 統一的文本到結構生成框架——UIE
統一的文本到結構生成框架——UIE

引言:信息抽取終于走到了這一步:邁入大一統時代!
今天為大家介紹一篇好基友 @陸博士 的ACL22論文《Unified Structure Generation for Universal Information Extraction》,這也是中科院和百度聯合發布的1篇信息抽取統一建模工作UIE。
UIE官方鏈接:https://universal-ie.github.io
本文的組織架構為:
1.統一建模是IE發展的必然趨勢
眾所周知,信息抽取(IE)是一個從文本到結構的轉換過程。常見的實體、關系、事件分別采取Span、Triplet、Record形式的異構結構。
曾幾何時,當我們面對各種復雜多樣的IE任務,我們總會造各式各樣IE模型的輪子,來滿足不同復雜任務的多變需求。

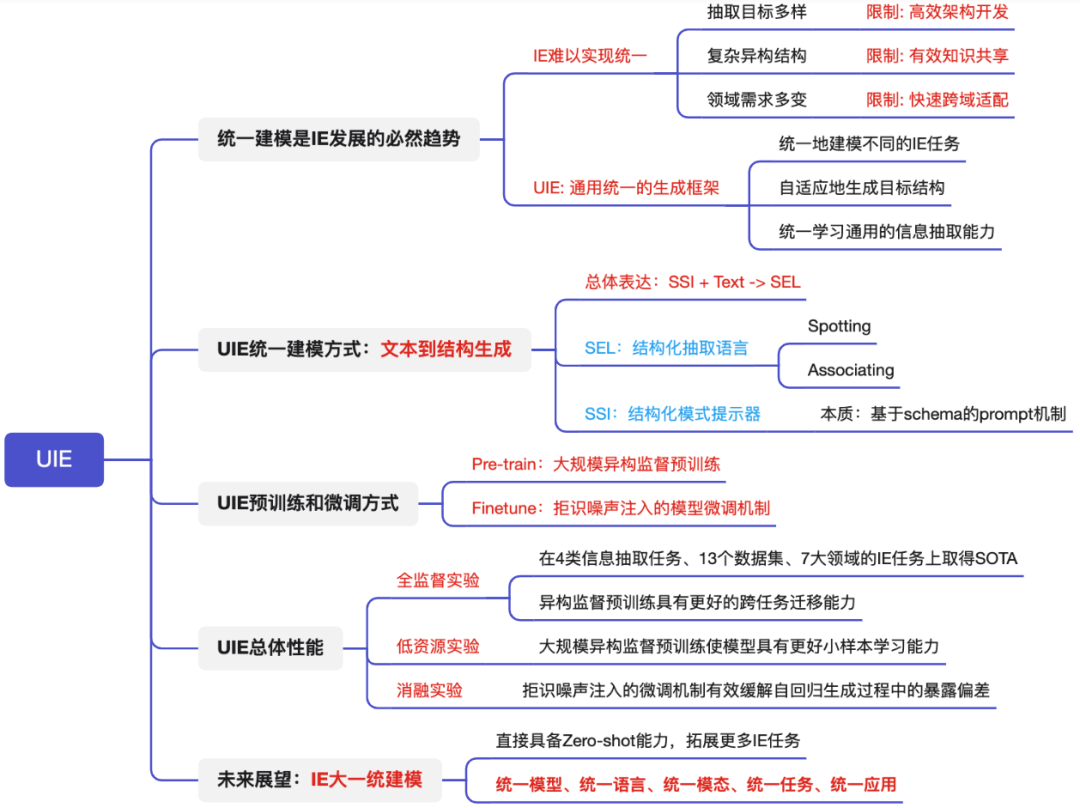
如上圖所示:由于多樣的抽取目標、相異的復雜結構、多變的領域需求時,導致信息抽取模型一直難以實現統一建模,極大限制了IE系統高效架構開發、有效知識共享、快速跨域適配。
比如,一個真實的情況是:針對不同任務設定,需要針對特定領域schema建模,不同IE模型被單個訓練、不共享,一個公司可能需要管理眾多IE模型。

當我們每次造不同IE輪子的時候,都要喝下不同的肥宅快樂水,撩以解憂(這不是個玩笑)
不過,在生成式統一建模各類NLP任務的今天,信息抽取統一建模也成為可能。
不久前,JayJay在《信息抽取的"第二范式"》一文中指出:生成式統一建模,或許是信息抽取領域正在發生的一場“深刻變革”。
因此:開發通用的IE結構是大有裨益的,可以統一建模不同的IE任務,從各種資源中自適應預測異構結構。總之:統一、通用的IE勢不可擋!
