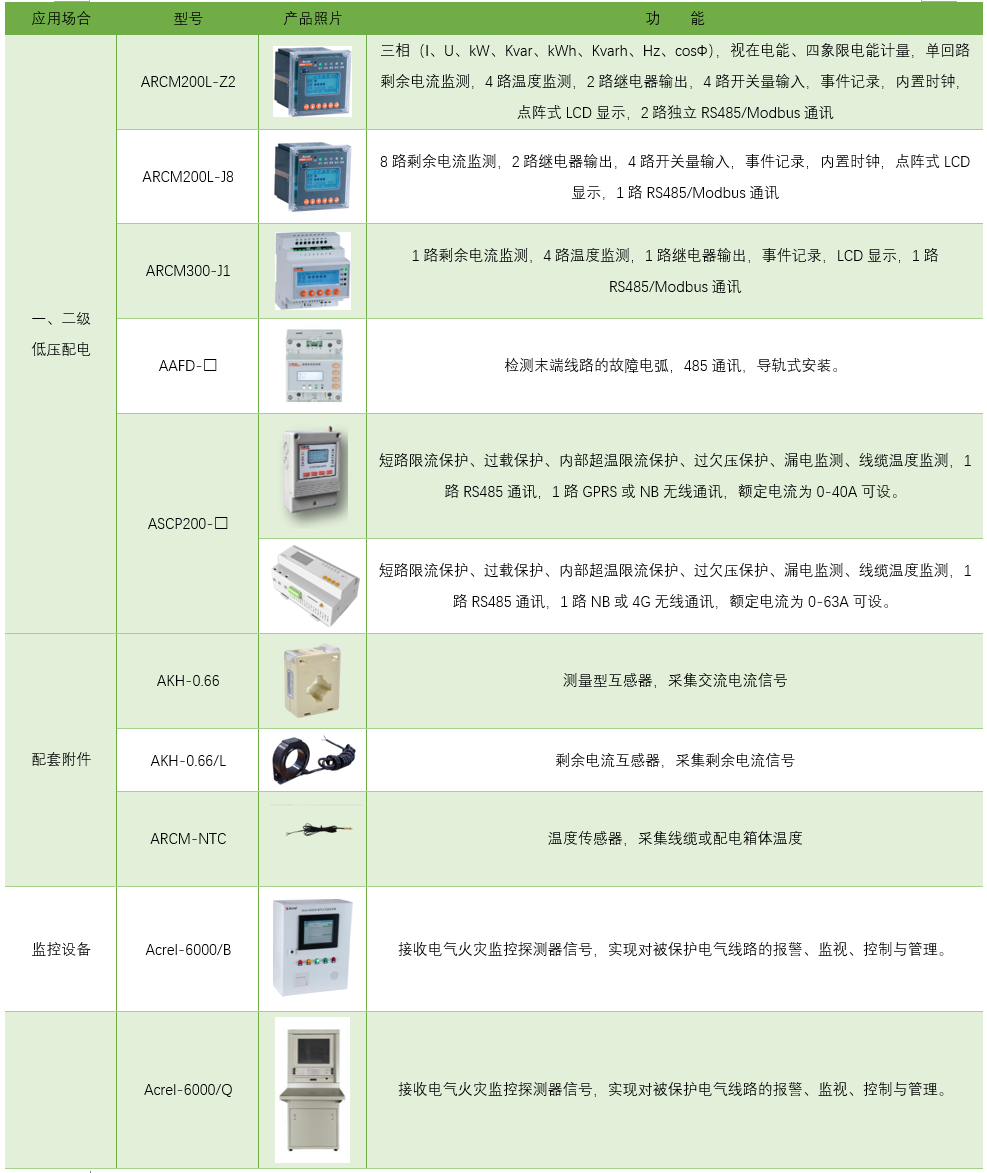
 電子發燒友App
電子發燒友App



背景介紹
餓了么監控系統EMonitor:是一款服務于餓了么所有技術部門的一站式監控系統,覆蓋了系統監控、容器監控、網絡監控、中間件監控、業務監控、接入層監控以及前端監控的數據存儲與查詢。每日處理總數據量近PB,每日寫入指標數據量百T,每日指標查詢量幾千萬,配置圖表個數上萬,看板個數上千。
CAT:是基于Java 開發的實時應用監控平臺,為美團點評提供了全面的實時監控告警服務
本文通過對比分析下2者所做的事情為契機討論監控系統或許該有的面貌,以及淺談下監控系統發展的各個階段
CAT做的事情(開源版)
首先要強調的是這里我們只能拿到github上開源版CAT的最新版3.0.0,所以是基于此進行對比
接下來說說CAT做了哪些事情?
