BigData“大數據”是繼云計算、物聯網之后TI產業又一次顛覆性的技術變革。當今信息時代所產生的數據量已經大到無法用傳統的工具進行采集、存儲、管理與分析。全球產生的數據量,僅在2011就達到1ZB,且根據預測,未來十年全球數據存儲量將增長50倍。大數據不是云計算,是云計算的靈魂和升級方向。
2014-05-22 10:17:26 1543
1543 根據IDC預測,全球在2010年正式進入ZB時代,全球數據量大約每兩年翻一番,意味著人類在最近兩年產生的數據量相當于之前產生的全部數據量。爆炸式增長的數據,正推動人類進入大數據的時代。
2015-12-15 08:37:43975 本文通過MyBatis一個低版本的bug(3.4.5之前的版本)入手,分析MyBatis的一次完整的查詢流程,從配置文件的解析到一個查詢的完整執行過程詳細解讀MyBatis的一次查詢流程,通過本文
2022-10-10 11:42:332026 上篇文章我們介紹過通過 Mybatis Plus 進行增刪改查,如下這段代碼: /** * 根據id修改 * UPDATE user SET user_name=?, user_age
2023-09-25 15:06:541517 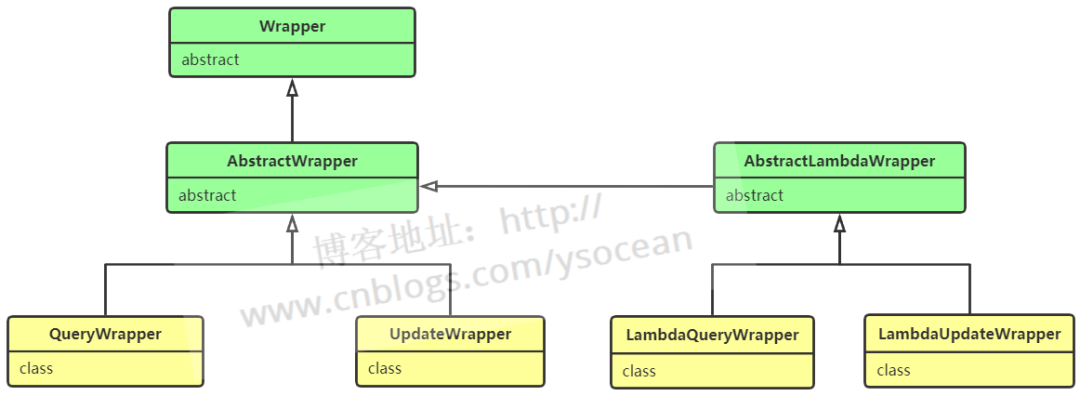
作者:京東保險 王奕龍 物流的分揀業務在某些分揀場地只有一個數據源,因為數據量比較大,將所有數據存在一張表內查詢速度慢,也為了做不同設備數據的分庫管理,便在這個數據源內創建了多個不同庫名但表完全相同
2024-12-12 10:23:161652 SpringBoot-15-之整合MyBatis-注解篇+分頁
2019-10-28 08:09:33
Mybatis第一講
2020-06-04 15:33:44
一個輕量的方案, 令mybatis支持數據庫輕兼容
2020-04-09 17:44:06
來源:互聯網隨著物聯網不斷的發展的趨于成熟期,我們同時也收集了更多的信息數據,其實就是所謂的大數據。換個說法,也就是說物聯網和大數據可以互相協作。據統計《福布斯》預測,到2025年,生成的數據量將增加到175 ZB。這將對收集、分析和報告數據的方式產生巨大的影響。
2020-10-22 06:01:50
,挖掘數據定義:基于前面的查詢數據進行數據挖掘,來滿足高級別的數據分析需求。特點和挑戰:算法復雜,并且計算涉及的數據量和計算量都大。使用的產品:R,HadoopMahout
2018-06-11 16:41:53
大數據是對海量數據進行存儲、計算、統計、分析處理的一系列處理手段,處理的數據量通常是TB級,甚至是PB或EB級的數據,這是傳統數據處理手段所無法完成的,其涉及的技術有分布式計算、高并發處理、高可用
2018-04-08 16:50:41
微服務 SpringBoot 20(九):整合Mybatis
2019-07-16 11:03:31
數據量大,現在的軟件分析效率太低,操作也麻煩,有沒有更適合的數據分析軟件?或許BI數據分析軟件會是個好選擇。奧威軟件旗下的OurwayBI就是一款專做大數據可視分析的軟件,能在極短時間內完成億級數據
2020-12-29 11:33:27
,數據量只增不減, 急需一個分析海量數據不掉鏈子的數據分析軟件,那么,在大數據bi軟件中,能做到這點的有哪些?帆軟、奧威軟件、永洪、億信華辰還是其他?國內排名靠前的幾個老牌bi軟件基本都實現了億級數據秒分析