這篇ACL2022論文,@陸博士提出了一個面向信息抽取的統一文本到結構生成框架UIE,它可以:
統一地建模不同的IE任務;
自適應地生成目標結構;
從不同的知識來源統一學習通用的信息抽取能力。
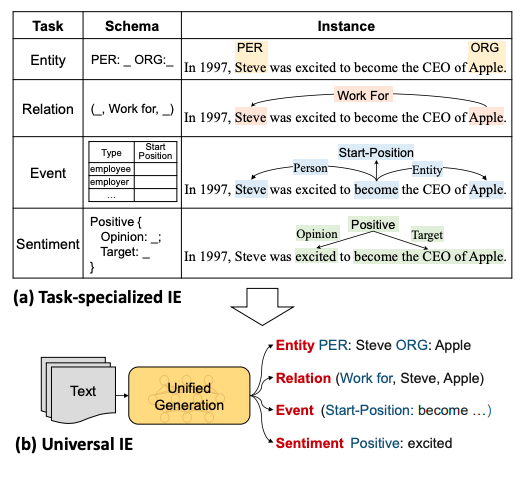
具體來說,UIE:
通過結構化抽取語言對不同的信息抽取目標結構進行統一編碼;
通過結構化模式提示器自適應生成目標結構;
通過大規模結構化/非結構化數據進行模型預訓練捕獲常見的IE能力;
實驗結果表明,本文提出的統一生成框架,基于T5模型進行了IE預訓練,在實體、關系、事件和情感等4個信息抽取任務、13個數據集的全監督、低資源和少樣本設置下均取得了SOTA性能。
接下來,我們將具體介紹UIE是如何統一建模的,以及具體是如何預訓練的?
2. UIE統一建模方式:文本到結構生成
信息抽取任務可以表述為“文本到結構”的問題,不同的IE任務對應不同的結構。
UIE旨在通過單一框架統一建模不同IE任務的文本到結構的轉換,也就是:不同的結構轉換共享模型中相同的底層操作和不同的轉換能力。
這里主要有兩個挑戰:
IE任務的多樣性,需要提取許多不同的目標結構,如實體、關系、事件等;
IE任務是通常是使用不同模式定義的特定需求(不同schema),需要自適應地控制提取過程;
因此,針對上述挑戰,需要:
設計結構化抽取語言(SEL,Structured Extraction Language)來統一編碼異構提取結構,即編碼實體、關系、事件統一表示。
構建結構化模式提示器(SSI,Structural Schema Instructor),一個基于schema的prompt機制,用于控制不同的生成需求。
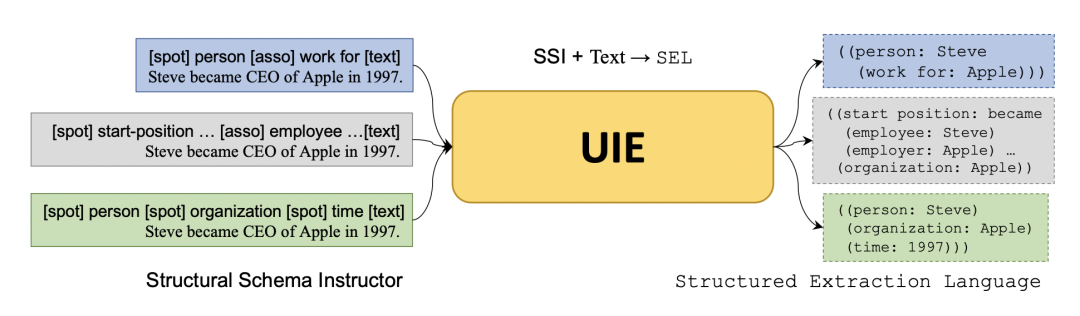
上圖展示了UIE的整體框架,整體架構就是:SSI + Text -> SEL
一句話簡單概括就是:SSI就是輸入特定抽取任務的schema,SEL就是把不同任務的抽取結果統一用1種語言表示。
1)SEL:結構化抽取語言
不同的IE任務可以分解為2個原子操作:
Spotting:找出Spot Name對應的Info Span,如某個實體或Trigger觸發詞;