1 抽象出監控模型
抽象出Transaction、Event、Heartbeat、Metric 4種監控模型。
Transaction:用來記錄一段代碼的執行時間和次數
Event:用來記錄一件事發生的次數
Heartbeat:表示程序內定期產生的統計信息, 如CPU利用率
Metric:用于記錄業務指標,可以記錄次數和總和
針對Transaction和Event都固定了2個維度,type和name,并且針對type和name進行分鐘級聚合成報表并展示曲線。
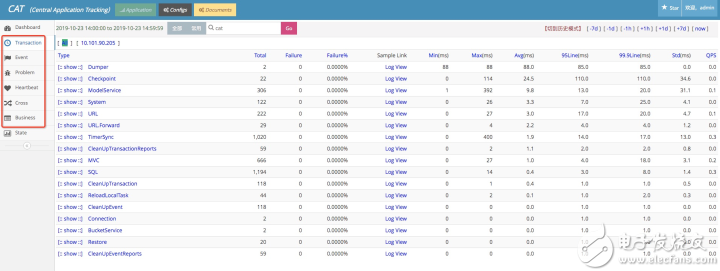
2 采樣鏈路
針對上述Transaction、Event的type和name分別有對應的分鐘級的采樣鏈路
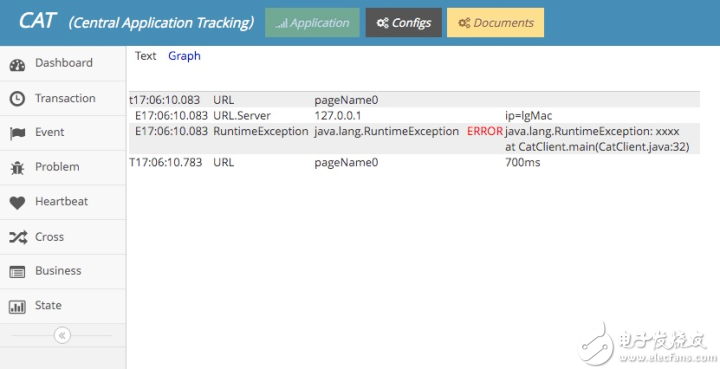
3 自定義的Metric打點
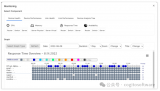
目前支持Counter和Timer類型的打點,支持tag,單機內單個Metric的tag組合數限制1000。 并且有簡單的監控看板,如下圖所示:
4 與其他組件集成
比如和Mybatis集成,在客戶端開啟相關的sql執行統計,并將該統計劃分到Transaction統計看板中的type=SQL的一欄下
5 告警
可以針對上述的Transaction、Event等做一些簡單的閾值告警
餓了么EMonitor和CAT的對比
餓了么EMonitor借鑒了CAT的相關思想,同時又進行了改進。
1 引入Transaction、Event的概念
針對Transaction和Event都固定了2個維度,type和name,不同地方在于聚合用戶發過來的數據
CAT的架構圖如下所示:
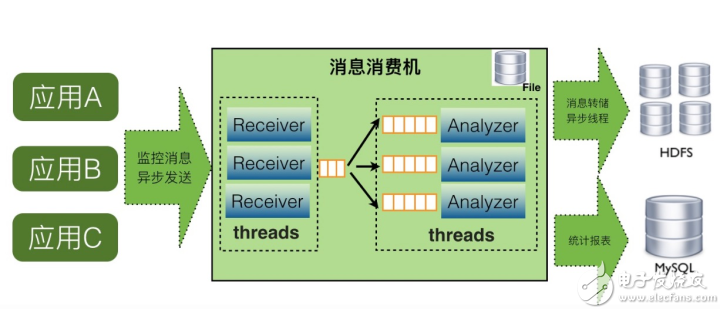
CAT的消費機需要做如下2件事情:
對Transaction、Event等消息模型按照type和name進行當前小時的聚合,歷史小時的聚合數據寫入到mysql中
將鏈路數據寫入到本地文件或者遠程HDFS上
