將模型稱為 “視覺語言” 模型是什么意思?一個結合了視覺和語言模態的模型?但這到底是什么意思呢?
2023-03-03 09:49:37 1577
1577 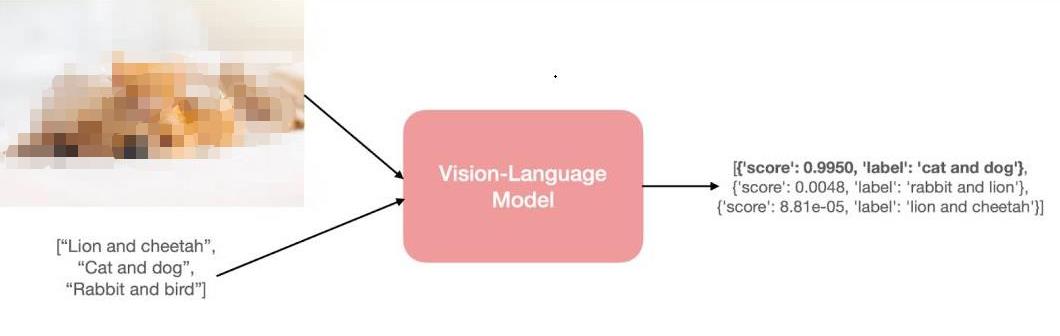
大型語言模型的出現極大地推動了自然語言處理領域的進步,但同時也存在一些局限性,比如模型可能會產生看似合理但實際上是錯誤或虛假的內容,這一現象被稱為幻覺(hallucination)。幻覺的存在使得
2023-08-15 09:33:452260 
最新研究揭示,盡管大語言模型LLMs在語言理解上表現出色,但在邏輯推理方面仍有待提高。為此,研究者們推出了GLoRE,一個全新的邏輯推理評估基準,包含12個數據集,覆蓋三大任務類型。
2023-11-23 15:05:162019 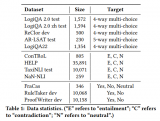
在大型語言模型(LLMs)的應用中,提示工程(Prompt Engineering)是一種關鍵技術,用于引導模型生成特定輸出或執行特定任務。通過精心設計的提示,可以顯著提高LLMs的性能和適用性。本文將介紹提示工程的主要方法和技巧,包括少樣本提示、提示壓縮和提示生成。
2023-12-13 14:21:471405 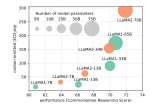
1.LLM(大語言模型)大型語言模型(LLMs)是先進的人工智能系統,經過大量文本數據集的訓練,可以理解和生成類似人類的文本。他們使用深度學習技術以上下文相關的方式處理和生成語言。OpenAI
2024-05-10 08:27:261964 
NVIDIA NeMo 大型語言模型(LLM)服務幫助開發者定制大規模語言模型;NVIDIA BioNeMo 服務幫助研究人員生成和預測分子、蛋白質及 DNA ? 美國加利福尼亞州圣克拉拉
2022-09-21 15:24:52737 
? 電子發燒友網報道(文/周凱揚)大語言模型的風靡給AI應用創造了不少機會,無論是效率還是創意上,大語言模型都帶來了前所未有的表現,這些大語言模型很快成為大型互聯網公司或者AI應用公司的殺手級產品
2024-06-03 05:15:003339 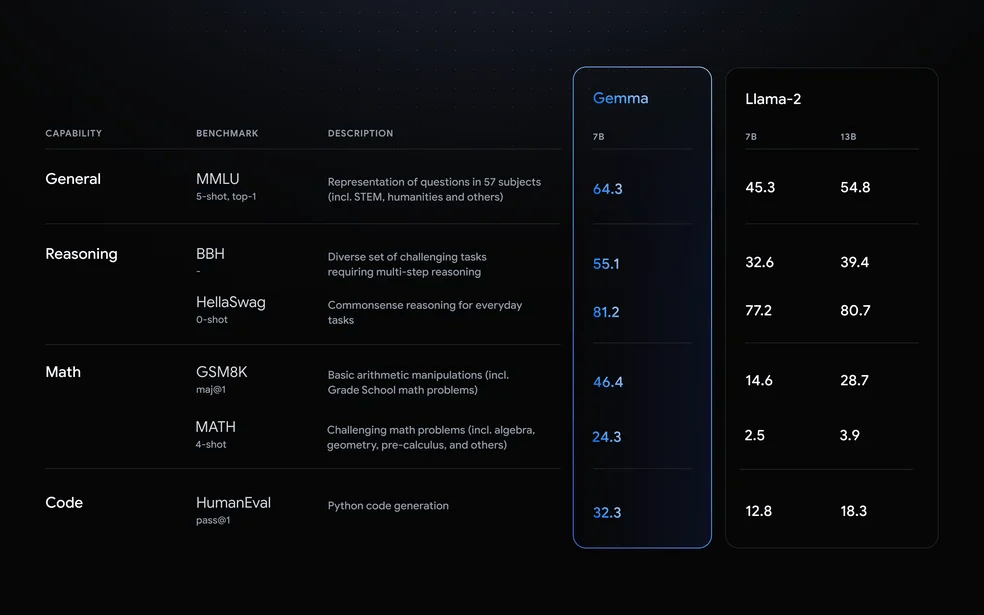
今天開始學習《大語言模型應用指南》第一篇——基礎篇,對于人工智能相關專業技術人員應該可以輕松加愉快的完成此篇閱讀,但對于我還是有許多的知識點、專業術語比較陌生,需要網上搜索學習更多的資料才能理解書中
2024-07-25 14:33:23
今天來學習大語言模型在自然語言理解方面的原理以及問答回復實現。
主要是基于深度學習和自然語言處理技術。
大語言模型涉及以下幾個過程:
數據收集:大語言模型通過從互聯網、書籍、新聞、社交媒體等多種渠道
2024-08-02 11:03:41
訓練模型如BERT、GPT等。這些模型在理解自然語言、生成文本、處理對話等方面具有不同的能力。因此,在選擇模型時,需要了解每個模型的特點和優勢,以便根據企業需求進行選擇。大型模型通常需要較大的計算資源
2024-12-17 16:53:12
之后,成為文本建模領域的熱門架構。不僅如此,它還對自然語言處理領域產生了深遠的影響。基于Transformer的預訓練模型,如GPT系列和BERT系列,已在多種任務上取得了卓越的成績。目前的大型語言
2024-05-05 12:17:03
