 AMD剛剛發布7nm CDNA架構的MI100加速卡
AMD剛剛發布7nm CDNA架構的MI100加速卡

今晚AMD剛剛發布了7nm CDNA架構的MI100加速卡,NVIDIA這邊就推出了A100 80GB加速卡。雖然AMD把性能奪回去了,但是A100 80GB的HBM2e顯存也是史無前例了。
NVIDIA今年3月份發布了安培架構的A100加速卡(名字中沒有Tesla了),升級了7nm工藝和Ampere安培架構,集成542億晶體管,826mm2核心面積,使用了40GB HBM2顯存,帶寬1.6TB/s。
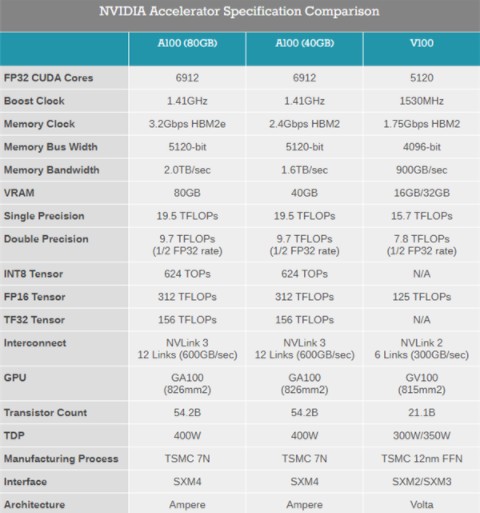
現在的A100 80GB加速卡在GPU芯片上沒變化,依然是A100核心,6912個CUDA核心,加速頻率1.41GHz,FP32性能19.5TFLOPS,FP64性能9.7TFLOPS,INT8性能624TOPS,TDP 400W。
變化的主要是顯存,之前是40GB,HBM2規格的,帶寬1.6TB/s,現在升級到了80GB,顯存類型也變成了更先進的HBM2e,頻率從2.4Gbps提升到3.2Gbps,使得帶寬從1.6TB/s提升到2TB/s。
對游戲卡來說,這樣的顯存容量肯定是浪費了,但是在高性能計算、AI等領域,顯存很容易成為瓶頸,所以翻倍到80GB之后,A100 80GB顯卡可以提供更高的性能,NVIDIA官方信息稱它的性能少則提升25%,多則提升200%,特別是在AI訓練中,同時能效也提升了25%。
在A100 80GB加速卡發布之后,現在的A100 40GB版依然會繼續銷售。
責任編輯:pj
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
amd
+關注
關注
25文章
5682瀏覽量
139937 -
NVIDIA
+關注
關注
14文章
5592瀏覽量
109717 -
帶寬
+關注
關注
3文章
1040瀏覽量
43352
發布評論請先 登錄
相關推薦
熱點推薦
FPGA硬件加速卡設計原理圖:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片
FPGA硬件加速, PCIe半高卡, XCKU115, 光纖采集卡, 信號計算板, 硬件加速卡

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN標準嵌入式開發板
LLM-8850KitLLM-8850Kit是一款面向邊緣AI與嵌入式計算場景的高性能AI加速卡套件,由LLM-8850CardAI加速卡與LLM-8850PiHat轉接板組成。核心加速卡

高速信號處理設計方案:413-基于雙XCVU9P+C6678的100G光纖加速卡
C6678, XCVU9P, ZU19EG開發板,, 高速信號處理, 光纖加速卡, XCVU9P光纖加速卡
昆侖芯R200 AI加速卡技術規格解析
昆侖芯R200加速卡基于7nm XPU-R架構,在150W功耗下提供256 TOPS INT8算力,側重高性能推理。配備最高32GB GDDR6內存(512GB/s帶寬)及108路視頻解碼能力,支持

邁向云端算力巔峰:昆侖芯K200 AI加速卡全面解讀
昆侖芯K200作為云端AI加速卡,在K100架構基礎上全面升級。其INT8算力達256 TOPS,配備16GB HBM內存與512GB/s帶寬,專為千億參數大模型訓練與高并發推理優化。采用全高全長雙

專為邊緣而生:深度解析昆侖芯K100 AI加速卡,釋放128 TOPS極致能效
昆侖芯K100邊緣AI加速卡以75W超低功耗實現128 TOPS的INT8算力,重新定義邊緣推理能效標準。其半高半長設計搭載8GB HBM內存與256GB/s帶寬,支持INT8至FP32多精度計算

深圳光量子工廠啟示:PCI 加速卡為何偏向 25MHz 2016 有源晶振?
在 PCI?加速卡項目中,工程師使用SJK 2016?系列有源晶振?25MHZ。原因不僅僅是規格匹配,更在于系統復雜度。

算力密度翻倍!江原D20加速卡發布,一卡雙芯重構AI推理標桿
的關鍵技術瓶頸。 ? 在此背景下,江原科技推出采用自研AI芯片的AI加速卡江原D10,并在今年5月實現量產交付。在大算力AI芯片全流程國產化產業鏈實現首次突破后,11月11日,江原科技再次發布新一代全國產AI加速卡——江原D20

虛擬電廠加速卡不是噱頭!萬點規模VPP的性能分水嶺
。 ? 此時僅靠邊緣MPU/CPU的通用算力,可能無法及時處理數據清洗、異常檢測、指令下發校驗等任務,而加速卡(如 GPU、FPGA 加速卡)的并行計算能力可快速消化數據洪流,避免“小包風暴”導致的系統卡頓。 ? 虛擬電廠對AG
AMD 7nm Versal系列器件NoC的使用及注意事項
AMD 7nm Versal系列器件引入了可編程片上網絡(NoC, Network on Chip),這是一個硬化的、高帶寬、低延遲互連結構,旨在實現可編程邏輯(PL)、處理系統(PS)、AI引擎(AIE)、DDR控制器(DDRMC)、CPM(PCIe/CXL)等模塊之間
智算加速卡是什么東西?它真能在AI戰場上干掉GPU和TPU!
隨著AI技術火得一塌糊涂,大家都在談"大模型"、"AI加速"、"智能計算",可真到了落地環節,算力才是硬通貨。你有沒有發現,現在越來越多的AI企業不光用GPU,也不怎么迷信TPU了?他們嘴里多了一個新詞兒——智算加速卡。


邊緣AI運算革新 DeepX DX-M1 AI加速卡結合Rockchip RK3588多路物體檢測解決方案
DeepX 推出了一款革命性的產品 DeepX DX-M1 AI 推理加速卡 采用 PCIe Gen3 M.2 M-Key 接口,具備高達 25 TOPS 的卓越運算性能,以及高準確度、低功耗、低溫

寒武紀基于思元370芯片的MLU370-X8 智能加速卡產品手冊詳解
MLU370-X8智能加速卡是全面升級的數據中心訓推一體AI加速卡,基于寒武紀全新一代思元370芯片,接口為PCIe 4.0 X16,是全高全長雙寬(FHFL-Dual-Slot)的標準PCIe加速卡,適用于業內最新的CPU平臺

邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測方案
本方案特別結合了 Orange Pi 5 Plus (Rockchip RK3588) 與 MemryX AI 加速卡,構建出一套高性價比的智能解決方案。憑借 MemryX 提供的豐富軟件資源




 工商網監
工商網監
評論