EMonitor的架構圖如下所示:
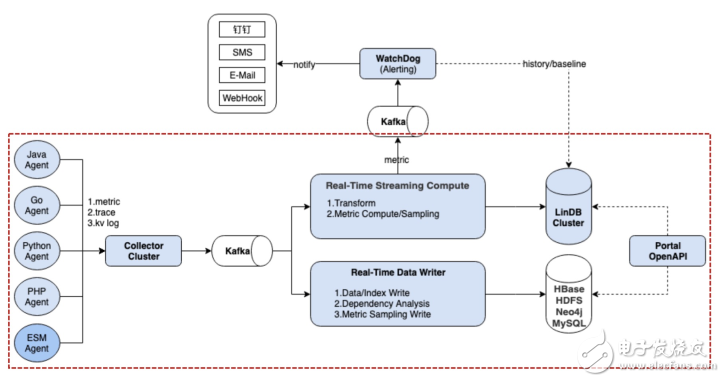
EMonitor分2路對數據進行隔離處理:
Real-Time Streaming Compute:對用戶發過來的鏈路中的Transaction、Event等監控模型轉變成指標數據并進行10s的預聚合,同時也對用戶發過來的Metric數據進行10s預聚合。最后將10s預聚合的數據寫入到LinDB時序數據庫(已開源,有興趣的可以關注star下)中,以及kafka中,讓告警模塊watchdog去消費kafka做實時告警
Real-Time Data Writer:對用戶發過來的鏈路數據構建鏈路索引、向HDFS和HBase寫入索引和鏈路數據,同時會構建應用之間的依賴關系,將依賴關系寫入到Neo4j中
所以EMonitor和CAT的一個很大不同點就在于對指標的處理上,EMonitor交給專業的時序數據庫來做,而CAT自己做聚合就顯得功能非常受限,如下所示:
CAT只能整小時的查看type和name數據,不能跨小時,即不能查看任意2個時間之間的報表數據,EMonitor沒有此限制
CAT沒法查看所有type匯總后的響應時間和QPS,EMonitor可以靈活的自由組合type和name進行聚合
CAT的type和name報表是分鐘級的,EMonitor是10s級別的
CAT的type和name沒能和歷史報表曲線直接對比,EMonitor可以對比歷史報表曲線,更容易發現問題
CAT的type和name列表首頁展示了一堆數字,無法立即獲取一些直觀信息,比如給出了響應時間TP99 100ms這個到底是好還是壞,EMonitor有當前曲線和歷史曲線,相對來說可以直接判斷到底ok不ok
CAT的TP99、TP999基于單機內某個小時內的報表是準確的,除此之外多機或者多個小時的聚合TP99、TP999是用加權平均來計算的,準確性有待提高
但是CAT也有自己的優勢:
CAT含有TP999、TP9999線(但是準確性還有些問題),EMonitor只能細到TP99
CAT的type和name可以按照機器維度進行過濾,EMonitor沒有做到這么細粒度