2023-01-16 10:11:50
各位大神,我想在ACCESS中根據數據量建立不同表格保存數據,還能再查詢嗎
2015-11-28 21:12:04
傳統IDC部署網站(MariaDB慢查詢日志,Tomcat_JDK部署)
2019-05-10 14:54:54
我買了一個研華的8681E開發板,核心用的是C6678,我想使用PCIE接口,結合VLFFT程序,實現持續的大數據量的FFT變換,但是我不知道如何在VLFFT程序的基礎上進行修改,加入PCIE的傳輸
2018-06-19 06:11:55
VS1053只支持ogg和wav格式錄音,但是錄下來6秒的文件數據量大概有100k,請問有沒有辦法減小數據量,或者解碼的時候采用MP3解碼?
2019-01-21 06:36:07
你好,請問怎么查看USB 走線每幀傳輸的圖像數據量
2025-05-14 06:12:18
單片機作為服務器,PC作為客戶端,通過上位機讀取單片機flash中的數據,遵從TCPModbus協議。現在就是頻繁大數據量收發會導致服務器主動斷開連接,然后客戶端就連不上了,也ping不通,希望各位大神幫忙分析一下,或者給個排查問題的思路。
2020-03-18 04:35:33
從傳感器(導航接收機)用串口讀數據,由于一幀數據量較大,且傳感器輸出波特率較慢,導致讀取特別慢,有0.3s。但系統需要每10ms 迭代一次算法,請問有什么方案可以使讀數據不占用DSP時間?DMA?PRU?
2019-09-06 08:42:19
大數據(big data)目錄1什么是大數據2大數據的定義3大數據的特點[1]4大數據的作用[2]5大數據的分析6大數據的技術7大數據的處理8大數據的常見誤解9大數據時代存儲所面對的問題[3]10大數據應用與案例分析11相關條目12參考文獻什么是大數據...
2021-07-12 06:52:21
我目前正在使用 CYW20829 的 BLE 進行最大數據發送應用,我使用的是 FREERTOS(例程 Bluetooth_LE_GATT_Throughput_Server 是我的參考),藍牙被
2024-07-23 07:56:17
我現在有一個程序,需要采集大量數據:20數據每秒,每次采集需要持續幾個到十幾個小時,并且將數據顯示在xy圖上,程序在剛開始運行的時候可以順暢,但是一段時間后,隨著數據量的增加,xy圖就有點慢,導致整個運行都會被拖慢,采集數據的速度也打不到20數據每秒了,這個要怎么處理?
2019-09-30 09:42:09
有些小伙伴還會遇到手機充電很慢的問題,只能干著急,那么手機為什么會出現充電慢的現象呢?是什么原因導致的呢?要如何解決?接下來小編就來教你如何解決手機充電慢的問題。1、充電 插頭 導致手機充電慢選用了錯誤規格的充電插...
2021-09-14 07:04:05
在CCSV4.2 平臺上運行 OMAPL138 的EVM。現在有一個大數據量的數組加入到工程,由于數據量超過了片內存儲器,需要在DDR2中分配一片空間來存儲該數據。
第一步: 在DSP/BIOS 中
2018-06-21 00:58:29
HAL庫在大數據量頻繁收發時為什么會出現串口接收失效呢?怎樣去解決HAL庫在大數據量頻繁收發時出現串口接收失效的問題?
