") 大規(guī)模專家并行模型在TensorRT-LLM的設計
大規(guī)模專家并行模型在TensorRT-LLM的設計

DeepSeek-V3 / R1 等模型采用大規(guī)模細粒度混合專家模型 (MoE) 架構,大幅提升了開源模型的質量。Llama 4 和 Qwen3 等新發(fā)布的開源模型的設計原則也采用了類似的大規(guī)模細粒度 MoE 架構。但大規(guī)模 MoE 模型為推理系統(tǒng)帶來了新的挑戰(zhàn),如高顯存需求和專家間負載失衡等。
之前,我們介紹過突破 DeepSeek R1 模型低延遲極限的 TensorRT-LLM 優(yōu)化措施,多 Token 預測 (MTP) 的實現(xiàn)與優(yōu)化以及提高 DeepSeek R1 吞吐量性能的優(yōu)化措施。
DeepSeek 團隊還分享了優(yōu)化此類大規(guī)模專家并行 (EP) 模型 (如 DeepEP 和 EPLB) 的寶貴經驗與實踐。此外,DeepSeek 團隊在這份[1]技術報告中詳細闡述了具體設計考慮因素。除此之外,社區(qū)中也有在其他推理引擎中實現(xiàn)大規(guī)模 EP 的優(yōu)秀實踐,例如 SGLang 團隊的這個項目[2]。
這篇技術博客共分為上中下三篇,將介紹支持 TensorRT-LLM 中端到端大規(guī)模 EP 的詳細設計與實現(xiàn),主要包含以下內容:
如何使用 NVIDIA 多節(jié)點 NVLink (MNNVL) 硬件特性來實現(xiàn)高性能通信內核。
如何設計和實現(xiàn)在線專家負載均衡器,以動態(tài)平衡專家負載分布并適應在線流量模式的變化。我們將展示:
證明此類優(yōu)化措施必要性的經驗數(shù)據分析。
在線流量數(shù)據統(tǒng)計模塊的實現(xiàn)。
復制和放置策略的設計與實現(xiàn)。
