2020-03-10 11:07:25
了System.out.println("標準分詞:");System.out.println(HanLP.segment("你好,歡迎使用HanLP!"
2018-11-08 15:39:04
allWords是上一步中得到的所有的詞,sentWords是第一步中對單個句子的分詞結果:4、計算相似度(兩個向量的余弦值):以上所有方法的完整代碼如下
2019-02-23 10:27:38
, 可以作為分詞標注器的用戶詞典導入,從而使分詞結果更加準確。(2)關鍵詞提取 關鍵詞提取能夠對單篇文章或文章集合,提取出若干個代表文章中心思想的 詞匯或短語,可用于精化閱讀、語義查詢和快速匹配等
2019-11-14 17:04:43
,lsi+tfidf模型對詞細粒度大、分詞少的分詞器不友好,所以最后hanlp出錯率更大。jieba與hanlp都是很不錯的分詞器,結巴使用更方便。hanlp準確度要高一些(感覺),而且與文中提到的詞向量相匹配
2018-11-14 11:07:19
表示,對一些取用水項目進行區域的限批," \66."嚴格地進行水資源論證和取水許可的批準。"67. print("="*30+"關鍵詞提取
2018-10-31 11:05:07
, 技術/n, 博客/n, !每個詞段后的 /nx,/w之類的是 HanLP定義的詞性,可以去看 HanLP的接口來獲取詳情· 文本推薦 三個關鍵字的語句推薦結果為:機器學習→[人工智能如今是非常火熱的一門
2018-11-21 11:38:50
停用詞的移除、大小寫字母轉化和詞干提取。4)獲取查詢。獲取單詞權重,對于可疑文檔利用TF-IDF獲得關鍵詞,并排序得到相應的關鍵詞列表。排在前n個的關鍵詞組成一個查詢,以此類推,本試驗中n=5。5)檢索
2016-01-26 10:38:19
提高網站關鍵詞排名的28個SEO小技巧關鍵詞位置、密度、處理 URL中出現關鍵詞(英文) 網頁標題中出現關鍵詞(1-3個) 關鍵詞標簽中出現關鍵詞(1-3個) 描述標簽中出現關鍵詞(主關鍵詞重復2次
2010-12-01 17:08:20
仿造example/speech_recognition/asr樣例寫了一個關鍵詞識別程序,識別到關鍵詞后,就播放提示音。目前關鍵詞可以正確識別,就是播放提示音的時候就報錯,報錯信息如下,請各位幫忙
2023-03-10 06:18:08
('com.hankcs.hanlp.tokenizer.NLPTokenizer')print(NLPTokenizer.segment('中國科學院計算技術研究所的宗成慶教授正在教授自然語言處理課程'))# 關鍵詞提取document = "水利部水資源司
2019-01-08 16:26:14
本篇分享一個使用hanlp分詞的操作小案例,即在spark集群中使用hanlp完成分布式分詞的操作,文章整理自【qq_33872191】的博客,感謝分享!以下為全文: 分兩步:第一步:實現
2019-01-21 10:45:23
(NLPTokenizer.segment('中國科學院計算技術研究所的宗成慶教授正在教授自然語言處理課程'))# 關鍵詞提取document = "水利部水資源司司長陳明忠9月29日在
2018-12-14 10:23:25
?網站建設 ?網站推廣 ?關鍵詞優化 ?百度地標 ?歡迎咨詢QQ:2991704102
2014-03-15 16:13:23
,相比英文分詞,中文分詞實現難度更高。NLPIR實驗室總結了幾項中文分詞難點。中文分詞概念分詞技術就是搜索引擎針對用戶提交查詢的關鍵詞串進行的查詢處理后根據用戶的關鍵詞串用各種匹配方法進行的一種技術。當然
2019-09-04 17:39:58
矩陣模型,以一個詞的起始位置作為行,終止位置作為列,可以得到一個二維矩陣。例如:“他說的確實在理”這句話圖詞的存儲方法:一種是的DynamicArray法,一種是快速offset法。Hanlp代碼中采用
2019-03-13 13:27:44
、轉化率,且與自己產品相關的關鍵詞,單獨拿出來放進 search term 里面進行優化 listing 的操作。2.自己利用一些工具去篩選出一些買家搜索詞,然后根據自己對產品的理解,買家的搜索習慣,適當
2017-06-05 15:41:28
