 數據的基本概念!大數據時代的新術語
數據的基本概念!大數據時代的新術語

“大數據時代”的概念最早由世界著名的咨詢公司麥肯錫提出。麥肯錫說:“數據已滲透到今天的每個行業和業務功能領域,并已成為重要的生產要素”。
本文引自:《數據技術基礎》(作者:張潔、呂佑龍、張朋、汪俊亮)。
隨著互聯網技術的發展,現有計算機擁有了在極短時間內處理海量數據的能力,進而催生了一大批企業利用大量的數據,將傳統的企業運營方式進行顛覆,使得企業實現了從靠人力決策到靠數據決策的轉變,這意味著更少的決策失誤和更大的利潤,而對于普通民眾而言則能享受到更好的服務質量和辦事效率。 在以上過程中,大量的企業決策與服務提供需要依靠大數據技術支撐,并且大數據帶來的經濟效益已經大于開發成本,由此進入大數據時代。
內涵與特征 1)大數據的內涵
大數據的定義方法有很多種,如果仔細觀察,會發現不同領域專家學者給出了不同的定義。通常所說的“大數據”往往指的是“大數據現象”。
(1)計算機科學與技術:當數據量、數據的復雜程度、數據處理的任務要求等超出了傳統數據存儲與計算能力時,稱之為大數據(現象)。可見,計算機科學與技術中是從存儲和計算能力視角理解大數據——大數據不僅是“數據存量”的問題,還與數據增量、復雜度和處理要求(如實時分析)有關。
(2)統計學:當能夠收集足夠的全部(總體中的絕大部分)個體的數據,且計算能力足夠強,可以不用抽樣,直接在總體上就可以進行統計分析時,稱之為大數據(現象)。可見,統計學主要從所處理的問題和總體的規模之間的相對關系視角理解“大數據”。
(3)機器學習:當訓練集足夠大,且計算能力足夠強,只需要通過對已有的實例進行簡單查詢即可達到“智能計算的效果”時,稱之為大數據(現象)。可見,機器學習主要從“智能的實現方式”理解大數據-智能可以通過簡單的實例學習和機械學習的方式來實現。
(4)社會科學家:當多數人的大部分社會行為可以被記錄下來時,稱之為大數據(現象)。可見,社會科學家眼里的大數據主要是從“數據規模與價值密度角度”談的,即數據規模過大導致的價值密度過低。
總之,術語大數據的內涵已超出了數據本身,代表的是數據帶來的機遇與挑戰,可以總結如下。
(1)機遇:原先無法(或不可能)找到的數據,現在可能找到;原先無法實現的計算目的(如數據的實時分析),現在可以實現。
(2)挑戰:原先一直認為正確或最佳的理念、理論、方法、技術和工具越來越凸現出其局限性,在大數據時代需要改變思考模式。
2)大數據的特征
通常,用4V來表示大數據的基本特征。但是,建議讀者結合上述對大數據的內涵的討論,靈活理解大數據的特征。
(1)Volume(數據量大):數據量大是一個相對于計算和存儲能力的說法,就目前而言,當數據量達到PB級以上,一般稱為“大”的數據。但是,應該注意到,大數據的時間分布往往不均勻,近幾年所生成的數據,相對占比最高。
(2)Variety(類型多):數據類型多是指大數據存在多種類型的數據,不僅包括結構化數據,還包括非結構化數據和半結構化數據。有統計顯示,在未來,非結構化數據的占比將達到90%以上。非結構化數據所包括的數據類型很多,例如網絡日志、音頻、視頻、圖片、地理位置信息等。數據類型的多樣性往往導致數據的異構性,進而加大了數據處理的復雜性,對數據處理能力提出了更高要求。
(3)Value(價值密度低):在大數據中,價值密度的高低與數據總量的大小之間并不存在線性關系,有價值的數據往往被淹沒在海量無用數據之中,也就是人們常說的“我們淹沒在數據的海洋,卻又在忍受著知識的饑渴(We are drowning in a sea of data and thirsting for knowledge)”。例如,一段長達120min連續不間斷的監控視頻中,有用數據可能僅有幾秒。因此,如何在海量數據中洞見有價值的數據成為數據科學的重要課題。
(4)Velocity(速度快):大數據中所說的“速度”包括兩種——增長速度和處理速度。一方面,大數據增長速度快。有統計顯示,2009—2020年期間的數字宇宙的年均增長率將達到41%,另一方面,對大數據處理的時間(計算速度)要求也越來越高,“大數據的實時分析”成為熱門話題。
業務數據化
