") 一文看懂AI大模型的并行訓(xùn)練方式(DP、PP、TP、EP)
一文看懂AI大模型的并行訓(xùn)練方式(DP、PP、TP、EP)

大家都知道,AI計(jì)算(尤其是模型訓(xùn)練和推理),主要以并行計(jì)算為主。
AI計(jì)算中涉及到的很多具體算法(例如矩陣相乘、卷積、循環(huán)層、梯度運(yùn)算等),都需要基于成千上萬(wàn)的GPU,以并行任務(wù)的方式去完成。這樣才能有效縮短計(jì)算時(shí)間。
搭建并行計(jì)算框架,一般會(huì)用到以下幾種常見(jiàn)的并行方式:
Data Parallelism,數(shù)據(jù)并行
Pipeline Parallelism,流水線并行
Tensor Parallelism,張量并行
Expert Parallelism, 專(zhuān)家并行
接下來(lái),我們逐一看看,這些并行計(jì)算方式的工作原理。
DP(數(shù)據(jù)并行)
首先看看DP,數(shù)據(jù)并行(Data Parallelism)。
AI訓(xùn)練使用的并行,總的來(lái)說(shuō),分為數(shù)據(jù)并行和模型并行兩類(lèi)。剛才說(shuō)的PP(流水線并行)、TP(張量并行)和EP(專(zhuān)家并行),都屬于模型并行,待會(huì)再介紹。

這里,我們需要先大概了解一下神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過(guò)程。簡(jiǎn)單來(lái)說(shuō),包括以下主要步驟:

1. 前向傳播:輸入一批訓(xùn)練數(shù)據(jù),計(jì)算得到預(yù)測(cè)結(jié)果。
2. 計(jì)算損失:通過(guò)損失函數(shù)比較預(yù)測(cè)結(jié)果與真實(shí)標(biāo)簽的差距。
3. 反向傳播:將損失值反向傳播,計(jì)算網(wǎng)絡(luò)中每個(gè)參數(shù)的梯度。
4. 梯度更新:優(yōu)化器使用這些梯度來(lái)更新所有的權(quán)重和偏置(更新參數(shù))。
以上過(guò)程循環(huán)往復(fù),直到模型的性能達(dá)到令人滿意的水平。訓(xùn)練就完成了。
我們回到數(shù)據(jù)并行。
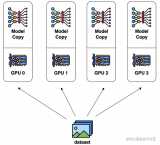
數(shù)據(jù)并行是大模型訓(xùn)練中最為常見(jiàn)的一種并行方式(當(dāng)然,也適用于推理過(guò)程)。
它的核心思想很簡(jiǎn)單,就是每個(gè)GPU都擁有完整的模型副本,然后,將訓(xùn)練數(shù)據(jù)劃分成多個(gè)小批次(mini-batch),每個(gè)批次分配給不同的GPU進(jìn)行處理。
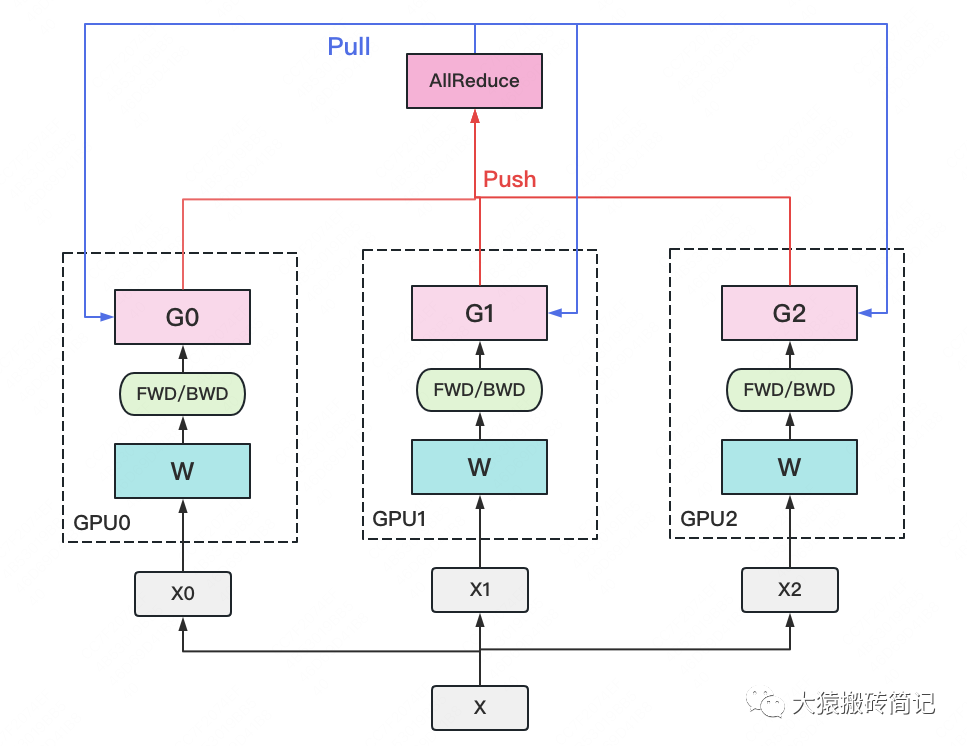
數(shù)據(jù)并行的情況下,大模型訓(xùn)練的過(guò)程是這樣的:

