 神經網絡是如何學習預測的?
神經網絡是如何學習預測的?

作為一名程序員,我們習慣于去了解所使用工具、中間件的底層原理,本文則旨在幫助大家了解 AI 模型的底層機制,讓大家在學習或應用各種大模型時更加得心應手,更加適合沒有 AI 基礎的小伙伴們。
GPT 與神經網絡的關系
GPT 想必大家已經耳熟能詳,當我們與它進行對話時,通常只需關注自己問出的問題(輸入)以及 GPT 給出的答案(輸出),對于輸出內容是如何產生的,我們一無所知,它就像一個神秘的黑盒子。
GPT 是一種基于神經網絡的自然語言處理(NLP)模型,使用大量數據輸入神經網絡對模型進行訓練,直到模型的輸出在一定程度上符合我們的預期,訓練成熟的模型就可以接收用戶的輸入,并針對輸入中的關鍵信息給出經過 “思考” 后的答案。想要弄明白 GPT 究竟是如何 “思考” 的,或許我們可以從神經網絡出發。
什么是神經網絡
那么,神經網絡到底是什么呢?或者說,為什么是神經網絡?高中的生物學告訴我們,人類的神經系統由數以億計的神經元連接而成,它們是生物學上的細胞,有細胞體、樹突、軸突等主要結構,不同神經元之間的樹突與軸突通過突觸與其他神經元相互連接,形成復雜的人腦神經網絡。人工智能為了使機器獲得接近人類的智力,嘗試效仿人腦的思考過程,創造出了一種模仿人腦神經元之間相互連接的計算模型 —— 神經網絡。它由多層神經元組成,每個神經元接收輸入并產生相應的輸出。根據上述定義,圖 1 中黑盒子的內部結構已初具輪廓,下圖中的每個圓圈都代表一個神經元,神經元具有計算能力,可以將計算出來的結果傳遞到下一個神經元。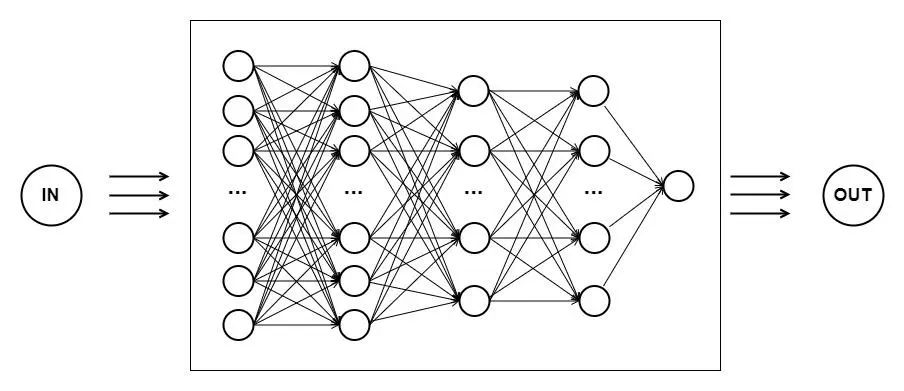
在生物學中,大腦的結構越簡單,智力也就越低;相應地,神經系統越復雜,能處理的問題越多,智力也就越高。人工神經網絡也是如此,越復雜的網絡結構計算能力越強大,這也是為什么發展出了深度神經網絡。之所以被稱為 "深度",是因為它具有多個隱藏層(即上圖中縱向神經元的層數),相對于傳統的淺層神經網絡,深度神經網絡具有更多的層級結構。訓練深度神經網絡的過程就叫做深度學習。構建好深度神經網絡之后,我們只需要將訓練數據輸入到神經網絡中,它就會自發地學習數據中的特征。比如說我們想要訓練一個深度神經網絡來識別貓,只需要將大量不同種類、不同姿勢、不同外觀的貓的圖片輸入到神經網絡中讓它學習。訓練成功后,我們將一張任意的圖片輸入到神經網絡中,它會告訴我們里面是否有貓。
神經網絡是如何計算的
現在,我們已經知道了什么是神經網絡以及它的基本結構,那么神經網絡中的神經元是如何對輸入數據進行計算的呢?
在此之前,我們要解決一個問題:數據是如何輸入到神經網絡中的?下面以圖像和文本類型的數據為例講解。
- 數據是如何輸入到神經網絡中的
1、圖像輸入處理