隨著互聯網的快速發展,企業逐漸面臨越來越多大數據時代的不確定性和挑戰,很可能因為成本高居不下而逐漸失去份額,被競爭對手超越并最終出局。企業每天都會產生大量的業務數據,通過實現業務數據化可以幫助企業經營者對尚未掌握的商業機遇進行理性評估判斷,實現業務增值,同時幫助企業提升內部運營效率,降低成本。因此業務數據化是未來發展的一大趨勢。
1)設計目標和原則
業務數據化的設計目標是要從大量的、可能是雜亂無章的、難以理解的數據中抽取并推導出對于某些特定的人或事物來說有價值、有異議的數據。設計原則包括簡約原則、綜觀原則、解釋原則以及智慧原則。
(1)簡約原則:簡化現有的數據集,使得一種小規模的數據就能夠產生同樣的分析效果。通過一些數據規約方法獲取可靠數據,減少數據集規模,提高數據抽象程度,提升數據挖掘效率,使之在實際工作中,可以根據需要選用合適的處理方法,以達到操作上的簡單、簡潔、簡約和高效。
(2)綜觀原則:對認知對象進行綜合性的觀察、分析和探索,以求得解決問題的策略和戰略。它堅持整體的具體統一性,凸顯認知對象的具體實在性。
(3)解釋性原則:針對提取的數據究竟表達什么或意味什么,很大程度上,并不取決于數據信息自身所標明的“客觀實在性”,而是取決于認知主體對數據進行解讀時的主觀評價,以此揭示數據的本質。
(4)智慧原則:在對數據的處理挖掘過程中既要兼具數據處理能力,也要具備應用算法和編寫代碼的經驗。在大數據時代,不僅要關注數據的多樣性、差異性、精確性和實效性;還要深入挖掘各類數據,并在此基礎上在不同的數據集成中分析不同的假設情境,建構不同的可視化圖像,揭示數據集成的變化及其產生的效用。
2)數據線程
數據線程是指以價值鏈活動為脈絡,以業務為中心,構建的數據建模、關聯、因果、集成、演化等全主線流程。數據線程通過建立面向業務應用的數據模型,實現各種信息化業務系統數據源的統一建模需求;針對設計、制造、運行、維護等生產環節,發掘數據資源間的復雜關聯關系和因果關系;通過描述業務驅動的數據動態演化過程,提升對產品迭代、工藝更新、設備維護等業務決策問題的適應能力。數據線程圍繞數據生成、匯聚、存儲、歸檔、分析、使用和銷毀等全過程,實現了產品研發設計、生產制造、經營管理和銷售服務等全價值鏈活動中業務數據的有效組織,為業務數據化提供了良好的基礎。
3)業務數據系統
業務數據系統主要包括業務數據集成系統、業務數據管理系統、業務數據分析系統、業務數據可視化系統等多個子系統。
(1)業務數據集成系統:是面向業務的數據集成系統。隨著企業信息化建設的發展,企業建立了眾多的信息系統,以幫助企業進行內外部業務的管理。但是,企業各系統的數據是分布的、異構的,為了共享這些業務數據,需要一個業務數據集成系統來完成數據的共享與轉換。業務數據集成系統通過對具體的數據庫業務數據進行訪問,實現了基于變量的增量數據的獲取和發送,不僅解決了分布式環境下異構數據的集成,還具有良好的擴展性及部署的簡單性。
(2)業務數據管理系統:是業務數據系統的核心組成部分,主要完成對業務數據的操縱與管理功能,實現數據對象的創建、數據存儲數據的查詢、添加、修改與刪除操作和數據庫的用戶管理、權限管理等。業務數據管理系統可以依據它所支持的數據庫模型來做分類,例如關系式、XML;或依據所支持的計算機類型來做分類,例如服務器群集、移動電話;或依據所用查詢語言來做分類,例如SQL、XQuery;或依據性能沖量重點來做分類,例如最大規模、最高運行速度。
(3)業務數據分析系統:主要功能是從眾多外部系統中,采集相關的業務數據,集中存儲到系統的數據庫中。系統內部對所有的原始數據通過一系列處理轉換之后,存儲到數據倉庫的基礎庫中;然后,通過業務需要進行一系列的數據轉換到相應的數據集市,供其他上層數據應用組件進行專題分析或者展示,并將數據加以匯總和理解并消化,以求最大化地開發數據的功能,發揮數據的作用。
(3)業務數據可視化系統:將數據進行更清晰的展示,能夠準確而高效、精簡而全面地傳遞信息和知識。可視化能將不可見的數據現象轉化為可見的圖形符號,能將錯綜復雜、看起來沒法解釋和關聯的數據,建立起聯系和關聯,發現規律和特征,獲得更有商業價值的洞見和價值。
4)智能制造業務數據
智能制造業務數據主要包括以下6個方面。
(1)從底層的設備控制系統中采集的數據,包括設備的狀態數據、設備參數等,如數控系統、產線控制系統等。