1、對(duì)數(shù)據(jù)進(jìn)行均勻切割,發(fā)給不同的、并行工作的GPU(Worker);
2、各GPU都擁有一樣的模型以及模型參數(shù),它們各自獨(dú)立進(jìn)行前向傳播、反向傳播,計(jì)算得到各自的梯度;
3、各GPU通過(guò)卡間通信,以All-Reduce的通信方式,將梯度推給一個(gè)類(lèi)似管理者的GPU(Server);
4、Server GPU對(duì)所有梯度進(jìn)行求和或者平均,得到全局梯度;
5、Server GPU將全局梯度回傳(broadcast廣播)到每個(gè)Worker GPU,進(jìn)行參數(shù)更新(更新本地模型權(quán)重)。更新后,所有worker GPU模型參數(shù)保持一致。
然后,再繼續(xù)重復(fù)這樣的過(guò)程,直至完成所有的訓(xùn)練。
再來(lái)一張圖,幫助理解:

從下往上看
這里提到的All-Reduce,也是一個(gè)AI領(lǐng)域的常見(jiàn)概念,字面意思是“全(All)-規(guī)約(Reduce)”,即:對(duì)所有節(jié)點(diǎn)的數(shù)據(jù)進(jìn)行聚合(如求和、求最大值),并將最終結(jié)果分發(fā)到所有節(jié)點(diǎn)。(參考:到底什么是All-Reduce、All-to-All?)
數(shù)據(jù)并行的優(yōu)點(diǎn),在于實(shí)現(xiàn)過(guò)程比較簡(jiǎn)單,能夠顯著加速大規(guī)模數(shù)據(jù)的訓(xùn)練過(guò)程,尤其適用于數(shù)據(jù)量遠(yuǎn)大于模型參數(shù)的場(chǎng)景。
數(shù)據(jù)并行的缺點(diǎn),在于顯存的限制。因?yàn)槊總€(gè)GPU上都有完整的模型副本,而當(dāng)模型的規(guī)模和參數(shù)越大,所需要的顯存就越大,很可能超過(guò)單個(gè)GPU的顯存大小。
數(shù)據(jù)并行的通信開(kāi)銷(xiāo)也比較大。不同GPU之間需要頻繁通信,以同步模型參數(shù)或梯度。而且,模型參數(shù)規(guī)模越大,GPU數(shù)量越多,這個(gè)通信開(kāi)銷(xiāo)就越大。例如,對(duì)于千億參數(shù)模型,單次梯度同步需傳輸約2TB數(shù)據(jù)(FP16精度下)。
ZeRO
這里要插播介紹一個(gè)概念——ZeRO(Zero Redundancy Optimizer,零冗余優(yōu)化器)。
在數(shù)據(jù)并行策略中,每個(gè)GPU的內(nèi)存都保存一個(gè)完整的模型副本,很占內(nèi)存空間。那么,能否每個(gè)GPU只存放模型副本的一部分呢?
沒(méi)錯(cuò),這就是ZeRo——通過(guò)對(duì)模型副本中的優(yōu)化器狀態(tài)、梯度和參數(shù)進(jìn)行切分,來(lái)實(shí)現(xiàn)減少對(duì)內(nèi)存的占用。
ZeRO有3個(gè)階段,分別是:
ZeRO-1:對(duì)優(yōu)化器狀態(tài)進(jìn)行劃分。
ZeRO-2:對(duì)優(yōu)化器狀態(tài)和梯度進(jìn)行劃分
ZeRO-3:對(duì)優(yōu)化器狀態(tài)、梯度和參數(shù)進(jìn)行劃分。(最節(jié)省顯存)
通過(guò)下面的圖和表,可以看得更明白些:


根據(jù)實(shí)測(cè)數(shù)據(jù)顯示,ZeRO-3在1024塊GPU上訓(xùn)練萬(wàn)億參數(shù)模型時(shí),顯存占用從7.5TB降至7.3GB/卡。
值得一提的是,DP還有一個(gè)DDP(分布式數(shù)據(jù)并行)。傳統(tǒng)DP一般用于單機(jī)多卡場(chǎng)景。而DDP能多機(jī)也能單機(jī)。這依賴(lài)于Ring-AllReduce,它由百度最先提出,可以有效解決數(shù)據(jù)并行中通信負(fù)載不均(Server存在瓶頸)的問(wèn)題。

PP(流水線并行)
再來(lái)看看模型并行。
剛才數(shù)據(jù)并行,是把數(shù)據(jù)分為好幾個(gè)部分。模型并行,很顯然,就是把模型分為好幾個(gè)部分。不同的GPU,運(yùn)行不同的部分。(注意:業(yè)界對(duì)模型并行的定義有點(diǎn)混亂。也有的資料會(huì)將張量并行等同于模型并行。)
流水線并行,是將模型的不同層(單層,或連續(xù)的多層)分配到不同的GPU上,按順序處理數(shù)據(jù),實(shí)現(xiàn)流水線式的并行計(jì)算。

例如,對(duì)于一個(gè)包含7層的神經(jīng)網(wǎng)絡(luò),將1~2層放在第一個(gè)GPU上,3~5層放在第二個(gè)GPU上,6~7層放在第三個(gè)GPU上。訓(xùn)練時(shí),數(shù)據(jù)按照順序,在不同的GPU上進(jìn)行處理。
乍一看,流水并行有點(diǎn)像串行。每個(gè)GPU需要等待前一個(gè)GPU的計(jì)算結(jié)果,可能會(huì)導(dǎo)致大量的GPU資源浪費(fèi)。

上面這個(gè)圖中,黃色部分就是Bubble (氣泡)時(shí)間。氣泡越多,代表GPU處于等待狀態(tài)(空閑狀態(tài))越長(zhǎng),資源浪費(fèi)越嚴(yán)重。
為了解決上述問(wèn)題,可以將mini-batch的數(shù)據(jù)進(jìn)一步切分成micro-batch數(shù)據(jù)。當(dāng)GPU 0處理完一個(gè)micro-batch數(shù)據(jù)后,緊接著開(kāi)始處理下一個(gè)micro-batch數(shù)據(jù),以此來(lái)減少GPU的空閑時(shí)間。如下圖(b)所示:

還有,在一個(gè)micro-batch完成前向計(jì)算后,提前調(diào)度,完成相應(yīng)的反向計(jì)算,這樣就能釋放部分顯存,用以接納新的數(shù)據(jù),提升整體訓(xùn)練性能。如上圖(c)所示。
這些方法,都能夠顯著減少流水線并行的Bubble時(shí)間。
對(duì)于流水線并行,需要對(duì)任務(wù)調(diào)度和數(shù)據(jù)傳輸進(jìn)行精確管理,否則可能導(dǎo)致流水線阻塞,以及產(chǎn)生更多的Bubble時(shí)間。
TP(張量并行)
模型并行的另外一種,是張量并行。
如果說(shuō)流水線并行是將一個(gè)模型按層「垂直」分割,那么,張量并行則是在一個(gè)層內(nèi)「橫向」分割某些操作。

具體來(lái)說(shuō),張量并行是將模型的張量(如權(quán)重矩陣)按維度切分到不同的GPU上運(yùn)行的并行方式。
張量切分方式分為按行進(jìn)行切分和按列進(jìn)行切分,分別對(duì)應(yīng)行并行(Row Parallelism)(權(quán)重矩陣按行分割)與列并行(Column Parallelism)(權(quán)重矩陣按列分割)。

每個(gè)節(jié)點(diǎn)處理切分后的子張量。最后,通過(guò)集合通信操作(如All-Gather或All-Reduce)來(lái)合并結(jié)果。