,它通過抽象思考和邏輯推理,協助我們應對復雜的決策。
相應地,我們設計了兩類任務來檢驗大語言模型的能力。一類是感性的、無需理性能力的任務,類似于人類的系統1,如情感分析和抽取式問答等。大語言模型在這
2024-05-07 17:21:45
閱讀和理解。
文案創作能力:在大語言模型應用中占據核心地位,尤其對于滿足多樣化、復雜化的內容需求具有不可替代的價值。這種能力不僅限于戲劇劇本、市場營銷文案、學術研究論文和數據分析報告等多種文章形態的生成
2024-05-07 17:12:40
大語言模型的核心特點在于其龐大的參數量,這賦予了模型強大的學習容量,使其無需依賴微調即可適應各種下游任務,而更傾向于培養通用的處理能力。然而,隨著學習容量的增加,對預訓練數據的需求也相應
2024-05-07 17:10:27
《大語言模型》是一本深入探討人工智能領域中語言模型的著作。作者通過對語言模型的基本概念、基礎技術、應用場景分析,為讀者揭開了這一領域的神秘面紗。本書不僅深入討論了語言模型的理論基礎,還涉及自然語言
2024-04-30 15:35:24
《大語言模型“原理與工程實踐”》是關于大語言模型內在機理和應用實踐的一次深入探索。作者不僅深入討論了理論,還提供了豐富的實踐案例,幫助讀者理解如何將理論知識應用于解決實際問題。書中的案例分析有助于
2024-05-07 10:30:50
復用和優化效果。這些趨勢共同推動了大語言模型在深度學習研究和應用中的重要地位。數據效應指出大型模型需要更多數據進行訓練,以提高性能。其次,表示能力使得大語言模型能夠學習更復雜、更精細的表示方法,從而
2024-05-04 23:55:44
的復雜模式和長距離依賴關系。
預訓練策略:
預訓練是LLMs訓練過程的第一階段,模型在大量的文本數據上學習語言的通用表示。常用的預訓練任務包括遮蔽語言建模(Masked Language
2024-05-05 10:56:58
再次感謝電子發燒友提供的書籍試讀機會。今天來分享下我在學習大模型訓練中 注意力機制 的心得體會。
雖然注意力機制可以顯著提高模型處理長序列數據的能力,但這也帶來了計算成本的增加。在大型模型中,自
2024-06-07 14:44:24
前言
深度學習是機器學習的分支,而大語言模型是深度學習的分支。機器學習的核心是讓計算機系統通過對數據的學習提高性能,深度學習則是通過創建人工神經網絡處理數據。近年人工神經網絡高速發展,引發深度學習
2024-05-13 00:09:37
解鎖
我理解的是基于深度學習,需要訓練各種數據知識最后生成自己的的語言理解和能力的交互模型。
對于常說的RNN是處理短序列的數據時表現出色,耳真正厲害的是Transformer,此框架被推出后直接
2024-05-12 23:57:34
無法在 OVMS 上運行來自 Meta 的大型語言模型 (LLM),例如 LLaMa2。
從 OVMS GitHub* 存儲庫運行 llama_chat Python* Demo 時遇到錯誤。
2025-03-05 08:07:06
自然語言處理——53 語言模型(數據平滑)
2020-04-16 11:11:25
C語言之自然對數的底e的計算,很好的C語言資料,快來學習吧。
2016-04-22 17:45:55 0
0 C語言教程之自然對數的底e的計算,很好的C語言資料,快來學習吧。
2016-04-22 17:45:550 C語言教程之對數組進行升序和降序排序,很好的C語言資料,快來學習吧。
2016-04-25 16:09:480 大型網絡異常數據庫的快速數據定位模型仿真_朱保鋒