Associating:找出Asso Name對應的Info Span,鏈接Info Span片段間的關系:如兩個實體pair的關系、論元和觸發詞間的關系;

如上圖(a)所示:SEL語言可以統一用(Spot Name:Info Span(Asso Name:Info Span)(Asso Name:Info Span)...)形式表示,具體地:
Spot Name:Spotting操作的Info Span的類別信息,如實體類型;
Asso Name: Associating操作的Info Span的類別信息,如關系類型、關系類型;
Info Span:Spotting或Associating操作相關的文本Span;
如上圖(b)所示:
藍色部分代表關系任務:person為實體類型Spot Name,work for為關系類型Asso Name;
紅色部分代表事件任務:start-position為事件類型Spot Name,employee為論元類型Asso Name;
黑色部分代表實體任務:organization和time為實體類型Spot Name;

上圖給出一個中文case:考察事件 為事件類型Spot Name,主角/時間/地點 為論元類型Asso Name。
2)SSI:結構化模式提示器
SSI的本質一個基于schema的prompt機制,用于控制不同的生成需求:在Text前拼接上相應的Schema Prompt,輸出相應的SEL結構語言。
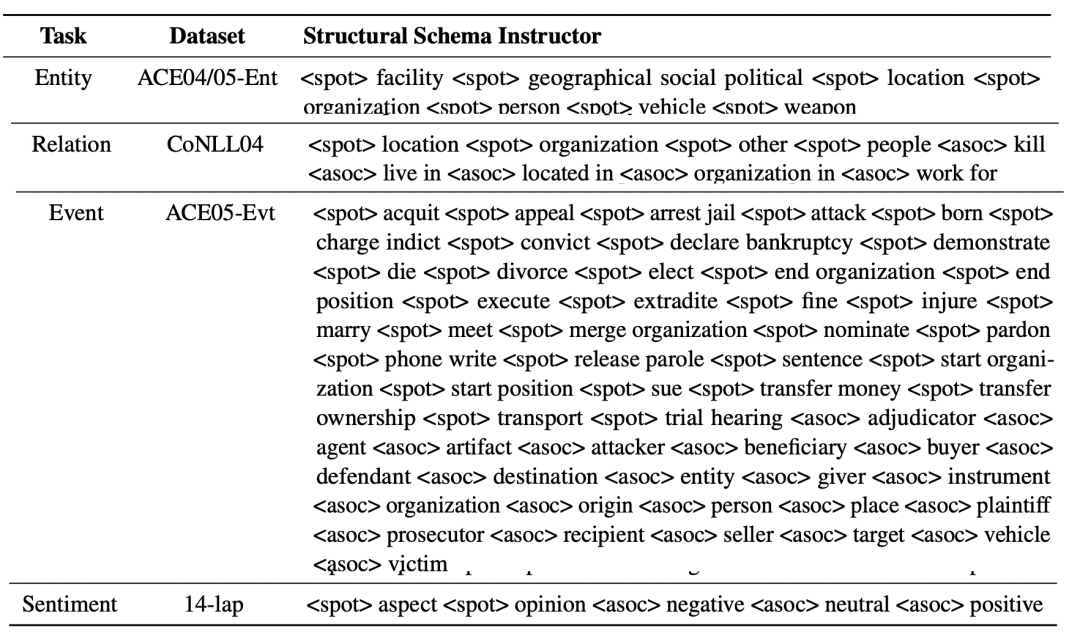
不同任務的的形式是:
實體抽取:[spot] 實體類別 [text]
關系抽取:[spot] 實體類別 [asso] 關系類別 [text]
事件抽取:[spot] 事件類別 [asso] 論元類別 [text]
觀點抽取:[spot] 評價維度 [asso] 觀點類別 [text]
下圖給出了不同任務數據集的SSI形式:
3. UIE預訓練和微調方式
本小節,我們將介紹:
1)Pre-train:如何預訓練一個大規模的UIE模型,來捕獲不同IE任務間的通用IE能力?
