K-means 算法是典型的基于距離的聚類(lèi)算法,采用距離作為相似性的評(píng)價(jià)指標(biāo),兩個(gè)對(duì)象的距離越近,其相似度就越大。而簇是由距離靠近的對(duì)象組成的,因此算法目的是得到緊湊并且獨(dú)立的簇。
2022-07-18 09:19:13 3028
3028 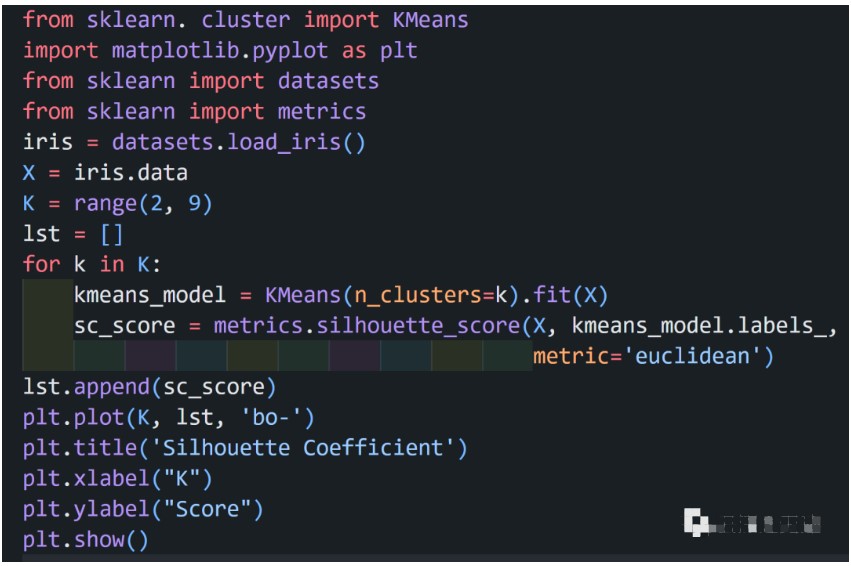
CCD圖像分析方法和預(yù)測(cè)算法???
2012-07-01 15:20:49
FCM聚類(lèi)算法以及改進(jìn)模糊聚類(lèi)算法用于醫(yī)學(xué)圖像分割的matlab源程序
2018-05-11 23:54:19
什么是K-均值聚類(lèi)法?K均值聚類(lèi)算法的MATLAB怎么實(shí)現(xiàn)?
2021-06-10 10:01:25
網(wǎng)絡(luò)測(cè)試 NetWork 分析儀
2024-03-14 22:30:52
推薦一篇博客STM32之CAN ---CAN ID過(guò)濾器分析:http://blog.csdn.net/flydream0/article/details/8148791
2015-10-22 22:23:29
直放站是網(wǎng)絡(luò)優(yōu)化覆蓋的一種解決方案,但由于直放站質(zhì)量或安裝工藝問(wèn)題,可能會(huì)信源基站造成嚴(yán)重的上行干擾。通過(guò)本文介紹的方法,基于OTT/MDT大數(shù)據(jù)的聚類(lèi)特征分析,結(jié)合現(xiàn)網(wǎng)干擾KPI和場(chǎng)景信息,可以
2020-12-03 14:53:55
一.簡(jiǎn)介這個(gè)系列博客博主給大家分享了基于Qualcomm DSP算法集成分析與案例分享,今天再給大家分享份干貨----ThunderSoft公司基于Qualcomm msm8996平臺(tái)的超聲波姿勢(shì)識(shí)別算法實(shí)例分析。二.超聲波姿勢(shì)識(shí)別算法(EL)實(shí)例分析 圖1 圖2圖3圖4圖5圖6
2018-09-28 14:20:58
[源碼和文檔分享]JAVA實(shí)現(xiàn)基于k-means聚類(lèi)算法實(shí)現(xiàn)微博輿情熱點(diǎn)分析系統(tǒng)
2020-06-04 08:21:55
在一個(gè)數(shù)組中使用聚類(lèi)算法找出重復(fù)出現(xiàn)的數(shù)組元素,然后使用其他字符表示,達(dá)到減少儲(chǔ)存空間的作用,有哪位大哥做過(guò)相關(guān)的項(xiàng)目嗎?希望可以賜教一下或者有償提供服務(wù)也可以!