2017-01-03 18:00:370 為了實現在線海量數據的高效存儲與訪問,在內存云分級存儲架構下,提出一種基于數據重要性的遷移模型( MMDS)。首先,通過數據本身的大小、時間重要性、用戶訪問總量等因素對數據本身的重要性進行計算;其次
2017-12-27 16:54:331 如今有許多企業存儲討論的重點是將數據轉移到公共云上進行歸檔,因為進入的成本并不高,尤其是在需要即時容量的情況下。但是,一旦企業采用公共云,可能會出現這樣的情況,需要將數據遷移回本地部署的數據中心,以實現逆向云存儲戰略。
2018-06-14 09:01:293512 數據先要通過存儲層存儲下來,然后根據數據需求和目標來建立相應的數據模型和數據分析指標體系對數據進行分析產生價值。
2020-03-27 10:06:101383 Python官方文檔說法是“Python數據模型”,大多數Python書籍作者說法是“Python對象模型”,它們是一個意思,表示“計算機編程語言中對象的屬性”。這句話有點抽象,只要知道對象是Python對數據的抽象,在Python中萬物皆對象就可以了。
2021-02-10 15:59:003050 
深度學習模型應用于自然語言處理任務時依賴大型、高質量的人工標注數據集。為降低深度學習模型對大型數據集的依賴,提出一種基于BERT的中文科技自然語言處理預訓練模型 ALICE。通過對遮罩語言模型進行
2021-05-07 10:08:1614 NVIDIA為全球企業開發和部署大型語言模型打開了一扇新的大門——使這些企業能夠建立他們自己的、特定領域的聊天機器人、個人助理和其他AI應用程序,并能夠以前所未有的水平理解語言中的微妙和細微差別
2021-11-12 14:30:072126 NVIDIA NeMo 大型語言模型(LLM)服務幫助開發者定制大規模語言模型;NVIDIA BioNeMo 服務幫助研究人員生成和預測分子、蛋白質及 DNA
2022-09-22 10:42:291202 韓國先進的移動運營商構建包含數百億個參數的大型語言模型,并使用 NVIDIA DGX SuperPOD 平臺和 NeMo Megatron 框架訓練該模型。
2022-09-27 09:24:301995 隨著大型語言模型( LLM )的規模和復雜性不斷增長, NVIDIA 今天宣布更新 NeMo Megatron 框架,提供高達 30% 的訓練速度。
2022-10-10 15:39:421436 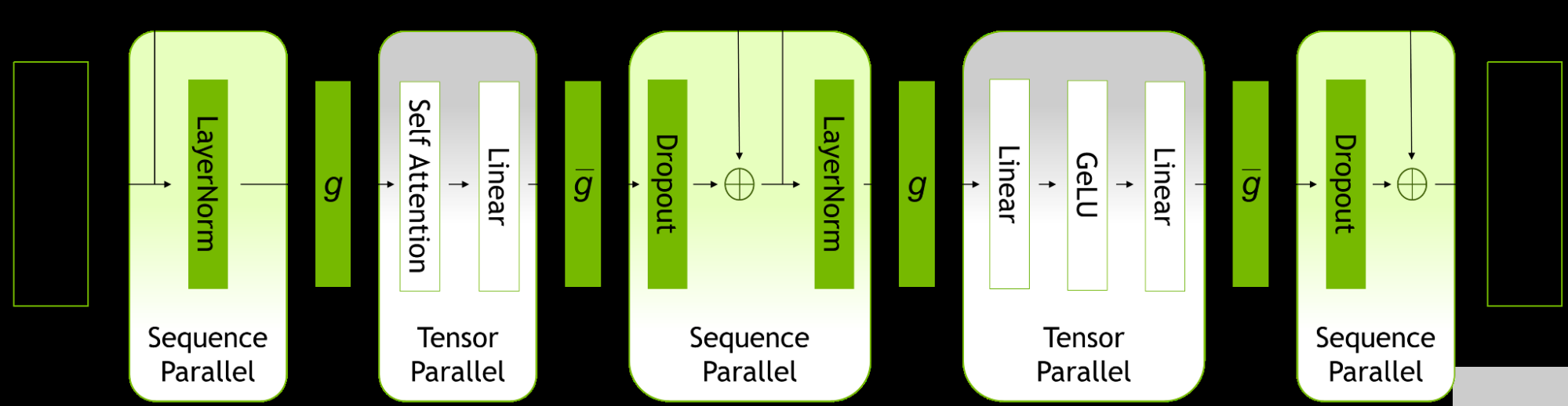
。 這一聯合團隊的研究指出,經過基因組學訓練的大型語言模型(LLM)可將應用擴展到大量基因組學任務。 該團隊使用 NVIDIA 的超級計算機 Cambridge-1 來訓練參數規模從 500M 到 2.5B 不等的各種大型語言模型(LLM)。這些模型在各種基因組數據集上進行了訓練,以探
2023-01-17 01:05:041217 BigCode 是一個開放的科學合作組織,致力于開發大型語言模型。近日他們開源了一個名為 SantaCoder 的語言模型,該模型擁有 11 億個參數
2023-01-17 14:29:531365 通過大規模數據集訓練來學習識別、總結、翻譯、預測和生成文本及其他內容。 大型語言模型是 Transformer 模型最成功的應用之一。它們不僅將人類的語言教給 AI,還可以幫助 AI 理解蛋白質、編寫軟件代碼等等。 除了加速翻譯軟件、聊天機器人
