") 華為正式開源盤古7B稠密和72B混合專家模型
華為正式開源盤古7B稠密和72B混合專家模型

[中國,深圳,2025年6月30日] 今日,華為正式宣布開源盤古70億參數(shù)的稠密模型、盤古Pro MoE 720億參數(shù)的混合專家模型和基于昇騰的模型推理技術。
此舉是華為踐行昇騰生態(tài)戰(zhàn)略的又一關鍵舉措,推動大模型技術的研究與創(chuàng)新發(fā)展,加速推進人工智能在千行百業(yè)的應用與價值創(chuàng)造。
盤古Pro MoE 72B模型權重、基礎推理代碼,已正式上線開源平臺。
基于昇騰的超大規(guī)模MoE模型推理代碼,已正式上線開源平臺。
盤古7B相關模型權重與推理代碼將于近期上線開源平臺。
我們誠邀全球開發(fā)者、企業(yè)伙伴及研究人員下載使用,反饋使用意見,共同完善。請訪問https://gitcode.com/ascend-tribe
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
華為
+關注
關注
218文章
36139瀏覽量
262548 -
人工智能
+關注
關注
1819文章
50231瀏覽量
266619 -
昇騰AI
+關注
關注
0文章
87瀏覽量
940 -
盤古大模型
+關注
關注
1文章
112瀏覽量
1059
原文標題:華為宣布開源盤古7B稠密和72B混合專家模型
文章出處:【微信號:huaweicorp,微信公眾號:華為】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
熱點推薦
大曉機器人開源實時生成世界模型Kairos 3.0-4B
近日,大曉機器人重磅開源開悟世界模型3.0(Kairos 3.0)-4B 系列具身原生世界模型。作為業(yè)內(nèi)首個實現(xiàn) “多模態(tài)理解 — 生成 — 預測” 一體化的

大模型推理服務的彈性部署與GPU調(diào)度方案
7B 模型 FP16 推理需要約 14GB 顯存,70B 模型需要 140GB+,KV Cache 隨并發(fā)數(shù)線性增長,顯存碎片化導致實際利用率不足 60%。
基于合眾恒躍rk3576?開發(fā)板deepseek-r1-1.5b/7b 部署指南
? 核心結(jié)論:部署流程分為?5?大核心步驟,依次為基礎環(huán)境安裝、模型下載、模型格式轉(zhuǎn)換、部署程序編譯、開發(fā)板運行測試,1.5b?模型適配?4+32G?開發(fā)板,

NVIDIA ACE現(xiàn)已支持開源Qwen3-8B小語言模型
為助力打造實時、動態(tài)的 NPC 游戲角色,NVIDIA ACE 現(xiàn)已支持開源 Qwen3-8B 小語言模型(SLM),可實現(xiàn) PC 游戲中的本地部署。
Arm率先適配騰訊混元開源模型,助力端側(cè)AI創(chuàng)新開發(fā)
本周初,騰訊混元宣布開源四款小尺寸模型(參數(shù)分別為 0.5B、1.8B、4B、7B),可無縫運行
如何本地部署NVIDIA Cosmos Reason-1-7B模型
近日,NVIDIA 開源其物理 AI 平臺 NVIDIA Cosmos 中的關鍵模型——NVIDIA Cosmos Reason-1-7B。這款先進的多模態(tài)大模型能夠理解視頻、進行物理
華為宣布開源盤古7B稠密和72B混合專家模型
關鍵一步,為全球開發(fā)者、企業(yè)及研究人員提供了強大的技術支撐。 ? 華為此次開源行動涵蓋三大核心板塊:盤古Pro MoE 72B模型權重與基礎
帶增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc
電子發(fā)燒友網(wǎng)為你提供()帶增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7
發(fā)表于 06-27 18:31

具有載波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和 B7) skyworksinc
電子發(fā)燒友網(wǎng)為你提供()具有載波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和
發(fā)表于 06-19 18:35
帶增益的 RX 分集 FEM(B3、B39、B1、B40、B41 和 B7) skyworksinc
電子發(fā)燒友網(wǎng)為你提供()帶增益的 RX 分集 FEM(B3、B39、B1、B40、B41 和 B7
發(fā)表于 06-19 18:30
在阿里云PAI上快速部署NVIDIA Cosmos Reason-1模型
NVIDIA 近期發(fā)布了 Cosmos Reason-1 的 7B 和 56B 兩款多模態(tài)大語言模型 (MLLM),它們經(jīng)過了“物理 AI 監(jiān)督微調(diào)”和“物理 AI 強化學習”兩個階段的訓練。其中
代碼革命的先鋒:aiXcoder-7B模型介紹
? ? 國內(nèi)開源代碼大模型 4月9日aiXcoder宣布正式開源其7B模型Base版,僅僅過去一個禮拜,aiXcoder-

NVIDIA RTX 5880 Ada與Qwen3系列模型實測報告
近日,阿里巴巴通義千問團隊正式推出新一代開源大語言模型——Qwen3 系列,該系列包含 6 款 Dense 稠密模型和 2 款 MoE 混合
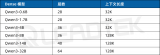
NVIDIA使用Qwen3系列模型的最佳實踐
阿里巴巴近期發(fā)布了其開源的混合推理大語言模型 (LLM) 通義千問 Qwen3,此次 Qwen3 開源模型系列包含兩款

【幸狐Omni3576邊緣計算套件試用體驗】CPU部署DeekSeek-R1模型(1B和7B)
架構和動態(tài)計算分配技術,在保持模型性能的同時顯著降低了計算資源需求。
模型特點:
參數(shù)規(guī)模靈活:提供1.5B/7B/33B等多種規(guī)格
發(fā)表于 04-21 00:39



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論