張量并行的優(yōu)點(diǎn),是適合單個(gè)張量過(guò)大的情況,可以顯著減少單個(gè)節(jié)點(diǎn)的內(nèi)存占用。
張量并行的缺點(diǎn),是當(dāng)切分維度較多的時(shí)候,通信開(kāi)銷(xiāo)比較大。而且,張量并行的實(shí)現(xiàn)過(guò)程較為復(fù)雜,需要仔細(xì)設(shè)計(jì)切分方式和通信策略。
放一張數(shù)據(jù)并行、流水線并行、張量并行的簡(jiǎn)單對(duì)比:

專(zhuān)家并行
2025年初DeepSeek爆紅的時(shí)候,有一個(gè)詞也跟著火了,那就是MoE(Mixture of Experts,混合專(zhuān)家模型)。
MoE模型的核心是“多個(gè)專(zhuān)家層+路由網(wǎng)絡(luò)(門(mén)控網(wǎng)絡(luò))”。

專(zhuān)家層的每個(gè)專(zhuān)家負(fù)責(zé)處理特定類(lèi)型的token(如語(yǔ)法、語(yǔ)義相關(guān))。路由網(wǎng)絡(luò)根據(jù)輸入token的特征,選擇少數(shù)專(zhuān)家處理這個(gè)token,其他專(zhuān)家不激活。
MoE實(shí)現(xiàn)了任務(wù)分工、按需分配算力,因此大幅提升了模型效率。
專(zhuān)家并行(Expert Parallelism),是MoE(混合專(zhuān)家模型)中的一種并行計(jì)算策略。它通過(guò)將專(zhuān)家(子模型)分配到不同的GPU上,實(shí)現(xiàn)計(jì)算負(fù)載的分布式處理,提高計(jì)算效率。
專(zhuān)家并行與之前所有的并行相比,最大的不同在于,輸入數(shù)據(jù)需要通過(guò)一個(gè)動(dòng)態(tài)的路由選擇機(jī)制分發(fā)給相應(yīng)專(zhuān)家,此處會(huì)涉及到一個(gè)所有節(jié)點(diǎn)上的數(shù)據(jù)重分配的動(dòng)作。
然后,在所有專(zhuān)家處理完成后,又需要將分散在不同節(jié)點(diǎn)上的數(shù)據(jù)按原來(lái)的次序整合起來(lái)。
這樣的跨片通信模式,稱(chēng)為All-to-All。(再次參考:到底什么是All-Reduce、All-to-All?)
專(zhuān)家并行可能存在負(fù)載不均衡的問(wèn)題。某個(gè)專(zhuān)家所接收到的輸入數(shù)據(jù)大于了其所能接收的范圍,就可能導(dǎo)致Tokens不被處理或不能被按時(shí)處理,成為瓶頸。
所以,設(shè)計(jì)合理的門(mén)控機(jī)制和專(zhuān)家選擇策略,是部署專(zhuān)家并行的關(guān)鍵。
混合并行
在實(shí)際應(yīng)用中,尤其是訓(xùn)練萬(wàn)億參數(shù)級(jí)別的超大模型時(shí),幾乎不會(huì)只使用單一的并行策略,而是采用多維度的混合并行(結(jié)合使用多種并行策略)。
例如:
數(shù)據(jù)并行+張量并行:數(shù)據(jù)并行處理批量樣本,張量并行處理單樣本的大矩陣計(jì)算。
流水線并行+專(zhuān)家并行:流水線并行劃分模型層,專(zhuān)家并行劃分層內(nèi)專(zhuān)家模塊。
更高級(jí)的,是3D并行,通過(guò)“數(shù)據(jù)并行+張量并行+流水線并行”,實(shí)現(xiàn)三重拆分,是超大模型訓(xùn)練的主流方案。

3D并行
最后的話
好啦,以上就是關(guān)于DP、PP、TP、EP等并行訓(xùn)練方式的介紹。大家都看懂了沒(méi)?