2 采樣鏈路
目前CAT和EMonitor都可以通過type和name來過濾采樣鏈路,不同點在于
CAT的采樣鏈路是分鐘級別的,EMonitor是10s級別的
針對某一個type和name,CAT目前無法輕松找想要的鏈路,EMonitor可以輕松的找到某個時刻或者說某段時間內響應時間想要的鏈路(目前已經申請專利)
EMonitor的鏈路如下所示:
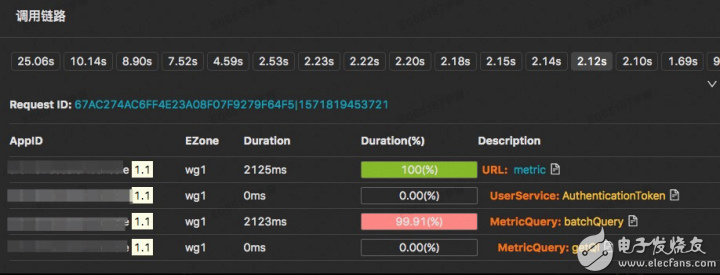
這張圖是某個10s時刻、某個type和name過濾條件下的采樣鏈路
第一行是這10s內的采樣鏈路,按照響應時間進行了排序
可以隨意點擊某個響應時間來查看對應的鏈路詳情
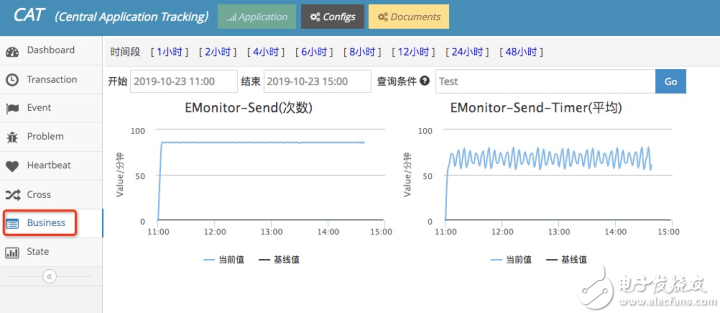
3 自定義的Metric打點
EMonitor支持Counter、Timer、Histogram、Payload、Gauge等等多種形式的打點方式,并且支持tag
Counter:計數累加類型
Timer:可以記錄一段代碼的耗時,包含執行次數、耗時最大值、最小值、平均值
Histogram:包含Timer的所有東西,同時支持計算TP99線,以及其他任意TP線(從0到100)
Payload:可以記錄一個數據包的大小,包含數據包個數、包的最大值、最小值、平均值
Gauge:測量值,一般用于衡量隊列大小、連接數、CPU、內存等等
也就是任意Metric打點都可以流經EMonitor進行處理了并輸送到LinDB時序數據庫中。至此,EMonitor就可以將任何監控指標統一在一起了,比如機器監控都可以通過EMonitor來保存了,這為一站式監控系統奠定了基礎
自定義Metric看板
CAT只有一個簡易的Metric看板 EMonitor針對Metric開發了一套可以媲美Grafana的指標看板,相比Grafana的優勢:
有一套類似SQL的非常簡單的配置指標的方式
跟公司人員組織架構集成,更加優雅的權限控制,不同的部門可以建屬于自己的看板
指標和看板的收藏,當源指標或看板改動后,無需收藏人員再改動
