 寒武紀成功適配DeepSeek-V3.2-Exp模型
寒武紀成功適配DeepSeek-V3.2-Exp模型

2025年9月29日,寒武紀已同步實現對深度求索公司最新模型DeepSeek-V3.2-Exp的適配,并開源大模型推理引擎vLLM-MLU源代碼。代碼地址和測試步驟見文末,開發者可以在寒武紀軟硬件平臺上第一時間體驗DeepSeek-V3.2-Exp的亮點。
寒武紀一直高度重視大模型軟件生態建設,支持以DeepSeek為代表的所有主流開源大模型。借助于長期活躍的生態建設和技術積累,寒武紀得以快速實現對DeepSeek-V3.2-Exp這一全新實驗性模型架構的day 0適配和優化。
寒武紀一直重視芯片和算法的聯合創新,致力于以軟硬件協同的方式,優化大模型部署性能,降低部署成本。此前,我們對DeepSeek系列模型進行了深入的軟硬件協同性能優化,達成了業界領先的算力利用率水平。針對本次的DeepSeek-V3.2-Exp新模型架構,寒武紀通過Triton算子開發實現了快速適配,利用BangC融合算子開發實現了極致性能優化,并基于計算與通信的并行策略,再次達成了業界領先的計算效率水平。依托DeepSeek-V3.2-Exp帶來的全新DeepSeek Sparse Attention機制,疊加寒武紀的極致計算效率,可大幅降低長序列場景下的訓推成本,共同為客戶提供極具競爭力的軟硬件解決方案。
↓ vLLM-MLU DeepSeek-V3.2-Exp適配的源碼(點擊文末“閱讀原文”可直接跳轉)↓
https://github.com/Cambricon/vllm-mlu
基于vLLM-MLU的DeepSeek-V3.2-Exp運行指南
一、環境準備
軟件:需使用寒武紀訓推一體鏡像Cambricon Pytorch Container部署,鏡像內預裝運行vLLM-MLU的各項依賴。
硬件:4臺8卡MLU服務器。
如需獲取完整的軟硬件運行環境,請通過官方渠道聯系寒武紀。
二、運行步驟及結果展示
Step1:模型下載
模型文件請從Huggingface官網自行下載,后文用${MODEL_PATH}表示下載好的模型路徑。
Step 2:啟動容器
加載鏡像,啟動容器,命令如下:
# 加載鏡像 docker load -i cambricon_pytorch_container-torch2.7.1-torchmlu1.28.0-ubuntu22.04-py310.tar.gz # 啟動容器 docker run -it --net=host --shm-size'64gb'--privileged -it --ulimitmemlock=-1${IMAGE_NAME} /bin/bash # 安裝社區vLLM 0.9.1版本 pushd${VLLM_SRC_PATH}/vllm VLLM_TARGET_DEVICE=empty pip install . popd # 安裝寒武紀vLLM-mlu pushd${VLLM_SRC_PATH}/vllm-mlu pip install . popd
Step 3:啟動Ray服務
在執行模型前,需要先啟動ray服務。啟動命令如下:
# 設置環境變量
exportGLOO_SOCKET_IFNAME=${INFERENCE_NAME}
exportNOSET_MLU_VISIBLE_DEVICES_ENV_VAR=1
# 主節點
ray start --head--port${port}
# 從節點
ray start --address='${master_ip}:${port}'
Step 4:運行離線推理
這里提供簡易的離線推理腳本`offline_inference.py`:
importsys fromvllmimportLLM, SamplingParams defmain(model_path): # Sample prompts. prompts = [ "Hello, my name is", "The capital of France is", "The future of AI is", ] sampling_params = SamplingParams( temperature=0.6, top_p=0.95, top_k=20, max_tokens=10) # Create an LLM. engine_args_dict = { "model": model_path, "tensor_parallel_size":32, "distributed_executor_backend":"ray", "enable_expert_parallel":True, "enable_prefix_caching":False, "enforce_eager":True, "trust_remote_code":True, } llm = LLM(**engine_args_dict) # Generate texts from the prompts. outputs = llm.generate(prompts, sampling_params) # Print the outputs. foroutputinoutputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt:{prompt!r}, Generated text:{generated_text!r}") if__name__ =='__main__': main(sys[1])
運行如下命令,完成模型離線推理:
# 運行推理命令 pythonoffline_inference.py --model${MODEL_PATH}
運行結果符合預期,具體結果如下:

Step 5:運行在線推理
分別啟動server和client,完成推理服務,示例如下:
# server
vllmserve${MODEL_PATH}
--port8100
--max-model-len40000
--distributed-executor-backend ray
--trust-remote-code
--tensor-parallel-size32
--enable-expert-parallel
--no-enable-prefix-caching
--disable-log-requests
--enforce-eager
# client, we post a single request here.
curl -X POST http://localhost:8100/v1/completions
-H"Content-Type: application/json"
-d'{"model":${MODEL_PATH},
"prompt": "The future of AI is",
"max_tokens": 50, "temperature": 0.7
}'
運行結果如下:

提取輸入輸出信息如下,符合預期。
Prompt:The futureofAIis Output:being shapedbya numberofkey trends. These include the riseoflargelanguagemodels, the increasing useofAIinenterprise, the developmentofmore powerfulandefficient AI hardware,andthe growing focusonAI ethicsandsafety. Largelanguagemodelsare
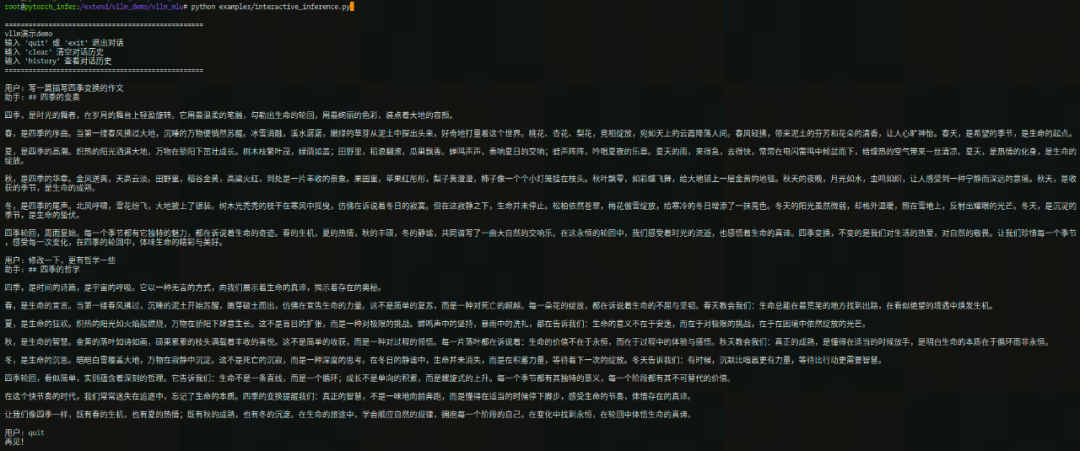
Step 6:運行交互式對話
使用vLLM-MLU框架,運行交互式對話demo,執行結果如下:
-
開源
+關注
關注
3文章
4245瀏覽量
46284 -
寒武紀
+關注
關注
13文章
217瀏覽量
74980 -
DeepSeek
+關注
關注
2文章
836瀏覽量
3320
原文標題:寒武紀Day 0適配DeepSeek-V3.2-Exp,同步開源推理引擎vLLM-MLU
文章出處:【微信號:Cambricon_Developer,微信公眾號:寒武紀開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
寒武紀科技上市了嗎_寒武紀科技股權結構是怎樣的
寒武紀芯片量產了嗎_如何看待國產自主的寒武紀芯片
寒武紀科技的股東都有誰_寒武紀科技十大股東
寒武紀科技生態爆發,產業伙伴展示寒武紀芯片應用
麒麟980將整合寒武紀科技的最新AI技術:“寒武紀1M”
寒武紀先后推出了用于終端場景的寒武紀1A寒武紀1M系列芯片
寒武紀的思元(MLU)云端智能加速卡與百川智能完成大模型適配,攜手創新生成式AI

寒武紀與智象未來達成戰略合作并完成大模型適配




 工商網監
工商網監
評論