 后摩智能5篇論文入選國際頂會
后摩智能5篇論文入選國際頂會

2025年伊始,后摩智能在三大國際頂會(AAAI、ICLR、DAC)中斬獲佳績,共有5篇論文被收錄,覆蓋大語言模型(LLM)推理優化、模型量化、硬件加速等前沿方向。
AAAI作為人工智能領域的綜合性頂級會議,聚焦AI基礎理論與應用創新;ICLR作為深度學習領域的權威會議,專注于表示學習、神經網絡架構和優化方法等基礎技術;DAC則是電子設計自動化(EDA)領域最重要的國際學術會議之一,涵蓋半導體設計、計算機體系結構、硬件加速、芯片設計自動化、低功耗計算、可重構計算以及AI在芯片設計中的應用等方向。以下為后摩智能本年度入選論文概述:
01【AAAI-2025】Pushing the Limits of BFP on Narrow Precision LLM Inference
?論文鏈接:https://arxiv.org/abs/2502.00026
大語言模型(LLMs)在計算和內存方面的巨大需求阻礙了它們的部署。塊浮點(BFP)已被證明在加速線性運算(LLM 工作負載的核心)方面非常有效。然而,隨著序列長度的增長,非線性運算(如注意力機制)由于其二次計算復雜度,逐漸成為性能瓶頸。這些非線性運算主要依賴低效的浮點格式,導致軟件優化困難和硬件開銷較高。
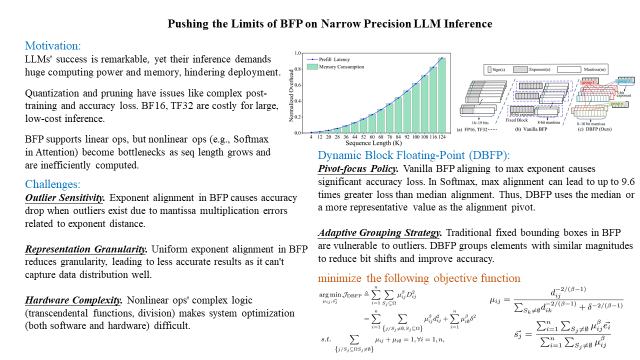
在本論文中,我們深入研究了BFP在非線性運算中的局限性和潛力。基于研究結果,我們提出了一種軟硬件協同設計框架(DB-Attn),其中包括:
DBFP:一種先進的 BFP 變體,采用樞軸聚焦策略(pivot-focus strategy)以適應不同數據分布,并采用自適應分組策略(adaptive grouping strategy)以實現靈活的指數共享,從而克服非線性運算的挑戰。
DH-LUT:一種創新的查找表(LUT)算法,專門用于基于 DBFP 格式加速非線性運算。
基于DBFP的硬件引擎:我們實現了一個RTL級的DBFP 計算引擎,支持FPGA和ASIC部署。
實驗結果表明,DB-Attn在LLaMA的Softmax運算上實現了 74%的GPU加速,并在與SOTA設計相比,計算開銷降低10 倍,同時保持了可忽略的精度損失。
02【ICLR-2025】OSTQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting
?論文鏈接:https://arxiv.org/abs/2501.13987
后訓練量化(Post-Training Quantization, PTQ)已成為廣泛采用的技術,用于壓縮和加速大語言模型(LLMs)。LLM量化的主要挑戰在于,數據分布的不均衡性和重尾特性會擴大量化范圍,從而減少大多數值的比特精度。近年來,一些方法嘗試通過線性變換來消異常值并平衡通道間差異,但這些方法仍然具有啟發性,往往忽略了對整個量化空間內數據分布的優化。