alpha、beta、prod不同環境之間的一鍵同步指標和看板,無需配置多次
PC端和移動端的同步查看指標和看板
類SQL的配置查詢指標方式如下所示:
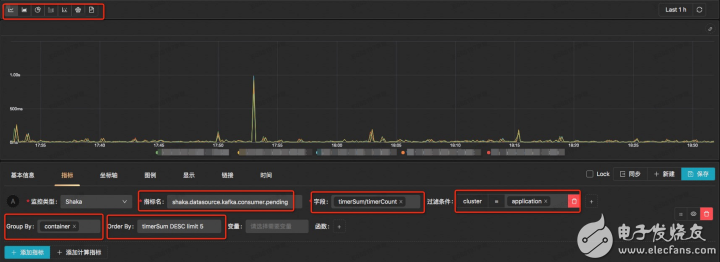
可以配置圖表的展現形式
可以配置要查詢的字段以及字段之間的加減乘除等豐富的表達式
可以配置多個任意tag的過濾條件
可以配置group by以及order by
看板整體如下所示:
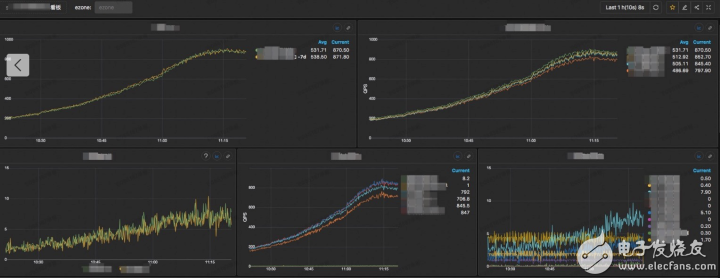
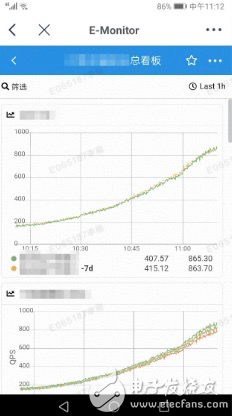
移動端顯示如下:
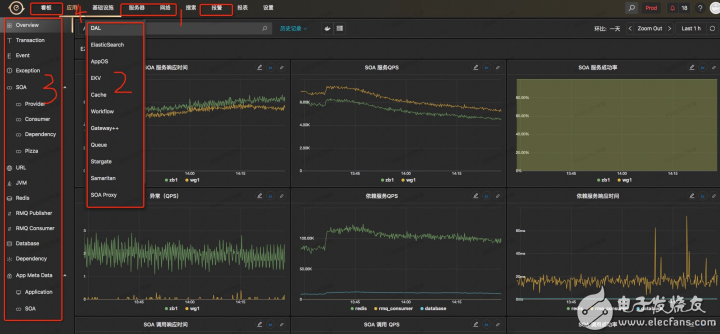
4 與其他組件集成
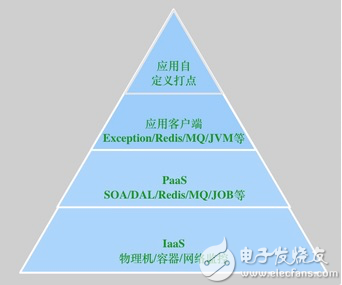
目前EMonitor已經打通了IaaS層、PaaS層、應用層的所有鏈路和指標的監控,再也不用在多個監控系統中切換來切換去了,如下所示
1 IaaS層物理機、機房網絡交換機等的監控指標
2 PaaS層中間件服務端的監控指標
3 應用層SOA、Exception、JVM、MQ等客戶端的相關指標
4 應用層自定義的監控指標
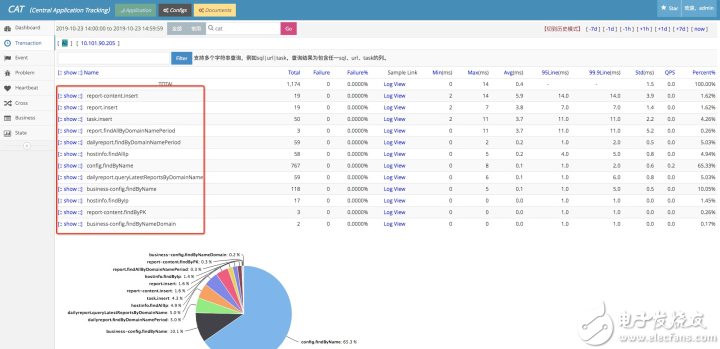
以打通餓了么分庫分表中間件DAL為例:
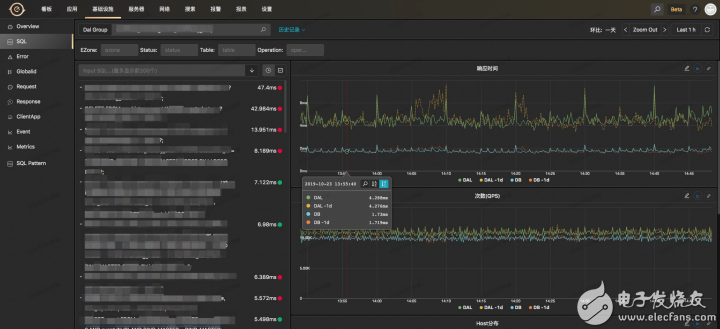
可以根據機房、執行狀態、表、操作類型(比如Insert、Update、Select等)進行過濾查看
左邊列表給出每條SQL的執行的平均耗時
右邊2個圖表給出該條SQL在DAL中間件層面、DB層面的耗時以及調用QPS
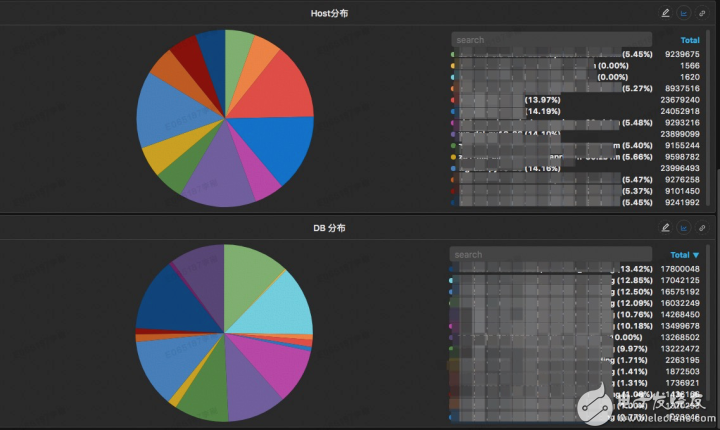
可以給出該SQL打在后端DAL中間、DB上的分布情況,可以用于排查是否存在一些熱點的情況
還有一些SQL查詢結果的數據包大小的曲線、SQL被DAL限流的情況等等
可以查看任何時間點上該SQL的調用鏈路信息
