 K-means聚類算法指南
K-means聚類算法指南

假設您想根據內容和主題對數百(或數千)個文檔進行分類,或者您希望出于某種原因將不同的圖像組合在一起。或者更重要的是,假設你有相同的數據已經被分類但是你想要挑戰這個標簽,您想知道數據分類是否有意義,或者是否可以改進。
好吧,我的建議是你對數據進行聚類。信息經常會因為冗余等各種原因變得模糊不清,而將數據分組到具有相似特征的群集(群集)中是一種有效的方式。
聚類是一種廣泛用于查找具有相似特征的觀察組(稱為聚類)的技術。此過程不是由特定目的驅動的,這意味著您不必專門告訴您的算法如何對這些觀察進行分組,因為它是獨立進行(組有機地形成)分組的。結果是,同一組中的觀察(或數據點)在它們之間比另一組中的其他觀察更相似。目標是獲得盡可能相似的同一組中的數據點,并使不同組中的數據點盡可能不相似。
K-means非常適合探索性分析,非常適合了解您的數據并提供幾乎所有數據類型的見解。無論是圖像、圖形還是文本,K-means都非常靈活,幾乎可以滿足所有需求。
無監督學習中的搖滾明星之一
聚類(包括K均值聚類)是一種用于數據分類的無監督學習技術。
無監督學習意味著沒有輸出變量來指導學習過程(沒有這個或那個,沒有對錯),數據由算法來探索以發現模式。我們只觀察這些特征,但沒有對結果進行確定的測量值,因為我們想要找出它們。
與監督學習不同的是,非監督學習技術不使用帶標簽的數據,算法需要自己去發現數據中的結構。
在聚類技術領域中,K-means可能是最常見和經常使用的技術之一。K-means使用迭代細化方法,基于用戶定義的集群數量(由變量K表示)和數據集來產生其最終聚類。例如,如果將K設置為3,則數據集將分組為3個群集,如果將K設置為4,則將數據分組為4個群集,依此類推。
K-means從任意選擇的數據點開始,作為數據組的提議方法,并迭代地重新計算新的均值,以便收斂到數據點的最終聚類。
但是,如果您只提供一個值(K),算法如何決定如何對數據進行分組?當您定義K的值時,您實際上是在告訴算法您需要多少均值或質心(如果設置K = 3,則創建了3個均值或質心,其中包含3個聚類)。質心是表示聚類中心的數據點(均值),它可能不一定是數據集的成員。
這就是算法的工作原理:
K個質心是隨機創建的(基于預定義的K值)
K-means將數據集中的每個數據點分配到最近的質心(最小化它們之間的歐幾里德距離),這意味著如果數據點比任何其他質心更接近該群集的質心,則認為該數據點位于特定集群中。
然后K-means通過獲取分配給該質心集群的所有數據點的平均值來重新計算質心,從而減少與前一步驟相關的集群內總方差。K均值中的“均值”是指對數據求均值并找到新的質心。
該算法在步驟2和3之間迭代,直到滿足一些標準(例如最小化數據點與其對應質心的距離之和,達到最大迭代次數,質心值不變或數據點沒有變化集群)