2021-12-08 07:53:40
目前在做httpserver,發現發送小數據時沒有問題,但當發送大數據量時,發現write函數,無法返回,一路跟蹤下來發現卡死在u32_t sys_arch_sem_wait(sys_sem_t
2019-07-16 22:28:02
我用UART串口現在只能發送和接收低于20字節的小數據量,但是發送大數據量串口會卡死或者嚴重丟包是怎么回事?
2019-05-07 17:39:20
仿真器是 SEED XDS510PLUS單步執行時,速度非常慢,一條賦值指令也要幾秒鐘.如何解決?
2018-07-27 09:38:04
請教下,c8051 的串口發送是采用查詢方式還是中斷方式好 ?? 發送數據量不是很大。
2019-05-08 00:12:04
這種圖這么做呀 輸入有兩個數據量 然后在LabVIEW上呈現這樣的圖
2015-05-08 12:13:37
在分析常用的計算最大Lyapunov指數小數據量法的基礎上,研究了混沌吸引子時間軌道的不可逆特性,提出基于后向搜索和雙向搜索計算最大Lyapunov指數的推廣小數據量法通用經驗公
2009-03-01 23:30:57 30
30 數字廣播嵌入式終端在接收大數據量的廣播信息時受限于軟件處理速度,數據因不能得到及時處理而造成丟包,大量數據動態存儲時的頻繁申請易產生內存碎片,影響系統運行速度
2009-04-09 08:44:3636 sql 查詢慢的48個原因分析 1、沒有索引或者沒有用到索引(這是查詢慢最常見的問題,是程序設計的缺陷)。 2、I/O吞吐量小,形成了瓶頸效應。 3、沒有創建計算列導致查詢不優化。 4、內存不足。 5、網絡速度慢。 6、查詢出的數據量過大(可以采用多次查詢,其他
2011-03-08 11:58:540 根據IDC發布的數字宇宙研究報告(Digital Universe)顯示,在接下來的8年中,我們所產生的數據量將超過40 ZB(澤字節),這相當于地球上每個人產生5200GB的數據。
2012-12-21 14:56:227243 一、實時數據查詢: 我們看看小P在實時數據計算方面又有哪些卓越表現呢? 由于 Presto 卓越的性能表現,使得 Presto 可以彌補 Hive 無法滿足的實時計算空白,因此可以將 Presto
2017-09-30 17:42:100 越來越高。例如,在W eb2.0的社交網站巾有龐大的用戶群,每時每刻都有大量的數據量訪問,因而會產牛大量的日志和資料等,其數據量已經達到PB級別。對于這些海量的數據,小但包括結構化數據,更多的是包括非結構化數據,傳統關系
2017-11-11 15:49:509 本文主要講mybatis的一級緩存,一級緩存是SqlSession級別的緩存。mybatis提供查詢緩存,用于減輕數據壓力,提高數據庫性能。mybaits提供一級緩存,和二級緩存。一級緩存
2017-11-27 20:44:231432 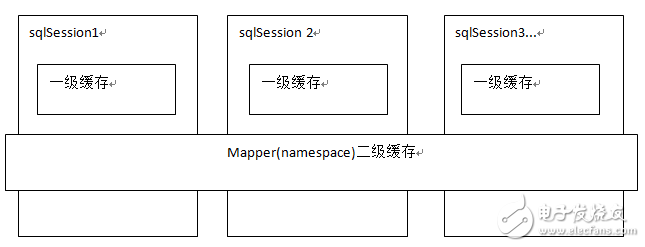