2)Finetune:如何通過快速的Finetune使UIE適應不同設置下的不同 IE 任務。
1)Pre-train:大規模異構監督預訓練
UIE預訓練語料主要來自Wikipedia、Wikidata和ConceptNet,構建了3種預訓練數據:
D_pair: 通過Wikipedia對齊Wikidata,構建text-to-struct的平行語料:(SSI,Text,SEL)
D_record: 構造只包含SEL語法結構化record數據:(None,None,SEL)
D_text: 構造無結構的原始文本數據:(None,Text',Text'')
針對上述數據,分別構造3種預訓練任務,將大規模異構數據整合到一起進行預訓練:
Text-to-Structure Pre-training:為了構建基礎的文本到結構的映射能力,對平行語料D_pair訓練,同時構建負樣本作為噪聲訓練(引入negative schema)。
Structure Generation Pre-training:為了具備SEL語言的結構化能力,對D_pair數據只訓練 UIE 的 decoder 部分。
Retrofitting Semantic Representation:為了具備基礎的語義編碼能力,對D_text數據進行 span corruption訓練。
最終的預訓練目標,包含以上3部分;
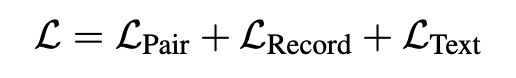
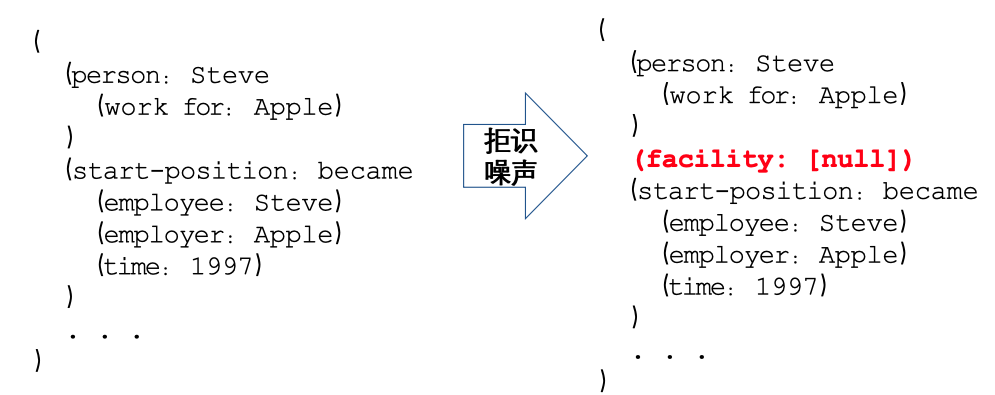
2)Finetune:拒識噪聲注入的模型微調機制
為了解決自回歸Teacher-forcing的暴露偏差,構建了拒識噪聲注入的模型微調機制:隨機采樣SEL中不存在的SpotName類別和AssoName類別,即:(SPOTNAME, [NULL]) 和 (ASSONAME, [NULL]),學會拒絕生成錯誤結果的能力,如下圖所示:
4. UIE主要實驗結論
1)全監督實驗
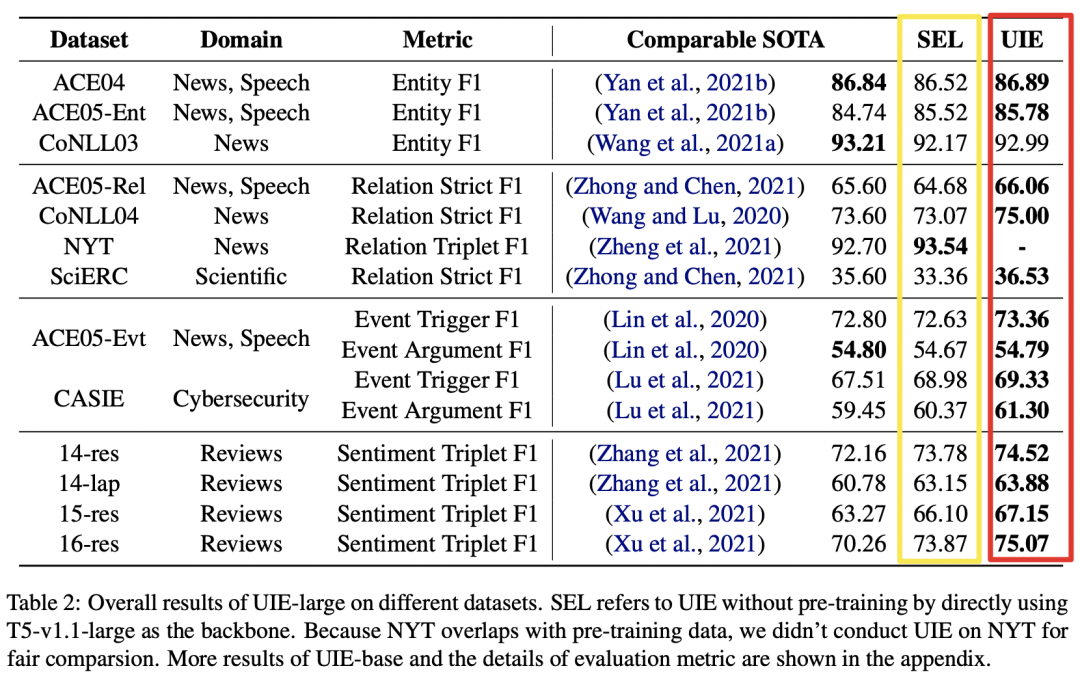
如上圖所示,SEL代表未經預訓練的UIE模型。可以看出:
1、在4類信息抽取任務、13個數據集、7大領域的IE任務上,UIE達到了SOTA性能;
2、對比SEL和UIE結果:異構監督預訓練顯著地提升了 UIE 的通用信息抽取能力,具有更好的跨任務遷移能力;
2)少樣本實驗
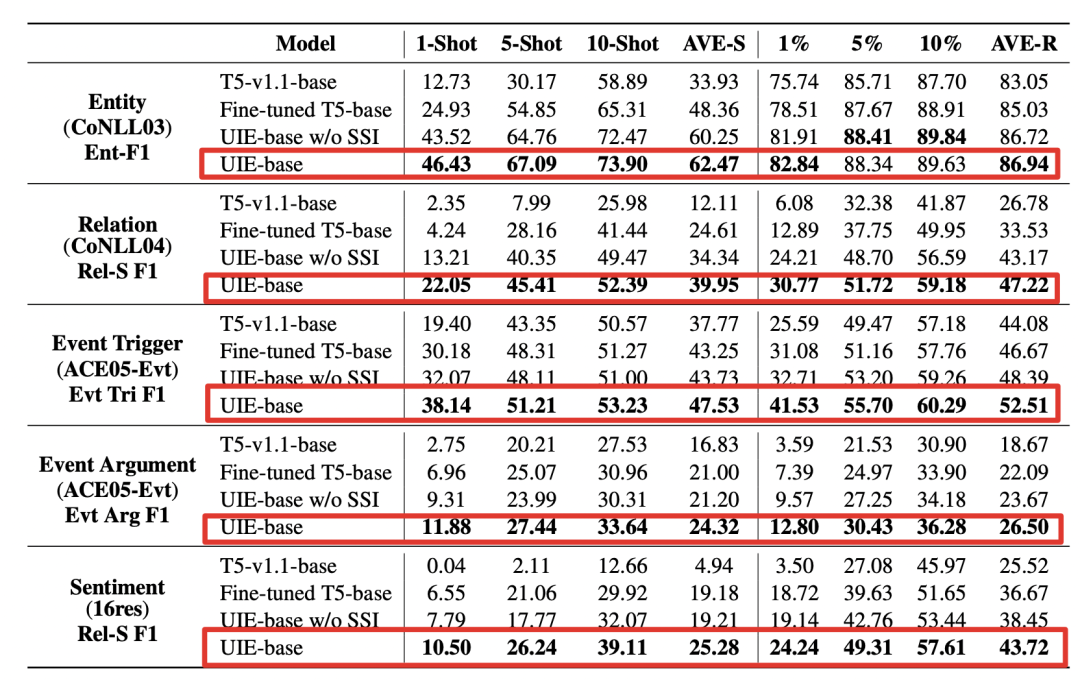
少樣本實驗可以發現:
1、大規模異構監督預訓練可以學習通用的信息抽取能力,使模型具有更好小樣本學習能力。
2、當去掉SSI結構化模式提示器后,發現指標下降,因此:結構化抽取指令具有更好的定向遷移的能力。
3)消融實驗
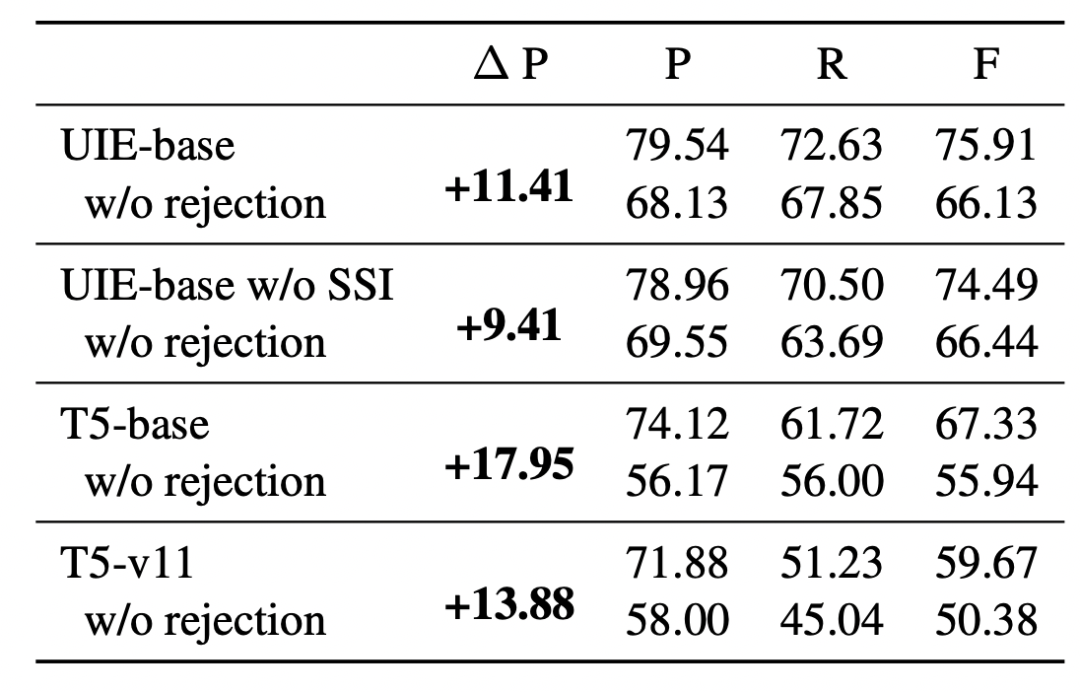
上述消融實驗表明:基于拒識噪聲注入的模型微調機制可以有效緩解自回歸生成過程中的暴露偏差問題。
總結與展望