(2)直接采集各類終端及傳感器的數據,如溫度傳感器、振動傳感器、噪聲傳感器、手持終端等。
(3)從各類業務應用信息系統中獲取數據,如MES系統從PDM系統獲取BOM數據,從ERP系統獲取訂單數據等。
(4)從各類業務運行過程中獲取的樣本數據集,是指以業務為中心,積累的歷史樣本數據,可用于智能制造過程中模型的訓練。
(5)指算法和模型數據,是指機器學習、深度學習、強化學習等算法和已訓練好的模型,用戶可以直接從業務數據系統中調用這些算法和模型數據,用于制造大數據分析、預測、決策等。
(6)從互聯網獲取數據,如獲取市場信息數據、環境數據,上下游供應商數據等。還包括來源于人類軌跡產生的數據,包括在現代工業制造鏈中,從采購,生產,物流與銷售市場的內部流程等。通過行為軌跡數據與設備數據的結合,可以幫助我們實現客戶的分析和挖掘。
大數據時代的新理念
大數據時代的到來改變了人們的生活方式、思維模式和研究范式,也帶來了很多全新的理念。
(1)研究范式的新認識——從第三范式到第四范式:2007年,圖靈獎獲得者Jim Gray提出了科學研究的第四范式——數據密集型科學發現(Data-intensive Scientific Discovery)。在他看來,人類科學研究活動已經歷過3種不同范式的演變過程(原始社會的實驗科學范式、以模型和歸納為特征的理論科學范式和以模擬仿真為特征的計算科學范式),目前正在從計算科學范式轉向數據密集型科學發現范式。第四范式,即數據密集型科學發現范式的主要特點是科學研究人員只需要從大數據中查找和挖掘所需要的信息和知識,無須直接面對所研究的物理對象。
(2)數據重要性的新認識——從數據資源到數據資產:在大數據時代,數據不僅是一種資源,而更是一種重要的資產。因此,數據科學應把數據當作一種資產來管理,而不能僅僅當作資源來對待。也就是說,與其他類型的資產相似,數據也具有財務價值,且需要作為獨立實體進行組織與管理。
(3)對方法論的新認識——從基于知識解決問題到基于數據解決問題:傳統方法論往往是基于知識的,即從大量實踐(數據)中總結和提煉出一般性知識(定理、模式、模型、函數等)之后,用知識去解決(或解釋)問題。因此,傳統的問題解決思路是問題→知識→問題,即根據問題找知識,并用知識解決問題。然而,數據科學中興起了另一種方法論——問題→數據→問題,即根據問題找數據,并直接用數據(不需要把數據轉換成知識的前提下)解決問題。
(4)對數據分析的新認識——從統計學到數據科學:在傳統科學中,數據分析主要以數學和統計學為直接理論工具。但是,云計算等計算模式的出現以及大數據時代的到來,提升了人們對數據的獲取、存儲、計算與管理能力。在海量、動態、異構的數據環境中,人們開始重視相關分析,而不僅僅是因果分析。人們更加關注的是數據計算的“效率”而不再盲目追求其精準度。
(5)對計算智能的新認識——從復雜算法到簡單算法:“只要擁有足夠多的數據,我們可以變得更聰明”是大數據時代的一個新認識。因此,在大數據時代,原本復雜的智能問題變成簡單的數據問題——只要對大數據的進行簡單查詢就可以達到“基于復雜算法的智能計算的效果”。
(6)對數據管理重點的新認識——從業務數據化到數據業務化:在大數據時代,企業需要重視一個新的課題——數據業務化,即如何基于數據動態地定義、優化和重組業務及其流程,進而提升業務的敏捷性,降低風險和成本。
(7)對決策方式的新認識——從目標驅動型決策到數據驅動型決策:傳統科學思維中,決策制定往往是目標或模型驅動的——根據目標(或模型)進行決策。在大數據時代出現了另一種思維模式,即數據驅動型決策,數據成為決策制定的主要觸發條件和重要依據。
(8)對產業競合關系的新認識——從以戰略為中心競合關系到以數據為中心競合關系:在大數據時代,企業之間的競合關系發生了變化,原本相互激烈競爭,甚至不愿合作的企業,不得不開始合作,形成新的業態和產業鏈。
(9)對數據復雜性的新認識——從不接受到接受數據的復雜性:在傳統科學看來,數據需要徹底凈化和集成,計算目的是需要找出精確答案,其背后的哲學是“不接受數據的復雜性”。然而,大數據中更加強調的是數據的動態性、異構性和跨域等復雜性——彈性計算、魯棒性、虛擬化和快速響應,開始把復雜性當作數據的一個固有特征來對待,組織數據生態系統的管理目標轉向將組織處于混沌邊緣狀態。