2020-03-09 23:07:45
Mahout – Clustering (聚類(lèi)篇)Leave a reply什么是Mahout?” Apache Mahout? project’s goal is to build a
2021-07-02 07:39:31
基于主元分析與模糊C均值聚類(lèi)的丙烯睛反應(yīng)器優(yōu)化Optimizing Acrylonitrile Reactor Basedo nP rincipalC omponentA nalysisand Fuzzy C-Means Cluster李 永耐 搏 愛(ài) 平(華 東 理 工 大 學(xué) 自 動(dòng)化
2008-10-18 15:38:42 24
24 分析并比較現(xiàn)有網(wǎng)絡(luò)安全態(tài)勢(shì)評(píng)估方法,從網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)出發(fā),引入圖論算法和數(shù)據(jù)挖掘的聚類(lèi)方法,提出一種針對(duì)分布式系統(tǒng)的安全態(tài)勢(shì)評(píng)估方法。利用圖聚類(lèi)算法生成分布式
2009-04-02 09:30:1824 針對(duì)聚類(lèi)算法在金融領(lǐng)域廣泛應(yīng)用的實(shí)際情況,基于銀行客戶數(shù)據(jù)集,對(duì)DBSCAN, K-means和X-means 3種聚類(lèi)算法在執(zhí)行效率、可擴(kuò)展性、異常點(diǎn)檢測(cè)能力等方面進(jìn)行對(duì)比分析,并提出將X-mea
2009-04-06 08:50:1222 分析空間數(shù)據(jù)的特點(diǎn)和用常規(guī)方法進(jìn)行空間數(shù)據(jù)聚類(lèi)分析的難點(diǎn)與不足,提出一種基于改進(jìn)的演化算法空間數(shù)據(jù)聚類(lèi)方法——SDCEA。解決用傳統(tǒng)方法進(jìn)行空間數(shù)據(jù)聚類(lèi)分析時(shí)存在的問(wèn)
2009-04-10 09:29:2428 層次聚類(lèi)方法是聚類(lèi)分析的一個(gè)重要方法。該文利用通用搜索樹(shù)實(shí)現(xiàn)了一種新的層次聚類(lèi)算法,可以把整個(gè)聚類(lèi)過(guò)程中形成的樹(shù)型結(jié)構(gòu)都保存在硬盤(pán)上,支持從宏觀到細(xì)微的分析過(guò)
2009-04-23 10:10:5724 密度聚類(lèi)算法DBSCAN是一種有效的聚類(lèi)分析方法。本文構(gòu)建了網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)模型,并將一種改進(jìn)的基于密度聚類(lèi)的入侵檢測(cè)算法IDBC應(yīng)用于檢測(cè)引擎設(shè)計(jì)。IDBC算法改進(jìn)了網(wǎng)絡(luò)連接記
2009-08-24 08:41:564 提出了一種多密度網(wǎng)格聚類(lèi)算法GDD。該算法主要采用密度閾值遞減的多階段聚類(lèi)技術(shù)提取不同密度的聚類(lèi),使用邊界點(diǎn)處理技術(shù)提高聚類(lèi)精度,同時(shí)對(duì)聚類(lèi)結(jié)果進(jìn)行了人工干預(yù)。G
2009-08-27 14:35:5811 異常檢測(cè)是入侵檢測(cè)中防范新型攻擊的基本手段,本文應(yīng)用增強(qiáng)的K-means 算法對(duì)檢測(cè)數(shù)據(jù)進(jìn)行聚類(lèi)分類(lèi)。計(jì)算機(jī)仿真結(jié)果說(shuō)明了該方法對(duì)入侵檢測(cè)是有
2009-09-03 10:21:3714 基于小波包分析的滾動(dòng)軸承模糊聚類(lèi)方法:用小波包方法構(gòu)造滾動(dòng)軸承狀態(tài)信號(hào)的能量特征向量,通過(guò)模糊聚類(lèi)方法對(duì)滾動(dòng)軸承狀態(tài)進(jìn)行分類(lèi),只需少量的樣本數(shù)據(jù)就能獲得較好的分
2009-10-22 16:39:1513 聚類(lèi)算法研究:對(duì)近年來(lái)聚類(lèi)算法的研究現(xiàn)狀與新進(jìn)展進(jìn)行歸納總結(jié).一方面對(duì)近年來(lái)提出的較有代表性的聚類(lèi)算法,從算法思想、關(guān)鍵技術(shù)和優(yōu)缺點(diǎn)等方面進(jìn)行分析概括;另一方面選擇
2009-10-31 08:57:2418 本文通過(guò)對(duì)常用動(dòng)態(tài)聚類(lèi)方法的分析,提出了基于“約簡(jiǎn)-優(yōu)化”原理的兩階段動(dòng)態(tài)聚類(lèi)算法的框架,此方法克服了動(dòng)態(tài)聚類(lèi)搜索空間過(guò)大的問(wèn)題,提高了聚類(lèi)的精度和效率。
2010-01-09 11:31:1412 對(duì)用戶訪問(wèn)日志數(shù)據(jù)進(jìn)行分析,構(gòu)造會(huì)話-類(lèi)型矩陣,利用概率潛在語(yǔ)義分析模型建立合適的用戶興趣聚類(lèi)分析算法,提高用戶興趣聚類(lèi)精度。實(shí)驗(yàn)結(jié)果驗(yàn)證了該算法的有效性。