2023-02-23 19:50:046084 大型語言模型能識別、總結、翻譯、預測和生成文本及其他內容。
2023-03-08 13:57:009398 和運行自定義大型語言模型和生成式AI模型,這些模型專為企業所在領域的特定任務而創建,并且在專有數據上訓練。 ? Getty Images、Morningstar、Quantiphi、Shutterstock公
2023-03-22 13:45:40607 
能夠構建、完善和運行自定義大型語言模型和生成式 AI 模型,這些模型專為企業所在領域的特定任務而創建,并且在專有數據上訓練。 Getty Images、Morningstar、Quantiphi、Shutterst
2023-03-23 06:50:04907 NVIDIA NeMo 服務幫助企業將大型語言模型與其專有數據相結合,賦能智能聊天機器人、客戶服務等更多應用。 如今的大型語言模型知識淵博,但它們的工作方式有點像時間膠囊——所收集的信息僅限于第一次
2023-03-25 09:10:031082 對于任何沒有額外微調和強化學習的預訓練大型語言模型來說,用戶得到的回應質量可能參差不齊,并且可能包括冒犯性的語言和觀點。這有望隨著規模、更好的數據、社區反饋和優化而得到改善。
2023-04-24 10:07:063187 
近來NLP領域由于語言模型的發展取得了顛覆性的進展,擴大語言模型的規模帶來了一系列的性能提升,然而單單是擴大模型規模對于一些具有挑戰性的任務來說是不夠的
2023-05-10 11:13:172935 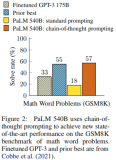
大型語言模型LLM(Large Language Model)具有很強的通用知識理解以及較強的邏輯推理能力,但其只能處理文本數據。
2023-05-10 16:53:151926 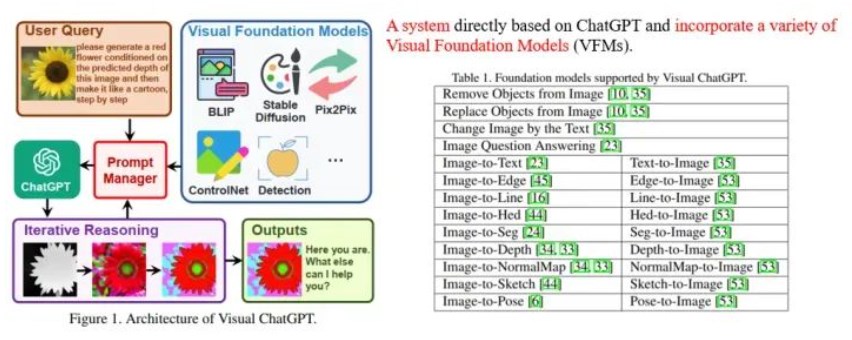
? 大型語言模型能否捕捉到它們所處理和生成的文本中的語義信息?這一問題在計算機科學和自然語言處理領域一直存在爭議。然而,MIT的一項新研究表明,僅基于文本形式訓練、用于預測下一個token的語言模型
2023-05-25 11:34:111273 
近日,IBM 存儲推出了基于其閃存產品 IBM FlashSystem 的新能力,幫助企業高效應對數據安全威脅。
2023-05-25 16:35:021717 ChatGPT 在 2022 年年底的橫空出世,引發了各行各業對生成式人工智能、大型語言模型和基礎模型的廣泛關注和討論,人工智能發展的“質變時刻”正在加速到來。作為人工智能應用的“三駕馬車”,算力
2023-05-25 16:36:221512 
大型語言模型研究的發展有三條技術路線:Bert 模式、GPT 模式、混合模式。其中國內大多采用混合模式, 多數主流大型語言模型走的是 GPT 技術路線,直到 2022 年底在 GPT-3.5 的基礎上產生了 ChatGPT。
2023-06-09 12:34:536429 
近年來,像 GPT-4 這樣的大型語言模型 (LLM) 因其在自然語言理解和生成方面的驚人能力而受到廣泛關注。但是,要根據特定任務或領域定制LLM,定制培訓是必要的。本文提供了有關自定義訓練 LLM 的詳細分步指南,其中包含代碼示例和示例。
