 電子發燒友App
電子發燒友App



近期隨著 AI 市場的爆發式增長,作為 AI 背后技術的核心之一 GPU(圖形處理器)的價格也水漲船高。GPU 在人工智能中發揮著巨大的重要,特別是在計算和數據處理方面。目前生產 GPU 主流廠商其實并不多,主要就是 NVIDIA、AMD、Intel、高通等廠家。本文將主要聊聊 NVIDIA GPU 的核心架構及架構演進。
深入了解GPU架構
在探討 NVIDIA GPU 架構之前,我們先來了解一些相關的基本知識。GPU 的概念,是由 NVIDIA 公司在 1999 年發布 Geforce256 圖形處理芯片時首先提出,從此 NVIDIA 顯卡的芯就用 GPU 來稱呼,是專門設計用于處理圖形渲染的處理器,主要負責將圖像數據轉換為可以在屏幕上顯示的圖像。
與 CPU 不同,GPU 具有數千個較小的內核(內核數量取決于型號和應用),因此 GPU 架構針對并行處理進行了優化。GPU 可以同時處理多個任務,并且在處理圖形和數學工作負載時速度更快。GPU 架構是賦予 GPU 功能和獨特能力的一切,主要組成包括:
CUDA 核心:GPU 架構中的主要計算單元,能夠處理各種數學和邏輯運算。
內存系統:包括 L1、L2 高速緩存和共享內存等,用于存儲數據和指令,以減少 GPU 訪問主存的延遲。
高速緩存和緩存行:用于提高 GPU 的內存訪問效率。
TPC/SM:CUDA 核心的分組結構,一個 TPC 包含兩個 SM,每個 SM 都有自己的 CUDA 核心和內存。
Tensor Core( 2017 年 Volta 架構引入):Tensor張量核心,用于執行張量計算,支持并行執行FP32與INT32運算。
RT Core(2018 年 Turing 架構引入 ):光線追蹤核心,負責處理光線追蹤加速。
此外,NVIDIA GPU 架構還包括內存控制器、高速緩存控制器、CUDA 編譯器和驅動程序等其他組件,這些組件與SM 和其他核心組件協同工作,可以實現高效的并行計算和內存訪問,提高 GPU 的性能和能效。下面我們來詳細了解一下這些 GPU 架構每一部分的作用及功能。
Streaming?Multiprocessor(SM)
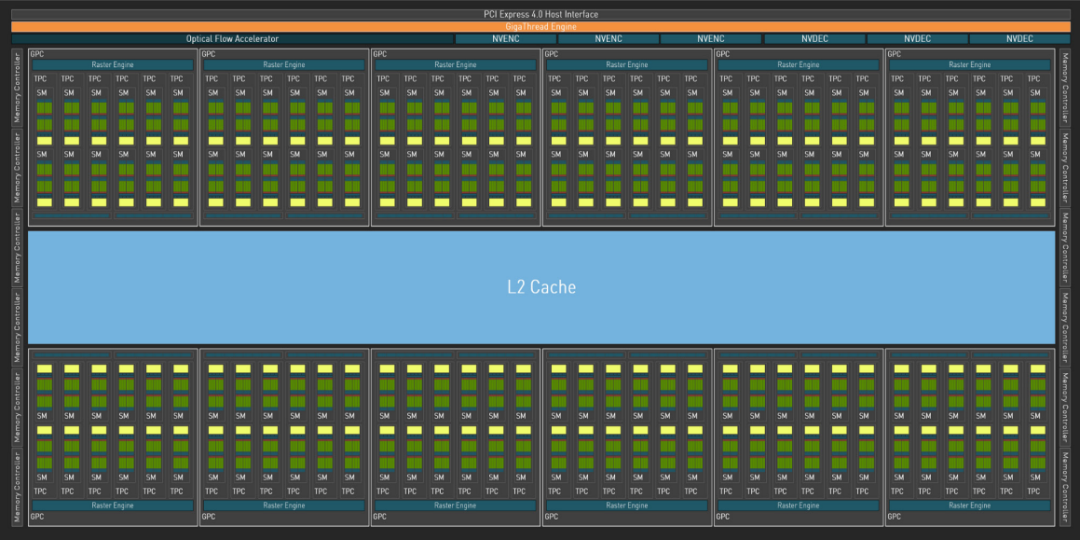
從上圖中可以看出 GPU 主要有許許多多的 SM 組成,SM 全稱為 Streaming Multiprocessor 流式多處理器,是 NVIDIA GPU 架構中的重要組成部分,也是 GPU 的基本計算單元。每個 SM 由多個 CUDA 核心、紋理單元、Tensor Core、流控制器和存儲器等輔助單元組成,可以同時執行多個計算任務,并具有高度的靈活性和性能。
最先支持 CUDA 的 GPU —— G80 或 GeForce 8800 GTX,包含 8 個 TPC,每一個 TPC 中有兩個 SM,一共有 16 個 SM。接下來支持 CUDA 的 GPU 是 GT200 或 GeForceGTX 280,它增加了 TPC 中的 SM 數量,包含 10 個 TPC 并且每個 TPC 含有 3 個 SM,總共是 30 個 SM。每一代 GPU 架構所支持的 SM 核心數量都不相同,如在 2020 年 Ampere 架構的完整 GA102 核心中,總共有 92 個 SM,每個 SM 包含 128 個 CUDA 核心、4 個 Tensor 核心和 1 個RT 核心。
CUDA Core
看完 SM 的介紹,接下來我們看看構成 SM 最重要的組成部分 CUDA Core。
