今年以來可以說是最熱的賽道,而AI大模型對算力的需求爆發(fā),也帶動了AI服務(wù)器中各種類型的芯片需求,所以本期核芯觀察將關(guān)注ChatGPT背后所用到的算力芯片產(chǎn)業(yè)鏈,梳理目前主流類型的AI算力芯片產(chǎn)業(yè)上下游企業(yè)以及運作模式。 ? 接上期Chat
2023-05-28 00:34:00 3883
3883 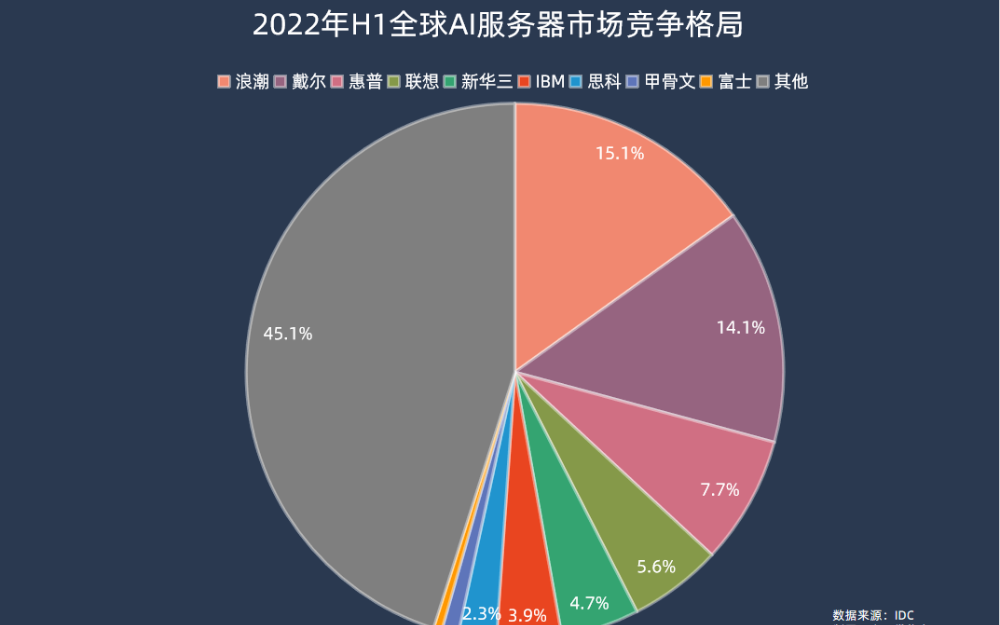
今年以來可以說是最熱的賽道,而AI大模型對算力的需求爆發(fā),也帶動了AI服務(wù)器中各種類型的芯片需求,所以本期核芯觀察將關(guān)注ChatGPT背后所用到的算力芯片產(chǎn)業(yè)鏈,梳理目前主流類型的AI算力芯片產(chǎn)業(yè)上下游企業(yè)以及運作模式。 ? 接上期Chat
2023-06-04 05:05:433560 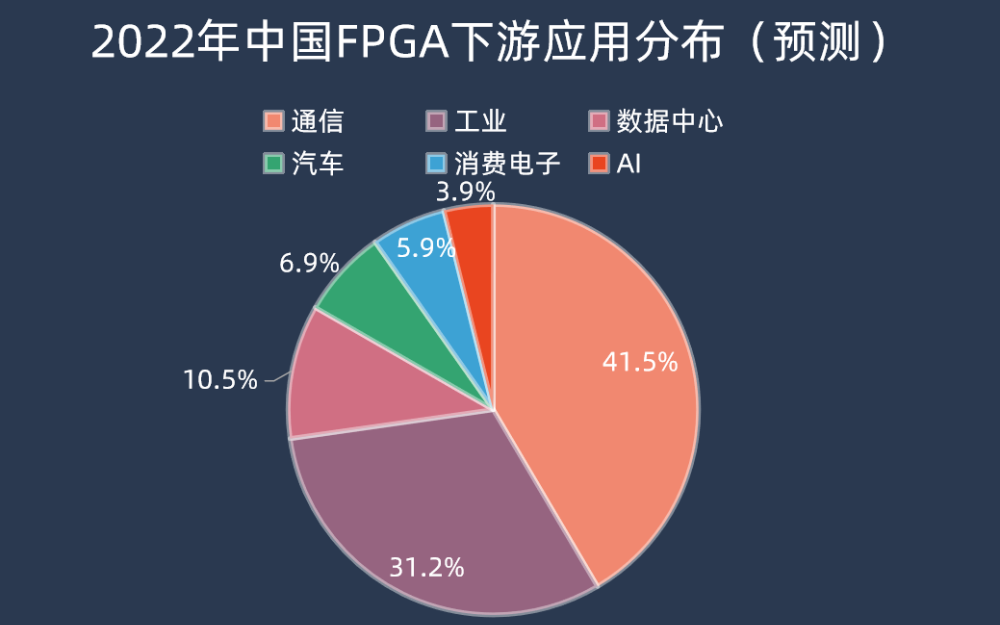
的縮寫,即每秒所能夠進行的浮點運算數(shù)目(每秒浮點運算量)。 ? 算力可以分為通用算力、智能算力和超算算力。早前通用算力占整體算力的比重達到90%以上,近些年隨著人工智能技術(shù)的發(fā)展,智能算力規(guī)模迅速增長。從需求層面看,2022年,中國智能算力規(guī)模為268百億億次/秒(EFLOPS),已經(jīng)超過通用算力規(guī)
2024-02-06 00:08:008229 我用的是xinlinx spartan6 FPGA,我想知道它的IP核RAM是與FPGA獨立的,只是集成在了一起呢,還是占用了FPGA的資源來形成一個RAM?如果我以ROM的形式調(diào)用該IP核,在
2013-01-10 17:19:11
語言編程的,因此可以根據(jù)圖像處理的實際需求,動態(tài)地調(diào)整硬件資源的使用。這使得FPGA在處理圖像時能夠?qū)崿F(xiàn)更高的能效比,從而降低系統(tǒng)的功耗。這對于需要長時間運行的圖像處理系統(tǒng)尤為重要。
五、可重配置性
2024-10-09 14:36:26
有誰知道現(xiàn)在國內(nèi)外有哪些公司賣FPGA的圖像處理相關(guān)的IP核?