針對大數據環境下完整性查詢時間代價消耗過高的問題,提出了一種采用近似完整性查詢方法的系統-Probery。Probery所采用的近似完整性查詢方法不同于傳統的近似查詢,其近似性主要體現為數據查全
2017-12-25 16:55:020 本文主要詳細介紹了MyBatis的實現原理。mybatis底層還是采用原生jdbc來對數據庫進行操作的,只是通過 SqlSessionFactory,SqlSession Executor
2018-02-24 11:25:356990 
我們說 Mysql 單表適合存儲的最大數據量,自然不是說能夠存儲的最大數據量,如果是說能夠存儲的最大量,那么,如果你使用自增 ID,最大就可以存儲 2^32 或 2^64 條記錄了,這是按自增 ID
2020-04-16 08:08:002078 
根據IDC預測,全球在2010年正式進入ZB時代,全球數據量大約每兩年翻一番,意味著人類在最近兩年產生的數據量相當于之前產生的全部數據量。爆炸式增長的數據,正推動人類進入大數據的時代。
2018-09-29 11:07:321237 在此背景下,連接設備的數量、產生的收入和數據量也將呈現驚人的增長:到2020年,全球連接設備數量將達到500億臺;到2025年,物聯網銷售收入將達到1.6萬億美元;到2020年,物聯網產生的數據量將達到4.4ZB。
2019-01-15 15:47:569787 
在現代社會,每個人的一言一行都產生數據并被記錄下來,IDC數據顯示,自從2010年進入ZB階段以來,全球數據量約每兩年翻一番,近幾年產生的數據量幾乎與之前所有時代的數據量齊平。爆發的數據將人類推入大數據時代。
2019-03-01 14:24:152015 隨著高清監控普及,安防監控領域數據量爆炸式增長,催生了對智能化技術的需求。
2019-07-10 14:03:484121 相信那些鮮少接觸過大數據的人,很難清楚知曉究竟多大的數據量才能被稱為大數據。
2019-09-11 10:32:191294 從數據稀缺到現在有大量的數據,近年來,可用的數據量呈指數級增長,大數據變得無處不在。
2019-09-28 02:44:002318 物聯網(IoT)和大數據技術在組織和個人之間快速增長。據《福布斯》預測,到2025年,生成的數據量將增加到175zettabytes。這將對收集、分析和報告數據的方式產生巨大影響。
2020-06-18 11:35:5211130 物聯網(IoT)和大數據技術在組織和個人之間快速增長。據《福布斯》預測,到2025年,生成的數據量將增加到175 zettabytes。這將對收集、分析和報告數據的方式產生巨大影響。
2020-06-24 08:00:000 經常有同學問我,我的一個SQL語句使用了索引,為什么還是會進入到慢查詢之中呢?今天我們就從這個問題開始來聊一聊索引和慢查詢。
2020-08-10 16:09:151375 