用于平衡多個 GPU 間在線工作負載的 MoE 權重負載和重新分配器。
為適應專家負載均衡器需求而對 MoE 路由器和計算模塊進行的必要修改。
一些證明當前 TensorRT-LLM 中實現(xiàn)效果的初步數(shù)據。
未來的技術博客還將涵蓋以下主題:
對 TensorRT-LLM 大規(guī)模 EP 實現(xiàn)的性能調優(yōu)和優(yōu)化的介紹。
如何在不使用 MNNVL 的情況下,為 Hopper 和其他 NVIDIA GPU 實現(xiàn)高效的大規(guī)模 EP 支持。
使用大規(guī)模 EP 并獲得性能提升的最佳實踐。
如何將大規(guī)模 EP 與其他系統(tǒng)優(yōu)化技術相結合。
雖然本技術博客主要討論 TensorRT-LLM,但我們相信其核心理念和實現(xiàn)方法也可用于其他推理引擎在 NVIDIA GPU 上的推理性能。此外,我們希望借助社區(qū)的力量,探索如何更好地將當前 TensorRT-LLM 大規(guī)模 EP 實現(xiàn)模塊化,使其更容易被社區(qū)復用。
最后,本博客包含針對 Grace Blackwell 機架式系統(tǒng)的詳細實現(xiàn)方式,例如使用 Grace Blackwell 機架式系統(tǒng)跨 GPU 連接的通信組件,以及使用 Grace CPU 與 Blackwell GPU 間高帶寬 C2C 連接的 MoE 權重加載和重新分配模塊等。但整體設計原則和軟件架構仍適用于非此 NVIDIA GPU 系統(tǒng)。為了便于擴展到其他非此系統(tǒng),我們有意識地關注了設計和實現(xiàn)的通用性。這些更改應能與現(xiàn)有其他組件輕松組合。
引入大規(guī)模 EP 的初衷
引入大規(guī)模 EP(本文中指 EP > 8)主要基于以下系統(tǒng)考量:
我們希望通過提高聚合顯存帶寬來加載專家權重,從而降低執(zhí)行延遲。
我們希望通過增加有效批處理大小充分利用 GPU 算力。
需注意,當端到端 (E2E) 執(zhí)行時間主要由 MoE GroupGEMM 計算主導時,引入大規(guī)模 EP 可顯著提升性能。但若端到端執(zhí)行時間未被 MoE GroupGEMM 計算主導,引入大規(guī)模 EP 提升的性能有限。
系統(tǒng)設計中不存在“免費的午餐”。當 EP 規(guī)模增大到超過 8(有時甚至不到 8)時,由于 MoE 模型的稀疏執(zhí)行特性,會自動觸發(fā) EP 級別的負載失衡問題。
以下是一些基于特定數(shù)據集的經驗觀察(所有分析均使用DeepSeek R1 模型在32 個 GPU上進行):
對一個機器翻譯數(shù)據集的觀察結果
首先,我們將概述各層的整體失衡問題:
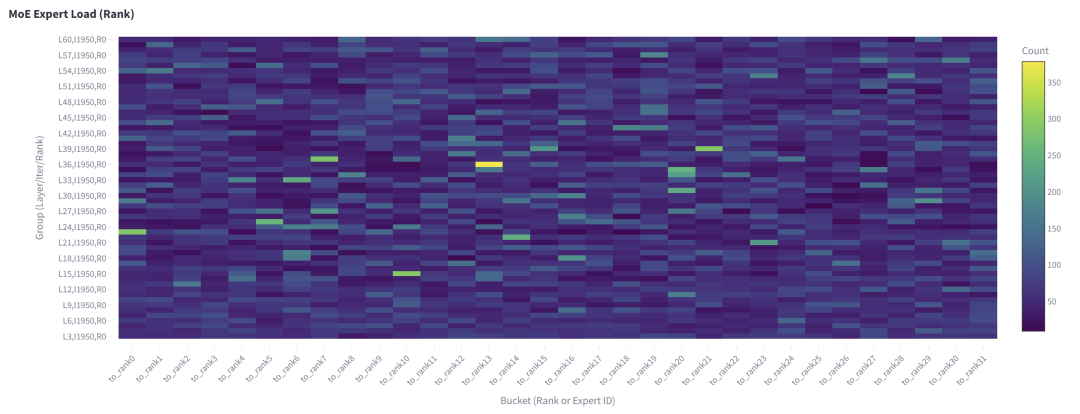
圖 1. 從 rank 0 發(fā)送到所有 rank(包括 rank 0)的 Token 數(shù)(對應解碼迭代 1950)及所有 MoE 層
如圖 1 所示,在第 36 層的 MoE 中,從rank 0 發(fā)送到 rank 13的 Token 數(shù)明顯更多。
如果我們放大第 36 層的 MoE 并記錄其激活專家 rank 的分布,可以清楚地看到有一個 rank 被更頻繁地激活:
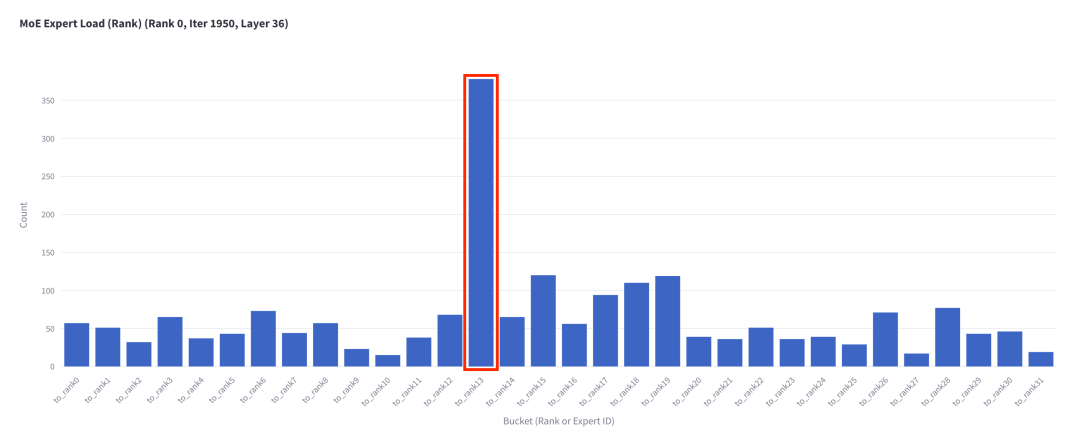
圖 2. 第 36 層每個專家 rank 接收的 Token 數(shù)量
如果我們將數(shù)據展平以查看每個專家接收的 Token 數(shù)量,可以發(fā)現(xiàn)有一些專家比其他專家更活躍:
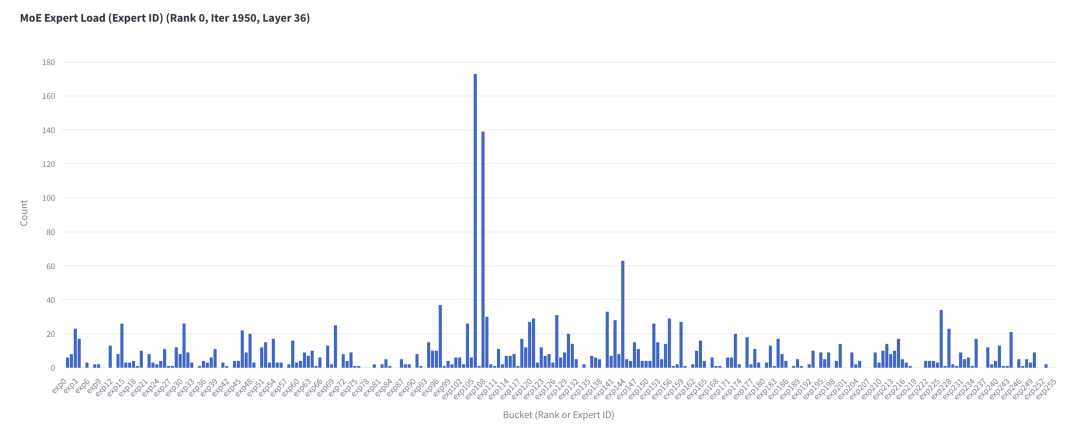