2023-06-12 09:35:433709 他預計,深度學習和大型語言模型會繼續發展:這個領域的未來可能會有一小部分重大突破,加之許多細微改進,所有這些都將融入到一個龐大而復雜的工程體系。他還給出了一些有趣、可執行的思想實驗。
2023-06-12 16:38:48855 本文旨在更好地理解基于 Transformer 的大型語言模型(LLM)的內部機制,以提高它們的可靠性和可解釋性。 隨著大型語言模型(LLM)在使用和部署方面的不斷增加,打開黑箱并了解它們的內部
2023-06-25 15:08:492366 
?? 大型語言模型(LLM) 是一種深度學習算法,可以通過大規模數據集訓練來學習識別、總結、翻譯、預測和生成文本及其他內容。大語言模型(LLM)代表著 AI 領域的重大進步,并有望通過習得的知識改變
2023-07-05 10:27:352808 簡單來說,語言模型能夠以某種方式生成文本。它的應用十分廣泛,例如,可以用語言模型進行情感分析、標記有害內容、回答問題、概述文檔等等。但理論上,語言模型的潛力遠超以上常見任務。
2023-07-14 11:45:401398 
來源: DeepHub IMBA 大型語言模型(llm)是一種人工智能(AI),在大量文本和代碼數據集上進行訓練。它們可以用于各種任務,包括生成文本、翻譯語言和編寫不同類型的創意內容。 今年開始
2023-07-28 12:20:021214 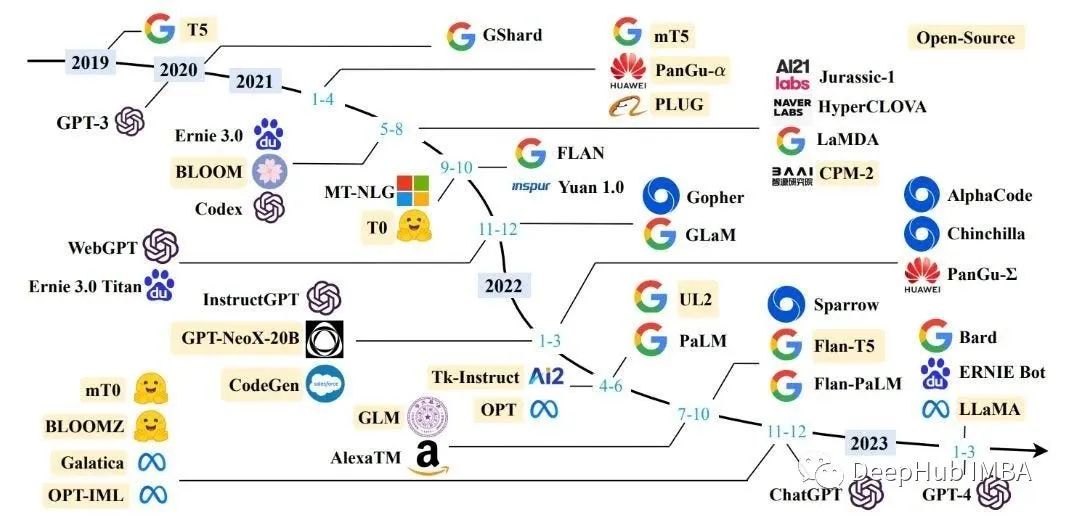
近日,美智庫蘭德公司高級工程師克里斯托弗·莫頓(Christopher Mouton)在C4ISRNET網站撰文,分析ChatGPT等大型語言模型的出現給國家安全帶來的新風險。主要觀點如下:
2023-08-04 11:44:53717 大型語言模型(llm)是一種人工智能(AI),在大量文本和代碼數據集上進行訓練。它們可以用于各種任務,包括生成文本、翻譯語言和編寫不同類型的創意內容。今年開始,人們對開源LLM越來越感興趣。這些模型
2023-08-01 00:21:271468 對話文本數據,作為人類交流的生動表現,正成為訓練大型模型的寶貴資源。這些數據不僅蘊含了豐富的語言特點和人類交流方式,更在模型訓練中發揮著重要的意義,從而為其賦予更強大的智能和更自然的交流能力。 大型模型
2023-08-14 10:11:111084 。 大型模型,特別是基于深度學習的預訓練語言模型,如GPT-3.5,依賴于大規模的文本數據來進行訓練。這些模型之所以強大,源于它們從這些數據中學習到的語義、關聯和結構。文本數據中蘊含著豐富的知識、思想和信息,通過模型的
2023-08-14 10:06:231041 近日,清華大學新聞與傳播學院發布了《大語言模型綜合性能評估報告》,該報告對目前市場上的7個大型語言模型進行了全面的綜合評估。近年,大語言模型以其強大的自然語言處理能力,成為AI領域的一大熱點。它們
2023-08-10 08:32:012137 今天,Meta發布了Code Llama,一款可以使用文本提示生成代碼的大型語言模型(LLM)。
2023-08-25 09:06:572437 
,大型語言模型(Large Language Models,LLM)徹底改變了自然語言處理領域,使機器能夠生成類似人類的文本并進行有意義的對話。這些模型,例如OpenAI的GPT,擁有驚人的語言理解和生成能力。它們可以被用于廣泛的自然語言處理任務,包括文本生成、翻譯、自動摘要、情緒分析等
2023-09-04 16:55:251140 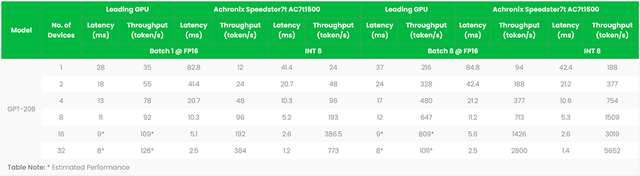
