 從模型到產品:Qwen2.5-VL在BM1684X邊緣計算部署全攻略
從模型到產品:Qwen2.5-VL在BM1684X邊緣計算部署全攻略

前言:部署意義與應用場景
1.1 Qwen-2-5-VL與BM1684X的組合
行業意義:
- ? 邊緣AI革命:大模型從云端下沉到邊緣設備是當前AI發展的關鍵趨勢。根據ABI Research數據,到2026年,75%的企業數據將在邊緣處理
- ? 成本效益:相比云端部署,邊緣部署可降低80%的長期運營成本(IDC 2023報告)
- ? 隱私安全:醫療、金融等敏感數據無需上傳云端,滿足GDPR等合規要求
典型應用場景:

1.2 BM1684X的獨特優勢
硬件特性:
- ? 32TOPS INT8算力,特別適合Transformer架構的量化部署
- ? 獨特的內存訪問模式(Twin/Quadruplets Interleave)優化大模型參數吞吐
- ? 專用DQ/RQ加速指令,提升量化模型執行效率
一、深度環境配置指南
1.1 系統燒錄
為了讓BM1684X開發板順利啟動,我們需要將Ubuntu 20.04系統鏡像燒錄到TF卡中,使其作為啟動介質。
選擇TF卡作為啟動方式,主要有以下幾點考慮:
- ? BM1684X開發板通常不預裝操作系統,需要用戶自行安裝;
- ? 與直接燒寫到eMMC相比,使用TF卡啟動更為安全,能有效避免因操作失誤導致的設備損壞;
- ? TF卡便于系統遷移和備份,提高開發靈活性。
燒錄方法:使用 balenaEtcher 等工具,將系統鏡像寫入TF卡。完成后,將TF卡插入開發板的TF卡槽即可啟動。
# 在Linux主機操作(示例)# 步驟1:插入TF卡,確認設備節點(通常為/dev/sdX)lsblk
# 步驟2:下載系統鏡像(以V24.04.01為例)
wgethttps://sophon-file.sophon.cn/sophon-prod-s3/drive/24/04/01/sophon-img-ubuntu20.04-arm64-20240401.img.gz
# 步驟3:解壓并燒錄(注意替換sdX為實際設備)
gunzipsophon-img-ubuntu20.04-arm64-20240401.img.gzsudodd if=sophon-img-ubuntu20.04-arm64-20240401.img of=/dev/sdX bs=4M status=progresssync
“關鍵注意:
- ? 使用sync命令確保寫入完成
- ? 推薦使用Class 10及以上速度的TF卡
- ? 首次啟動后執行resize2fs /dev/mmcblk0p1擴展根分區”
1.2 Python環境配置
目的:創建專用的 Python 3.10 虛擬環境,并安裝基礎依賴。
原因:
- ? Qwen-2-5-VL 依賴特定版本的 Python 庫;
- ? 虛擬環境可避免與系統 Python 沖突;
- ? Python 3.10 在類型提示和性能優化方面表現更優,適合 AI 應用開發。
操作步驟:
# 步驟1:安裝Python 3.10sudo apt install -y python3.10 python3.10-venv
# 步驟2:創建虛擬環境(在/data分區保證足夠空間)
python3.10-m venv /data/qwen_env --system-site-packages
# 步驟3:激活環境并升級
pipsource /data/qwen_env/bin/activatepython-m pip install --upgrade pip
# 步驟4:安裝核心依賴(使用清華鏡像加速)
pipconfig set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pipinstall torch==2.1.0torchvision==0.16.0--extra-index-url https://download.pytorch.org/whl/cu118
典型問題排查:
- ? 若遇到GLIBC_2.32 not found錯誤,需更新系統:sudo apt upgrade libc6
- ? 內存不足時添加交換空間:
sudofallocate -l 8G /swapfile
sudochmod600 /swapfile
sudomkswap /swapfile
sudoswapon /swapfile
二、模型部署深度解析
2.1 模型獲取與轉換
目的:
獲取 Qwen-2-5-VL 模型(BM1684X 專用格式),可選擇下載已編譯模型或手動轉換原始模型。
原因:
- ? 預編譯 .bmodel 文件已針對 BM1684X 的指令集進行優化,開箱即用;
- ? 原始 PyTorch 模型需要經過量化與編譯,才能在 TPU 上高效運行;
- ? 若需使用自定義模型,需掌握完整的模型轉換流程,便于遷移和調試。
操作步驟:
# 方案A:直接下載預編譯模型(推薦)
wgethttps://example.com/qwen2_5-vl_bm1684x_int4_seq1024.bmodel -O /data/models/qwen_vl.bmodel
# 方案B:從PyTorch模型轉換(需TPU-MLIR工具鏈)
tpu_mlir--model qwen_vl.onnx\
--input_shape"1,3,448,448"\
--input_type float32\
--output_type int8\