想象一個畫面:當我們把一張圖片放大到一定程度時,可以看到一格一格的小方塊。這個小方塊就稱為像素點,一張圖片的像素點越多,說明像素越高,圖片越清晰。每個像素點僅由一種顏色構成,光學中的三原色包含紅色、綠色、藍色,通過不同程度地混合這三種顏色可以產生出所有其他顏色。在 RGB 模型中,每種顏色的強度可以用一個數值來表示,通常在 0 到 255 之間。紅色的強度值為 0 表示沒有紅色光,255 表示最大強度的紅色光;綠色和藍色的強度值也是類似的。為了存儲一張圖像,計算機要存儲三個獨立的矩陣,這三個矩陣分別與圖像的紅色、綠色和藍色的強度相對應。如果圖像的大小是 256 * 256 個像素,那么在計算機中使用三個 256 * 256 的矩陣(二維數組)就能表示這張圖像。可以想象將三個矩陣表示的顏色重疊堆放在一起,便可顯現出圖像的原始樣貌。現在我們得到了圖像在計算機中的表示方式,那么如何將它輸入到神經網絡呢?通常我們會把上述三個矩陣轉化為一個向量,向量可以理解成 1 * n(行向量)或 n * 1(列向量)的數組。那么這個向量的總維數就是 256 * 256 * 3,結果是 196608。在人工智能領域中,每一個輸入到神經網絡的數據都被叫做一個特征,那么上面的這張圖像中就有 196608 個特征。這個 196608 維的向量也被叫做特征向量。神經網絡接收這個特征向量作為輸入,并進行預測,然后給出相應的結果。
2、文本輸入處理
文本是由一系列字符組成的,首先需要將文本劃分成有意義的單詞,這個過程稱為分詞。在分詞后,構建一個由出現的所有單詞或部分高頻單詞組成的詞匯表(也可以使用已有的詞匯表)。詞匯表中的每個單詞都會被分配一個唯一索引,這樣可以將文本轉換為離散的符號序列,方便神經網絡進行處理。在輸入神經網絡之前,通常會將文本的符號序列轉換為密集的向量表示。以文本 “How does neural network works?” 為例:
- 分詞:["how", "does", "neural", "network", "works"]
- 構建詞匯表:{"how": 0, "does": 1, "neural": 2, "network": 3, "works": 4}
- 序列化文本數據:["how", "does", "neural", "network", "works"] -->[0, 1, 2, 3, 4]
向量化:
#此處以one-hot向量表示法為例:
[[1,0,0,0,0]
[0,1,0,0,0]
[0,0,1,0,0]
[0,0,0,1,0]
[0,0,0,0,1]]
最后,將向量序列作為輸入,給神經網絡進行訓練或預測。
至此我們已經知道了數據以怎樣的形式輸入到神經網絡中,那么神經網絡是如何根據這些數據進行訓練的呢?
- 神經網絡是如何進行預測的
首先明確模型訓練和預測的區別:訓練是指通過使用已知的數據集來調整模型的參數,使其能夠學習到輸入和輸出之間的關系;預測是指使用訓練好的模型來對新的輸入數據進行預測。
神經網絡的預測其實是基于一個很簡單的線性變換公式:
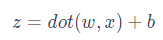
其中,x?表示特征向量,w?是特征向量的權重,表示每個輸入特征的重要程度,b?表示閾值,用于影響預測結果。公式中的 dot () 函數表示將 w?和 x?進行向量相乘。舉例:如果一個輸入數據有 i?個特征,代入公式計算結果為: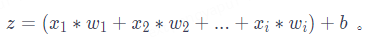