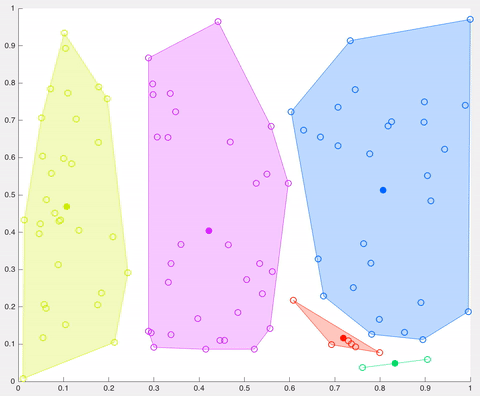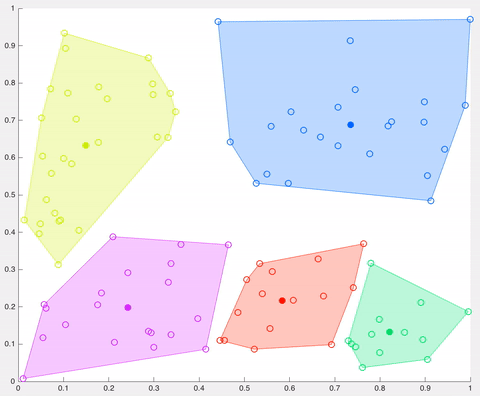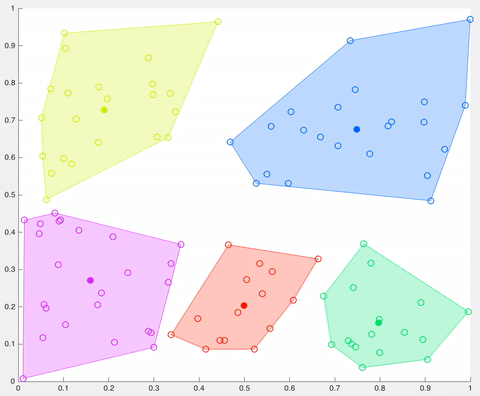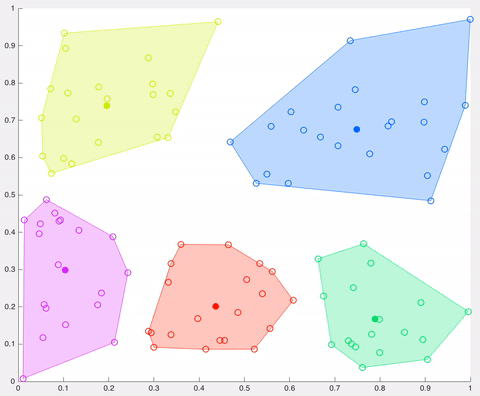
在該示例中,經過5次迭代之后,計算的質心保持相同,并且數據點不再交換集群(算法收斂)。這里,每個質心都顯示為一個深色的數據點。
運行此算法的初始結果可能不是最佳結果,并且使用不同的隨機起始質心重新運行它可能提供更好的性能(不同的初始對象可能產生不同的聚類結果)。出于這個原因,通常的做法是使用不同的起點多次運行算法,并評估不同的初始化方法(例如Forgy或Kaufman方法)。
但另一個問題出現了:你如何知道K的正確值,或者要創建多少個質心?對此這個問題沒有普遍的答案,雖然質心或集群的最佳數量還不是先驗的,但是存在不同的方法來估計它。一種常用的方法是測試不同數量的集群并測量得到的誤差平方之和,選擇K值,在該值處增加將導致誤差和減小的非常小,而減小時將急劇增加誤差和。定義最佳集群數的這一點被稱為“肘點”,可以用作一個視覺度量來找到K值的最佳選擇。
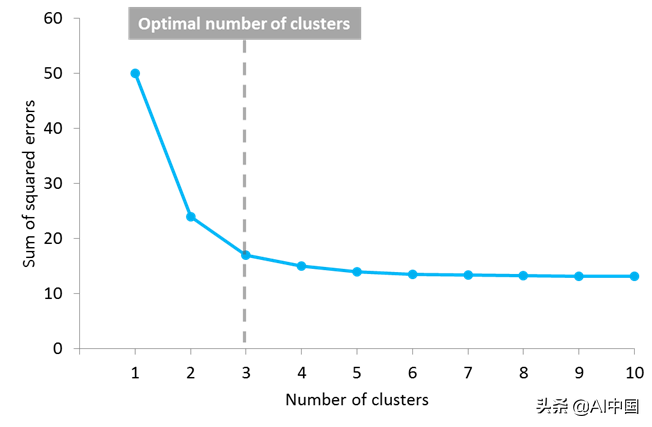
在此示例中,肘點位于3個集群中
K-means是您的數據科學工具包中必不可少的,有幾個原因。首先,它易于實現并帶來高效的性能。畢竟,您只需要定義一個參數(K的值)來查看結果。它的速度很快并且可以很好地處理大型數據集,使其能夠處理當前的海量數據。它非常靈活,可以與幾乎任何數據類型一起使用,其結果易于解釋,并且比其他算法更易于解釋。此外,該算法非常受歡迎,您幾乎可以在任何學科中找到用例和實現。
但凡事都有不利的一面
K-means也存在一些缺點。第一個是你需要定義集群的數量,這個決定會嚴重影響結果。此外,由于初始質心的位置是隨機的,因此結果可能不具有可比性并且顯示缺乏一致性。K-means生成具有統一大小的聚類(每個聚類具有大致相同的觀察量),即使數據可能以不同的方式運行,并且它對異常值和噪聲數據非常敏感。此外,它假設每個聚類中的數據點被建模為位于該聚類質心周圍的球體內(球形限制),但是當違反此條件(或任何先前的條件)時,算法可以以非直觀的方式運行。
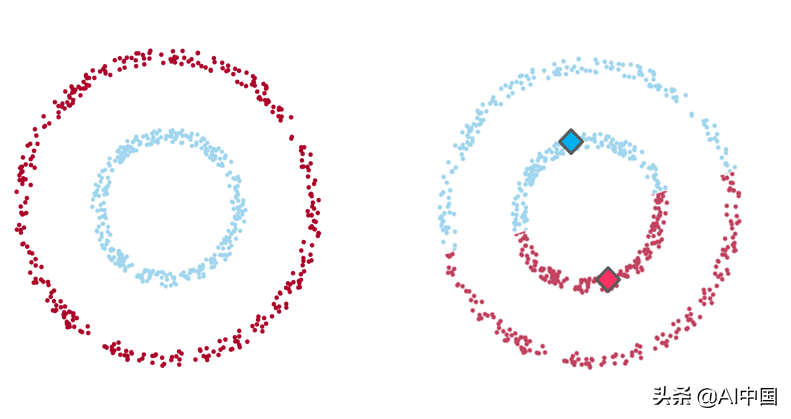
例1
示例1:在左側,數據的直觀聚類,兩組數據點之間有明顯分離(由一個較大的數據點包圍的一個小環的形狀)。在右側,通過K均值算法(K值為2)聚類的相同數據點,其中每個質心用菱形表示。如您所見,該算法無法識別直觀的聚類。
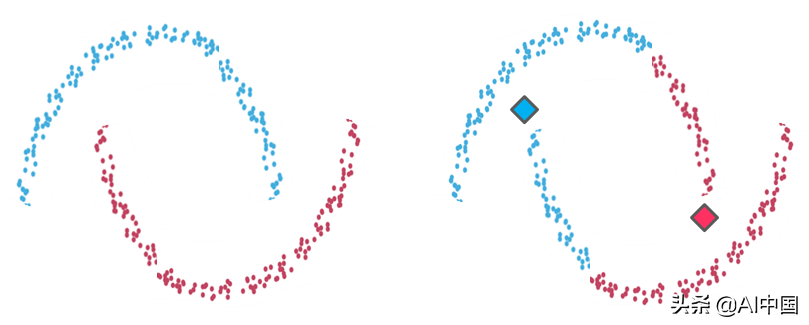
例2
示例2:左側是兩個可識別數據組的聚類。在右側,K-means聚類在相同數據點上的結果不適合直觀的聚類。與示例1的情況一樣,由于算法的球形限制,K-means創建的分區不能反映我們在視覺上識別的內容。它試圖找到圍繞它們的整個數據球體的質心,并且當聚類的幾何形狀偏離球體時表現很差。