我們可以對神經網絡架構進行優化,使之適配微控制器的內存和計算限制范圍,并且不會影響精度。我們將在本文中解釋和探討深度可分離卷積神經網絡在 Cortex-M 處理器上實現關鍵詞識別的潛力。關鍵詞識別
2021-07-26 09:46:37
`在使用Hanlp詞典進行分詞的時候,會出現分詞不準的情況,原因是內置詞典中并沒有收錄當前這個詞,也就是我們所說的未登錄詞,只要把這個詞加入到內置詞典中就可以解決類似問題,如何操作呢,下面我們來看
2019-01-25 11:06:13
、用戶自定義詞典、詞性標注),命名實體識別(中國人名、音譯人名、日本人名、地名、實體機構名識別),關鍵詞提取,自動摘要,短語提取,拼音轉換,簡繁轉換,文本推薦,依存句法分析(MaxEnt依存句法分析
2018-12-12 16:27:49
路徑;A、B、C 對應的是 ES 版本號。使用自定義詞典默認詞典是精簡版的詞典,能夠滿足基本需求,但是無法使用感知機和 CRF 等基于模型的分詞器。HanLP 提供了更加完整的詞典,請按需下載。詞典
2019-04-22 15:53:33
,組織機構名等來切分詞Elasticsearch默認分詞 輸出: IK分詞 輸出: hanlp分詞 輸出: ik分詞沒有根據句子的含義來分詞,hanlp能根據語義正確的切分出詞安裝步驟: 1
2019-07-01 11:34:33
我們可以對神經網絡架構進行優化,使之適配微控制器的內存和計算限制范圍,并且不會影響精度。我們將在本文中解釋和探討深度可分離卷積神經網絡在 Cortex-M 處理器上實現關鍵詞識別的潛力。關鍵詞識別
2019-07-23 06:59:07
的講義《The Structured Perceptron》。 本文實現的AP分詞器預測是整個句子的BMES標注序列,當然屬于結構化預測問題了。感知機二分類感知機的基礎形式如《統計學習方法》所述,是定義在
2019-01-14 11:15:41
我們在使用hanlp詞典進行分詞的時候,難免會出現分詞不準確的情況,原因是由于內置詞典中并沒有收錄當前的這個詞,也就是我們所說的未登錄詞,只要把這個詞加入到內置詞典中就可以解決類似問題,如何操作
2019-03-18 15:25:42
如何在 Cortex-M 處理器上實現高精度關鍵詞識別
2021-02-05 07:14:00
僅作為學習記錄,大佬請跳過。這些東西都是存儲器關鍵詞:RAM和ROM兩大類ROM——PROM、EPROM、E2PROM、FLASH1、RAM、ROM對電腦來說,RAM是內存,ROM是硬盤2、PROM
2021-12-10 06:46:06
模型是上述一般文本信息抽取的具體實現。 NLPIR大數據語義智能分析平臺在文本信息提取介紹方面,能夠實現新詞提取和關鍵詞提取。 新詞發現能從文本中挖掘出具有內涵的新詞、新概念,用戶可以用于專業詞典
2019-09-16 15:03:58
一夜之間關鍵詞排名掉完了,沒有被K,也沒有出現違規操作,這是怎么回事呢?
2021-01-27 11:01:21
:Java網址:hankcs/HanLP開發機構:大快搜索協議:Apache-2.0功能:非常多,主要有中文分詞,詞性標注,命名實體識別,關鍵詞提取,自動摘要,短語提取,拼音轉換,簡繁轉換,文本推薦,依存
2018-11-26 10:31:45
網站定位之關鍵詞的選取 策劃網站首先需要策劃的是我們網站的主題,而一份網站的主題是用關鍵字息息相關的,怎么策劃和選擇關鍵字以及如何在關鍵字巧妙的使用長尾以及百度分詞,才能夠最大化的利用標題
2011-04-19 15:03:12
)、基于 CRF 模型的分詞、N- 最短路徑分詞等。實現了不少經典分詞方法。Hanlp 的部分模塊做了重要優化,比如雙數組,匹配速度很快,可以直接拿過來使用。Hanlp 做了不少重現經典算法的工作,可以去
2018-10-26 13:48:43
`自然語言處理工具hanlp關鍵詞提取圖解TextRank算法 看一個博主(亞當-adam)的關于hanlp關鍵詞提取算法TextRank的文章,還是非常好的一篇實操經驗分享,分享一下給各位需要
2019-02-20 11:06:29
data版和ptotable版,對于一般的分詞而言,protable完全就可以滿足要求。另外還有一些其他的操作,例如詞性識別,也是實際應用中比較多的。當然其他的類似關鍵詞提取,情感識別做個參考也就
2018-11-28 10:02:37
請問DSP里如何確定ioport關鍵詞定義的地址對應的引腳?
