 MoDem解決了視覺強化學習領域的三個挑戰
MoDem解決了視覺強化學習領域的三個挑戰

【導讀】MetaAI這次發布的MoDem解決了視覺強化學習領域的三個挑戰,無需解碼器,效率最高提升250%,一起看看它有多牛。
12月27日,MetaAI 負責視覺和強化學習領域的A
截止27日晚間,這篇推文的閱讀量已經達到73.9k。
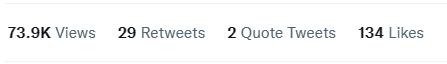
他表示,僅給出5個演示,MoDem就能在100K交互步驟中解決具有稀疏獎勵和高維動作空間的具有挑戰性的視覺運動控制任務,大大優于現有的最先進方法。
有多優秀呢?
他們發現MoDem在完成稀疏獎勵任務方面的成功率比低數據機制中的先前方法高出150%-250%。

Lecun也轉發了這一研究,表示MoDem的模型架構類似于JEPA,可在表征空間做出預測且無需解碼器。
鏈接小編就放在下面啦,有興趣的小伙伴可以看看~

論文鏈接:https://arxiv.org/abs/2212.05698
Github鏈接:https://github.com/facebookresearch/modem
研究創新和模型架構
樣本效率低下是實際應用部署深度強化學習 (RL) 算法的主要挑戰,尤其是視覺運動控制。
基于模型的RL有可能通過同時學習世界模型并使用合成部署來進行規劃和政策改進,從而實現高樣本效率。
然而在實踐中,基于模型的RL的樣本高效學習受到探索挑戰的瓶頸,這次研究恰恰解決了這些主要挑戰。
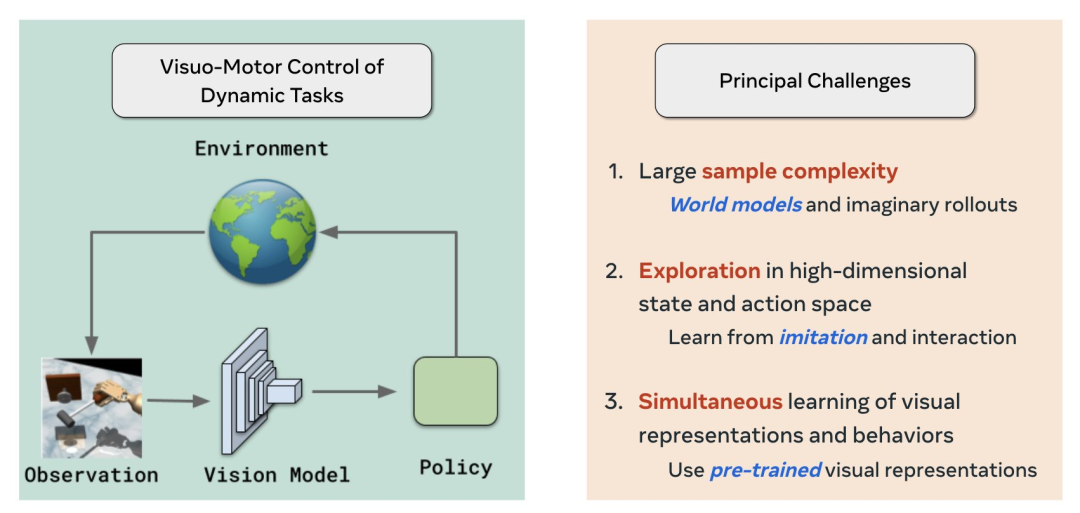
首先,MoDem分別通過使用世界模型、模仿+RL和自監督視覺預訓練,解決了視覺強化學習/控制領域的三個主要挑戰:
大樣本復雜性(Large sample complexity)
高維狀態和動作空間探索(Exploration in high-dimensional state and action space)
同步視覺表征和行為學習(Simultaneous learning of visual representations and behaviors)
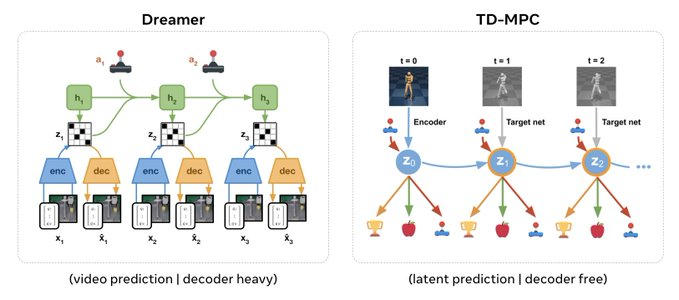
這次的模型架構類似于Yann LeCun的JEPA,并且無需解碼器。
作者Aravind Rajeswaran表示,相比Dreamer需要像素級預測的解碼器,架構繁重,無解碼器架構可支持直接插入使用SSL預訓練的視覺表示。
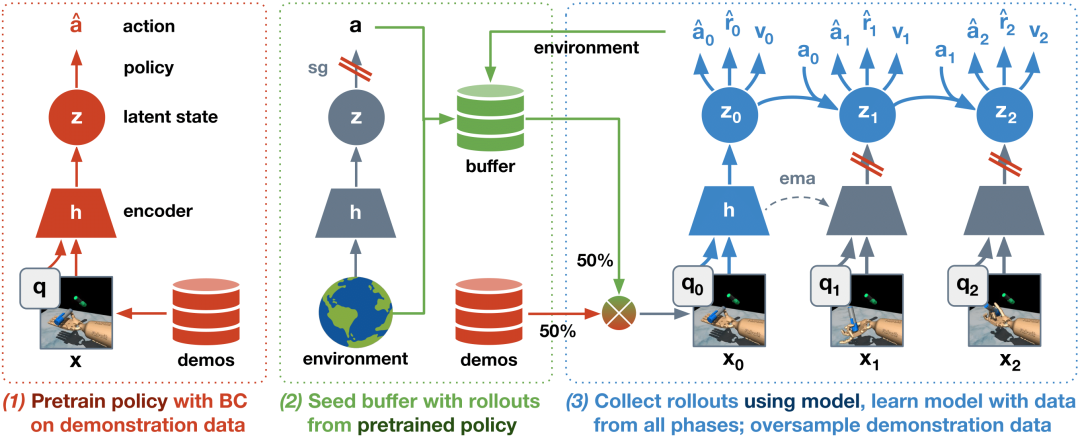
此外基于IL+RL,他們提出了一個三階段算法:
BC預訓練策略
使用包含演示和探索的種子數據集預訓練世界模型,此階段對于整體穩定性和效率很重要
通過在線互動微調世界模型
結果顯示,生成的算法在21個硬視覺運動控制任務中取得了SOTA結果(State-Of-The-Art result),包括Adroit靈巧操作、MetaWorld和DeepMind控制套件。
從數據上來看,MoDem在各項任務中的表現遠遠優于其他模型,結果比之前的SOTA方法提升了150%到250%。
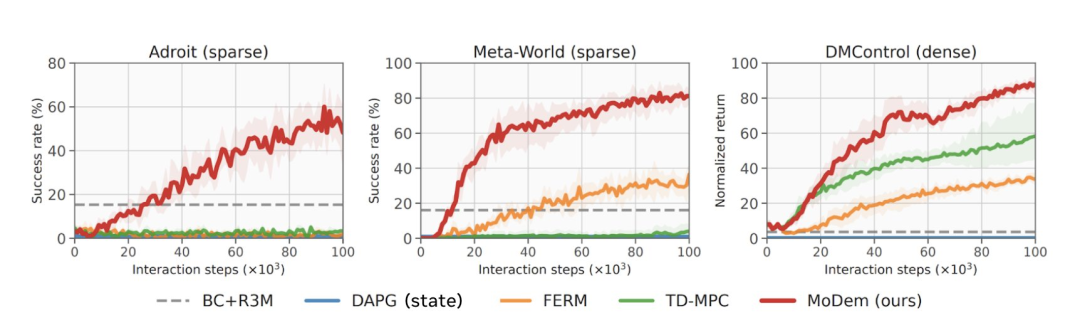
紅色線條為MoDem在各項任務中的表現
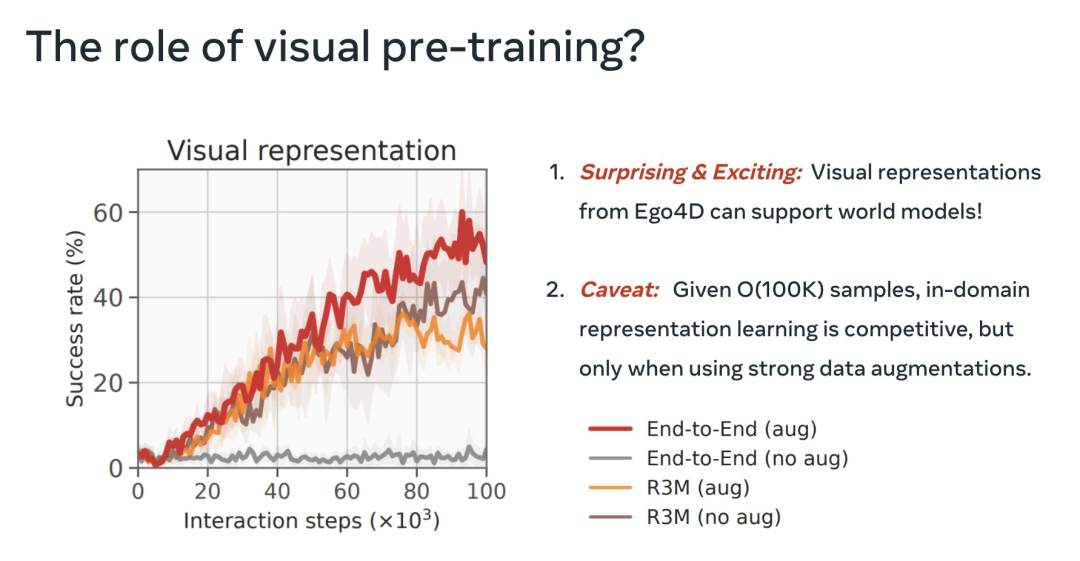