--calibration_dataset ./cali_images/\
--quantize\
--processor bm1684x\
--output qwen_vl_int8.bmodel
轉換原理:
- 1. 圖優化:合并冗余算子,將PyTorch算子映射為TPU原生算子
- 2. 量化校準:使用校準數據集統計激活值分布,確定最優量化參數
- 3. 指令生成:根據BM1684X的SIMD架構生成高效機器碼
2.2 內存優化配置(3W詳解)
目的:調整BM1684X的內存訪問模式以適應大模型需求。
原因:
- ? 默認內存模式可能造成帶寬瓶頸
- ? 不同場景需要不同的內存訪問策略:
- ? 視頻分析:需要獨立帶寬給視頻編解碼? 純推理任務:需要最大化內存吞吐
操作步驟:
#查看當前模式cat/proc/sophon/mem_mode
#模式切換(需要root權限)
# 模式0:獨立通道(調試用)echo0 > /proc/sophon/mem_mode
#模式1:雙通道交叉(視頻+AI場景)echo1 > /proc/sophon/mem_mode
#模式2:四通道全交叉(純AI推理)echo2 > /proc/sophon/mem_mode &&sync
性能對比數據:
| 模式 | 帶寬(GB/s) | 適合場景 | ResNet50 fps |
| 0 | 17.1 | 調試 | 152 |
| 1 | 38.4 | 多模態 | 218 |
| 2 | 68.3 | 大模型 | 305 |
三、實戰:智能安防部署案例
3.1 場景需求
某工廠需要實時監測以下情況:
- ? 人員是否佩戴安全帽
- ? 設備操作是否符合規程
- ? 危險區域闖入檢測
3.2 部署方案
importcv2from
qwen_vl_wrapperimportQwenVL
# 初始化
model = QwenVL(
bmodel_path="/data/models/qwen_vl.bmodel",
tokenizer_path="./tokenizer",
dev_id=0
)
# 視頻分析循環
cap = cv2.VideoCapture("rtsp://factory_cam1")
whileTrue:
ret, frame = cap.read()
ifnotret:break# 多問題并行分析
queries = [
"圖中是否有未戴安全帽的人員?",
"是否有人員在危險區域內?",
"設備操作桿是否在正確位置?" ]
results = model.batch_predict(frame, queries)
# 報警邏輯for q, ans in zip(queries, results):
if"是"inans:
trigger_alert(q, frame)
3.3 性能優化技巧
- 1.幀采樣:對高幀率視頻每3幀處理1次
- 2.區域聚焦:只對ROI區域進行高分辨率分析
- 3.結果緩存:對靜態場景復用之前的分析結果
四、進階調試技巧
4.1 性能分析工具
# 查看TPU利用率
bm_top
# 詳細性能分析(需SDK工具)
bm_profile --cmd"python demo.py"--output profile.json
# 內存使用分析
bm_memcheck --tool=valgrind python demo.py
4.2 典型錯誤處理
錯誤1:TPU timeout error
- ? 原因:單次推理超過硬件時限
- ? 解決:減小輸入尺寸或拆分模型
錯誤2:Memory allocation failed
- ? 原因:內存碎片化
- ? 解決:重啟TPU服務
sudosystemctl restart bm-sophon
錯誤3:Quantization range error
- ? 原因:輸入數據超出校準范圍
- ? 解決:添加輸入歸一化:
input_tensor= (input_tensor -127.5) /128.0 # 適配INT8量化
五、Qwen-2.5-VL使用驗證
使用方式
# 視頻識別 python3 qwen2_5_vl.py--vision_inputs="[{"type":"video_url","video_url":{"url":"../datasets/videos/carvana_video.mp4"},"resized_height":420,"resized_width":630,"nframes":2}]" # 圖片識別 python3 qwen2_5_vl.py--vision_inputs="[{"type":"image_url","image_url":{"url":"../datasets/images/panda.jpg"},"max_side":420}]" # 同時 python3 qwen2_5_vl.py--vision_inputs="[{"type":"video_url","video_url":{"url":"../datasets/videos/carvana_video.mp4"},"resized_height":420,"resized_width":630,"nframes":2},{"type":"image_url","image_url":{"url":"../datasets/images/panda.jpg"},"max_side":840}]" # 純文本對話 python3 qwen2_5_vl.py--vision_inputs=""
使用效果