并行計(jì)算方式其實(shí)非常復(fù)雜,剛才我們只是做了最簡(jiǎn)單的介紹。但在真實(shí)工作中,開(kāi)發(fā)者無(wú)需了解具體的實(shí)現(xiàn)細(xì)節(jié),因?yàn)闃I(yè)界提供了例如DeepSpeed(微軟開(kāi)源,支持3D并行+ZeRO內(nèi)存優(yōu)化)、Megatron-LM(NVIDIA開(kāi)源,3D并行的標(biāo)桿)、FSDP等開(kāi)源軟件,能夠讓開(kāi)發(fā)者直接進(jìn)行大語(yǔ)言模型訓(xùn)練。
小棗君之所以要專(zhuān)門(mén)介紹并行訓(xùn)練方式,其實(shí)更多是為了幫助大家深入地理解算力集群架構(gòu)和網(wǎng)絡(luò)的設(shè)計(jì)。
大家可以看到,不同的并行訓(xùn)練方式,有著不同的通信流量特點(diǎn)。算力集群整體架構(gòu)和網(wǎng)絡(luò)設(shè)計(jì),需要盡量去適配這些并行計(jì)算方式的流量特點(diǎn),才能滿足模型訓(xùn)推任務(wù)的要求,實(shí)現(xiàn)更高的工作效率。
比如說(shuō),數(shù)據(jù)并行,由于需要頻繁同步梯度信息,對(duì)網(wǎng)絡(luò)帶寬要求較高,需要確保網(wǎng)絡(luò)帶寬能夠滿足大量梯度數(shù)據(jù)快速傳輸?shù)男枨螅苊庖驇挷蛔銓?dǎo)致通信延遲,影響訓(xùn)練效率。
流水線并行,大模型的每一段,在不同的服務(wù)器上以流水線的方式逐步計(jì)算,涉及到多個(gè)服務(wù)器“串起來(lái)”,就建議部署在比較靠近的服務(wù)器上(盡量部署在葉脊網(wǎng)絡(luò)的同一個(gè)leaf葉下)。
張量并行,通信數(shù)據(jù)量大,就建議部署在一臺(tái)服務(wù)器的多個(gè)GPU上進(jìn)行計(jì)算。
專(zhuān)家并行中,不同專(zhuān)家分配在不同GPU上,GPU間需要交換中間計(jì)算結(jié)果等信息,其通信流量特點(diǎn)取決于專(zhuān)家的數(shù)量以及數(shù)據(jù)交互的頻率等,也需要合理規(guī)劃GPU間的連接方式和通信路徑。

總之,在GPU算卡性能越來(lái)越難以提升的背景下,深入研究并行計(jì)算的設(shè)計(jì),從架構(gòu)和網(wǎng)絡(luò)上挖掘潛力,是業(yè)界的必然選擇。
隨著AI浪潮的繼續(xù)發(fā)展,以后是否還會(huì)出現(xiàn)其它的并行訓(xùn)練方式呢?讓我們拭目以待吧!
文章來(lái)源于鮮棗課堂,作者小棗君
-
TP
+關(guān)注
關(guān)注
0文章
81瀏覽量
31546 -
DP
+關(guān)注
關(guān)注
1文章
244瀏覽量
42474 -
pp
+關(guān)注
關(guān)注
0文章
8瀏覽量
8515 -
ep
+關(guān)注
關(guān)注
0文章
16瀏覽量
16504 -
AI大模型
+關(guān)注
關(guān)注
0文章
401瀏覽量
1026
發(fā)布評(píng)論請(qǐng)先 登錄
AI模型是如何訓(xùn)練的?訓(xùn)練一個(gè)模型花費(fèi)多大?
基于Transformer做大模型預(yù)訓(xùn)練基本的并行范式
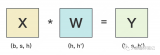
訓(xùn)練好的ai模型導(dǎo)入cubemx不成功怎么處理?
海思SD3403邊緣計(jì)算AI數(shù)據(jù)訓(xùn)練概述
訓(xùn)練好的ai模型導(dǎo)入cubemx不成功怎么解決?
AI模型是如何訓(xùn)練的?訓(xùn)練一個(gè)模型花費(fèi)多大?
什么是預(yù)訓(xùn)練 AI 模型?
什么是預(yù)訓(xùn)練AI模型?
圖解大模型訓(xùn)練之:數(shù)據(jù)并行上篇(DP, DDP與ZeRO)
大模型分布式訓(xùn)練并行技術(shù)(一)-概述
基于PyTorch的模型并行分布式訓(xùn)練Megatron解析

如何訓(xùn)練自己的AI大模型
為什么ai模型訓(xùn)練要用gpu
GPU是如何訓(xùn)練AI大模型的
一文看懂AI訓(xùn)練、推理與訓(xùn)推一體的底層關(guān)系




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論