大數據擁有著很多數據量,如果用傳統的數據管理方式不利于開展管理和處理的工作,因此要利用信息技術對數據進行存儲與處理,使海量資料得到有效的管理,大數據在處理和管理數據方面充分的發揮著自身的作用。
2020-08-11 11:09:536159 可以打上meta,查詢的時候按照meta進行查詢,加快查詢速度; 2. 采取每次追加部分數據的方式,跟“同步數據”每次全量數據入集市的方式相比,每天入集市任務的時間更短;數據庫處理的數據量更小,減少數據庫壓力。 ? 同時,“增量導入數據
2021-09-04 16:50:18792 
MyBatis-plus 是一款 Mybatis 增強工具,用于簡化開發,提高效率。下文使用縮寫 mp來簡化表示 MyBatis-plus,本文主要介紹 mp 搭配 Spring Boot
2021-06-01 09:30:233131 
1. MySQL查詢慢是什么體驗? 大多數互聯網應用場景都是讀多寫少,業務邏輯更多分布在寫上。對讀的要求大概就是要快。那么都有什么原因會導致我們完成一次出色的慢查詢呢? 1.1 索引 在數據量不是
2021-07-06 14:38:352278 結果。流式查詢的好處是能夠降低內存使用。 如果沒有流式查詢,我們想要從數據庫取 1000 萬條記錄而又沒有足夠的內存時,就不得不分頁查詢,而分頁查詢效率取決于表設計,如果設計的不好,就無法執行高效的分頁查詢。因此流式查詢是一個數據庫訪問框架必須具備的功能。 流式查詢的過程當
2021-08-04 15:52:235032 在BI系統中,經常會遇到性能的問題,比如打開報表慢,可能是數據量太大,或是報表前端太大加載慢;或是網絡問題;或是SQL運行慢。
2021-12-09 15:00:40879 
./oschina_soft/gitee-mybatis-plus.zip
2022-06-13 11:34:151 本文主要介紹mybatis-plus這款插件,針對springboot用戶。包括引入,配置,使用,以及擴展等常用的方面做一個匯總整理,盡量包含大家常用的場景內容。
2022-08-22 11:56:032027 使用fluent mybatis可以不用寫具體的xml文件,通過java api可以構造出比較復雜的業務sql語句,做到代碼邏輯和sql邏輯的合一。不再需要在Dao中組裝查詢或更新操作,在xml或
2022-09-15 15:41:011968 本文通過MyBatis一個低版本的bug(3.4.5之前的版本)入手,分析MyBatis的一次完整的查詢流程,從配置文件的解析到一個查詢的完整執行過程詳細解讀MyBatis的一次查詢流程,通過本文
2022-10-10 11:42:151430 ; 表示從第1000001條數據開始查,讀取1000條數據。隨著offset的增加,查詢的時長也會越來越長。當offset達到百萬級別的時候查詢時長有可能秒級,這是業務所不能容忍的。
2022-11-24 14:45:56959 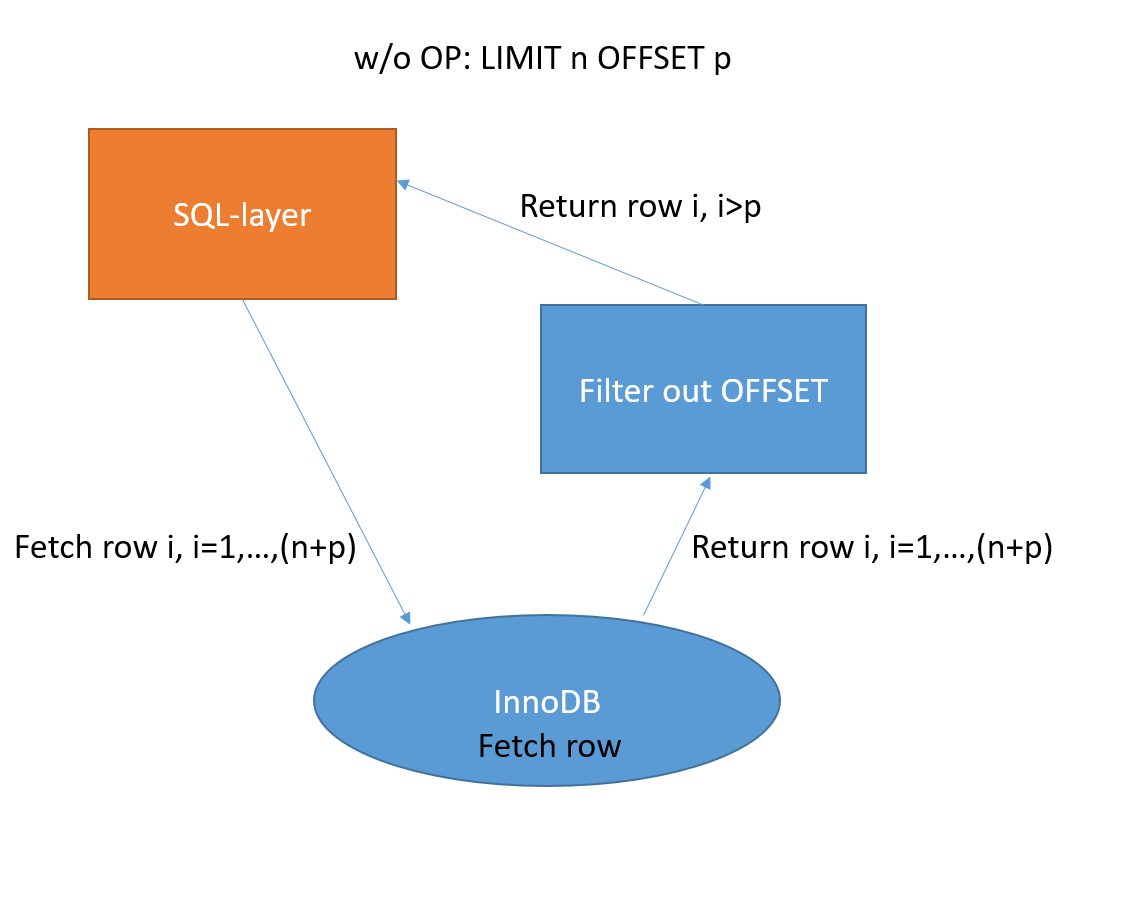