再以打通餓了么SOA服務為例:
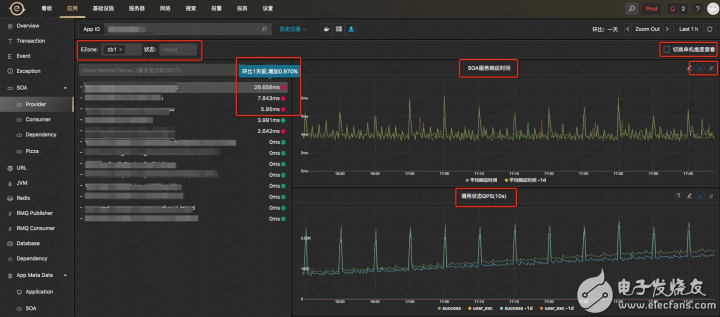
可以根據機房和狀態信息進行過濾
左邊一欄列出該應用提供的SOA服務接口,同時給出平均響應時間以及和昨天的對比情況
右邊的2個圖表分別給出了對應服務接口的服務響應時間和QPS以及和昨天的對比情況,同時可以切換平均響應時間到TP99或者其他TP值,同時配有可以快速對相關曲線添加告警的跳轉鏈接
可以切換到單機維度來查看每臺機器該SOA接口的響應時間和QPS,用來定位某臺機器的問題
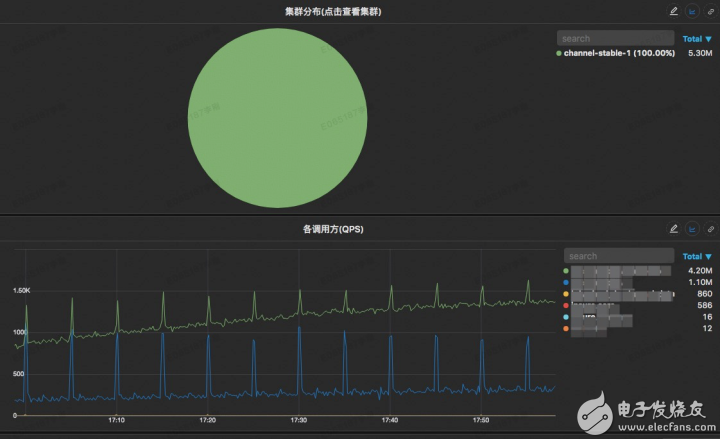
可以給出該SOA接口調用在不同集群的分布占比
可以給出該SOA接口的所有調用方以及他們的QPS
可以查看任何時間點上該SOA接口的調用鏈路信息
5 告警
可以針對所有的監控指標配置如下告警方式:
閾值:簡單的閾值告警,適用于CPU、內存等
同環比:與過去同期比較的告警
趨勢:適合于相對平滑連續的無需閾值的智能告警
其他告警形式
淺談監控系統的發展趨勢
1 日志監控階段
本階段實現方式:程序打日志,使用ELK來存儲和查詢程序的運行日志,ELK也能簡單顯示指標曲線
排障過程:一旦有問題,則去ELK中搜索可能的異常日志來進行分析排障
2 鏈路監控階段
上一個階段存在的問題:ELK只是基于一行一行日志進行聚合或者搜索分析,日志之間沒有上下文關聯。很難知道一次請求耗時較長究竟耗時在哪個階段
本階段實現方式:CAT橫空出世,通過建模抽象出Transaction、Metric等監控模型,將鏈路分析和簡單的報表帶入了大家的視野
告警方式:針對報表可以進行閾值監控 排障過程:一旦有告警,可以通過點擊報表來詳細定位到是哪個type或name有一定問題,順便找到對應的鏈路,查看詳細的信息
3 指標監控階段
上一階段存在的問題:CAT對自定義指標支持的比較弱,也無法實現或者展現更加多樣的查詢聚合需求
本階段的實現方式:支持豐富的Metric指標,將鏈路上的一些報表數據也可以劃分到指標中,交給專業的時序數據庫來做指標的存儲和查詢,對接或者自研豐富的指標看板如Grafana