隨著各大公司爭相加入人工智能的潮流,芯片和人才供不應求。初創公司SambaNova(https://sambanova.ai/)聲稱,其新處理器可以幫助公司在幾天內建立并運行自己的大型語言模型
2023-09-27 16:10:511225 AI大模型將AI帶入新的發展階段。AI大模型需要更高效的海量原始數據收集和預處理,更高性能的訓練數據加載和模型數據保存,以及更加及時和精準的行業推理知識庫。以近存計算、向量存儲為代表的AI數據新范式正在蓬勃發展。
2023-10-23 11:26:092173 
適應各種各樣的任務,而無需進一步的訓練。 這就引出了一個問題: 時間序列的基礎模型能像自然語言處理那樣存在嗎? 一個預先訓練了大量時間序列數據的大型模型,是否有可能在未見過的數據上產生準確的預測? 通過
2023-11-03 10:15:221255 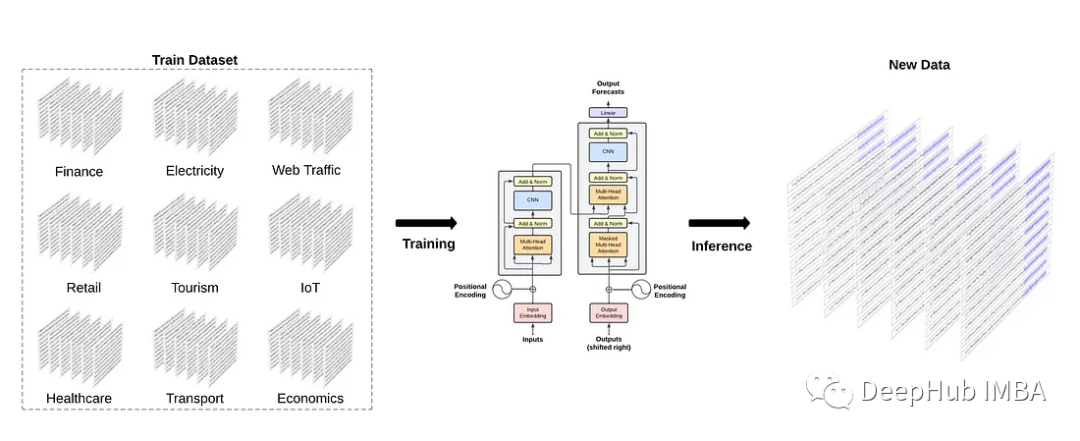
本文基于亞馬遜云科技推出的大語言模型與生成式AI的全家桶:Bedrock對大語言模型進行介紹。大語言模型指的是具有數十億參數(B+)的預訓練語言模型(例如:GPT-3, Bloom, LLaMA)。這種模型可以用于各種自然語言處理任務,如文本生成、機器翻譯和自然語言理解等。
2023-12-04 15:51:461470 隨著人工智能技術的快速發展,大型預訓練模型如GPT-4、BERT等在自然語言處理領域取得了顯著的成功。這些大模型背后的關鍵之一是龐大的數據集,為模型提供了豐富的知識和信息。本文將探討大模型數據集的突破邊界以及未來發展趨勢。
2023-12-06 16:10:441236 大規模語言模型(Large Language Models,LLM),也稱大規模語言模型或大型語言模型,是一種由包含數百億以上參數的深度神經網絡構建的語言模型,使用自監督學習方法通過大量無標注
2023-12-07 11:40:436327 
的人工智能模型,旨在理解和生成自然語言文本。這類模型的核心是深度神經網絡,通過大規模的訓練數據和強大的計算能力,使得模型能夠學習到語言的語法、語境和語義等多層次的信息。 大語言模型的發展歷史可以追溯到深度學習的
2023-12-21 17:53:593103 ,帶你發現大語言模型的潛力,解鎖無限可能。 揭秘大語言模型的魔法 在動手操作之前,我們先來揭秘一下大語言模型的魔法。這些模型通過大量的文本數據進行預訓練,使其具備了超強的理解和生成自然語言的能力。搞懂它的構造和培訓過程
2023-12-29 14:18:591167 大型語言模型(LLM)是基于人工智能的先進模型,經過訓練,它可以密切反映人類自然交流的方式處理和生成人類語言。這些模型利用深度學習技術和大量訓練數據來全面理解語言結構、語法、上下文和語義。
2024-01-03 16:05:252389 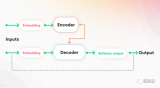
隨著開源預訓練大型語言模型(Large Language Model, LLM )變得更加強大和開放,越來越多的開發者將大語言模型納入到他們的項目中。其中一個關鍵的適應步驟是將領域特定的文檔集成到預訓練模型中,這被稱為微調。
2024-01-04 12:32:391367 
韓國互聯網巨頭Kakao最近宣布開發了一種名為“蜜蜂”(Honeybee)的多模態大型語言模型。這種創新模型能夠同時理解和處理圖像和文本數據,為更豐富的交互和查詢響應提供了可能性。