2015-04-28 21:34:24
進行處理其給出結(jié)果的延時是兩行圖像的時間。還有這個算子法和現(xiàn)在卷積神經(jīng)網(wǎng)絡(luò)中最前面的卷積層運算是類似的。
FPGA中的Block Ram是重要和稀缺資源,能緩存的圖像數(shù)據(jù)行數(shù)是有限的,所以這個
2024-06-12 16:26:07
inference在設(shè)備端上做。嵌入式設(shè)備的特點是算力不強、memory小。可以通過對神經(jīng)網(wǎng)絡(luò)做量化來降load和省memory,但有時可能memory還吃緊,就需要對神經(jīng)網(wǎng)絡(luò)在memory使用上做進一步優(yōu)化
2021-12-23 06:16:40
卷積神經(jīng)網(wǎng)絡(luò)為什么適合圖像處理?
2022-09-08 10:23:10
的突破。AlexNet 在百萬 量級的 ImageNet數(shù)據(jù)集上對于圖像分類的精度大幅 度超過傳統(tǒng)方法,一舉摘下了視覺領(lǐng)域競賽 ILSVRC2012的桂冠。自 AlexNet之后,研究者從卷積神經(jīng)網(wǎng) 絡(luò)
2022-08-02 10:39:39
融合和視頻處理技術(shù),從而提高汽車的安全性能。
目標識別跟蹤:RK3588可提供6TOPS高性能NPU算力,支持深度學(xué)習(xí)算法和人臉識別等應(yīng)用,并可通過PCIe 3.0高速接口從FPGA端接收高幀率圖像
2024-07-17 10:49:03
本帖最后由 enlinux123 于 2014-11-7 16:41 編輯
想?yún)⒓蛹夹g(shù)培訓(xùn)學(xué)習(xí)可以加張工2232894713最近一段時間一直在研究基于FPGA的圖像處理,乘著這個機會和大家交流
2014-11-05 09:50:00
* 16 * 16(INT8 MAC) * 2 * 0 55G / 1024 = 17.6 TOPS
如果enable winograd INT8的算力可以提高一倍,winograd 要求卷積核必須是3*3
2023-09-19 08:11:10
膨脹處理,其中B是一個卷積模板或卷積核,其形狀可以為正方形或圓形,通過模板B與圖像A進行卷積計算,掃描圖像中的每一個像素點,用模板元素與二值圖像元素做“與”運算,如果都為0,那么目標像素點為0,否則
2018-11-23 16:39:34
已下是rx580顯卡算力9-11 Mh 沒有開啟計算模式,挖幾分種重啟自動開啟,計算模式只支持WIN1022-28 Mh 原版BIOS,開啟時序,并設(shè)置超頻29-32 Mh 正常算力,卡體質(zhì)不同算力
2021-07-23 06:59:09
sTm32可以做卷積核濾波圖片嗎
2023-09-21 07:17:26
,能夠?qū)崿F(xiàn)高效地圖像檢測、識別、分類等AI應(yīng)用。早前在該架構(gòu)基礎(chǔ)之上,深鑒科技做出了第一代FPGA產(chǎn)品,已經(jīng)在攝像頭市場實現(xiàn)了批量出貨。 DPU計算核心采用全流水設(shè)計結(jié)構(gòu)設(shè)計,內(nèi)部集成了大量的卷積運算器
2018-03-23 15:27:20
,得到訓(xùn)練參數(shù)2、利用開發(fā)板arm與FPGA聯(lián)合的特性,在arm端實現(xiàn)圖像預(yù)處理已經(jīng)卷積核神經(jīng)網(wǎng)絡(luò)的池化、激活函數(shù)和全連接,在FPGA端實現(xiàn)卷積運算3、對整個系統(tǒng)進行調(diào)試。4、在基本實現(xiàn)系統(tǒng)的基礎(chǔ)上
2018-12-19 11:37:22
項目名稱:基于cortex-m系列核和卷積神經(jīng)網(wǎng)絡(luò)算法的圖像識別試用計劃:本人在圖像識別領(lǐng)域有三年多的學(xué)習(xí)和開發(fā)經(jīng)驗,曾利用nesys4ddr的fpga開發(fā)板,設(shè)計過基于cortex-m3的軟核
2019-04-09 14:12:24
。將一個卷積核在(x,y)空間像素點的輸出,和它前后的幾個卷積核上的輸出做權(quán)重歸一化。使用了重疊的最大值池化層。3x3的池化核,步長為2,因此產(chǎn)生了重疊池化效應(yīng),使得一個像素點在多個池化結(jié)果中均有輸出
2018-06-07 17:26:31
車載以太網(wǎng)在數(shù)據(jù)發(fā)送過程中的編碼,4b-3b-2t-pam3。其中在3b-2t的時候,導(dǎo)致頻率降為原來的2/3,所以100base-T1的mdi傳輸頻率為66.7MHz;對于1000base-T1,同樣采用4b-3b-2t-pam3的編碼方式,為什么傳輸頻率為750MHz呢?