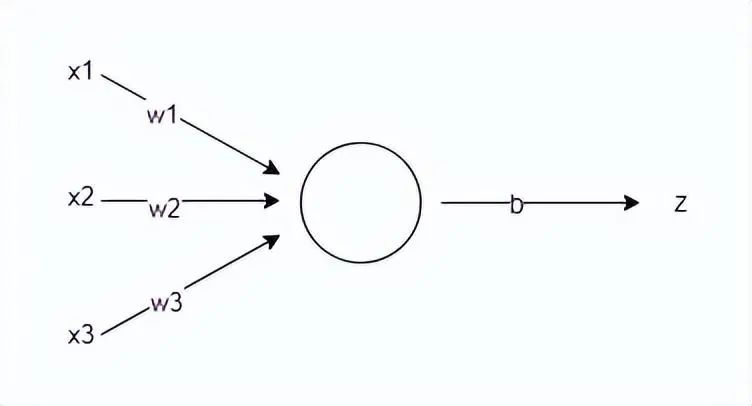
如何理解這個公式呢?假設你需要決策周末是否去公園劃船,你對此猶豫不決,需要神經網絡幫你做決定。決定是否去劃船有三個因素:天氣是否晴朗溫暖、地點是否遠近適中、同行玩伴是否合心意。實際情況是出行那天天氣為陰且偶有陣風、地點在 20km 外的偏遠郊區、同行玩伴是心儀已久的大帥哥。這三個因素即為輸入數據的特征向量 x=[x1, x2, x3],我們需要根據特征對結果的影響來設置特征值,如 “天氣不好” 和 “地點偏遠” 對結果具有負向的影響,我們可以把它設為 - 1,“同行玩伴是心儀已久的大帥哥” 顯然對結果有大大的正向影響,可以把它設為 1,即特征向量 x=[-1, -1, 1]。接下來,需要根據你的偏好來設置三個特征的權重,也就是每個因素對你最終決策的影響程度。如果你不在乎天氣和地點,只要與大帥哥同行便風雨無阻,那么可以將權重設置為 w=[1, 1, 5];如果你是個懶狗,那你可能會設置權重為 w=[2, 6, 3];總之,權重是根據對應特征的重要程度來確定的。我們選擇第一組權重 w=[1, 1, 5],特征向量為 x=[-1, -1, 1], 并設置閾值 b=1,假設結果 z ≥ 0 表示去,z < 0 表示不去,計算預測結果 z = (x1w1 + x2w2 + x3*w3) + b = 4 > 0,因此神經網絡給出的預測結果是:去公園劃船。
上面使用的公式
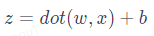
本質上是一種邏輯回歸,用于將輸入數據映射到二分類的概率輸出。邏輯回歸通常使用一個特定的激活函數來實現將 z?值到 [0, 1] 的映射關系,即 Sigmoid 函數,它將線性變換的結果通過非線性映射轉化為概率值。通常,大于等于 0.5 的概率值被視為正類,小于 0.5 的概率值被視為負類。Sigmoid 函數的公式和圖像如下所示: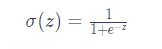
除了能將結果輸出范圍控制在 0 到 1 之間,Sigmoid 函數(或其他激活函數)另外一個重要作用就是將線性變換的結果進行非線性映射,使神經網絡可以學習和表示更加復雜的非線性關系。如果沒有激活函數,神經網絡只能解決簡單的線性問題;加入激活函數之后,只要層數足夠多,神經網絡就能解決所有問題,因此激活函數是必不可少的。
- 神經網絡是如何進行學習的
得到預測結果后,神經網絡會通過損失函數判斷預測結果是否準確,如果不夠準確,神經網絡會進行自我調整,這就是學習的過程。
損失函數用于衡量模型的預測結果與真實標簽之間的誤差。通過將預測值與真實值進行比較,損失函數提供了一個數值指標,反映了模型當前的預測性能。較小的損失值表示模型的預測結果與真實標簽更接近,而較大的損失值表示預測誤差較大。下面介紹一個常用于二分類問題的損失函數(對數損失):
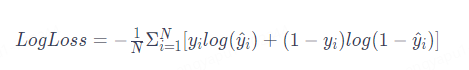