圖 3. 第 36 層每個專家接收的 Token 數(shù)量
值得注意的是,這種失衡問題在多次迭代中非常穩(wěn)定,如下圖所示:
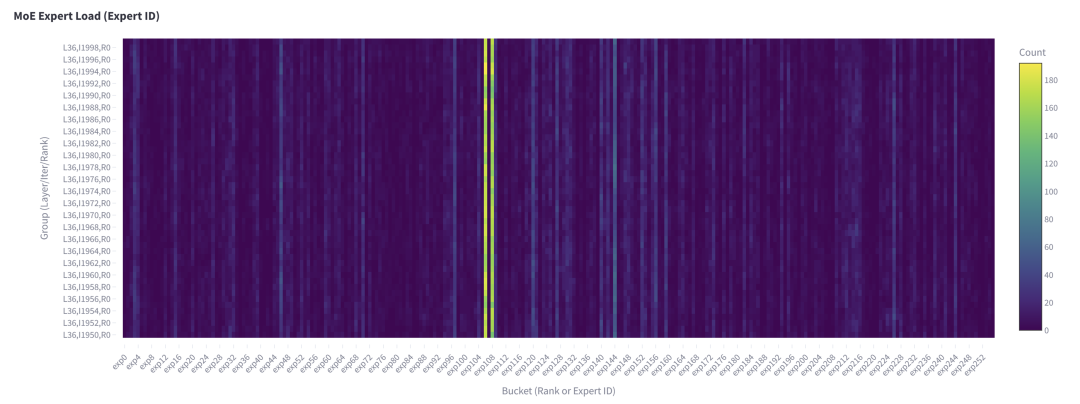
圖 4. 第 36 層每個專家在 50 個解碼步驟內接收的 Token 總數(shù),本地 batch size=256。
顯然,圖 4 中的熱門專家與圖 3 中僅包含單次解碼迭代數(shù)據的專家相同。我們還對本地 batch size=1(對應單次請求)進行了基于持續(xù)時間的分析,觀察到類似的模式:
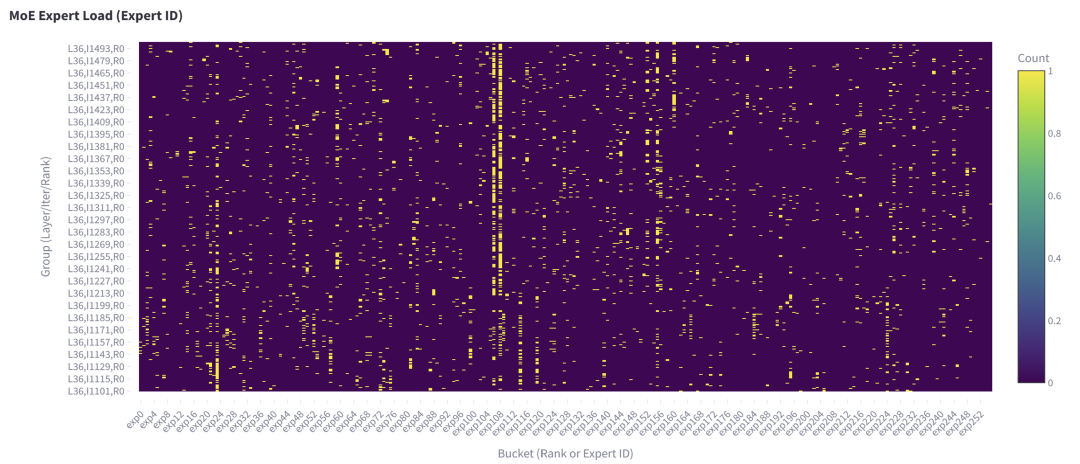
圖 5. 第 36 層每個專家在 400 次解碼迭代內接收的 Token 總數(shù),本地 batch size=1。
綜上所述,針對該機器翻譯數(shù)據集的研究結果可總結為:
某些層中存在一些熱點,部分 EP 所在 GPU 的負載可能遠高于其他 EP。
其原因可能是最熱門專家或多個熱門專家位于同一 rank。
路由 Token 的分布可能在數(shù)十至數(shù)百個迭代步驟甚至更多迭代步驟內保持一致。
在單個請求的執(zhí)行中,不同迭代步之間也存在相同的熱門專家。
另一個實際問題是上述觀察結果在其他數(shù)據集上是否會發(fā)生顯著變化。因此,我們對 GSM8K 數(shù)據集進行了類似的分析。
對 GSM8K 數(shù)據集的觀察結果
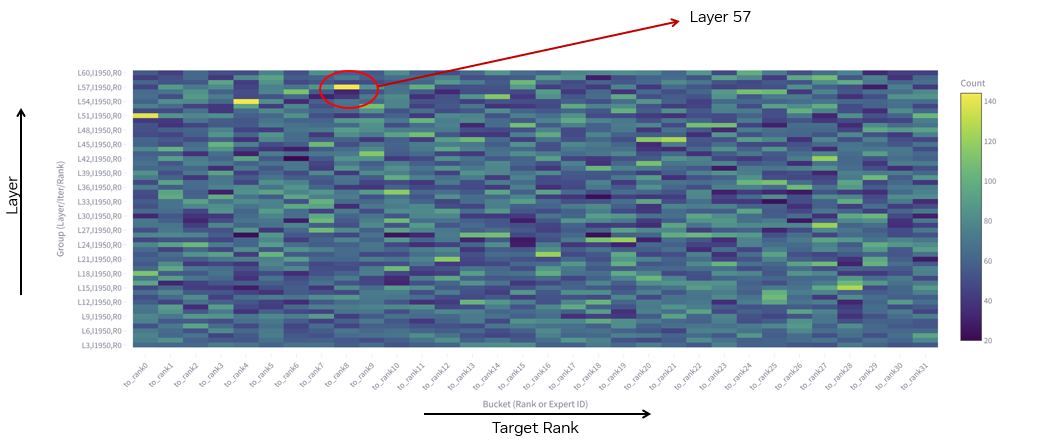
圖 6. 從 rank 0 發(fā)送到所有 rank 的 Token 數(shù)(對應第 1950 個迭代步)及所有 MoE 層
如圖 6 所示,與圖 1 相比,GSM8K 數(shù)據集中的熱門層變成了第 57 層而非第 36 層。那么 GSM8K 數(shù)據集中第 36 層的具體情況如何?