2023-12-13 11:24:39
in Network。AlexNet中卷積層用線性卷積核對圖像進行內(nèi)積運算,在每個局部輸出后面跟著一個非線性的激活函數(shù),最終得到的叫做特征函數(shù)。而這種卷積核是一種廣義線性模型,進行特征提取時隱含地假設(shè)了特征是線性
2018-05-08 15:57:47
,這就是IP核。
IP核一般原廠做一些資源開放,定制的IP核一般就要收費了。像做圖像、音視頻處理,AI等,開發(fā)可能會涉及到這一方面。IP核有優(yōu)點也有缺點:IP核往往不能跨平臺使用;IP核不透明,看不到內(nèi)部核心代碼等。
有關(guān)IP核有這方面資料可以分享探討交流學(xué)習(xí)。
2024-04-29 21:01:16
最近行業(yè)都在說“算力是AI的命門”,但國產(chǎn)芯片真的能接住這波需求嗎?
前陣子接觸到海思昇騰910B,實測下來有點超出預(yù)期——7nm工藝下算力直接拉到256 TFLOPS,比上一代提升了40%,但功耗
2025-10-27 13:12:41
,減少了硬件資源的占用。該方案在Cyclone II FPGA 芯片EP2C35F484 上實現(xiàn),占用 20 070 個邏輯單元(少于60% 的資源),系統(tǒng)最高時鐘達到100 MHz 。與傳統(tǒng)的128 位數(shù)據(jù)路徑設(shè)計相比,更方便與處理器進行接口。
2012-08-11 11:53:10
結(jié)構(gòu),即在內(nèi)存中開辟一個整數(shù)數(shù)組來進行計數(shù),但是在FPGA 中定義數(shù)組是非常消耗資源的,尤其是當數(shù)組成員的位寬很大時。例如用觸發(fā)器來統(tǒng)計256 灰度的720p 圖像的直方圖,將消耗4000 個邏輯單元
2012-05-14 12:37:37
FPGA 上實現(xiàn)卷積神經(jīng)網(wǎng)絡(luò) (CNN)。CNN 是一類深度神經(jīng)網(wǎng)絡(luò),在處理大規(guī)模圖像識別任務(wù)以及與機器學(xué)習(xí)類似的其他問題方面已大獲成功。在當前案例中,針對在 FPGA 上實現(xiàn) CNN 做一個可行性研究
2019-06-19 07:24:41
背景介紹數(shù)據(jù)、算法和算力是人工智能技術(shù)的三大要素。其中,算力體現(xiàn)著人工智能(AI)技術(shù)具體實現(xiàn)的能力,實現(xiàn)載體主要有CPU、GPU、FPGA和ASIC四類器件。CPU基于馮諾依曼架構(gòu),雖然靈活,卻
2021-07-26 06:47:30
大俠好,歡迎來到FPGA技術(shù)江湖,江湖偌大,相見即是緣分。大俠可以關(guān)注FPGA技術(shù)江湖,在“闖蕩江湖”、\"行俠仗義\"欄里獲取其他感興趣的資源,或者一起煮酒言歡。
今天
2023-05-25 18:08:24
目前市場上炙手可熱的芯片礦機 當數(shù)芯動 A10PRO , 7g 版本的 算力750m 功耗 1300w 這款機器廠家出廠時預(yù)定價格在 48900 左右那時候定的客戶到如今 機器價格已經(jīng)漲到
2021-07-23 07:39:58
的可以參考一下,歡迎一起交流學(xué)習(xí)。話不多說,上貨。
使用FPGA做圖像處理優(yōu)勢最關(guān)鍵的就是:FPGA能進行實時流水線運算,能達到最高的實時性。因此在一些對實時性要求非常高的應(yīng)用領(lǐng)域,做圖像處理
2023-06-08 15:55:34
。
內(nèi)置獨立NPU, 算力達 1TOPS,可用于輕量級人工智能應(yīng)用。
支持幾乎全格式的H.264解碼,支持1080p@60fps的解碼,支持4K@30fps的H.265解碼,以及1080p@60fps
2024-12-24 15:07:12
需要大量向量計算的任務(wù)中表現(xiàn)出色,例如圖像和視頻處理等。(三)通用的 AI 算力融合方式 :以 CPU 核融合方式提供原生 AI 算力。生態(tài)對接 :實現(xiàn)與所有主流 AI 生態(tài)的快速對接,方便
2025-01-06 17:37:36
The HFA1110 is a unity gain closed loop buffer that achieves-3dB bandwidth of 750MHz, while
2009-01-08 18:21:29 12
12 ????內(nèi)嵌ARM核的FPGA芯片EPXA10及其在圖像驅(qū)動和處理方面的應(yīng)用 ????