例3
示例3:再次,在左側有兩個清晰的集群(一個小而緊密的數據組和另一個較大且分散的集群),K-means無法識別(右側)。這里,為了平衡兩個數據組之間的集群內距離并生成具有統一大小的集群,該算法混合兩個數據組并創建2個不代表數據集的人工集群。
有趣的是,無論這些數據點之間的關系多么明顯,K-means都不允許彼此遠離的數據點共享同一個集群。
現在做什么?
事情是現實生活中的數據幾乎總是復雜、雜亂無章和嘈雜的。現實世界中的情況很少能反映出明確的條件,即可立即應用這些類型的算法。在K-means算法的情況下,預計至少有一個假設會被違反,因此我們不僅要識別它,還需要知道在這種情況下該做什么。
好消息是還有其他選擇,可以糾正缺陷。例如,將數據轉換為極坐標可以解決我們在示例1中描述的球形限制。如果發現嚴重的限制,還可以考慮使用其他類型的聚類算法。可能的方法是使用基于密度或基于層次的算法,這些算法修復了一些K均值限制(但也有其自身的局限性)。
總之,K-means是一種具有大量潛在用途的精彩算法,因此它具有多種功能,幾乎可用于任何類型的數據分組。但是從來沒有免費的午餐:如果你不想被引導到錯誤的結果,你需要了解它的假設和它的運作方式。
審核編輯 :李倩
-
聚類算法
+關注
關注
2文章
118瀏覽量
12548 -
K-means
+關注
關注
0文章
28瀏覽量
11782
原文標題:一個完整的K-means聚類算法指南!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
算法工程師需要具備哪些技能?
使用K-means算法進行異常偵測
1688品類API:熱門行業榜單,選品指南!

DLP472TE 0.47 英寸 4K 超高清數字微鏡器件設計指南
看懂C語言程序中的內聚和耦合
ADC的采樣濾波算法利用卡爾曼濾波算法
K8s存儲類設計與Ceph集成實戰
聚辰EEPROM定義座艙存儲新標桿?

光伏建筑一體化BIPV:透射率與光伏發電效率的應用研究




 工商網監
工商網監
評論