2010-01-27 15:39:3819 該文針對(duì)聚類(lèi)問(wèn)題上缺乏骨架研究成果的現(xiàn)狀,分析了聚類(lèi)問(wèn)題的近似骨架特征,設(shè)計(jì)并實(shí)現(xiàn)了近似骨架導(dǎo)向的歸約聚類(lèi)算法。該算法的基本思想是:首先利用現(xiàn)有的啟發(fā)式聚類(lèi)算
2010-02-10 11:48:095 針對(duì)k-means算法存在的不足,提出了一種改進(jìn)算法。 針對(duì)目前供電企業(yè)CRM系統(tǒng)的特點(diǎn)提出了用聚類(lèi)分析方法進(jìn)行客戶群細(xì)分模型設(shè)計(jì),通過(guò)實(shí)驗(yàn)驗(yàn)證了本文提出的k-means改進(jìn)算法的高效性
2010-03-01 15:28:5115 Web文檔聚類(lèi)中k-means算法的改進(jìn)
介紹了Web文檔聚類(lèi)中普遍使用的、基于分割的k-means算法,分析了k-means算法所使用的向量空間模型和基于距離的相似性度量的局限性,從而
2009-09-19 09:17:031233 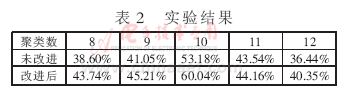
聚類(lèi)算法及聚類(lèi)融合算法研究首先對(duì) 聚類(lèi)算法 的特點(diǎn)進(jìn)行了分析,然后對(duì)聚類(lèi)融合算法進(jìn)行了挖掘。最后得出聚類(lèi)融合算法比聚類(lèi)算法更能得到很好的聚合效果。
2011-08-10 15:08:0233 介紹了K-means 聚類(lèi)算法的目標(biāo)函數(shù)、算法流程,并列舉了一個(gè)實(shí)例,指出了數(shù)據(jù)子集的數(shù)目K、初始聚類(lèi)中心選取、相似性度量和距離矩陣為K-means聚類(lèi)算法的3個(gè)基本參數(shù)。總結(jié)了K-means聚
2012-05-07 14:09:1427 基于最小生成樹(shù)的層次K_means聚類(lèi)算法_賈瑞玉
2017-01-03 15:24:455 基于改進(jìn)K_means算法的海量數(shù)據(jù)分析技術(shù)研究_李歡
2017-01-07 18:39:170 基于聚類(lèi)中心優(yōu)化的k_means最佳聚類(lèi)數(shù)確定方法_賈瑞玉
2017-01-07 18:56:130 混合細(xì)菌覓食和粒子群的k_means聚類(lèi)算法_閆婷
2017-01-07 19:00:390 一種擬人聚類(lèi)算法在PHM聚類(lèi)分析中的應(yīng)用_賀呈磊
2017-01-07 21:39:440 基于SVD的K_means聚類(lèi)協(xié)同過(guò)濾算法_王偉
2017-03-17 08:00:000 基于改進(jìn)K_means聚類(lèi)的欠定盲分離算法_柴文標(biāo)
2017-03-17 10:31:390 基于停留點(diǎn)聚類(lèi)的多粒度熱點(diǎn)區(qū)域分析方法_劉穎
2017-03-16 09:10:372 模糊C均值(Fuzzy C-means)算法簡(jiǎn)稱(chēng)FCM算法,是一種基于目標(biāo)函數(shù)的模糊聚類(lèi)算法,主要用于數(shù)據(jù)的聚類(lèi)分析。有了模糊集合的概念,一個(gè)元素隸屬于模糊集合就不是硬性的了,在聚類(lèi)的問(wèn)題中,可以把
2017-08-28 19:53:5114 鑒于主元分析法的降維特性和模糊C均值聚類(lèi)算法良好的分類(lèi)性能,本文在丙烯睛反應(yīng)器操作參數(shù)的優(yōu)化中,結(jié)合這兩種方法,將主元分析處理后的數(shù)據(jù)作為新的樣本輸入,利用模糊C均值聚類(lèi)算法進(jìn)行優(yōu)化操作。
2017-09-08 15:48:039 聚類(lèi)分析計(jì)算方法主要有如下幾種:劃分法、層次法、密度算法、圖論聚類(lèi)法、網(wǎng)格算法和模型算法。劃分法(partitioning methods),給定一個(gè)有N個(gè)元組或者紀(jì)錄的數(shù)據(jù)集,分裂法將構(gòu)造K個(gè)分組,每一個(gè)分組就代表一個(gè)聚類(lèi),K《N。
2017-10-25 19:18:34178023 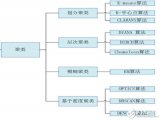
。提出一種基于優(yōu)化粒子群算法的云存儲(chǔ)中大數(shù)據(jù)優(yōu)化聚類(lèi)算法,進(jìn)行了云存儲(chǔ)大數(shù)據(jù)聚類(lèi)的原理分析,在傳統(tǒng)的模糊C均值聚類(lèi)的基礎(chǔ)上,采用粒子群聚類(lèi)算法進(jìn)行大數(shù)據(jù)聚類(lèi)算法改進(jìn)設(shè)計(jì),把數(shù)據(jù)的分割轉(zhuǎn)化為對(duì)空間的分割,得到
2017-10-28 12:46:531 聚類(lèi)分析是從給定的數(shù)據(jù)集中搜索數(shù)據(jù)對(duì)象之間所存在的有價(jià)值的、數(shù)據(jù)分布模式。其主要解決的問(wèn)題就是如何在沒(méi)有得到先驗(yàn)知識(shí)的前提下,實(shí)現(xiàn)滿足這種要求的聚簇聚合。聚類(lèi)分析被廣泛應(yīng)用于金融數(shù)據(jù)的分析、空間數(shù)據(jù)