2006-04-16 23:33:071544 FPGA調(diào)查顯示門陣列的沒落,Xilinx和Altera仍占統(tǒng)計地位
一個由EETimes、Piper-Jaffray和位于Sandia National Labs的FPGA Mission Assurance Center組織的FPGA用戶調(diào)查顯示,已經(jīng)預(yù)言了很長時間的
2008-10-17 08:32:59719 騰視科技AI算力模組TS-SG-SM9系列搭載算能高集成度處理器CV186AH/BM1688片,功耗低、算力強、接口豐富、兼容性好。7.2-16TOPS INT8算力,兼容INT4/INT8
2025-10-20 10:16:03
基于FPGA硬件實現(xiàn)固定倍率的圖像縮放,將2維卷積運算分解成2次1維卷積運算,對輸入原始圖像像素先進行行方向的卷積,再進行列方向的卷積,從而得到輸出圖像像素。把圖像縮放過程
2012-05-09 15:52:0435 基于FPGA的經(jīng)濟型MPEG2運動圖像編碼器IP核設(shè)計
2016-08-30 15:10:149 a) 通過反復(fù)堆疊3*3的小型卷積核和2*2的最大池化層構(gòu)建。 b) VGGNet擁有5段卷積,每一段卷積網(wǎng)絡(luò)都會將圖像的邊長縮小一半,但將卷積通道數(shù)翻倍:64 —>128 —>256 —>512 —>512 。這樣圖像的面積縮小到1/4,輸出通道數(shù)變?yōu)?倍,輸出tensor的總尺寸每次縮小一半。
2018-08-21 15:10:274308 
我們都知道,卷積核的作用在于特征的抽取,越是大的卷積核尺寸就意味著更大的感受野,當然隨之而來的是更多的參數(shù)。
2018-08-24 11:10:3523694 本文以適合FPGA實現(xiàn)為目的,提出一種具有計算規(guī)則性的快速二值圖像連通域標記算法。與傳統(tǒng)的二值圖像標記算法相比,該算法具有運算簡單性、規(guī)則性和可擴展性的特點,適合以FPGA實現(xiàn)。選用在100MHz
2018-11-14 10:07:007716 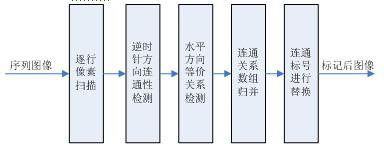
電子發(fā)燒友網(wǎng)為你提供TI(ti)DS90CR288A相關(guān)產(chǎn)品參數(shù)、數(shù)據(jù)手冊,更有DS90CR288A的引腳圖、接線圖、封裝手冊、中文資料、英文資料,DS90CR288A真值表,DS90CR288A管腳等資料,希望可以幫助到廣大的電子工程師們。
2018-10-16 11:10:12

與 FCN 通常CNN網(wǎng)絡(luò)在卷積層之后會接上若干個全連接層, 將卷積層產(chǎn)生的特征圖(feature map)映射成一個固定長度的特征向量。以AlexNet為代表的經(jīng)典CNN結(jié)構(gòu)適合于圖像級的分類和回歸
2018-09-26 17:22:02920 在許多疾病的病理學(xué)診斷中,細胞核的形狀、特征的變化是病變發(fā)生與否的重要依據(jù),利用計算機智能分割出病理組織切片中的細胞核能為疾病診斷提供更多的參考。本研究將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用在乳腺癌病理組織切片圖像中
2018-11-14 17:34:056 /APC連接器。BGO747(FCO,SCO)用于CATV光節(jié)點系統(tǒng),工作在40~750MHz頻率范圍內(nèi)。工作時放大器電源腳和光二極管偏壓腳連接24V(DC)電壓,其模塊包括一個適合波長1290
2019-03-29 09:05:01601 2.0GHz,G90T主頻達到2.05GHz;GPU方面搭載了720Hz Mali-G76 MC4,主頻高達800Mhz,并且內(nèi)置雙核APU,支持10GB LPDDR4x運存,頻率最高可達2133MHz,可為手機帶來強勁性能,安兔兔跑分超22萬。
2019-08-04 10:16:082753 HPC 是算力坊內(nèi)生的生態(tài)系統(tǒng)代幣,支撐著算力坊項目的運行,是算力坊生態(tài)系統(tǒng)中重要的支付載體, HPC 將算力坊數(shù)萬臺礦機算力為價值擔保,提供可靠的去中心化加密貨幣算力服務(wù)。