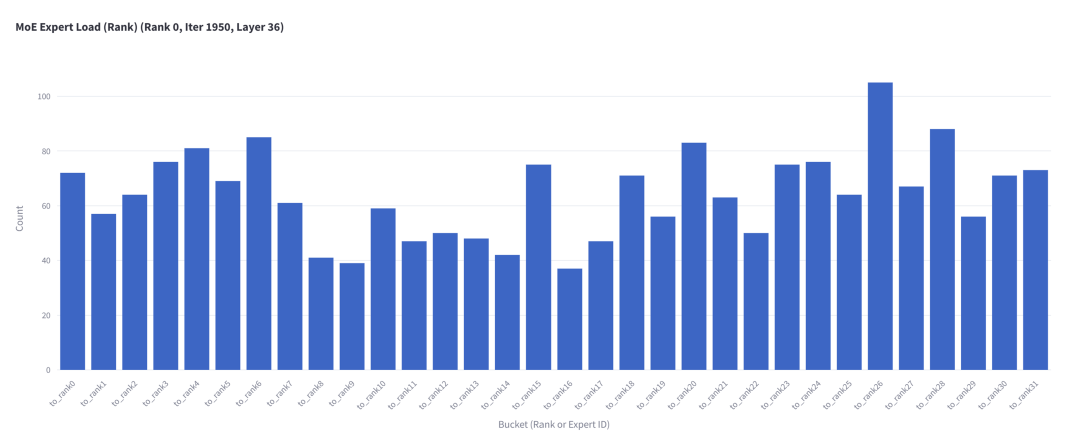
圖 7. 從 EP rank 0 發(fā)送到其他 EP rank 的 Token 數(shù)(仍以迭代 1950、MoE 第 36 層為例)
從圖 7 可以清楚地看到,工作負載失衡于不同數(shù)據集(圖 2 所示)中觀察到的情況不同。在圖 8 中可以觀察到在 GSM8K 數(shù)據集上,工作負載的失衡在多次迭代中也相對穩(wěn)定。這與之前的機器翻譯數(shù)據集相同。
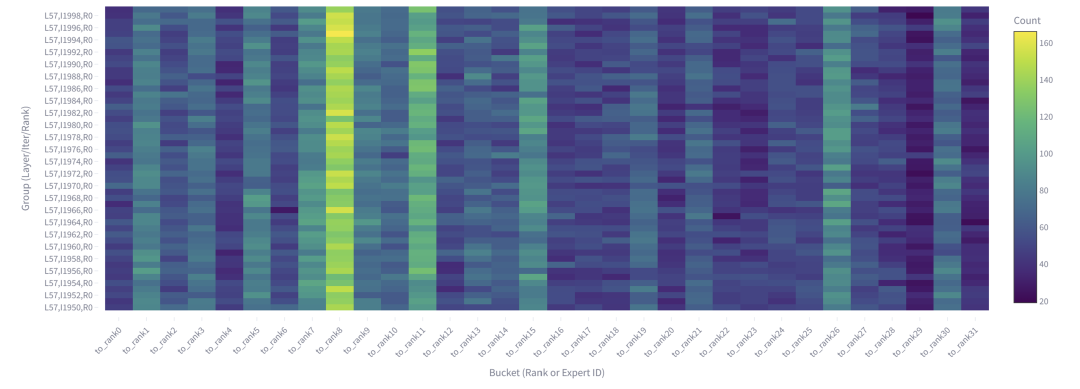
圖 8. 從 EP rank 0 發(fā)送到所有 rank 的 Token 總數(shù)(MoE 第 57 層,50 個解碼步驟內,本地 batch size=256)
如果我們將每個 GPU EP 層面的數(shù)據展平為專家層面,可以得到下圖。
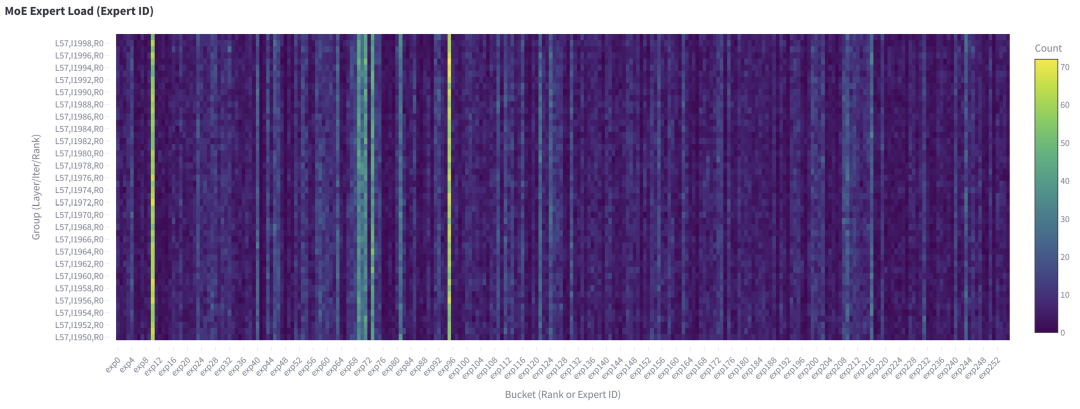
圖 9. 第 57 層的每個專家在 50 個解碼步驟內接收的 Token 總數(shù),本地 batch size=256
單個請求中也存在類似的失衡模式。
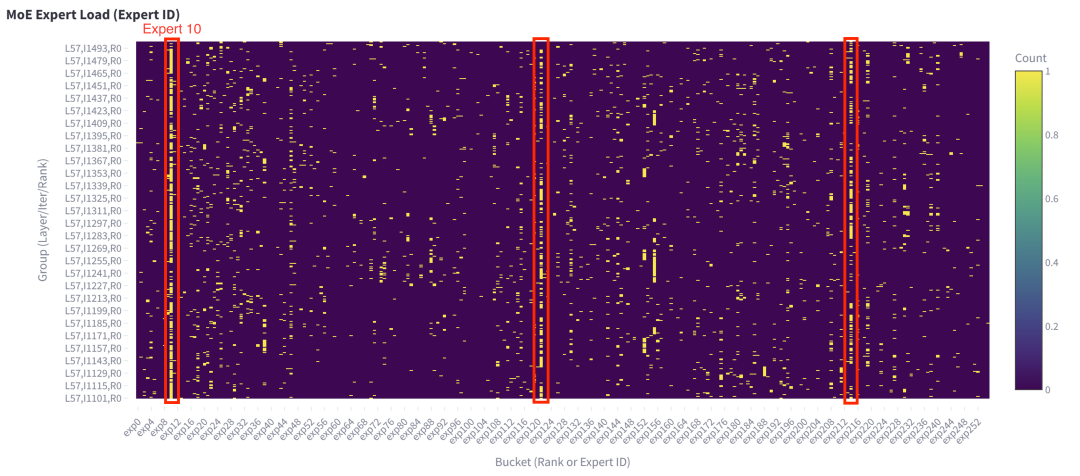
圖 10. 單次請求下第 57 層的每個專家在 400 個解碼步驟內接收的 Token 總數(shù)
如果使用另一個請求,我們仍然可以觀察到專家失衡問題。雖然熱門專家可能不同,但有一些是共同的(在此示例中是專家 10)。
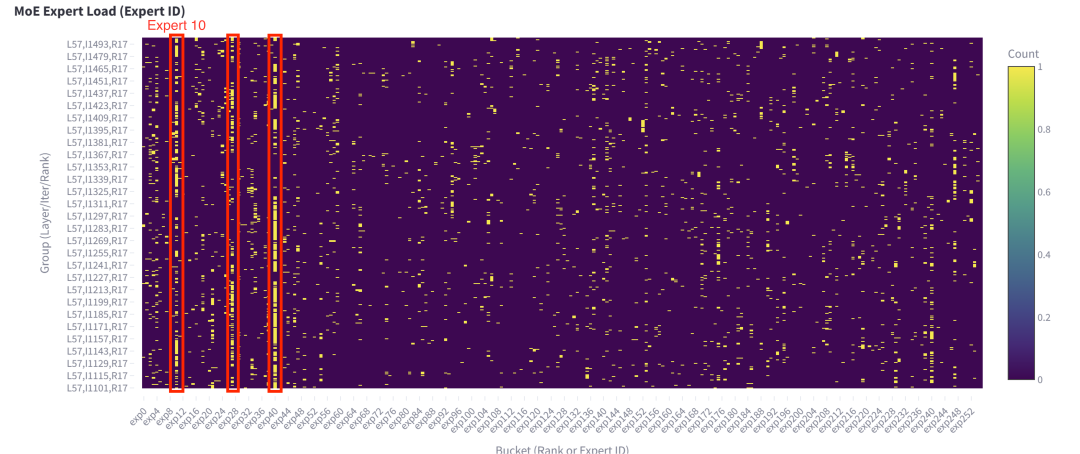
圖 11. 單次請求下第 57 層每個專家在 400 個解碼步驟內接收的 Token 總數(shù)
通過對兩個數(shù)據集的數(shù)據分析,我們得出以下結論:
EP 級別工作負載失衡問題在多個數(shù)據集的大規(guī)模 EP 推理中較為常見。且 EP 失衡的嚴重程度可能因層而異。此外,EP 失衡的問題具有數(shù)據集敏感性。