2017-11-03 09:51:5513291 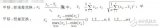
為了提高WSN節(jié)點(diǎn)定位精度,針對(duì)測(cè)距誤差對(duì)定位結(jié)果的影響,提出基于模糊C均值聚類(lèi)的定位算法。算法首先利用多邊定位算法得到若干個(gè)定位結(jié)果,利用模糊C均值聚類(lèi)算法對(duì)定位結(jié)果進(jìn)行聚類(lèi)分析,然后,根據(jù)聚類(lèi)
2017-11-09 17:47:1310 傳統(tǒng)kmeans算法由于初始聚類(lèi)中心的選擇是隨機(jī)的,因此會(huì)使聚類(lèi)結(jié)果不穩(wěn)定。針對(duì)這個(gè)問(wèn)題,提出一種基于離散量改進(jìn)k-means初始聚類(lèi)中心選擇的算法。算法首先將所有對(duì)象作為一個(gè)大類(lèi),然后不斷從對(duì)象
2017-11-20 10:03:232 圖聚類(lèi)是指把圖中相對(duì)連接緊密的頂點(diǎn)及其相關(guān)的邊分組形成一個(gè)子圖的過(guò)程,在包括機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘、模式識(shí)別、圖像分析及生物信息等領(lǐng)域有著廣泛應(yīng)用。但是,隨著大數(shù)據(jù)時(shí)代的到來(lái),圖數(shù)據(jù)海量增長(zhǎng)。面對(duì)廣泛
2017-11-22 11:42:562 預(yù)測(cè)子空間聚類(lèi)PSC算法由于建立在PCA模型下,無(wú)法魯棒地進(jìn)行主元分析,導(dǎo)致在面對(duì)帶有強(qiáng)噪聲的數(shù)據(jù)時(shí),聚類(lèi)性能受到嚴(yán)重影響。為了提高PSC算法對(duì)噪聲的魯棒性,利用近年來(lái)受到廣泛關(guān)注的RPCA分解技術(shù)
2017-11-22 16:53:370 為了解決kmeans算法在Hadoop平臺(tái)下處理海量高維數(shù)據(jù)時(shí)聚類(lèi)效果差,以及已有的改進(jìn)算法不利于并行化等問(wèn)題,提出了一種基于Hash改進(jìn)的并行化方案。將海量高維的數(shù)據(jù)映射到一個(gè)壓縮的標(biāo)識(shí)空間,進(jìn)而
2017-11-24 14:24:322 的詞向量,利用K-means對(duì)詞向量進(jìn)行聚類(lèi),從而實(shí)現(xiàn)話題關(guān)鍵詞的抽取。實(shí)驗(yàn)對(duì)比了基于PLSA和LDA主題模型下的話題抽取效果,發(fā)現(xiàn)本文的話題分析效果優(yōu)于主題模型的方法。同時(shí),采集足夠大量、內(nèi)容足夠豐富的語(yǔ)料,可訓(xùn)練得到泛化能力比較強(qiáng)的模
2017-11-24 15:44:311 針對(duì)傳統(tǒng)的K-means算法無(wú)法預(yù)先明確聚類(lèi)數(shù)目,對(duì)初始聚類(lèi)中心選取敏感且易受離群孤點(diǎn)影響導(dǎo)致聚類(lèi)結(jié)果穩(wěn)定性和準(zhǔn)確性欠佳的問(wèn)題,提出一種改進(jìn)的基于密度的K-means算法。該算法首先基于軌跡數(shù)據(jù)分布
2017-11-25 11:35:380 理論將用戶映射到能表征其用電行為特點(diǎn)的潛在特征空間,然后采用k-means聚類(lèi)算法在潛在特征空間上實(shí)現(xiàn)用電用戶群的細(xì)分聚類(lèi)。特別地引入了地理信息作為矩陣分解的正則化因子,使得學(xué)習(xí)到的潛在特征空間不僅滿足用戶群特征的正交,
2017-11-29 16:39:480 K-means算法是最簡(jiǎn)單的一種聚類(lèi)算法。算法的目的是使各個(gè)樣本與所在類(lèi)均值的誤差平方和達(dá)到最小(這也是評(píng)價(jià)K-means算法最后聚類(lèi)效果的評(píng)價(jià)標(biāo)準(zhǔn))
2017-12-01 14:07:3321912 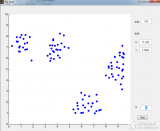
盡可能歸于一類(lèi),而把不相似的樣本劃分到不同的類(lèi)中。硬聚類(lèi)把每個(gè)待識(shí)別的對(duì)象嚴(yán)格的劃分某類(lèi)中,具有非此即彼的性質(zhì),而模糊聚類(lèi)建立了樣本對(duì)類(lèi)別的不確定描述,更能客觀的反應(yīng)客觀世界,從而成為聚類(lèi)分析的主流。
2017-12-01 14:26:0251640 
人工魚(yú)群是一種隨機(jī)搜索優(yōu)化算法,具有較快的收斂速度,對(duì)問(wèn)題的機(jī)理模型與描述無(wú)嚴(yán)格要求,具有廣泛的應(yīng)用范圍。本文在該算法的基礎(chǔ)上,結(jié)合傳統(tǒng)的K-means聚類(lèi)方法,提出了一種新的人工魚(yú)群混合聚類(lèi)算法
2017-12-04 16:18:150 針對(duì)既有歷史數(shù)據(jù)又有流特征的全新應(yīng)用場(chǎng)景,提出了一種基于組特征選擇和流特征的在線特征選擇算法。在對(duì)歷史數(shù)據(jù)的組特征選擇階段,為了彌補(bǔ)單一聚類(lèi)算法的不足,引入聚類(lèi)集成的思想。先利用k-means方法