華為云數據查詢加速解決方案,助力企業****數據"流通" 數字經濟時代,全球數據量激增,各行各業對數據庫的需求持續增長。然而,伴隨業務的增長,數據量的增大,單一的數據庫可能無法滿足數據存儲計算需求
2023-01-13 16:45:211461 在實際工作中當指定查詢數據過大時,我們一般使用分頁查詢的方式一頁一頁的將數據放到內存處理。但有些情況不需要分頁的方式查詢數據或分很大一頁查詢數據時,如果一下子將數據全部加載出來到內存中,很可能會發生OOM(內存溢出);
2023-01-16 10:17:082472 MyBatis Plus Join`一款專門解決MyBatis Plus 關聯查詢問題的擴展框架,他并不一款全新的框架,而是基于`MyBatis Plus`功能的增強,所以`MyBatis Plus
2023-02-28 15:19:213790 
大數據指的是規模、類型和速度都非常龐大的數據集合,這些數據通常是由傳感器、社交媒體、金融交易、科學實驗等大規模應用程序收集和生成的。大數據的特點是數據量極大、數據處理速度快、數據來源多樣、數據
2023-04-14 17:14:106552 大數據的4V特征是指數據的特點,主要包括以下四個方面:
1. Volume(數據量):所謂大數據,就是指數據量達到了一定的規模大小,通常需要使用分布式系統和算法進行處理和分析。數據
2023-04-16 16:08:3819403 Volume 大數據數據量大,數據量單位為T 或者P級
* Variety 數據類型多,大數據包含多種數據維度 比如 日志、視頻、圖片
* Value 價值密度低,商業價值高 比如監控視頻,其中關鍵1-2秒可能具有極高的價值
* Velocity 要求處理速度塊
2023-05-10 15:30:043591 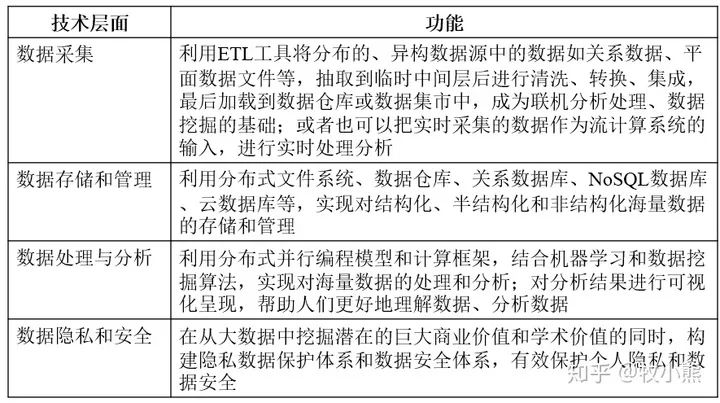
MyBatis、JDBC等做大數據量數據插入的案例和結果。 30萬條數據插入插入數據庫驗證 實體類、mapper和配置文件定義 User實體 mapper接口 mapper.xml文件
2023-05-22 11:23:131643 
在基于Mybatis的開發模式中,很多開發者還會選擇Mybatis-Plus來輔助功能開發,以此提高開發的效率。
2023-05-23 14:16:431963 
最近在壓測一批接口,發現接口處理速度慢的有點超出預期,感覺很奇怪,后面定位發現是數據庫批量保存這塊很慢。
這個項目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。
我點進去看了下源碼,感覺有點不太對勁:
2023-05-30 09:56:371324 
使用mybatis作為持久層的框架時,通過mybatis執行查詢數據的請求執行成功后,mybatis返回的結果集不是一個集合或對象,而是一個迭代器,可以通過遍歷迭代器來取出結果集
2023-06-12 09:57:201850 網關每秒采集的數據量是多少?以物通博聯工業網關為例,單體設備每秒可采集上萬數據點。不同的設備,不同的數據類型,其實都是不一樣的,有的設備數據采集周期很長,一秒鐘內可
