 寒武紀產品與眾智FlagOS全面適配
寒武紀產品與眾智FlagOS全面適配

大模型的快速發展正推動AI算力需求進入爆發式增長階段。與此同時,不同應用場景又對AI芯片提出了多樣化的挑戰:例如在大模型Prefill場景,對算力要求更高,對內存帶寬的要求則遠低于Decode場景;大模型訓練場景則不僅需要高算力與大容量內存,還需要更高的互連帶寬與大規模集群組網能力。顯然,單一的芯片架構已難以滿足多元化的業務需求,為部署不同類型的業務,大模型應用廠商往往需要引入多種不同架構的AI芯片。因此造成的跨芯片架構間業務代碼遷移與維護工作,尤其是算子遷移工作,往往耗時數月,成為業務遷移流程中的主要瓶頸。
針對行業痛點,北京智源人工智能研究院依托AI算法優化、芯片架構分析、編譯器技術和分布式通信領域的多年積累,聯手眾多社區伙伴共同啟動了眾智FlagOS項目,旨在通過統一軟件層解耦AI模型與異構硬件,打破不同架構芯片之間的軟件生態壁壘,為芯片硬件與上層AI應用之間搭建統一且高效銜接的橋梁,系統性解決“適配難、調優慢、協同弱”三大行業難題,實現“一次開發,處處運行”,致力于為AI產業打造開放協同的創新技術底座。
從2024年初起,寒武紀和智源研究院開始進行FlagGems(基于Triton的高性能通用AI算子庫)的聯合開發工作,后續進一步拓展到FlagTree(統一多后端的增強版Triton編譯器)、FlagCX(統一通信庫)、FlagScale(并行訓推一體框架)等組件。至2025年9月,寒武紀已經完成對FlagOS下各組件的適配和優化工作。隨著智源研究院在“AICC2025暨首屆FlagOS開放計算開發者大會”發布了FlagOS v1.5,寒武紀產品可通過眾智大模型全棧生態基座支撐更廣泛的生態伙伴。
寒武紀與FlagOS的適配與優化主要集中在算子、編譯器、分布式通信庫和并行框架組件等方面,以下將逐一介紹。
FlagGems
FlagGems是基于Triton語言實現的大模型算子庫,目標是在多硬件后端上提供高性能的算子實現,并通過基準測試與自適應調優,持續優化性能表現。項目提供面向不同芯片廠商的后端適配機制、可配置的調優參數體系,以及完整的文檔、測試與基準評測入口。
作為FlagOS生態的核心算子組件庫,FlagGems以“高復用性、極致性能、架構通用性”為設計理念,通過標準化算子模塊體系,大幅降低芯片廠商的算子開發與適配成本。作為首批深度參與FlagGems生態建設的芯片廠商,寒武紀全程投入算子適配與性能調優驗證工作,目前已完成206/209個核心算子的全功能支持,平均性能提升達1.9倍,其中絕大部分算子性能達到原生算子的80%以上。寒武紀將持續探索性能優化邊界,針對低效能的凹點算子展開專項攻堅,進一步消除性能瓶頸,實現全算子高性能覆蓋。

FlagTree
FlagTree是一個面向多種AI芯片的開源統一編譯器,致力于為多元化的AI硬件生態提供統一的編譯、適配和優化能力。項目以Triton生態為基礎,兼容現有主流AI芯片后端,統一代碼倉庫,并快速實現單倉庫多后端支持,為上游模型開發者與下游芯片廠商的協作與創新提供了極大便利,可大幅提升開發效率,促進了Triton生態的繁榮和演進。
在寒武紀與FlagTree的深度合作中,寒武紀Triton已成功合并至FlagTree主代碼倉庫。基于FlagTree編譯器與FlagGems算子庫,寒武紀針對QWen3-8B大語言模型開展全鏈路適配驗證:將模型中的37個核心算子(涵蓋矩陣乘法matmul、層歸一化layer_norm、注意力機制attention等關鍵計算單元)替換為FlagGems提供的Triton優化算子,在寒武紀芯片上進行推理性能測試,整網推理吞吐性能達到原生算子版本的80%,完全滿足實時推理場景需求。
這一成果不僅驗證了FlagTree+FlagGems技術棧的工程穩定性,更彰顯了Triton框架兩大核心優勢:顯著提升開發效率,算子迭代周期從傳統的2周大幅縮短至3天;跨架構兼容性,為前沿LLM模型的快速工程化開辟了高效技術路徑。
FlagCX
FlagCX是一款面向大規模AI訓練的通信中間件,通過對底層硬件差異進行抽象,使開發者能夠在異構硬件環境中無縫開展分布式訓練,從而有效提升資源利用效率和訓練性能。
FlagCX開源后,寒武紀即開始積極參與共建。從FlagCX v0.1.0版本開始,寒武紀就實現了絕大部分通信原語的支持,如今已完成對allreduce、reducescatter、allgather、send、recv等通信操作的全面支持。這種支持并非簡單的接口對接,而是通過FlagCX統一適配器模塊,實現了FlagCX與寒武紀原生CNCL通信庫的高效、深度集成。
FlagCX通過其核心層(FlagCX Core)處理異構通信,同時通過適配器無縫兼容包括寒武紀CNCL在內的各大廠商同構通信庫。這意味著,當用戶在純寒武紀MLU集群上進行同構訓練時,FlagCX能夠直接調用經過深度優化的CNCL庫,確保通信性能與直接使用CNCL原生庫基本持平,幾乎無性能損耗。這種深度集成保障寒武紀用戶在享受FlagCX統一接口便利性的同時,同樣可以獲得原生性能體驗。