2013-06-28 15:48:25
我想在在verilog文件中引入環,但是總是被quartus的綜合優化掉,請問quartus有類似于vivado * ALLOW_COMBINATORIAL_LOOPS = "true"的關鍵詞嗎?
2022-01-07 11:10:24
給出一種適用于在線垃圾模型的基于動態排位信息的關鍵詞確認方法,利用識別過程中聲學得分的排位信息進行關鍵詞確認,能在不降低檢出率的同時有效降低系統的誤警率,效果
2009-04-23 09:29:00 11
11 歧義詞的切分是中文分詞要面對的數個難題之一,解決好了這個問題就能夠有力提升中文分詞的正確率。對此,本文簡要介紹了漢語分詞的概況,并具體分析了當前中文分詞技術
2010-01-15 16:09:4118 2009年中國照明行業十大關鍵詞
一、節能推廣
關鍵詞:節能推廣
事
2009-12-15 10:24:05838 文本的關鍵詞識別是文本挖掘中的基本問題之一。在研究現有基于復雜網絡的關鍵詞識別方法的基礎上,從整個復雜網絡拓撲結構特征的信息缺失角度來考察各節點的重要程度。提出強度熵測度來量化評估各節點重要程度,用于解決中文關鍵詞識別問題。實驗結果表明,該評估方法簡單有效,特別適用于帶權復雜網絡的節點重要性評估。
2017-11-24 09:54:287 為改進基于關鍵詞的最優路徑查詢算法,在大規模圖以及多查詢關鍵詞下復雜度過高與可擴展性不足的缺陷,依據查詢關鍵詞序列構建候選路徑的策略提出一種高效查詢算法。該算法在路徑構建過程中優先滿足查詢關鍵詞的全
2017-12-06 11:28:210 人員參考。文中根據世界知識或分類體系計算詞語語義距離后轉化為詞語相似度的方法,將詞語間距離依據詞頻、詞權重等因子加工計算出關鍵詞集合間相似度矩陣后,用歐式距離表示其關鍵字集的相似度;之后聚類算法利用現有R軟件中開
2017-12-13 10:15:500 在云計算中,用戶在計算過程中的數據安全問題已經成為制約云計算發展的一個瓶頸。本文針對云計算中的加密搜索問題,提出一個有效的加密搜索方案。在搜索過程中,為保證用戶的數據安全,用戶需要隱藏搜索的關鍵詞
2017-12-14 14:14:350 在TF-IDF算法基礎上,提出新的基于詞頻統計的關鍵詞提取方法。利用段落標注技術,對處于不同位置的詞語給予不同的位置權重,對分詞結果中詞頻較高的同詞性詞語進行詞語相似度計算,合并相似度較高的詞語
2017-12-15 15:29:1413 科學、心理學和社會科學等多個方面研究了自動關鍵詞抽取的理論基礎.從宏觀、中觀和微觀角度,回顧和分析了自動關鍵詞抽取的發展、技術和方法.針對目前廣泛應用的自動關鍵詞抽取方法,包括統計法、基于主題的方法、基于網絡圖
2017-12-26 16:47:352 本章第一節就介紹基于關鍵詞生成一段文本的一些處理技術。其主要是應用關鍵詞提取、同義詞識別等技術來實現的。下面就對實現過程進行說明和介紹。
2017-12-26 18:12:4011481 
。? ? ? ? HanLP能提供以下功能:關鍵詞提取、短語提取、繁體轉簡體、簡體轉繁體、分詞、詞性標注、拼音轉換、自動摘要、命名實體識別(地名、機構名等)、文本推薦等功能,詳細請參見以下鏈接:http
2018-10-16 09:31:04622 的。elasticsearch-hanlpHanLPHanLP?是一款使用 Java 實現的優秀的,具有如下功能:中文分詞詞性標注命名實體識別關鍵詞提取自動摘要短語提取拼音轉換簡繁轉換文本推薦依存句法分析語料庫工具安裝