2017-12-05 11:00:410 傳統(tǒng)的k-means算法采用的是隨機(jī)數(shù)初始化聚類(lèi)中心的方法,這種方法的主要優(yōu)點(diǎn)是能夠快速的產(chǎn)生初始化的聚類(lèi)中心,其主要缺點(diǎn)是初始化的聚類(lèi)中心可能會(huì)同時(shí)出現(xiàn)在同一個(gè)類(lèi)別中,導(dǎo)致迭代次數(shù)過(guò)多,甚至陷入
2017-12-05 18:32:540 的算法。首先,通過(guò)各向異性擴(kuò)散處理圖像;然后,使用一維K-均值對(duì)像素進(jìn)行聚類(lèi);最后,根據(jù)聚類(lèi)結(jié)果和先驗(yàn)知識(shí)將像素值修改為最佳類(lèi)中心像素值。理論分析表明該算法可以使圖像的峰值信噪比( PSNR)達(dá)到最大值。實(shí)驗(yàn)結(jié)果表明:所
2017-12-06 16:44:110 本文提出了一種新的基于流行距離的譜聚類(lèi)算法,這是一種新型的聚類(lèi)分析算法。不僅能夠?qū)θ我獾姆且?guī)則形狀的樣本空間進(jìn)行聚類(lèi),而且能獲得全局最優(yōu)解。文章以聚類(lèi)算法的相似性度量作為切入點(diǎn),對(duì)傳統(tǒng)的相似性測(cè)度
2017-12-07 14:53:033 k-means算法自提出50多年來(lái),在聚類(lèi)分析中得到了廣泛應(yīng)用,但是,k-means算法存在一個(gè)突出的問(wèn)題,即需要預(yù)先設(shè)定聚類(lèi)數(shù)目。所以,本文針對(duì)如何自動(dòng)獲取k-means的聚類(lèi)數(shù)目進(jìn)行了研究
2017-12-13 10:49:440 針對(duì)原始K-means聚類(lèi)算法受初始聚類(lèi)中心影響過(guò)大以及容易陷入局部最優(yōu)的不足,提出一種基于改進(jìn)布谷鳥(niǎo)搜索(cs)的K-means聚類(lèi)算法(ACS-K-means)。其中,自適應(yīng)CS( ACS)算法
2017-12-13 17:24:063 在基于視角加權(quán)的多視角聚類(lèi)中,每個(gè)視角的權(quán)重取值對(duì)聚類(lèi)結(jié)果的精度都有著重要的影V向。針對(duì)此問(wèn)題,提出熵加權(quán)多視角核K-means( EWKKM)算法,通過(guò)給每個(gè)視角分配一個(gè)合理的權(quán)值來(lái)降低噪聲視角或
2017-12-17 09:57:111 針對(duì)傳統(tǒng)的二分類(lèi)音頻隱寫(xiě)分析方法對(duì)未知隱寫(xiě)方法的適應(yīng)性較差的問(wèn)題,提出了一種基于模糊C均值(FCM)聚類(lèi)與單類(lèi)支持向量機(jī)(OC-SVM)的音頻隱寫(xiě)分析方法。在訓(xùn)練過(guò)程中,首先對(duì)訓(xùn)練音頻進(jìn)行特征提取
2017-12-21 13:30:510 針對(duì)大數(shù)據(jù)環(huán)境下K-means聚類(lèi)算法聚類(lèi)精度不足和收斂速度慢的問(wèn)題,提出一種基于優(yōu)化抽樣聚類(lèi)的K-means算法(OSCK)。首先,該算法從海量數(shù)據(jù)中概率抽樣多個(gè)樣本;其次,基于最佳聚類(lèi)中心的歐氏
2017-12-22 15:47:184 針對(duì)傳統(tǒng)模糊C一均值( FCM)聚類(lèi)算法初始聚類(lèi)中心不確定,且需要人為預(yù)先設(shè)定聚類(lèi)類(lèi)別數(shù),從而導(dǎo)致結(jié)果不準(zhǔn)確的問(wèn)題,提出了一種基于中點(diǎn)密度函數(shù)的模糊聚類(lèi)算法。首先,結(jié)合逐步回歸思想作為初始聚類(lèi)中心
2017-12-26 15:54:200 通過(guò)對(duì)基于K-means聚類(lèi)的缺失值填充算法的改進(jìn),文中提出了基于距離最大化和缺失數(shù)據(jù)聚類(lèi)的填充算法。首先,針對(duì)原填充算法需要提前輸入聚類(lèi)個(gè)數(shù)這一缺點(diǎn),設(shè)計(jì)了改進(jìn)的K-means聚類(lèi)算法:使用數(shù)據(jù)間
2018-01-09 10:56:560 區(qū)別于傳統(tǒng)用戶用電行為分析方法,提出一種以聚類(lèi)算法為基礎(chǔ)的雙層聚類(lèi)分析方法。該方法結(jié)合給出的內(nèi)、外層變隨機(jī)設(shè)置為有目的選取初始聚類(lèi)中心的選取規(guī)則,解決了聚類(lèi)算法受初始聚類(lèi)中心隨機(jī)選取的影響,其收斂
2018-02-11 10:32:139 與分類(lèi)不同,分類(lèi)是示例式學(xué)習(xí),要求分類(lèi)前明確各個(gè)類(lèi)別,并斷言每個(gè)元素映射到一個(gè)類(lèi)別,而聚類(lèi)是觀察式學(xué)習(xí),在聚類(lèi)前可以不知道類(lèi)別甚至不給定類(lèi)別數(shù)量,是無(wú)監(jiān)督學(xué)習(xí)的一種。目前聚類(lèi)廣泛應(yīng)用于統(tǒng)計(jì)學(xué)、生物學(xué)、數(shù)據(jù)庫(kù)技術(shù)和市場(chǎng)營(yíng)銷(xiāo)等領(lǐng)域,相應(yīng)的算法也非常的多。