在寒武紀MLU與其他AI芯片的混合環境中,FlagCX成功保障混合訓練的模型精度與純MLU獨立訓練結果完全一致。更重要的是,在如此復雜的異構環境下,平均單卡吞吐量仍能達到MLU獨立訓練的99%以上。性能測試表明寒武紀MLU與FlagCX的結合,可以做到精度無損且性能和原生通信庫持平的水平,為用戶使用異構算力資源進行大模型訓推提供了可靠的技術基礎。

FlagScale
FlagScale是智源人工智能研究院主導開發的大模型全生命周期工具集,是FlagOS生態的核心組成部分,致力于構建覆蓋模型開發、分布式訓練與推理部署的統一技術體系。框架融合了Megatron-LM、vLLM、SGLang、Verl等主流開源項目,為大模型提供從訓練到推理的一站式解決方案。
在與FlagScale的深度合作中,寒武紀基于MLU硬件平臺完成了對Megatron-LM訓練框架和vLLM推理框架的全面適配與優化。在訓練環節,MLU平臺已充分支持智源Megatron體系下的多類主流模型,包括Llama系列、Aquila2系列、Qwen3系列等,并覆蓋從模型并行到混合精度的完整訓練流程;在推理環節,MLU平臺對vLLM框架實現了完備的兼容支持,可高效運行社區開源的多種大語言模型推理任務。
在完成框架級適配后,結合MLU架構特性,寒武紀還圍繞通信、算子和內存調度進行了多層次性能優化。通過集成自研CNCL通信庫、CNNL高性能算子庫及混合精度算子調度機制,可顯著提升分布式訓練的通信效率與算力利用率;在vLLM推理中,針對 Attention、LayerNorm、GEMM等核心算子進行了指令級與內存訪問模式優化,為后續性能提升奠定基礎。
憑借在FlagScale生態中的深度集成與架構適配經驗,寒武紀MLU平臺具備了對未來FlagScale開發或開放的新模型進行快速、即時適配的能力。無論是Megatron-LM體系下的新一代訓練模型,還是vLLM推理端的最新開源模型,MLU都能夠在框架演進中實現同步更新與性能優化,保持良好的生態兼容性和持續演進能力。
FlagScale的全面適配與持續優化,使寒武紀MLU在大模型訓練與推理全鏈路中具備了統一、高效、可擴展的框架級生態能力。這一進展不僅加速了國產AI硬件在開源大模型生態中的融合,也為大模型的工程化和高性能部署提供了有力支撐。
-
AI
+關注
關注
91文章
40403瀏覽量
301970 -
寒武紀
+關注
關注
13文章
217瀏覽量
74984 -
大模型
+關注
關注
2文章
3701瀏覽量
5224
原文標題:寒武紀擁抱眾智FlagOS生態
文章出處:【微信號:Cambricon_Developer,微信公眾號:寒武紀開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
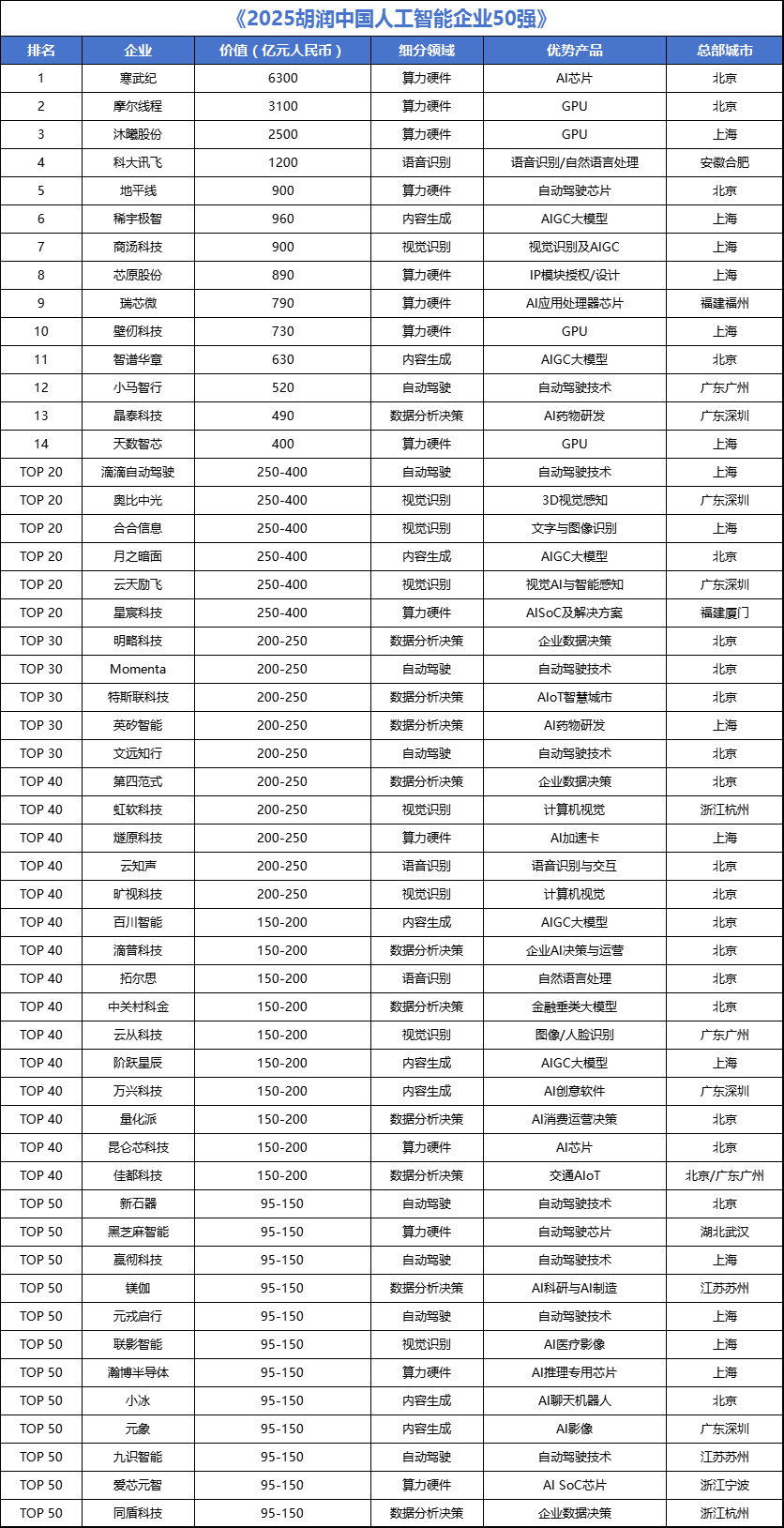
中國AI企業50強發布!寒武紀位居榜首,AI芯片公司包攬前三
寒武紀“炸裂”財報!一季度營收增長40倍,積極備貨應對“爆單”?
寒武紀去年營收增長超400% 凈利潤20.59億同比扭虧 寒武紀首個盈利年度
寒武紀實現對GLM-5的Day 0適配
寒武紀:預計2025年營收增長超400%,凈利潤扭虧為盈