2019-08-26 11:51:582096 ARM Cortex-A15,主頻1.5GHz
DSP C66x,主頻750MHz
2個雙核ARM Cortex-M4,主頻213MHz
2個雙核PRU,主頻200MHz
2019-12-03 14:57:346253 
ARM Cortex-A15,主頻1.5GHz
DSP C66x,主頻750MHz
2個雙核ARM Cortex-M4,主頻213MHz
2個雙核PRU,主頻200MHz
2019-12-03 14:50:474863 
RM Cortex-A15,主頻1.5GHz
DSP C66x,主頻750MHz
2個雙核ARM Cortex-M4,主頻213MHz
2個雙核PRU,主頻200MHz
2019-12-03 16:27:216617 
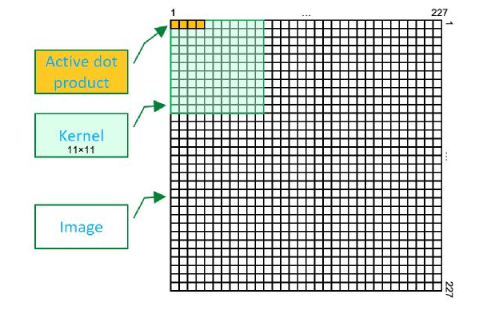
圖像卷積操作(convolution),或稱為核操作(kernel),是進行圖像處理的一種常用手段,
2020-03-13 16:44:033791 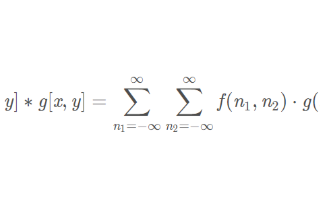
9月11日,在2020騰訊全球數(shù)字生態(tài)大會上,騰訊云副總裁劉煜宏透露,騰訊云大數(shù)據(jù)平臺的算力彈性資源池達500萬核,每日分析任務(wù)數(shù)達1500萬,每日實時計算次數(shù)超過40萬億,能支持超過一萬億維度
2020-09-11 10:53:24978 ,采集卡上使用DS90CR288進行并轉(zhuǎn)串處理,這種方式占用FPGA管腳資源多。當傳輸24bit RGB信號時,需要使用24(信號)+4(同步控制)+1(時鐘)=29個管腳,而使用lvds傳輸,使用altlvds_tx核,只需要5對lvds信號即可,共占用10個管腳。
2020-12-30 16:57:2725 ,英偉達的崛起離不開 AI 產(chǎn)業(yè)的發(fā)展。英偉達主攻的 GPU 在算力上約超出 CPU 2~3 個數(shù)量級,與 AI 產(chǎn)業(yè)結(jié)合效果更佳,這也是英偉達能夠在當前市場以底層算力芯片贏得高速發(fā)展的重要原因。 ? 但是,算力更強的 GPU 芯片也暴露出另一個顯著問題:利用率低。 ? “AWS 在
2020-12-30 17:05:095800 
本文通過通俗易懂的文字解釋了圖像卷積、邊緣提取以及濾波去燥的概念及其分類。? 一、圖像卷積 現(xiàn)在有一張圖片 f(x,y) 和一個kernel核 w(a,b)。 卷積(Convolution):卷積
2021-04-30 09:38:516433 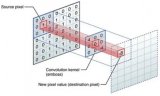
為更好地提取煙霧圖像的全局特征,提出一種基于膨脹卷積和稠密連接的煙霧識別方法。依次堆疊膨脹率不同的膨脹卷積,擴大卷積核的感受野,使得卷積核能夠感知更廣泛的煙霧圖像區(qū)域,在不同膨脹卷積層之間設(shè)計稠密
2021-05-14 11:32:369 ?在FPGA上生成8086指令兼容的軟核以及外設(shè)并在此基礎(chǔ)上跑通pc機上吃豆子PACMAN游戲項目(深圳市優(yōu)能電源技術(shù)有限公司)-在FPGA上生成8086指令兼容的軟核以及外設(shè),并在此基礎(chǔ)上跑通pc機上吃豆子PACMAN游戲項目
2021-09-16 12:17:3713 本期開小灶Heyro將帶領(lǐng)大家進入下一趟旅程——基于卷積神經(jīng)網(wǎng)絡(luò)的圖像分類算法講解,從而幫助大家了解在卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)下衍生出的被用于圖像分類的經(jīng)典算法。
2022-04-06 14:50:366370 由基于CPU芯片的服務(wù)器所提供的算力,主要用于基礎(chǔ)通用計算。日常提到的云計算、邊緣計算等都屬于基礎(chǔ)算力,它為移動計算、物聯(lián)網(wǎng)等提供計算支持。基礎(chǔ)算力占整體算力的比重由2016年的95%下降至2020年的57%,但其依舊是算力主力。