2024-01-19 16:11:201271 在科技界的矚目下,蘋果再次展示了其在人工智能領域的深厚實力。近日,蘋果宣布將使用自研的大型語言模型(LLM)Ajax來優化即將發布的iOS 18系統。這一創新舉措標志著蘋果在AI領域的進一步投資與探索,預示著iOS 18將帶來前所未有的智能體驗。
2024-05-10 11:20:43987 近日,小米公司官方宣布,其研發的大型語言模型MiLM已成功通過大模型備案,標志著這一技術成果正式邁入了應用階段。MiLM的推出,無疑將為小米的多元化產品線注入新的活力。
2024-05-17 09:31:41919 自2022年,ChatGPT發布之后,大語言模型(LargeLanguageModel),簡稱LLM掀起了一波狂潮。作為學習理解LLM的開始,先來整體理解一下大語言模型。一、發展歷史大語言模型的發展
2024-06-04 08:27:472710 近日,英偉達宣布開源了一款名為Nemotron-4 340B的大型模型,這一壯舉為開發者們打開了通往高性能大型語言模型(LLM)訓練的新天地。該系列模型不僅包含高達3400億參數,而且通過其獨特的架構,為醫療保健、金融、制造、零售等多個行業的商業應用提供了強大的支持。
2024-06-17 14:53:491203 隨著人工智能技術的飛速發展,大語言模型(LLM)已成為自然語言處理領域的核心工具,廣泛應用于智能客服、文本生成、機器翻譯等多個場景。然而,大語言模型的高計算復雜度和資源消耗成為其在實際應用中面臨
2024-07-04 17:32:041976 能力,逐漸成為NLP領域的研究熱點。大語言模型的預訓練是這一技術發展的關鍵步驟,它通過在海量無標簽數據上進行訓練,使模型學習到語言的通用知識,為后續的任務微調奠定基礎。本文將深入探討大語言模型預訓練的基本原理、步驟以及面臨的挑戰。
2024-07-11 10:11:521580 富士通(Fujitsu)與總部位于多倫多與舊金山的頂尖安全及數據隱私人工智能企業Cohere Inc.攜手宣布建立深度戰略合作伙伴關系,共同致力于大型語言模型(LLM)的創新與開發,旨在為企業界帶來前所未有的日語處理能力,進而優化客戶與員工體驗。
2024-07-16 16:55:551290 隨著計算和數據處理變得越來越分散和復雜,AI 的重點正在從初始訓練轉向更高效的AI 推理。Meta 的 Llama3 是功能強大的公開可用的大型語言模型 (LLM)。本次測試采用開源 LLM
2024-07-18 14:28:511401 
在人工智能與語言處理領域,DeepL再次以其創新實力引領潮流,宣布成功推出新一代面向翻譯與編輯應用的大型語言模型。這一里程碑式的進展,不僅鞏固了DeepL作為頂尖語言人工智能公司的地位,更標志著機器翻譯技術向更高質量、更智能化方向邁出了堅實的一步。
2024-07-19 15:56:411228 8月1日,根據各大媒體的廣泛報道,當前全球互聯網已經陷入了優質數據資源的嚴重匱乏,人工智能(AI)領域也正在面臨嚴峻的“數據墻”難題。對專注于研發大型AI模型的機構而言,他們目前面臨的挑戰便是如何尋找到新的數據來源或是能夠持續使用的優質替代品。
2024-08-01 15:20:041123 大型語言模型是2023年生成式人工智能熱潮背后的推動力。然而,它們已經存在了一段時間了。LLM是黑盒AI系統,它使用深度學習對超大數據集進行處理,以理解和生成新文本。現代LLM開始成型于2014年