在此過程中,他們還闡明了MoDem中不同階段的重要性、數據增強對視覺MBRL的重要性以及預訓練視覺表示的實用性。
最后,使用凍結的 R3M 功能遠遠優于直接的 E2E 方法。這很令人興奮,表明視頻中的視覺預訓練可以支持世界模型。
但8月數據強勁的E2E與凍結的R3M競爭,我們可以通過預訓練做得更好。
審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1218瀏覽量
43393 -
Meta
+關注
關注
0文章
322瀏覽量
12453 -
強化學習
+關注
關注
4文章
270瀏覽量
11967
原文標題:Meta推出MoDem世界模型:解決視覺領域三大挑戰,LeCun轉發
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中常提的離線強化學習是什么?

強化學習會讓自動駕駛模型學習更快嗎?

多智能體強化學習(MARL)核心概念與算法概覽

上汽別克至境E7首發搭載Momenta R6強化學習大模型
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
今日看點:智元推出真機強化學習;美國軟件公司SAS退出中國市場
自動駕駛中常提的“強化學習”是個啥?

淺談Sn-Bi-Ag低溫錫膏的晶界強化機制
NVIDIA Isaac Lab可用環境與強化學習腳本使用指南

怎么結合嵌入式,Linux,和FPGA三個方向達到一個均衡發展?

華為發布天才少年挑戰課題發布 五大主題方向課題放榜
18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現




 工商網監
工商網監
評論