2018-02-12 16:42:3516368 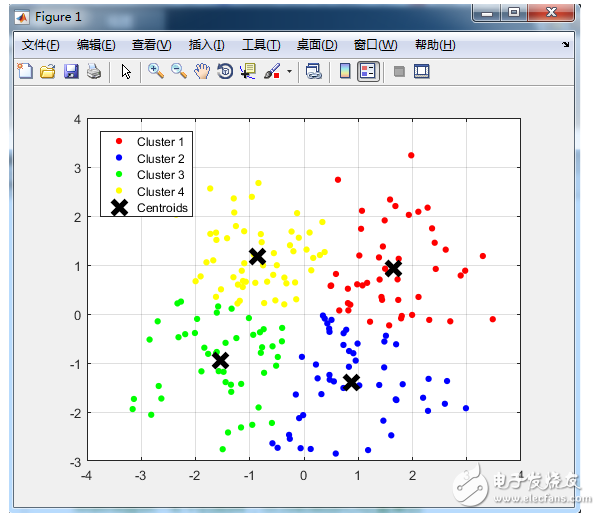
針對(duì)譜聚類(lèi)存在計(jì)算瓶頸的問(wèn)題,提出了一種快速的集成算法,稱(chēng)為間接譜聚類(lèi)。它首先運(yùn)用K-Means算法對(duì)數(shù)據(jù)集進(jìn)行過(guò)分聚類(lèi),然后把每個(gè)過(guò)分簇看成一個(gè)基本對(duì)象,最后在過(guò)分簇的級(jí)別上利用標(biāo)準(zhǔn)譜聚類(lèi)來(lái)完成
2018-02-24 14:43:590 本文開(kāi)始介紹了聚類(lèi)算法概念,其次闡述了聚類(lèi)算法的分類(lèi),最后詳細(xì)介紹了聚類(lèi)算法中密度DBSCAN的相關(guān)概況。
2018-04-26 10:56:4122613 
Matlab 提供系列函數(shù)用于聚類(lèi)分析,歸納起來(lái)具體方法有如下: 方法一:直接聚類(lèi),利用 clusterdata 函數(shù)對(duì)樣本數(shù)據(jù)進(jìn)行一次聚類(lèi),其缺點(diǎn)為可供用戶選擇的面較窄,不能更改距離的計(jì)算方法,該方法的使用者無(wú)需了解聚類(lèi)的原理和過(guò)程,但是聚類(lèi)效果受限制。
2018-05-18 15:04:007727 無(wú)監(jiān)督學(xué)習(xí)是機(jī)器學(xué)習(xí)技術(shù)中的一類(lèi),用于發(fā)現(xiàn)數(shù)據(jù)中的模式。本文介紹用Python進(jìn)行無(wú)監(jiān)督學(xué)習(xí)的幾種聚類(lèi)算法,包括K-Means聚類(lèi)、分層聚類(lèi)、t-SNE聚類(lèi)、DBSCAN聚類(lèi)等。
2018-05-27 09:59:1331502 
K-Means是十大經(jīng)典數(shù)據(jù)挖掘算法之一。K-Means和KNN(K鄰近)看上去都是K打頭,但卻是不同種類(lèi)的算法。kNN是監(jiān)督學(xué)習(xí)中的分類(lèi)算法,而K-Means則是非監(jiān)督學(xué)習(xí)中的聚類(lèi)算法;二者相同之處是均利用近鄰信息來(lái)標(biāo)注類(lèi)別。
2018-07-05 14:18:005429 針對(duì)傳統(tǒng)K-means型算法的“均勻效應(yīng)”問(wèn)題,提出一種基于概率模型的聚類(lèi)算法。首先,提出一個(gè)描述非均勻數(shù)據(jù)簇的高斯混合分布模型,該模型允許數(shù)據(jù)集中同時(shí)包含密度和大小存在差異的簇;其次,推導(dǎo)了非均勻
2018-12-13 10:57:5910 K-means算法是被廣泛使用的一種聚類(lèi)算法,傳統(tǒng)的-means算法中初始聚類(lèi)中心的選擇具有隨機(jī)性,易使算法陷入局部最優(yōu),聚類(lèi)結(jié)果不穩(wěn)定。針對(duì)此問(wèn)題,引入多維網(wǎng)格空間的思想,首先將樣本集映射到一個(gè)
2018-12-13 17:56:551 聚類(lèi)分析是將研究對(duì)象分為相對(duì)同質(zhì)的群組的統(tǒng)計(jì)分析技術(shù),聚類(lèi)分析的核心就是發(fā)現(xiàn)有用的對(duì)象簇。K-means聚類(lèi)算法由于具有出色的速度和良好的可擴(kuò)展性,一直備受廣大學(xué)者的關(guān)注。然而,傳統(tǒng)的K-means
2018-12-20 10:28:2910 在本文中,我們將討論一個(gè)金融機(jī)構(gòu)的實(shí)際使用案例,該案例使用-聚類(lèi)clustering(一種流行的機(jī)器學(xué)習(xí)算法)來(lái)為其客戶群定制其產(chǎn)品。
2020-10-12 13:58:053370 
聚類(lèi)或聚類(lèi)分析是無(wú)監(jiān)督學(xué)習(xí)問(wèn)題。它通常被用作數(shù)據(jù)分析技術(shù),用于發(fā)現(xiàn)數(shù)據(jù)中的有趣模式,例如基于其行為的客戶群。有許多聚類(lèi)算法可供選擇,對(duì)于所有情況,沒(méi)有單一的最佳聚類(lèi)算法。相反,最好探索一系列聚類(lèi)算法
2021-03-12 18:23:432746 度推薦算法。采用改進(jìn)的蜂群算法來(lái)優(yōu)化K- means++聚類(lèi)的中心點(diǎn),使聚類(lèi)中心在整個(gè)數(shù)據(jù)內(nèi)達(dá)到最優(yōu),并對(duì)聚類(lèi)結(jié)果進(jìn)行集成,使得聚類(lèi)得到進(jìn)一步優(yōu)化。根據(jù)聚類(lèi)結(jié)果,在同一類(lèi)中采用改進(jìn)的用戶相似度算法來(lái)優(yōu)化傳統(tǒng)相似度算法,
2021-03-18 11:17:1110 現(xiàn)有聚類(lèi)算法面向高維稀疏數(shù)據(jù)時(shí)多數(shù)未考慮類(lèi)簇可重疊和離群點(diǎn)的存在,導(dǎo)致聚類(lèi)效果不理想。為此,提出一種可重疊子空間K- Means聚類(lèi)算法。設(shè)計(jì)類(lèi)簇子空間計(jì)算策略,在聚類(lèi)過(guò)程中動(dòng)態(tài)更新每個(gè)類(lèi)簇的屬性