2022-05-13 14:36:579612 算力網(wǎng)絡(luò)的核心特征,是它通過算力,實現(xiàn)了對算力資源、網(wǎng)絡(luò)資源的全面接管,可以讓網(wǎng)絡(luò)實時感知用戶的算力需求,以及自身的算力狀態(tài)。經(jīng)過分析后,算力網(wǎng)絡(luò)可以調(diào)度不同位置、不同類型的算力資源,為用戶服務(wù)。
2022-08-17 09:32:236766 給出目前的框圖,如下所示,外部輸入25M,由Interface的PLL生成150/750MHz(離開148.5MHz有點偏差也沒關(guān)系),hdmi_ip接收前面測試的RGB數(shù)據(jù)后,模擬HDMI協(xié)議
2022-09-06 10:16:383822 算力網(wǎng)絡(luò)是“一種根據(jù)業(yè)務(wù)需求,在云、網(wǎng)、邊之間按需分配和靈活調(diào)度計算資源、存儲資源以及網(wǎng)絡(luò)資源的新型信息基礎(chǔ)設(shè)施”。
2022-12-14 15:48:008793 算力網(wǎng)絡(luò)的核心特征,是它通過算力,實現(xiàn)了對算力資源、網(wǎng)絡(luò)資源的全面接管,可以讓網(wǎng)絡(luò)實時感知用戶的算力需求,以及自身的算力狀態(tài)。經(jīng)過分析后,算力網(wǎng)絡(luò)可以調(diào)度不同位置、不同類型的算力資源,為用戶服務(wù)。
2022-12-14 16:09:055809 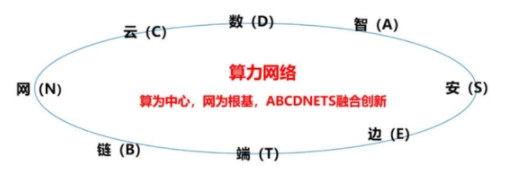
卷積神經(jīng)網(wǎng)絡(luò)(CNN)在圖像和語音領(lǐng)域使用廣泛,神經(jīng)網(wǎng)絡(luò)算法相比傳統(tǒng)的算法消耗了更多算力。為了探索對計算的優(yōu)化,我們進一步看到 AlexNet 模型(一種 CNN)的推理過程的各個層的計算資源消耗占比。
2023-05-09 11:37:202628 
算力服務(wù)層基于分布式微服務(wù)架構(gòu),支持應(yīng)用解構(gòu)成原子化功能 組件并組成算法庫,由 API Gateway統(tǒng)一調(diào)度,實現(xiàn) 原子化算法按需實例 化。 算力平臺層將算力資源抽象描述形成算力能力模板并對算力
2023-05-25 16:47:213 電子發(fā)燒友網(wǎng)站提供《PyTorch教程8.1之深度卷積神經(jīng)網(wǎng)絡(luò)(AlexNet).pdf》資料免費下載
2023-06-05 10:09:580 的選擇 智能算力水平是國家智能化、數(shù)字化發(fā)展水平的集中體現(xiàn),是數(shù)字化應(yīng)用建設(shè)及發(fā)展的底層基礎(chǔ)。《2021-2022全球計算力指數(shù)評估報告》數(shù)據(jù)顯示,美國、日本、德國、英國等15個國家在AI算力上的支出占總算力支出比重從2016年的9%增加到了12%,預(yù)計到2025年
2023-06-05 10:40:022434 
英偉達A100的算力是多少? 英偉達A100的算力為19.5 TFLOPS(浮點運算每秒19.5萬億次)。 V100 用 300W 功率提供了 7.8TFLOPS 的推斷算力,有 210 億個晶體管
2023-08-08 15:28:4543608 不同領(lǐng)域的應(yīng)用。 1.圖像識別 卷積神經(jīng)網(wǎng)絡(luò)最早應(yīng)用在圖像識別領(lǐng)域。其核心思想是通過多層濾波器來提取圖像的特征。卷積層主要包括卷積核、填充和步幅。卷積核通過滑動窗口的方式在輸入圖像上進行卷積運算,生成特征圖。填充可以用來控
2023-08-21 16:49:295898 各種任務(wù)表現(xiàn)出色。在本文中,我們將介紹常見的卷積神經(jīng)網(wǎng)絡(luò)模型,包括LeNet、AlexNet、VGG、GoogLeNet、ResNet、Inception和Xception。 1. LeNet