本文介紹了一個統一的文本到結構生成框架——UIE,可以通用建模不同的IE任務,自適應生成有針對性的結構,從不同的知識來源統一學習通用的信息抽取能力。
實驗結果表明UIE實現了在監督和低資源下的SOTA性能,同時驗證了其普遍性、有效性和可轉移性。
審核編輯 :李倩
-
建模
+關注
關注
1文章
321瀏覽量
63289 -
文本
+關注
關注
0文章
120瀏覽量
17867
原文標題:信息抽取大一統:百度中科院發布通用抽取模型UIE,刷新13個IE數據集SOTA!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
為什么國產MCU的工程生態很難統一?
京東零售廣告創意:統一的布局生成和評估模型

重構電子系統抗擾設計的統一理論框架——從關聯認知到正向設計

半導體封裝框架的外部結構設計
萬里紅文本生成算法通過國家網信辦備案
請問STM32如何移植Audio框架?
Copilot操作指南(一):使用圖片生成原理圖符號、PCB封裝
一種基于擴散模型的視頻生成框架RoboTransfer

關于鴻蒙App上架中“AI文本生成模塊的資質證明文件”的情況說明
ArkUI-X應用工程結構說明
STM32如何移植Audio框架?
一種多模態駕駛場景生成框架UMGen介紹
動量感知規劃的端到端自動駕駛框架MomAD解析
基于事件相機的統一幀插值與自適應去模糊框架(REFID)
使用OpenVINO GenAI和LoRA適配器進行圖像生成



 工商網監
工商網監
評論