2021-03-25 14:07:1013 在對(duì)旅游景點(diǎn)的評(píng)論挖掘中常以多景點(diǎn)橫向?qū)Ρ葹檠芯壳腥朦c(diǎn),為景點(diǎn)間的橫向比較及游人選擇景點(diǎn)服務(wù),而較少針對(duì)單一景點(diǎn)深入分析,為景點(diǎn)單要素精準(zhǔn)提升服務(wù)。以留園為例,按照構(gòu)成元素構(gòu)建聚類(lèi),并基于領(lǐng)域詞典
2021-04-15 15:33:117 將改進(jìn)的 DBSCAN聚類(lèi)算法與 Spark平臺(tái)并行聚類(lèi)計(jì)算理論相結(jié)合,對(duì)海量數(shù)據(jù)采用分而治之的辦法進(jìn)行聚類(lèi)處理,大幅減小了算法對(duì)內(nèi)存的占用率。實(shí)驗(yàn)仿真結(jié)果表明,所提出的并行計(jì)算方法能夠有效緩解內(nèi)存不足的問(wèn)題,并且該方法也能夠用來(lái)評(píng)價(jià) DBSCAN聚類(lèi)算法在Hadoφ平臺(tái)下的聚類(lèi)分析效果,還能對(duì)兩種聚類(lèi)
2021-04-26 15:14:499 聚類(lèi)分析是數(shù)據(jù)挖掘與分析最重要的方法之一。它把相似的數(shù)據(jù)對(duì)象歸類(lèi)到一個(gè)簇,把不同的數(shù)據(jù)對(duì)象盡可能分到不同的簇。其中k- means聚類(lèi)算法,由于其簡(jiǎn)單性和高效性,被廣泛運(yùn)用于解決各種現(xiàn)實(shí)問(wèn)題,例如
2021-04-28 16:43:551 為實(shí)現(xiàn)復(fù)雜網(wǎng)絡(luò)的快速分析,提出一種基于聚類(lèi)質(zhì)量的改進(jìn)非負(fù)矩陣分解(INMF)算法,將其用于動(dòng)態(tài)社區(qū)檢測(cè)。從理論分析角度證明了演化譜聚類(lèi)、INMF和模塊密度優(yōu)化之間的等價(jià)性,并基于該等價(jià)性,在不增加
2021-05-25 17:02:424 為降低并均衡無(wú)線傳感器網(wǎng)絡(luò)(WSN)中傳感器節(jié)點(diǎn)的能量消耗,提出一種基于最優(yōu)傳輸距離和 K-means聚類(lèi)的WSN分簇算法。根據(jù)層次聚類(lèi)算法建立聚類(lèi)特征樹(shù),將聚類(lèi)特征樹(shù)中的葉節(jié)點(diǎn)視為一個(gè)簇,并使每個(gè)
2021-05-26 14:50:172 隨著大數(shù)據(jù)時(shí)代的來(lái)臨,如何對(duì)海量高維數(shù)據(jù)進(jìn)行有效的聚類(lèi)分析并充分利用,已成為當(dāng)下的熱門(mén)研究課題。傳統(tǒng)的聚類(lèi)算法在處理高維數(shù)據(jù)時(shí),聚類(lèi)結(jié)果的精確度和穩(wěn)定性較低,而子空間聚類(lèi)算法通過(guò)分割原始數(shù)據(jù)的特征
2021-05-28 16:26:370 隨著大數(shù)據(jù)時(shí)代的來(lái)臨,如何對(duì)海量高維數(shù)據(jù)進(jìn)行有效的聚類(lèi)分析并充分利用,已成為當(dāng)下的熱門(mén)研究課題。傳統(tǒng)的聚類(lèi)算法在處理高維數(shù)據(jù)時(shí),聚類(lèi)結(jié)果的精確度和穩(wěn)定性較低,而子空間聚類(lèi)算法通過(guò)分割原始數(shù)據(jù)的特征
2021-05-28 16:26:373 信息,必將成為云”能否持續(xù)穩(wěn)定運(yùn)行的核心問(wèn)題。據(jù)此,文中提出了一種基于時(shí)序性告警的新型聚類(lèi)算法。算法利用設(shè)定時(shí)間窗口內(nèi)兩兩告警之間時(shí)間差的關(guān)系,構(gòu)造告警之間新的關(guān)系矩陣,再利用K- means算法對(duì)關(guān)系矩陣中的列向量
2021-06-17 14:34:524 K-means 是一種聚類(lèi)算法,且對(duì)于數(shù)據(jù)科學(xué)家而言,是簡(jiǎn)單且熱門(mén)的無(wú)監(jiān)督式機(jī)器學(xué)習(xí)(ML)算法之一。
2022-06-06 11:53:555202 在聚類(lèi)技術(shù)領(lǐng)域中,K-means可能是最常見(jiàn)和經(jīng)常使用的技術(shù)之一。K-means使用迭代細(xì)化方法,基于用戶定義的集群數(shù)量(由變量K表示)和數(shù)據(jù)集來(lái)產(chǎn)生其最終聚類(lèi)。例如,如果將K設(shè)置為3,則數(shù)據(jù)集將分組為3個(gè)群集,如果將K設(shè)置為4,則將數(shù)據(jù)分組為4個(gè)群集,依此類(lèi)推。
2022-10-28 14:25:212219 分享一篇關(guān)于聚類(lèi)的文章:10種聚類(lèi)算法和Python代碼。