2023-08-21 17:11:415641 打造一個AI大模型究竟需要多少算力?公開數(shù)據(jù)顯示,ChatGPT初始所需的算力就是1萬塊英偉達A100(一種AI芯片),價格超過7億元。后續(xù)的調(diào)優(yōu)訓(xùn)練每天消耗算力大概是3640PFLOPS,需要7至8個算力達500PFLOPS的數(shù)據(jù)中心支持,建設(shè)成本約為三、四十億元。
2023-08-23 16:09:081460 打造全國算力一張“網(wǎng)”
2023-12-15 18:56:192310 
英偉達H200的算力非常強大。作為新一代AI芯片,H200在性能上有了顯著的提升,能夠處理復(fù)雜的AI任務(wù)和大數(shù)據(jù)分析。然而,具體的算力數(shù)值可能因芯片配置、應(yīng)用場景以及優(yōu)化方向等因素而有所不同。
2024-03-07 16:15:044436 目標是使上海市智能算力總量超越30EFlops,占比達總計算力的50%以上。同時,要求算力網(wǎng)絡(luò)的節(jié)點間單向時間延遲穩(wěn)定在1毫秒之內(nèi),領(lǐng)先存儲的容量份額增長至50%以上。
2024-03-25 16:33:471459 4月11日,2024年度中興通訊云網(wǎng)生態(tài)峰會在南京成功舉辦,本屆峰會以“合作共贏,數(shù)智同興”為主題。期間,中興通訊高級副總裁張萬春發(fā)表了題為《全棧智算基礎(chǔ)設(shè)施,解鎖新質(zhì)生產(chǎn)力》的主題演講。
2024-04-15 18:26:281650 摩爾線程創(chuàng)始人兼CEO張建中在會上透露,為了滿足國內(nèi)對AI算力的迫切需求,他們正在積極尋求與國內(nèi)頂尖科研機構(gòu)的深度合作,共同推動更大規(guī)模的AI智算集群項目。
2024-05-10 16:36:052065 徐冰認為,國產(chǎn)芯片崛起以及算力商品化帶來的投資價值,使中美算力差距有望逐步縮小。只要中國持續(xù)在算力研發(fā)上投入資金及資源,便能拉近與美國的算力差距。
2024-05-28 11:25:082337 卷積操作 卷積神經(jīng)網(wǎng)絡(luò)的核心是卷積操作。卷積操作是一種數(shù)學(xué)運算,用于提取圖像中的局部特征。在圖像識別中,卷積操作通過滑動窗口(或稱為濾波器、卷積核)在輸入圖像上進行掃描,計算窗口內(nèi)像素值與濾波器的加權(quán)和,生成新的特征圖(Feature Map)。 1.2 激活函數(shù) 卷積層的輸出通常會通過
2024-07-02 14:28:152804 和應(yīng)用范圍。 一、卷積神經(jīng)網(wǎng)絡(luò)的基本原理 1. 卷積層(Convolutional Layer) 卷積層是CNN的核心組成部分,其主要功能是提取圖像中的局部特征。卷積層由多個卷積核(或濾波器)組成,每個卷積核負責提取圖像中的一個特定特征。卷積核在輸入圖像上滑動,計算卷積核與圖像的局部區(qū)域的
2024-07-02 15:30:582803 分類。 1. 卷積神經(jīng)網(wǎng)絡(luò)的基本概念 1.1 卷積層(Convolutional Layer) 卷積層是CNN中的核心組件,用于提取圖像特征。卷積層由多個卷積核(或濾波器)組成,每個卷積核負責提取圖像中的特定特征。卷積操作通過將卷積核在輸入圖像上滑動,計算卷積核與圖像的局部區(qū)域的點積,生成特
2024-07-03 10:51:081132 在《算力系列基礎(chǔ)篇——算力101:從零開始了解算力》中,相信各位粉絲初步了解到人工智能的“發(fā)動機”和核心驅(qū)動力:算力!算力!算力!(重要的事情說三遍)今天,一起學(xué)習(xí)一下計算機性能是如何影響算力
2024-07-11 08:04:57104 
經(jīng)典卷積網(wǎng)絡(luò)模型在深度學(xué)習(xí)領(lǐng)域,尤其是在計算機視覺任務(wù)中,扮演著舉足輕重的角色。這些模型通過不斷演進和創(chuàng)新,推動了圖像處理、目標檢測、圖像生成、語義分割等多個領(lǐng)域的發(fā)展。以下將詳細探討幾個經(jīng)典的卷積
2024-07-11 11:45:281961 卷積運算是圖像處理中一種極其重要的操作,廣泛應(yīng)用于圖像濾波、邊緣檢測、特征提取等多個方面。它基于一個核(或稱為卷積核、濾波器)與圖像進行相乘并求和的過程,通過這一操作可以實現(xiàn)對圖像的平滑、銳化、邊緣檢測等多種效果。本文將從卷積運算的基本概念、原理、應(yīng)用以及代碼示例等方面進行詳細闡述。