神經網絡學習的目的,就是通過調整模型的參數使損失函數達到最小值,從而改善模型的預測性能,這個過程也稱為模型的訓練。梯度下降算法可以解決這一問題,通過該算法找到合適的 w?(特征的權重)和 b(閾值),梯度下降算法會一步一步地改變 w 和 b?的值,使損失函數的結果越來越小,也就是使預測結果更精準。

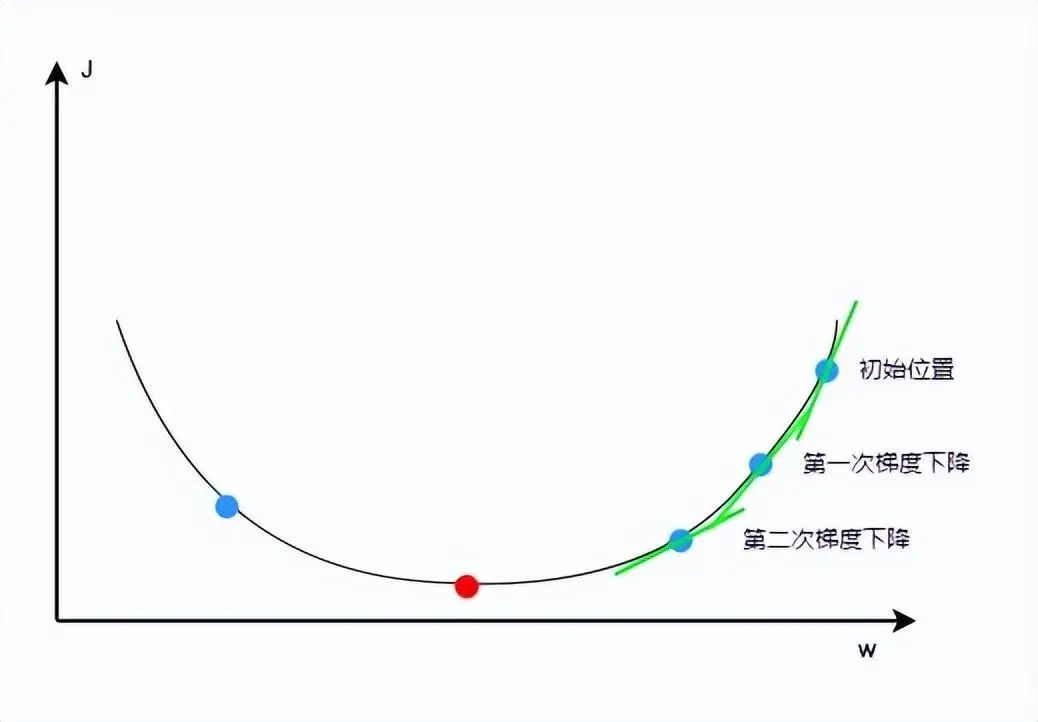 這里需要注意的是,如果學習率設置過小,則需要多次梯度下降才能到達最低點,浪費機器運行資源;如果設置過大,則可能錯過最低點直接到了圖中左側的點位,因此需要根據實際情況選擇一個正確的學習率。
這里需要注意的是,如果學習率設置過小,則需要多次梯度下降才能到達最低點,浪費機器運行資源;如果設置過大,則可能錯過最低點直接到了圖中左側的點位,因此需要根據實際情況選擇一個正確的學習率。
神經網絡的計算過程主要有兩個步驟:正向傳播和反向傳播。正向傳播用于計算神經元的輸出,也就是上述對輸入特征進行加權求和、并通過激活函數進行非線性變換的過程;反向傳播用于更新優化模型參數,通過計算損失函數關于模型參數的梯度,從輸出層向輸入層反向傳播梯度的過程(反向傳播涉及大量的數學計算,感興趣的讀者可以深入了解)。
小結
綜上所述,神經網絡訓練和學習的過程其實就是對模型參數進行不斷調優、減少預測損失值過程。經過充分訓練后,模型能夠從輸入數據中學習到有效的特征表示和權重分配,從而能夠對未見過的數據進行準確的預測。訓練完成的神經網絡模型可以應用于各種實際問題。比如,在圖像分類任務中,卷積神經網絡可以根據輸入圖像的特征自動識別物體或圖案;在自然語言處理任務中,循環神經網絡可以理解和生成文本;在推薦系統中,多層感知機神經網絡可以根據用戶的歷史行為進行個性化推薦。
這篇文章對神經網絡的工作機制做了淺層次的講解,如有不正之處,敬請指教!
作者:京東云開發者-京東零售 歐陽舟俞
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107767 -
AI
+關注
關注
91文章
39793瀏覽量
301403 -
GPT
+關注
關注
0文章
368瀏覽量
16871
發布評論請先 登錄
自動駕駛中常提的卷積神經網絡是個啥?

CNN卷積神經網絡設計原理及在MCU200T上仿真測試
NMSIS神經網絡庫使用介紹
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作
液態神經網絡(LNN):時間連續性與動態適應性的神經網絡

神經網絡的并行計算與加速技術
如何在機器視覺中部署深度學習神經網絡

無刷電機小波神經網絡轉子位置檢測方法的研究
神經網絡專家系統在電機故障診斷中的應用
神經網絡RAS在異步電機轉速估計中的仿真研究
基于FPGA搭建神經網絡的步驟解析




 工商網監
工商網監
評論