2023-01-07 09:33:382537 聚類(lèi)的效果,通常無(wú)訓(xùn)練集與測(cè)試集的劃分。 什么是聚類(lèi)?所謂數(shù)據(jù)聚類(lèi)是指根據(jù)數(shù)據(jù)的內(nèi)在性質(zhì)將數(shù)據(jù)分成一些聚合類(lèi),每一聚合類(lèi)中的元素盡可能具有相同的特性,不同聚合類(lèi)之間的特性差別盡可能大。?聚類(lèi)分析的目的是分析
2023-02-10 08:45:051180 繼續(xù)講解! 程序來(lái)啦! 最后看一下程序示例!看看如何用K-means算法實(shí)現(xiàn)數(shù)據(jù)聚類(lèi)的過(guò)程。程序很簡(jiǎn)單,側(cè)重讓大家了解和掌握 K-means算法 聚類(lèi)的過(guò)程! 看代碼吧!程序由三部
2023-02-11 07:20:04859 分享一篇關(guān)于聚類(lèi)的文章: **10種聚類(lèi)算法和Python代碼** 。文末提供`<span>jupyter notebook</span>`的完整代碼獲取方式。
聚類(lèi)或聚類(lèi)分析是無(wú)監(jiān)督學(xué)習(xí)問(wèn)題。它通常被用作數(shù)據(jù)分析技術(shù),用于發(fā)現(xiàn)數(shù)據(jù)中的有趣模式,例如基于其行為的客戶群。
2023-02-20 13:57:471331 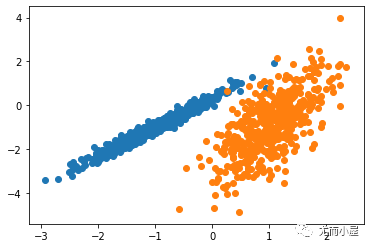
分享一篇關(guān)于聚類(lèi)的文章: **10種聚類(lèi)算法和Python代碼** 。文末提供`<span>jupyter notebook</span>`的完整代碼獲取方式。
聚類(lèi)或聚類(lèi)分析是無(wú)監(jiān)督學(xué)習(xí)問(wèn)題。它通常被用作數(shù)據(jù)分析技術(shù),用于發(fā)現(xiàn)數(shù)據(jù)中的有趣模式,例如基于其行為的客戶群。
2023-02-20 13:57:511532 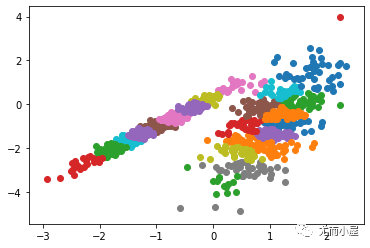
分享一篇關(guān)于聚類(lèi)的文章: **10種聚類(lèi)算法和Python代碼** 。文末提供`<span>jupyter notebook</span>`的完整代碼獲取方式。
聚類(lèi)或聚類(lèi)分析是無(wú)監(jiān)督學(xué)習(xí)問(wèn)題。它通常被用作數(shù)據(jù)分析技術(shù),用于發(fā)現(xiàn)數(shù)據(jù)中的有趣模式,例如基于其行為的客戶群。
2023-02-20 13:57:551719 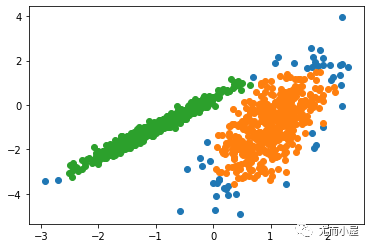
分享一篇關(guān)于聚類(lèi)的文章: **10種聚類(lèi)算法和Python代碼** 。文末提供`<span>jupyter notebook</span>`的完整代碼獲取方式。
聚類(lèi)或聚類(lèi)分析是無(wú)監(jiān)督學(xué)習(xí)問(wèn)題。它通常被用作數(shù)據(jù)分析技術(shù),用于發(fā)現(xiàn)數(shù)據(jù)中的有趣模式,例如基于其行為的客戶群。
2023-02-20 13:57:591899 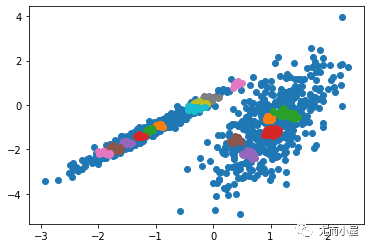
次聚類(lèi)是基因表達(dá)數(shù)據(jù)分析中應(yīng)用最廣泛的聚類(lèi)方法。層次聚類(lèi)在數(shù)據(jù)點(diǎn)之間構(gòu)建層次結(jié)構(gòu),它根據(jù)層次樹(shù)中的分支定義不同的類(lèi)群。許多單細(xì)胞轉(zhuǎn)錄組數(shù)據(jù)的聚類(lèi)算法都是基于層次聚類(lèi)或?qū)哟?b class="flag-6" style="color: red">聚類(lèi)作為分析的步驟之一。
2023-05-24 10:45:382427 
作者:凱魯嘎吉來(lái)源:博客園這篇文章對(duì)現(xiàn)有的深度聚類(lèi)算法進(jìn)行全面綜述與總結(jié)。現(xiàn)有的深度聚類(lèi)算法大都由聚類(lèi)損失與網(wǎng)絡(luò)損失兩部分構(gòu)成,博客從兩個(gè)視角總結(jié)現(xiàn)有的深度聚類(lèi)算法,即聚類(lèi)模型與神經(jīng)網(wǎng)絡(luò)模型。1.
2023-01-13 11:11:521728 
使用SBC ToolBox云平臺(tái)時(shí)間序列分析模塊探索基因集在不同時(shí)間點(diǎn)的表達(dá)趨勢(shì),使用c-means算法對(duì)基因集進(jìn)行聚類(lèi)分群,尋找出表達(dá)趨勢(shì)一致的基因集。
2023-09-20 16:52:482178 
時(shí)段等。這些信息可以對(duì)城市規(guī)劃、交通管理、公共安全等方面具有重要的指導(dǎo)意義。而為了實(shí)現(xiàn)人員軌跡分析,我們需要使用一些專(zhuān)門(mén)的算法和技術(shù)。 下面是幾種常用的人員軌跡分析算法: 1. 基于密度的聚類(lèi)算法: 基于密度的聚類(lèi)
2024-09-26 10:42:441419
 電子發(fā)燒友App
電子發(fā)燒友App








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論