2018-10-17 15:11:50540 HanLP介紹:http://hanlp.linrunsoft.com/?github地址:https://github.com/hankcs/HanLP?說明:使用hanlp實現分詞、智能
2018-10-17 15:13:201323 ),而且與文中提到的詞向量相匹配。(我免貴姓AI,jieba:我免/貴姓/AI,hanlp:我/免/貴姓/AI,實際:我/免貴/姓AI)參考資料:自然語言處理 中文分詞 詞性標注 命名實體識別 依存句法分析 關鍵詞提取 新詞發現 短語提取 自動摘要 文本分類 拼音簡繁文章來源于gladosAI的博客
2018-10-17 16:08:29350 ? ? ? ? System.out.println("標準分詞:");? ? ? ? System.out.println(HanLP.segment("你好,歡迎使用HanLP
2018-10-17 17:26:30447 實體識別,她用了一個很有意思的方法,自己改了HanLP的詞典,手動加了好多詞,而且后期版本迭代中還有可能繼續改。。。。改了HanLP的詞典就意味著不能用maven直接導入倉庫里的包了,只能直接將修改后
2018-10-18 14:33:32247 模型,以一個詞的起始位置作為行,終止位置作為列,可以得到一個二維矩陣。例如:“他說的確實在理”這句話圖詞的存儲方法:一種是的DynamicArray法,一種是快速offset法。Hanlp代碼中采用
2018-10-18 14:40:52398 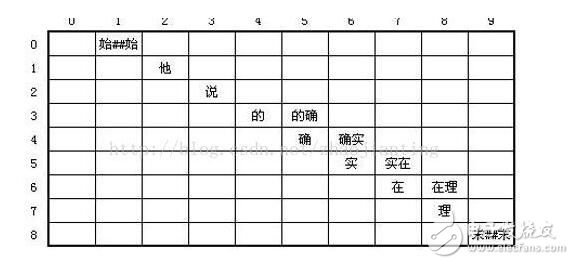
版本還是發現沒有client文件夾,放棄在python中調用java包Hanlp,直接在java程序中使用hanlp。11大Java開源中文分詞器的使用方法和分詞效果對比:http
2018-10-18 14:53:19339 前言 以前,我對大部分的處理中文分詞都是使用python的結巴分詞工具,該分詞工具是在線調用API, 關于這個的分詞工具的原理介紹,我推薦一個好的博客:?http://blog.csdn.net
2018-10-18 15:05:46318 = fs.create(new Path(path));? ? ? ? ? ? return out;? ? ? ? }? ? }3.設置IoAdapter,創建分詞器:private static
2018-11-07 09:33:31528 閱讀目錄手記實用系列文章:代碼封裝類:運行效果:手記實用系列文章:1?結巴分詞和自然語言處理HanLP處理手記2?Python中文語料批量預處理手記3?自然語言處理手記4?Python中調用自然語言
2018-11-07 09:35:28461 最近在學習用hanlp分詞做關鍵詞提取,但是現在有一個問題,雖然hanlp中各種功能直接調用很方便了,那么如果我需要從人名識別中僅僅提取出人名怎么操作呢?我按照官方的示例代碼,發現輸出的list
2018-11-08 15:50:28550 ?8.?11.?12.?13.?14.?15.?16.?17.?18.?19.??意思是默認文本字段類型啟用HanLP分詞器,text_general還開啟了solr默認的各種filter。solr