CUDA 全稱為統一計算設備架構 (Compute Unified Device Architecture) ,是一個并行計算平臺,同時也是一個應用程序編程接口 (API)。它是由 NVIDIA 專門設計,目的在于讓軟件開發人員能夠更好地控制他們可以使用的物理資源。使用 C 或 C++ 編碼的計算機程序員對資源分配有很大的控制權。CUDA 系統極大地促進了 OpenACC 和 OpenCL 等框架的普及和使用。CUDA 核心也是并行處理器,允許不同處理器同時處理數據。這與雙核或四核 CPU 類似,只不過 GPU 有數千個 CUDA 核心。區別在于 CPU 更像是一個管理員,負責控制整個計算機,而 GPU 適合做具體的工作。
并行計算
CUDA 的巨大優勢是任務并行化,允許通過擴展在 C 和 C++ 中并行工作,處理不同重要性級別的任務和數據。這些并行化任務可以使用各種高級語言來執行,例如 C 語言、C++以及 Python,或者簡單地使用包含 OpenACC 指令的開放標準。
CUDA 是目前最常用的任務加速平臺,并且技術的發展已經取得了巨大的進步。CUDA 技術是使用最廣泛、最重要的技術之一。
應用范圍
CUDA 應用范圍包括加密哈希、物理引擎、游戲開發等相關項目,在科學行業,在測量、測繪、天氣預報和其他等相關項目得到了很大改善和簡化。目前,數以千計的研究人員可以在學術和制藥領域從事分子動力學研究,這簡化了藥理學的開發和研究,從而在治療癌癥、阿爾茨海默病和其他當今無法治愈的疾病等復雜疾病方面在更短的時間內取得進展。
CUDA 還可以對有風險的金融操作進行預測,將效率加快至少十八倍或更多。其他例子包括 Tesla GPU 在云計算和其他需要強大工作能力的計算系統中廣受好評。CUDA 還允許自動駕駛車輛簡單高效地運行,能夠進行其他系統無法完成的實時計算。這種計算敏捷性使車輛能夠在很短的時間內做出重要決策,避開障礙物,順利行駛或避免事故。
Tensor Core
隨著 GPU 開始用于人工智能和機器學習工作,NVIDIA 從 2017 年開始在其數據中心 GPU 的 Volta 架構中引入了 Tensor Core。但是直到 NVIDIA?Turing 架構的推出(RTX 20 系列 GPU)這些核心才出現在消費類 GPU 中。
CUDA 核心足以滿足計算工作負載,但 Tensor Core 的速度明顯更快。CUDA 核心每個時間周期只能執行一項操作,但 Tensor 核心可以處理多項操作,從而帶來令人難以置信的性能提升。從根本意義上來說,Tensor Core 所做的就是提高矩陣乘法的速度。
計算速度的提升確實是以準確性為代價的,從這點上來說 CUDA 核心的準確度要高得多。但是在訓練機器學習模型時,Tensor Core 在計算速度和總體成本方面要有效得多,此時準確性的損失常常被忽略。
較之 CUDA Core 專門處理圖形工作負載,Tensor Core 更擅長處理數字工作負載。在它們同時工作的過程中,在某些場景下可以互換。
RT Core
2018 年 NVIDIA 發布了新一代的旗艦顯卡 RTX 2080,搭載了全新的 Turing(圖靈)架構。全新的架構也同時添加了名為 RT Core 的計算單元,相當于在 Volta 上增加的 Tensor Core,都是為了特殊應用架構而設計的計算單元。該計算單元的目的是為了讓 GPU 擁有實時光線追蹤的能力,一種可以讓畫面更換新的渲染演算法。
光線追蹤(Ray Tracing)的原理是從用戶端為起點,尋找光線反射和折射的路徑并算出用戶會看到的物體顏色及亮度。然而,由于使大量光線在空間中反射決策,且空間中實際的狀況未知,每一張圖所需的計算量極其巨大,無法即時計算出結果,因此游戲產業尚未大量采用該技術。在發布的 RTX 2080 顯卡中,NVIDIA 正式將 RT Core 加入繪圖卡,讓實時光學渲染法(Rendering)不再是說說而已。