(10)對數據處理模式的新認識——從小眾參與到大眾協同:傳統科學中,數據的分析和挖掘都是基于專家經驗,但在大數據時代,基于專家經驗的創新工作成本和風險越來越大,而基于專家-業余相結合(Pro-Am)的大規模協作日益受到重視,正成為解決數據規模與形式化之間矛盾的重要手段。
大數據時代的新術語
大數據時代的到來,為業務活動提出了一些新的任務和挑戰,同時出現了很多全新術語。
(1)數據化(datafication):捕獲人們的生活與業務活動,并將其轉換為數據的過程。
(2)數據柔術(data jiu-jitsu):數據科學家將大數據轉換具有立即產生商業價值的數據產品(data product)的能力,如圖1所示。數據產品是指在零次數據或一次數據的基礎上,通過數據加工活動形成的二次或三次數據,數據產品的特點包括:高層次性,其一般為二次數據或三次數據;成品性,數據產品往往不需要(或不需要大量的)進一步處理即可直接應用;商品性,數據產品可以直接用于銷售或交易;易于定價,相對于原始數據,數據產品的定價更為容易。
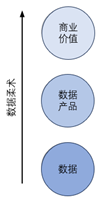 ? ? 圖1數據柔術
? ? 圖1數據柔術
(3)數據改寫(data munging):帶有一定的創造力和想象力的數據再加工行為,主要涉及數據的解析(parsing)、提煉(scraping)、格式化(formatting)和形式化(formalization)處理。與一般數據處理不同的是,數據再加工強調的是數據加工過程中的創造力和想象力。
(4)數據打磨(data wrangling):采用全手工或半自動化的方式,通過多次反復調整與優化過程,即將原始數據轉換為一次數據(或二次數據)的過程。其特殊性表現在不是完全自動化方式實現,一般用手工或半自動化工具;不是一次即可完成,需要多次反復調整與優化。
(5)數據分析式思維模式(data-analytic thinking):一種從數據視角分析問題,并基于數據來解決問題的思維模式。數據分析思維模式與傳統思維模式不同。前者,主要從數據入手,最終改變業務;后者從業務或決策等要素入手,最終改變數據。從分析對象和目的看,數據分析可以分為3個不同層次,如圖2所示。

圖2數據分析的層次
(6)描述性分析( descriptive analysis):采用數據統計中的描述統計量、數據可視化等方法描述數據的基本特征,如總和、均值、標準差等。描述性分析可以實現從數據到信息的轉化。
(7)預測性分析(predictive analysis):通過因果分析、相關分析等方法,基于過去/當前的數據得出潛在模式、共性規律或未來趨勢。預測性分析可以實現從信息到知識的轉化。
(8)規范性分析(normative analysis):不僅要利用當前和過去的數據,而且還會綜合考慮期望結果、所處環境、資源條件等更多影響因素,在對比分析所有可能方案的基礎上,提出可以直接用于決策的建議或方案。規范性分析可實現從知識到智慧的轉變。
(9)數據洞見(data insights):采用機器學習、數據統計和數據可視化等方法從海量數據中找到人們并未發現的且有價值的信息的能力。數據科學強調的是數據洞見——發現數據背后的信息、知識和智慧以及找到“被淹沒在海量數據中的未知數據”。與數據挖掘不同的是,數據科學項目的成果可以直接用于決策支持。數據洞見力的高低主要取決于主體的數據意識、經驗積累和分析處理能力。
(10)數據驅動(data-driven):是相對于決策驅動、目標驅動、業務驅動和模型驅動的一種提法。數據驅動主要以數據為觸發器(出發點)、視角和依據,進行觀測、控制、調整和整合其他要素——決策、目標、業務和模型等,如圖3所示。數據驅動是大數據時代的一種重要思維模式,也是業務數據化之后實現數據業務化的關鍵所在。
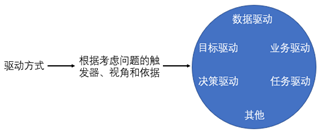
圖3常用的驅動方式
(11)數據密集型(data-intensive)應用:是相對于計算密集型應用、I/O密集型應用的一種提法,如圖4所示。也就是說,數據密集型應用中數據成為應用系統研發的主要焦點和挑戰。通常,數據密集型應用的計算比較容易,但數據具有顯著的復雜性(異構、動態、跨域和海量等)和海量性。例如,當對PB級復雜性數據進行簡單查詢時,計算不再是最主要的挑戰,而最主要挑戰來自于數據本身的復雜性。