2022-10-24 17:18:201382 
摘要:智能把控大數據量查詢,防患系統奔潰于未然 什么是最大讀取行 一直以來,大數據量查詢是數據庫 DBA 們調優的重點,DBA 們通常十八般武藝輪番上陣以期提升大數據查詢的性能:例如分庫分表、給表
2023-06-30 09:51:09594 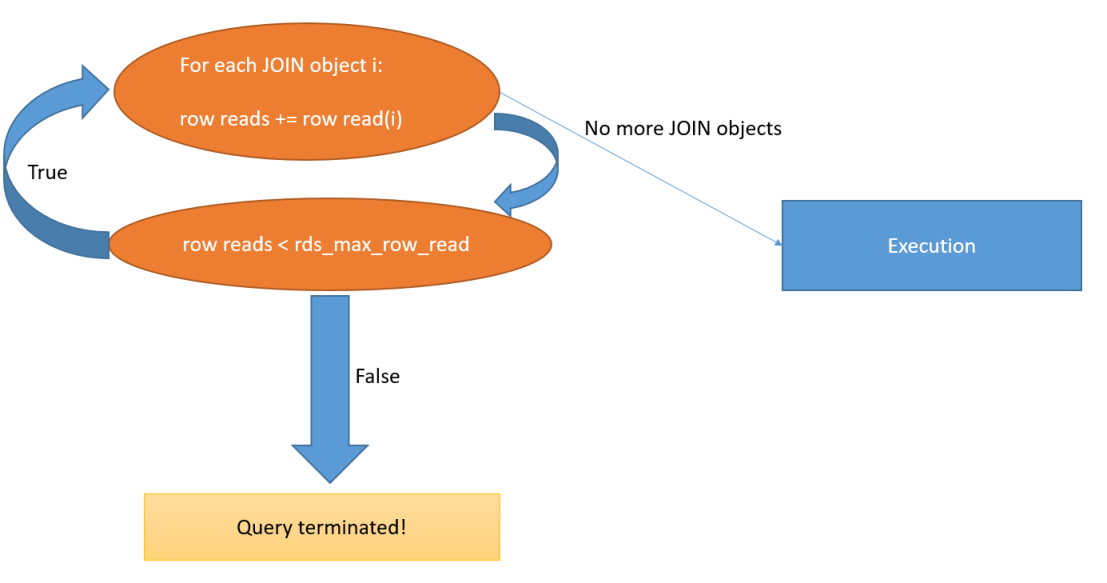
眾所周知,mybatis plus 封裝的 mapper 不支持 join,如果需要支持就必須自己去實現。但是對于大部分的業務場景來說,都需要多表 join,要不然就沒必要采用關系型數據庫了。
2023-07-07 10:19:565255 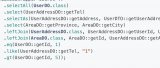
可以秒分析大數據的商業智能系統。 奧威BI系統采用微服務框架,解決因巨大的數據量而拖慢系統,導致系統卡頓、崩潰的問題,同時奧威BI系統也擁有極優秀的大數據計算、分析、可視化展現能力,能夠實現億級數據秒響應、秒分析、
2023-08-03 16:56:38738 大數據是人工智能嗎 隨著互聯網技術和數據采集技術的發展,數據量不斷增大,大數據應運而生。大數據技術的出現,使得數據分析的速度和效率大幅提高,同時也為人工智能的發展提供了基礎支撐。那么,大數據
2023-08-12 17:12:452737 本篇文章,我們通過 MyBatis Plus 來對一張表進行 CRUD 操作,來看看是如何簡化我們開發的。 1、創建測試表 創建 USER 表: DROP TABLE IF EXISTS
2023-10-09 15:08:24911 
在大數據平臺下,預處理的數據量非常大,而處理后的有效數據量往往比較小,因此,數據的生命周期管理顯得非常重要。數據生命周期管理(data life-cycle management,DLM)是一種基于策略的方法。
2023-10-11 11:41:324126 
出于一些歷史原因有的SQL查詢可能非常復雜,需要同時關聯非常多的表,使用一些復雜的函數、子查詢,這樣的SQL在項目初期由于數據量比較少,不會對數據庫造成較大的壓力,但是隨著時間的積累以及業務的發展,這些SQL慢慢就會轉變為慢SQL,對數據庫的性能產生一定的影響。
2023-10-31 10:29:332742 
數據庫的原理、使用場景、實現方法以及可能遇到的問題和解決方案。 一、多線程并發查詢的原理 在傳統的單線程查詢方式中,當一個查詢請求發起時,數據庫會按照順序執行查詢語句并返回結果。如果查詢語句比較復雜或者數據量比較大,查詢的時
2023-11-17 14:22:055795 當Java應用程序處理大數據量時,需要采取一些技術和策略來優化性能和提高可擴展性。在本文中,我將詳細介紹一些常見的處理大數據量的方法和建議。 一、數據結構和算法優化 1.使用合適的數據結構:選擇正確