告警方式:針對指標進行更加豐富的告警策略 排障過程:一旦有告警,可能需要到各個系統上查看指標看板,粗略定位根因,再結合鏈路總和分析
4 平臺打通整合階段
上一階段存在的問題:系統監控、中間件和業務監控、部分業務監控、鏈路監控與指標監控都各搞一套數據收集、預處理、存儲、查詢、展現、告警流程,各個系統處理數據格式、使用方式不統一
本階段的實現方式:打通從系統層面、容器層面、中間件層面、業務層面等等的可能的鏈路和指標監控,統一數據的處理流程,同時整合發布、變更、告警與監控曲線結合,成為一站式監控平臺
告警方式:可以統一的針對各個層面的監控數據做統一化的告警 排障過程:只需要在一個監控系統中就可以查看到所有的監控曲線和鏈路信息
目前我們EMonitor已完成這個階段,將公司之前存在已久的3套獨立的監控系統統一整合成現如今的一套監控系統
5 深度分析階段
上一階段存在的問題:
用戶雖然可以在一個系統中看到所有各個層面的監控數據了,但是每次排障時仍然要花很多的時間去查看各個層面是否有問題,一旦漏看一項可能就錯過了問題所在的根因
沒有整個業務的全局監控視角,都停留在各自應用的角度
總之:之前的階段都是去做一個監控平臺,用戶查詢什么指標就展示相應的數據,監控平臺并不去關心用戶所存儲數據的內容。現在呢就需要轉變思路,監控平臺需要主動去幫用戶分析里面所存儲的數據內容
本階段的實現方式:所要做的就是把幫用戶分析的過程抽象出來,為用戶構建應用大盤和業務大盤,以及為大盤做相關的根因分析。
應用大盤:就是為當前應用構建上下游應用依賴的監控、當前應用所關聯的機器監控、redis、MQ、database等等監控,可以時刻為應用做體檢,來主動暴露出問題,而不是等用戶去一個個查指標而后發現問題
業務大盤:就是根據業務來梳理或者利用鏈路來自動生產大盤,該大盤可以快速告訴用戶是哪些業務環節出的問題
根因分析:一個大盤有很多的環節,每個環節綁定有很多的指標,每次某個告警出來有可能需要詳細的分析下每個環節的指標,比如消費kafka的延遲上升,有各種各樣的原因都可能導致,每次告警排查都需要將分析流程再全部人為分析排查下,非常累,所以需要將定位根因的過程通過建模抽象下,來進行統一解決