2024-07-11 15:15:464942 N為一個奇數(shù),如3、5、7等。奇數(shù)大小的卷積核有助于確定一個中心像素點,便于計算。 大小選擇 :卷積核的大小決定了濾波器的范圍。較大的卷積核可以覆蓋更多的像素點,從而更好地平滑圖像,但也可能導(dǎo)致圖像細節(jié)丟失過多。因此,在
2024-09-29 09:29:402463 高斯卷積核函數(shù)在圖像采樣中的意義主要體現(xiàn)在以下幾個方面: 1. 平滑處理與去噪 平滑圖像 :高斯卷積核函數(shù)通過其權(quán)重分布特性,即中心像素點權(quán)重最高,周圍像素點權(quán)重逐漸降低,實現(xiàn)了對圖像的平滑處理
2024-09-29 09:33:471176 FPGA(現(xiàn)場可編程門陣列)加速深度學(xué)習(xí)模型是當前硬件加速領(lǐng)域的一個熱門研究方向。以下是一些FPGA加速深度學(xué)習(xí)模型的案例: 一、基于FPGA的AlexNet卷積運算加速 項目名稱
2024-10-25 09:22:031856 隨著AI技術(shù)的廣泛應(yīng)用,算力需求呈現(xiàn)出爆發(fā)式增長。AI算力租賃作為一種新興的服務(wù)模式,正逐漸成為企業(yè)獲取算力資源的重要途徑。
2024-10-31 10:31:381215 企業(yè)AI算力租賃是指企業(yè)通過互聯(lián)網(wǎng)向?qū)I(yè)的算力提供商租用所需的計算資源,以滿足其AI應(yīng)用的需求。以下是對企業(yè)AI算力租賃的介紹,由AI部落小編為您整理。
2024-11-14 09:30:463028 ),是深度學(xué)習(xí)的代表算法之一。 一、基本原理 卷積運算 卷積運算是卷積神經(jīng)網(wǎng)絡(luò)的核心,用于提取圖像中的局部特征。 定義卷積核:卷積核是一個小的矩陣,用于在輸入圖像上滑動,提取局部特征。 滑動窗口:將卷積核在輸入圖像上滑動,每次滑動一個像素點。 計算卷積:將卷積核與輸入圖像的局部區(qū)域進行逐元素相乘,然
2024-11-15 14:47:482526 1月7日,南京信易達發(fā)布了旗下最新算力平臺“C-MOM智能算力融合平臺V3.0”,并更新了全新的UI視覺與交互系統(tǒng)。 該平臺集成了HPC超算中心、AI智算中心、C-AMC應(yīng)用中心、C-DCM數(shù)據(jù)中心
2025-01-08 10:56:451379 
像素行與像素窗口 一幅圖像是由一個個像素點構(gòu)成的,對于一幅480*272大小的圖片來說,其寬度是480,高度是272。在使用FPGA進行圖像處理時,最關(guān)鍵的就是使用FPGA內(nèi)部的存儲資源對像
2025-02-07 10:43:291528 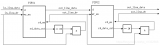
,這份報告極具前瞻性與指導(dǎo)意義。報告顯示,在算力規(guī)模方面,中國智能算力增速遠超預(yù)期,2024年中國智能算力規(guī)模達725.3EFLOPS,同比增長74.1%,是同期通用
2025-03-07 13:27:471935 
AI 訓(xùn)練與推理中的網(wǎng)絡(luò)效率瓶頸,助力數(shù)據(jù)中心在高帶寬、低延遲、高可靠性的需求下實現(xiàn)算力資源的最優(yōu)配置。
2025-05-28 14:08:401930 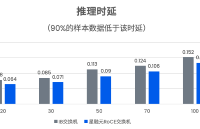
 電子發(fā)燒友App
電子發(fā)燒友App



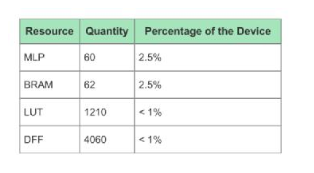
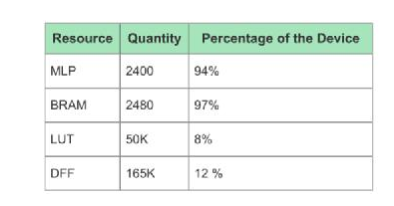
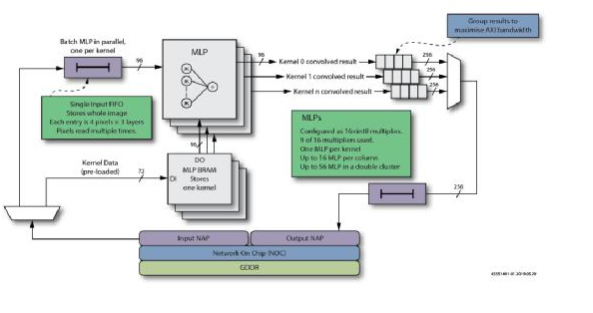

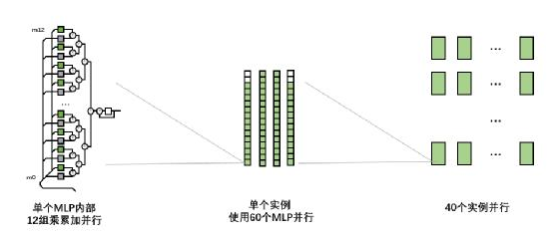








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論