2023-11-23 14:43:134808 個輕量級的持久層框架,它提供了一個靈活的SQL映射機制,使得開發者可以編寫原生SQL語句來操作數據庫。MyBatis的設計目標是將原生SQL和對象關系映射(ORM)相結合,以便開發者可以靈活地操作數據庫。 而MyBatis Plus是在MyBatis的基礎上進行了一些擴展和增強,它旨在進一步簡化開
2023-12-03 11:53:393663 。MyBatis框架的主要作用包括以下幾個方面。 數據庫操作的簡化和標準化: MyBatis框架提供了一種簡單的方式來執行數據庫操作,包括插入、更新、刪除和查詢等操作。通過使用MyBatis的API,開發人員可以快速地編寫數據庫操作相關的代碼,而無需關注數據庫連接、事務處
2023-12-03 14:49:502894 這兩種分頁方式的區別。 邏輯分頁是在數據庫中執行查詢時使用的一種分頁方式。這種方式是通過在查詢語句中添加LIMIT或OFFSET關鍵字來限制結果集的大小和偏移量來實現的。常見的邏輯分頁方式有MySQL中的LIMIT關鍵字,以及Oracle中的ROWNUM進行分頁。 邏輯分頁的主要優
2023-12-03 14:54:561626 的核心技術,包括數據采集、存儲與管理、處理與分析等方面。 一、大數據技術背景和概念 1.1 背景 隨著互聯網技術的迅猛發展,人們可以通過各種途徑產生、獲取和傳輸數據,使數據量呈現爆炸式增長的趨勢。這些數據來源包括
2024-01-31 11:07:268645 通過多個跳數進行通信,從而實現大范圍的覆蓋。然而,隨著數據量的增加和帶寬需求的提高,如何在藍牙Mesh網絡中實現高效、穩定的多跳大數據量高帶寬傳輸數據成為了一個亟待解決的問題。本文將介紹一種基于藍牙Mesh模塊的多跳大數據量高帶寬
2024-05-28 11:23:221656 
大數據從業者必知必會的Hive SQL調優技巧 摘要 :在大數據領域中,Hive SQL被廣泛應用于數據倉庫的數據查詢和分析。然而,由于數據量龐大和復雜的查詢需求,Hive SQL查詢的性能往往
2024-09-24 13:30:241063 作者:京東零售 張均杰 背景 部門內有一些億級別核心業務表增速非常快,增量日均100W,但線上業務只依賴近一周的數據。隨著數據量的迅速增長,慢SQL頻發,數據庫性能下降,系統穩定性受到嚴重影響。本篇
2025-01-23 17:38:38707 作為一名在生產環境摸爬滾打多年的運維工程師,我見過太多因為慢查詢導致的線上故障。今天分享一套經過實戰檢驗的MySQL慢查詢分析與索引優化方法論,幫你徹底解決數據庫性能瓶頸。
2025-08-13 15:55:16718 今天,我將分享我在處理數千次數據庫性能問題中積累的實戰經驗,幫助你系統掌握慢查詢分析與SQL優化的核心技巧。無論你是剛入門的運維新手,還是有一定經驗的工程師,這篇文章都將為你提供實用的解決方案。
2025-09-08 09:34:38761
 電子發燒友App
電子發燒友App








 工商網監
工商網監
評論