六、擴展應用開發
6.1 多模型流水線
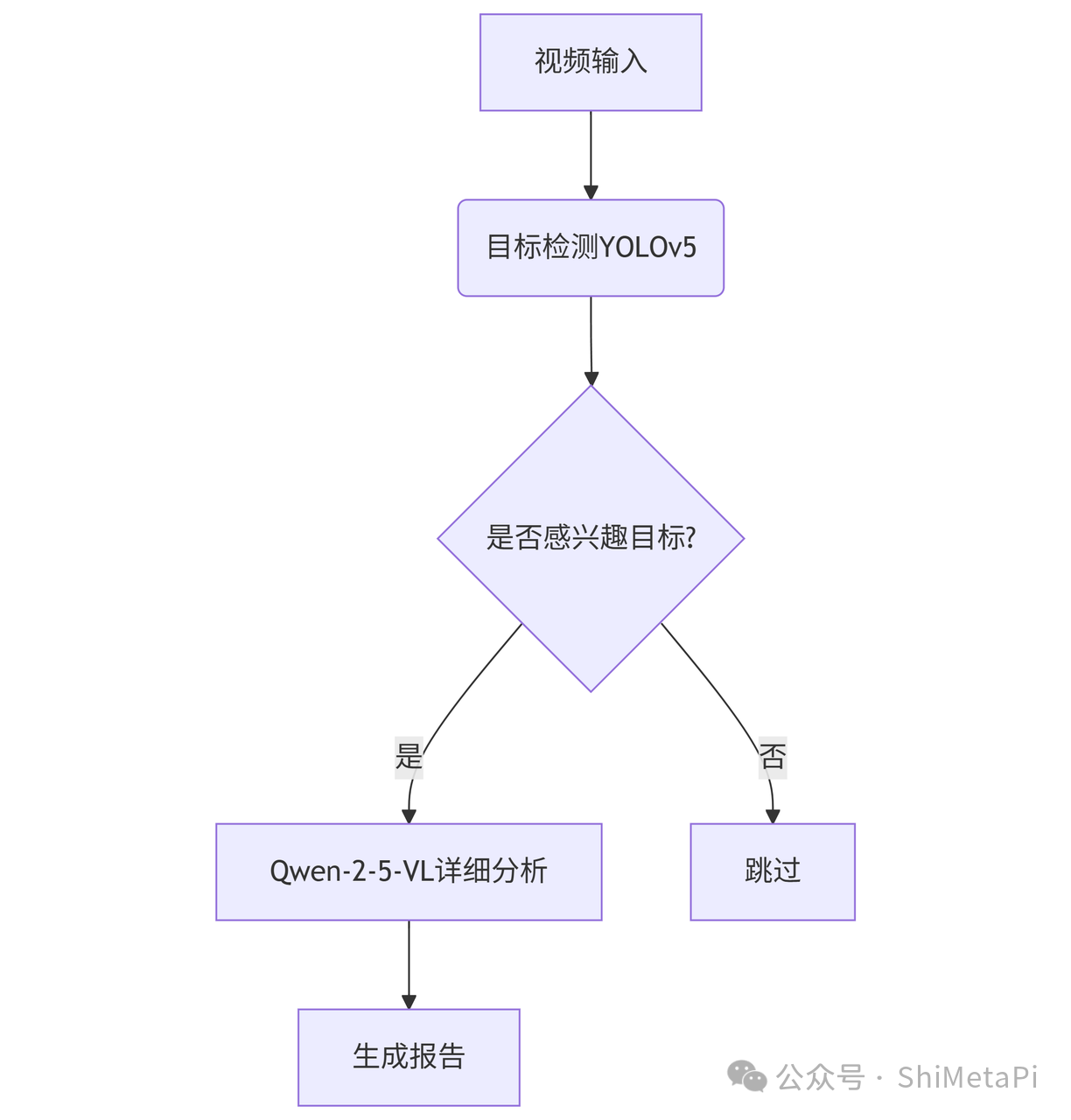
6.2 與業務系統集成
fromflaskimportFlask, request
importnumpyasnp
app = Flask(__name__)
model = load_model()
@app.route('/analyze', methods=['POST'])def analyze():
img = np.frombuffer(request.files['image'].read(), np.uint8)
question = request.form['question']
result = model.predict(img, question)
return{'answer': result}
if__name__ =='__main__':
app.run(host='0.0.0.0', port=5000)
總結
本指南不僅提供了step-by-step的技術實現,更揭示了邊緣部署多模態大模型的技術本質與商業價值。通過理解每個操作背后的原理和實現方法,開發者可以靈活應對各種工業場景的定制化需求。
-
AI
+關注
關注
91文章
40474瀏覽量
302079 -
邊緣計算
+關注
關注
22文章
3541瀏覽量
53595 -
通義千問
+關注
關注
1文章
42瀏覽量
622 -
BM1684
+關注
關注
0文章
7瀏覽量
239
發布評論請先 登錄
【算能RADXA微服務器試用體驗】Radxa Fogwise 1684X Mini 規格

基于算能第四代AI處理器BM1684X的邊緣計算盒子

探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業落地

利用英特爾OpenVINO在本地運行Qwen2.5-VL系列模型
Qwen3-VL 4B/8B全面適配,BM1684X成邊緣最佳部署平臺!
SAM(通用圖像分割基礎模型)丨基于BM1684X模型部署指南



 工商網監
工商網監
評論