在本文中,我們引入了一種新的量化評估指標——量化空間利用率(QSUR, Quantization Space Utilization Rate),該指標通過衡量數據在量化空間中的利用情況,有效評估數據的量化能力。同時,我們通過數學推導分析了各種變換的影響及其局限性,為優化量化方法提供了理論指導,并提出了基于正交和縮放變換的量化方法(OSTQuant)。
OSTQuant 采用 可學習的等效變換,包括正交變換和縮放變換,以優化權重和激活值在整個量化空間中的分布。此外,我們提出了KL-Top損失函數,該方法在優化過程中減少噪聲,同時在 PTQ 限制的校準數據下保留更多語義信息。
實驗結果表明,OSTQuant在各種 LLM 和基準測試上均優于現有方法。在W4-only 量化設置下,它保留了99.5%的浮點精度。在更具挑戰性的W4A4KV4量化配置中,OSTQuant在 LLaMA-3-8B 模型上的性能差距相比SOTA方法減少了32%。
03【ICLR-2025】MambaQuant:Quantizing the Mamba Family with Variance Aligned Rotation Methods
?論文鏈接:https://arxiv.org/abs/2501.13484
Mamba是一種高效的序列模型,其性能可與Transformer相媲美,并在各種任務中展現出作為基礎架構的巨大潛力。量化(Quantization)通常用于神經網絡,以減少模型大小并降低計算延遲。然而,對于Mamba進行量化的研究仍然較少,而現有的量化方法——盡管在CNN和Transformer模型上表現良好——在Mamba模型上的效果卻不理想(例如,即使在W8A8 設置下,Quarot 在Vim-T?上的準確率仍下降了 21%)。
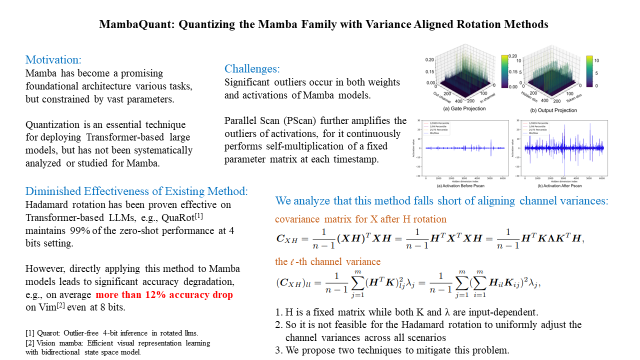
我們率先對這一問題進行了深入研究,并識別出了幾個關鍵挑戰。首先,在門控投影(gate projections)、輸出投影(output projections)和矩陣乘法(matrix multiplications)中存在顯著的異常值(outliers)。其次,Mamba 獨特的并行掃描(Parallel Scan, PScan)進一步放大了這些異常值,導致數據分布不均衡且具有重尾特性(heavy-tailed distributions)。第三,即便應用 Hadamard 變換,不同通道中的權重和激活值的方差仍然不一致。
為了解決這些問題,我們提出了MambaQuant,一個后訓練量化(PTQ)框架,其中包括:
KLT 增強旋轉(Karhunen-Loeve Transformation, KLT-Enhanced Rotation):將 Hadamard 變換與 KLT 結合,使得旋轉矩陣能夠適應不同通道分布。
平滑融合旋轉(Smooth-Fused Rotation):均衡通道方差,并可將額外參數合并到模型權重中。
實驗表明,MambaQuant 能夠在Mamba視覺和語言任務中將權重和激活量化至8-bit,且準確率損失低于1%。據我們所知,MambaQuant是首個專門針對 Mamba家族的全面PTQ方案,為其未來的應用和優化奠定了基礎。
04【DAC-2025】BBAL: A Bidirectional Block Floating Point-Based Quantisation Accelerator for Large Language Models
大語言模型(LLMs)由于其包含數十億參數,在部署于邊緣設備時面臨內存容量和計算資源的巨大挑戰。塊浮點(BFP)量化通過將高開銷的浮點運算轉換為低比特的定點運算,從而減少內存和計算開銷。然而,BFP需要將所有數據對齊到最大指數(max exponent),這會導致小值和中等值的丟失,從而引入量化誤差,導致LLMs 的精度下降。
為了解決這一問題,我們提出了一種雙向塊浮點(BBFP, Bidirectional Block Floating-Point)數據格式,該格式降低了選擇最大指數作為共享指數的概率,從而減少量化誤差。利用 BBFP 的特性,我們進一步提出了一種基于雙向塊浮點的量化加速器(BBAL),它主要包括一個基于BBFP 的處理單元(PE)陣列,并配備我們提出的高效非線性計算單元。

實驗結果表明,與基于異常值感知(outlier-aware)的加速器相比,BBAL在相似計算效率下,精度提升22%;同時,與傳統BFP量化加速器相比,BBAL在相似精度下計算效率提升 40%。
05【DAC-2025】NVR: Vector Runahead on NPUs for Sparse Memory Access
深度神經網絡(DNNs)越來越多地利用稀疏性來減少模型參數規模的擴展。然而,通過稀疏性和剪枝來減少實際運行時間仍然面臨挑戰,因為不規則的內存訪問模式會導致頻繁的緩存未命中(cache misses)。在本文中,我們提出了一種專門針對NPU(神經處理單元)設計的預取機制——NPU向量超前執行(NVR, NPU Vector Runahead),用于解決稀疏DNN任務中的緩存未命中問題。與那些通過高開銷優化內存訪問模式但可移植性較差的方法不同,NVR 采用超前執行(runahead execution),并針對NPU 架構的特點進行適配。

NVR 提供了一種通用的微架構級解決方案,能夠無需編譯器或算法支持地優化稀疏DNN任務。它以分離、推測性(speculative)、輕量級的硬件子線程的形式運行,并行于 NPU,且額外的硬件開銷低于5%。
實驗結果表明,NVR 將L2緩存未命中率降低了90%(相比最先進的通用處理器預取機制),并在稀疏任務上使NPU計算速度提升4倍(與無預取 NPU 相比)。此外,我們還研究了在NPU 中結合小型緩存(16KB)與NVR預取的優勢。我們的評估表明,增加這一小型緩存的性能提升效果比等量擴展L2緩存高5倍。
這5篇論文聚焦于大語言模型的優化、量化和硬件加速等關鍵技術,從算法創新到硬件適配,系統性地展現了后摩智能在AI軟硬件協同領域的深厚積累。研究成果從計算效率、能效優化和部署靈活性等多個維度,突破了大模型高效部署的技術瓶頸,為邊緣計算場景下的大模型壓縮與加速提供了創新性解決方案。期待這些工作能夠為大模型在端邊側的高效部署提供新范式,推動通用智能向更普惠、更可持續的方向演進。
接下來,我們將對5篇論文展開深度解析,詳細探討每篇論文的技術細節、創新點等,敬請關注。
-
芯片
+關注
關注
463文章
54183瀏覽量
467838 -
計算機
+關注
關注
19文章
7823瀏覽量
93342 -
AI
+關注
關注
91文章
40474瀏覽量
302077 -
后摩智能
+關注
關注
0文章
53瀏覽量
1729
原文標題:后摩前沿 | AAAI+ICLR+DAC,后摩智能5篇論文入選國際頂會
文章出處:【微信號:后摩智能,微信公眾號:后摩智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
地平線11篇論文強勢入選CVPR 2026

西井科技攜手同濟大學 三篇AI研究成果入選頂會ICLR 2026

MediaTek多篇論文入選全球前沿國際學術會議
后摩智能六篇論文入選四大國際頂會

理想汽車12篇論文入選全球五大AI頂會




 工商網監
工商網監
評論