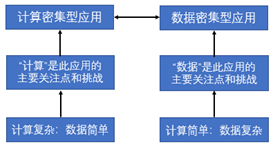
圖4計算密集型應用與數據密集型應用的區別
(12)數據空間(data space):主體的數據空間——與主體相關的數據及其關系的集合。主體相關性和可控性是數據空間中數據項的基本屬性。
(13)關聯數據(linked data):一種數據發布和關聯的方法。其中,數據發布是指采用資源描述框架(resource definition framework,RDF)和超文本傳輸協議(hypertext transfer protocol,HTTP)技術在Web上發布結構化信息;數據關聯是指采用RDF鏈接技術在不同數據源中的數據之間建立計算機可理解的互連關系。2006年, Tim Berners Lee首次提出了關聯數據的理念,目的在于不同資源之間建立計算機可理解的關聯信息,最終形成全球性大數據空間。Tim Berners Lee進一步明確提出了關聯數據技術中的數據發布和數據關聯的4項原則:采用統一資源標識符(uniform resource identifier, URI)技術統一標識事物;通過HTTP URI訪問URI標識;當URI被訪問時,采用RDF和SPARQL(Simple Protocol and RDF Query Language)標準,提供有用信息;提供信息時,也提供指向其他事物的URI,以便發現更多事物。
除了上述概念之外,還有數據消減(data reduction)、數據新聞(data journalism)、數據的開放獲取(open access)、數據質量、特征提取等傳統概念也重新備受關注。

大數據生命周期管理
在大數據平臺下,預處理的數據量非常大,而處理后的有效數據量往往比較小,因此,數據的生命周期管理顯得非常重要。數據生命周期管理(data life-cycle management,DLM)是一種基于策略的方法,用于管理信息系統的數據在整個生命周期內的流動:從創建和初始存儲,到它過時被刪除。(圖5)
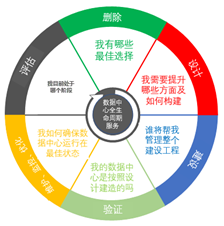
圖5大數據生命周期管理概述圖
DLM產品將涉及的過程自動化,通常根據指定的策略將數據組織成各個不同的層,并基于那些關鍵條件自動地將數據從一個層移動到另一個層。作為一項規則,較新的數據和那些很可能被更加頻繁訪問的數據,應該存儲在更快的,并且更昂貴的存儲媒介上,而那些不是很重要的數據則存儲在比較便宜的,稍微慢些的媒介上。數據生命周期管理的總體原則在數據的整個生命周期中,不同階段的數據其性能、可用性、保存等要求也不一樣。通常情況下,在其生命周期初期,數據的使用頻率較高,需要使用高速存儲,確保數據的高可用性。隨著時間的推移,數據重要性會逐漸降低,使用頻率會隨之下降,應將數據進行不同級別的存儲,為其提供適當的可用性、存儲空間,以降低管理成本和資源開銷。最終大部分數據將不再會被使用,可以將數據清理后歸檔保存,以備臨時需要時使用。
編輯:黃飛
-
數據
+關注
關注
8文章
7335瀏覽量
94769 -
大數據
+關注
關注
64文章
9063瀏覽量
143751
原文標題:數據的基本概念!
文章出處:【微信號:數字化企業,微信公眾號:數字化企業】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大數據解決方案如何實施
最受歡迎的大數據可視化工具
大數據平臺運營的基礎是什么
AI時代大數據背后的網絡力量-上海兆越100G核心工業交換機

湖北大數據集團到訪維智科技參觀交流
東軟集團領跑中國醫療大數據解決方案市場
組態大數據平臺是什么?有什么功能?

御控工業物聯網大數據解決方案:排水設備遠程監控與大數據統計系統
中科曙光讓氣象數據解碼邁入毫秒級時代
電壓波動與閃變的基本概念
群延遲的基本概念和仿真實例分析

更改最大數據包大小時無法識別USB設備如何解決?
大數據時代,如何提高高速PCB設計效率?




 工商網監
工商網監
評論