EP rank 級別失衡問題可能由某個最熱門的專家或多個熱門專家長期占據同一 EP rank 引起。
EP rank 失衡分布在數(shù)十到數(shù)百次迭代中相對穩(wěn)定。
盡管 EP rank 失衡分布在時間維度上具有穩(wěn)定性,但不同請求的 EP 失衡分布可能有所不同。
這些發(fā)現(xiàn)可指導我們對 TensorRT-LLM 大規(guī)模 EP 實現(xiàn)的設計考量:
設計時需考慮 EP 失衡問題以確保端到端的性能。
基于實時在線請求流量的在線 EP 負載均衡器(而非僅實現(xiàn)離線 EP 負載均衡器)對確保 EP 均衡器的穩(wěn)健性至關重要。
可運用 EP rank 失衡分布的時間維度穩(wěn)定性,以高效的方式將 MoE 權重重新分配至不同 EP rank。
在下一篇文章中,我們將深入探討 TensorRT-LLM 大規(guī)模 EP 的整體實現(xiàn)架構、負載均衡策略與性能優(yōu)化實踐。
引用
[1]DeepSeek-V3 技術報告:
https://arxiv.org/abs/2412.19437
[2]SGLang團隊項目:
https://lmsys.org/blog/2025-05-05-large-scale-ep/
作者
楊東旭
現(xiàn)任職于 NVIDIA Compute Arch 部門。主要負責 LLM 推理系統(tǒng)的開發(fā)和性能優(yōu)化。加入 NVIDIA 之前,曾從事搜索系統(tǒng)的 GPU 加速和開發(fā)工作。
喬顯杰
NVIDIA Compute Arch 部門高級架構師,主要負責 LLM 推理的性能評估和優(yōu)化。加入 NVIDIA 之前,他曾從事推薦系統(tǒng)的 GPU 加速研發(fā)工作。
謝開宇
NVIDIA Compute Arch 部門高級架構師,主要負責 TensorRT-LLM 項目的開發(fā),專注在系統(tǒng)性能和優(yōu)化工作。
朱恩偉