寒武紀引領AI芯片軟件新生態

商湯科技與寒武紀達成戰略合作
寒武紀成功適配DeepSeek-V3.2-Exp模型

寒武紀股價破1200大關創歷史新高 DeepSeek適配國產芯片成直接原因
寒武紀85后創始人陳天石身價超1500億
寒武紀聯手階躍星辰成立模芯生態創新聯盟
寒武紀基于思元370芯片的MLU370-X8 智能加速卡產品手冊詳解

寒武紀思元370芯片參數特性詳解
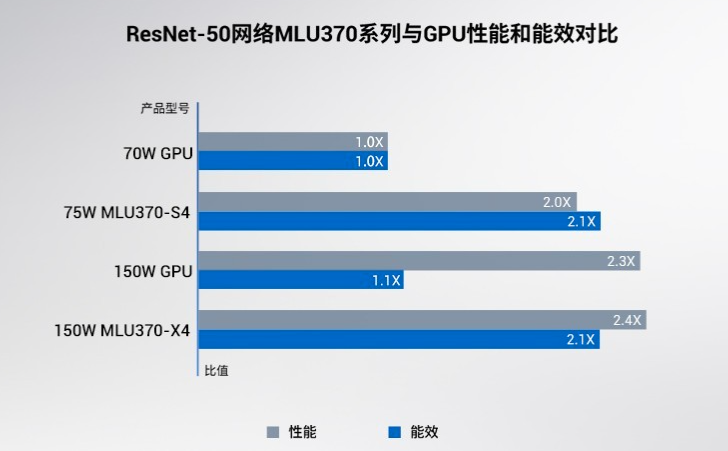
寒武紀一季度營收大漲4230% 凈利潤3.55億 扭虧為盈
美國業務收入占比低,寒武紀等回應加征關稅




 工商網監
工商網監
評論