趨勢報表分析:主動幫用戶發現一些逐漸惡化的問題點,比如用戶發布之后,接口耗時增加,很可能用戶沒有發現,雖然當前沒有問題,但是很有可能在明天的高峰期就會暴露問題,這些都是已經實實在在發生的事故
要想做主動分析,還深度依賴指標下鉆分析,即某個指標調用量下降了,能主動分析出是哪些tag維度組合導致的下降,這是上述很多智能分析的基礎,這一塊也不簡單
告警方式:可以統一的針對各個層面的監控數據做統一化的告警 排障過程:NOC根據業務指標或者業務大盤快速得知是哪些業務或者應用出先了問題,應用的owner通過應用大盤的體檢得知相關的變動信息,比如是redis波動、database波動、上下游應用的某個方法波動等等,來達到快速定位問題目的,或者通過對大盤執行根因分析來定位到根因
再談Logging、Tracing、Metrics
常見一張3者關系的圖
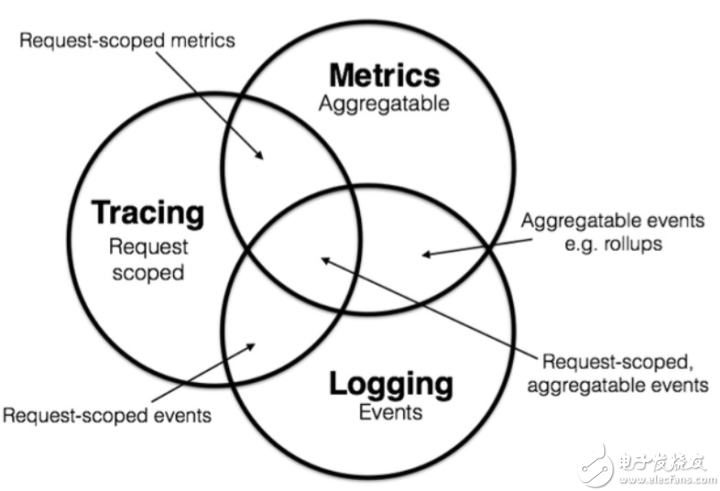
三者的確都不可或缺,相輔相成,但是我想說以下幾點:
三者在監控排障中的所占比例卻大不一樣:Metrics占據大頭,Tracing次之,Logging最后
Tracing含有重要的應用之間的依賴信息,Metrics有更多的可深度分析和挖掘的空間,所以未來必然是在Metrics上大做文章,再結合Tracing中的應用依賴來做更深度全局分析,即Metrics和Tracing兩者結合發揮出更多的可能性
參考鏈接: CAT:https://github.com/dianping/cat深度剖析開源分布式監控CAT:https://tech.meituan.com/2018/11/01/cat-in-depth-java-application-monitoring.html
作者信息:李剛,網名乒乓狂魔,餓了么監控組研發專家,餓了么內部時序數據庫LinDB項目負責人,目前致力于監控的智能分析領域。
本文為云棲社區原創內容,未經允許不得轉載






























 工商網監
工商網監
評論