GPU架構演進

在了解完 GPU 架構組成部分后,我們來看看 NVIDIA GPU 架構的演進。自 NVIDIA 成立之初,其 GPU 架構歷經多次變革。從 G80、GT200 系列,到 Fermi、Kepler、Pascal 和 Volta 架構等,以及近期的 Ampere 和 Hopper 架構。值得一提的是架構命名方式從 Tesla 架構開始每一代以科學家命名,每一代都有其獨特的設計和特點,簡單介紹下其中幾個架構。
G80 架構:英偉達第一個 GPU 架構,采用了 MIMD(多指令流多數據流)標量架構,擁有 128 個 SP(流處理器),核心頻率范圍從 250MHz 到 600MHz,搭配 DDR3 顯存。該架構是當時最強大的 GPU 之一,但是功耗較高。
Fermi 架構:英偉達第一個采用 GPU-Direct 技術的 GPU 架構,它擁有 32 個 SM(流多處理器)和 16 個 PolyMorph Engine 陣列,每個 SM 都擁有 1 個 PolyMorph Engine 和 64 個 CUDA 核心。該架構采用了 4 顆芯片的模塊化設計,擁有 32 個光柵化處理單元和 16 個紋理單元,搭配 GDDR5 顯存。
Volta 架構:采用了全新的設計理念和技術,擁有 256 個 SM 和 32 個 PolyMorph Engine 陣列,每個 SM 都擁有 64 個 CUDA 核心。該架構采用了全新的 Tensor 張量核心、ResNet 和 InceptionV3 加速模塊等技術,搭配 GDDR6X 顯存。
Turing 架構:代表產品為 GeForce RTX 20 系列。該架構首次引入了光線追蹤(Ray Tracing)和深度學習超級采樣(DLSS),為游戲和設計領域帶來了革命性的視覺效果和性能提升。此外,圖靈架構還優化了著色器性能,以提高渲染效率和能效比。Turing SM 設計采用全新架構,每個 TPC(Texture and Compute Cluster,紋理和計算集群)均包含兩個 SM,每個 SM 共有 64 個 FP 32 核心和 64 個 INT32 核心。也就是說,每個 SM 都包含 128 個核心。這些核心可以并行執行 FP32 與 INT32 運算。每個 Turing SM 還擁有 8 個混合精度 Turing Tensor 核心和 1 個 RT(Ray Tracing,光線追蹤)核心。
Ampere 架構:代表產品為 GeForce RTX 30 系列。該架構繼續優化并行計算能力,并引入了更先進的 GDDR6X 內存技術,大幅提高了內存帶寬和性能。相比 Turing 架構,Ampere 架構中的 SM 在 Turing 基礎上增加了一倍的 FP32 運算單元,這使得每個 SM 的 FP32 運算單元數量提高了一倍,同時吞吐量也就變為了一倍。此外,安培架構還改進了著色器性能和張量核(Tensor Cores),進一步加速深度學習和人工智能任務的處理速度。
經過幾十年的探索和發展,NVIDIA 的 GPU 架構以其層次化的內存設計、多線程技術、優化內存層次結構、混合精度計算技術和自動功耗優化技術,實現了高效、可擴展、靈活和能效比這幾個關鍵目標。從最初的 GeForce 系列到最新的 Hopper 架構,NVIDIA 不斷引領著 GPU 架構的發展,提供了強大的性能和創新的技術,從而在圖形處理和人工智能等領域取得了顯著的成功。
編輯:黃飛
?














 工商網監
工商網監
評論