NVIDIA DevTech 部門高級工程師,主要負責 TensorRT-LLM 項目的開發(fā)和性能優(yōu)化。
陳曉明
NVIDIA Compute Arch 部門的首席架構師和高級經理,對深度學習模型的算法軟硬件協(xié)同設計感興趣,最近從事大語言模型推理的性能建模、分析和優(yōu)化。
-
gpu
+關注
關注
28文章
5235瀏覽量
135901 -
模型
+關注
關注
1文章
3789瀏覽量
52208 -
DeepSeek
+關注
關注
2文章
837瀏覽量
3351
原文標題:大規(guī)模專家并行 (EP) 在 TensorRT-LLM 的設計動機與系統(tǒng)分析
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
DeepSeek R1 MTP在TensorRT-LLM中的實現(xiàn)與優(yōu)化

TensorRT-LLM初探(一)運行l(wèi)lama
使用NVIDIA Triton和TensorRT-LLM部署TTS應用的最佳實踐

如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
TensorRT-LLM中的分離式服務

現(xiàn)已公開發(fā)布!歡迎使用 NVIDIA TensorRT-LLM 優(yōu)化大語言模型推理

點亮未來:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驅動的 Windows PC 上運行新模型
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理優(yōu)化

NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

解鎖NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

TensorRT-LLM的大規(guī)模專家并行架構設計




 工商網監(jiān)
工商網監(jiān)
評論