2024-08-30 12:56:071372 大型語言模型LLMs具有自動化內容創建、提高內容質量及多樣化的潛力,可重塑企業與信息的交互方式。通過利用LLMs,企業能提升工作效率,降低運營成本,并獲得深入洞察。來自EgeGürdeniz
2024-10-13 08:07:52611 
大語言模型的開發是一個復雜且細致的過程,涵蓋了數據準備、模型架構設計、訓練、微調和部署等多個階段。以下是對大語言模型開發步驟的介紹,由AI部落小編整理發布。
2024-11-04 10:14:43953 訓練自己的大型語言模型(LLM)是一個復雜且資源密集的過程,涉及到大量的數據、計算資源和專業知識。以下是訓練LLM模型的一般步驟,以及一些關鍵考慮因素: 定義目標和需求 : 確定你的LLM將用
2024-11-08 09:30:002053 一,前言 ? 在AI領域,訓練一個大型語言模型(LLM)是一個耗時且復雜的過程。幾乎每個做大型語言模型(LLM)訓練的人都會被問到:“從零開始,訓練大語言模型需要多久和花多少錢?”雖然網上有很多
2024-11-08 14:15:541624 
云端語言模型的開發是一個復雜而系統的過程,涉及數據準備、模型選擇、訓練優化、部署應用等多個環節。下面,AI部落小編為您分享云端語言模型的開發方法。
2024-12-02 10:48:50959 在人工智能領域,大語言模型(Large Language Models, LLMs)背后,離不開高效的開發語言和工具的支持。下面,AI部落小編為您介紹大語言模型開發所依賴的主要編程語言。
2024-12-04 11:44:411149 大語言模型開發框架是指用于訓練、推理和部署大型語言模型的軟件工具和庫。下面,AI部落小編為您介紹大語言模型開發框架。
2024-12-06 10:28:43926 開發一個高效、準確的大語言模型是一個復雜且多階段的過程,涉及數據收集與預處理、模型架構設計、訓練與優化、評估與調試等多個環節。接下來,AI部落小編為大家詳細闡述AI大語言模型的開發步驟。
2024-12-19 11:29:221321 要充分發揮語言模型的潛力,有效的語言模型管理非常重要。以下,是對語言模型管理作用的分析,由AI部落小編整理。
2025-01-02 11:06:37618 本文系統性地闡述了大型語言模型(LargeLanguageModels,LLMs)中的解碼策略技術原理及其實踐應用。通過深入分析各類解碼算法的工作機制、性能特征和優化方法,為研究者和工程師提供了全面
2025-02-18 12:00:331182 在當今人工智能飛速發展的時代,大型語言模型(LLMs)正以其強大的語言理解和生成能力,改變著我們的生活和工作方式。在最近的一項研究中,科學家們為了深入了解如何高效地訓練大型語言模型,進行了超過
2025-03-03 11:51:041298 在當今人工智能領域,大型語言模型(LLM)的開發已經成為一個熱門話題。這些模型通過學習大量的文本數據,能夠生成自然語言文本,完成各種復雜的任務,如寫作、翻譯、問答等。https
2025-04-30 18:34:251138 隨著語言模型規模日益龐大,設備端推理變得越來越緩慢且耗能巨大。一個直接且效果出人意料的解決方案是剪除那些對任務貢獻甚微的完整通道(channel)。我們早期的研究提出了一種訓練階段的方法——自壓
2025-07-28 09:36:54443
 電子發燒友App
電子發燒友App









 工商網監
工商網監
評論