2018-11-29 14:36:05658 參考論文:《TextRank: Bringing Order into Texts》TextRank算法提取關鍵詞的Java實現TextRank算法自動摘要的Java實現這篇文章中作者大概解釋了一下
2018-11-29 14:44:35629 THULAC 、斯坦福分詞器、Hanlp 分詞器、jieba 分詞、IKAnalyzer 等。這里針對 jieba 和 HanLP 分別介紹不同場景下的中文分詞應用。jieba 分詞jieba 安裝(1
2018-11-29 14:45:451024 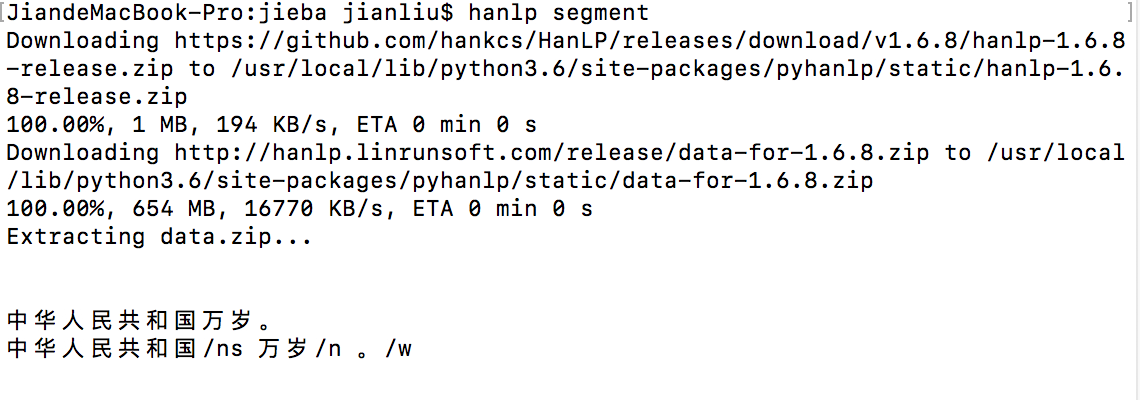
/elasticsearch-analysis-hanlpElasticsearch默認分詞?輸出:?IK分詞?輸出:?hanlp分詞?輸出:?ik分詞沒有根據句子的含義來分詞,hanlp能根據語義正確的切分出詞安裝步驟:?1、進入https
2018-11-29 15:01:08650 Textrank轉移概率矩陣計算過程,同時通過迭代運算對文檔中的詞語進行綜合影響力得分排序,最終提取得分最高的TopN個詞語作為關鍵詞。實驗結果表明,當選取Top3、Top5、Top7和Topl0個關鍵詞時,與基于詞向量聚類質心與 Textrank加權的關鍵詞抽取方法相比,該方法的平均F值
2021-03-21 09:55:1918 結合通配符模式與引入先驗信息的隨機游走算法,提出一種改進的關鍵詞提取方法。使用通配符約束捕獲詞語之間的語義關系,提取滿足間隙約東和一次性條件的順序模式以計算模式支持度,并在模式支持度大于等于最小
2021-03-27 10:36:4014 各類應用領域的文本數據日益增多,如何從這些海量數據中迅速準確地提取核心內容,已成為關鍵詞抽取的主要任務。提出一種基于詞和文檔嵌入的關鍵詞抽取方法,通過計算單詞與文檔在同一維度上的向量表示,得出每個
2021-04-02 14:59:554 關鍵詞提取是進行未知網絡協議逆向的關鍵步驟。鑒于現有的關鍵詞提取方法存在精確度不髙、需要較多先驗知識、操作繁瑣等問題,提出了一種基于位置信息的關鍵詞自動化提取算法。首先,通過 Trigram分詞獲取
2021-04-25 13:56:353 電子發燒友網站提供《TinyML變得簡單:關鍵詞識別(KWS).zip》資料免費下載
2023-07-13 10:20:245 ? ??在電商、內容平臺等應用中,用戶經常通過輸入關鍵詞搜索商品并獲取詳情。設計一個高效、可靠的API接口是核心需求。本文將逐步介紹如何設計并實現一個“搜索關鍵詞獲取商品詳情”的接口,涵蓋
2025-10-20 15:37:57380 
格式的字符串)。 關鍵詞與搜索結果的關聯性 :關鍵詞的精準度決定爬取結果的相關性,京東搜索會對關鍵詞進行分詞匹配(如 “Python 實戰書籍” 會拆分匹配 “Python”、“實戰”、“書籍”)。 請求參數中的關鍵詞傳遞 :在之前的爬蟲代碼中,關鍵詞通過
2026-01-04 10:40:5822 ? ?在電商領域,曝光率是決定商品銷量的關鍵因素之一。淘寶作為國內領先的電商平臺,提供了強大的搜索API接口,幫助開發者構建關鍵詞優化工具,從而提升商品在搜索結果中的排名和曝光。本文將詳細介紹淘寶
2026-01-05 15:38:0212
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論