") 全面概述ARM Mali GPU架構(gòu)演進(jìn)!
全面概述ARM Mali GPU架構(gòu)演進(jìn)!

年初有機(jī)會(huì)調(diào)研了一下歷代ARM Mali GPU架構(gòu),目前一共四代【1】,分別是Utgard,Midgard,Bifrost和Valhall。有感于他的演進(jìn)是大GPU架構(gòu)發(fā)展的縮影,所以作文一篇記錄心得。我不打算逐一介紹各代架構(gòu)的細(xì)節(jié),而是針對(duì)Shader處理器聊一聊每代GPU的發(fā)展。對(duì)各代架構(gòu)細(xì)節(jié)有興趣或者希望了解全貌的同學(xué)可以參考【2】【3】【4】【5】。
Shader處理器
圖形API發(fā)展到OpenGL 2.0之后,圖形處理管線擺脫了之前的固定模式,實(shí)現(xiàn)了高度的可定制化。出現(xiàn)了針對(duì)圖形管線各階段的Shader,比如Vertex Shader,F(xiàn)ragment Shader,再到后來(lái)的Geometry Shader,Tessellation Shader和Compute Shader。每個(gè)Shader都是一個(gè)用戶編寫(xiě)的小程序,執(zhí)行這些小程序就是GPU中Shader處理器的工作。
Shader處理器作為核心組件,它的架構(gòu)關(guān)系到GPU的性能表現(xiàn),也是演進(jìn)最為激烈的部分。每代Mali GPU都會(huì)對(duì)Shader處理器做較大調(diào)整以適應(yīng)圖形API和應(yīng)用的發(fā)展。這里著重討論兩個(gè)主要變化——統(tǒng)一處理器架構(gòu)和TLP驅(qū)動(dòng)的架構(gòu)設(shè)計(jì)。
從獨(dú)立到統(tǒng)一
初代的Utgard架構(gòu)有兩種Shader處理器,GP——執(zhí)行Vertex Shader,PP——執(zhí)行Fragment Shader。兩者采用不同的硬件架構(gòu)和指令集,所以編譯器會(huì)將不同的Shader編譯成各自Shader處理器的機(jī)器碼后交由它們分別執(zhí)行。
Vertex Shader是對(duì)每一個(gè)頂點(diǎn)執(zhí)行一次,而Fragment Shader是對(duì)每一個(gè)像素執(zhí)行一次,一般情況下Fragment Shader的執(zhí)行次數(shù)會(huì)多于Vertex Shader;而且很多圖形效果的實(shí)現(xiàn),F(xiàn)ragment Shader都比Vertex Shader更加復(fù)雜。所以Utgard是一個(gè)GP配上多個(gè)PP,比如一個(gè)GP配四個(gè)PP就是MP4,最高能配到MP8。單個(gè)PP的硬件設(shè)計(jì)也相對(duì)GP更加復(fù)雜。
這種獨(dú)立Shader處理器的架構(gòu)Shader處理器之間算力無(wú)法互通,當(dāng)一種Shader算力需求遠(yuǎn)大于另一種時(shí),另一種Shader處理器只能干等著無(wú)法幫忙,造成利用率下降。而且隨著圖形API加入新的Shader種類(lèi),給每一種Shader設(shè)計(jì)一種處理器會(huì)不斷增加軟件和硬件的復(fù)雜度。但其實(shí)這些Shader在純計(jì)算部分幾乎是一樣的,可以復(fù)用大部分的設(shè)計(jì),不必每一個(gè)Shader都搞一套。
所以從Midgard這一代開(kāi)始,采用了統(tǒng)一Shader處理器架構(gòu)。不同種類(lèi)的Shader共享計(jì)算部分作為統(tǒng)一Shader處理器,頂點(diǎn)插值和光柵化這些固定功能操作獨(dú)立于外。這樣每種Shader都能跑滿所有的處理器,提高了硬件利用率。
從ILP到TLP
ILP(Instruction Level Parallelism)和TLP(Thread Level Parallelism)都或多或少同時(shí)存在于每代的Shader處理器架構(gòu)中,但是趨勢(shì)是TLP的比重逐漸加大。
Utgard和Midgard架構(gòu)下TLP僅限于處理器級(jí)別,Shader處理器就像CPU的一個(gè)核心,一次運(yùn)行一個(gè)頂點(diǎn)或者像素的Shader,有幾個(gè)處理器就有幾個(gè)線程。比如Mali400MP4,有四個(gè)PP,可以并行處理四個(gè)像素的fragment shader。每個(gè)處理器完全采用了ILP的方式著重優(yōu)化單線程的處理能力。
我們可以從兩種架構(gòu)所使用的VLIW指令【6】一窺ILP的設(shè)計(jì)。Utgard PP的指令編碼可以參見(jiàn)【7】,包含兩個(gè)向量處理單元、兩個(gè)標(biāo)量處理單元、一個(gè)函數(shù)處理單元,還有負(fù)責(zé)各類(lèi)數(shù)據(jù)加載和執(zhí)行控制的單元。這種VLIW指令和普通的CPU指令不同,一條指令可以完成多個(gè)操作。它對(duì)應(yīng)了硬件上的管線(pipeline)結(jié)構(gòu),如圖一所示。管線是處理器執(zhí)行指令的一條流水線,可以分成多個(gè)階段(stage)。VLIW指令里的各個(gè)操作由這條管線里的各個(gè)階段完成。
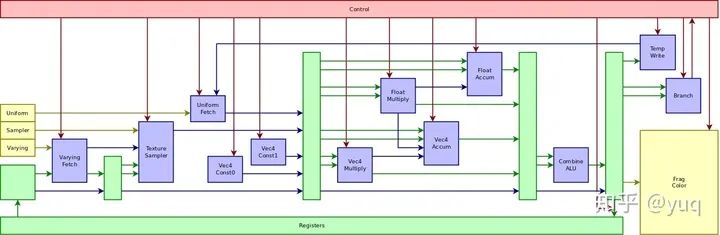
圖一:Utgard PP處理器管線【7】
比如這一系列操作:取貼圖數(shù)據(jù),然后做加法,再做乘法,最后寫(xiě)結(jié)果到內(nèi)存。精簡(jiǎn)指令集(RISC)一般需要四條指令,每條指令都有各自的取指令,執(zhí)行,寫(xiě)結(jié)果的步驟;但是VLIW可以在一條指令里將這些操作依序串起來(lái),取出的貼圖數(shù)據(jù)不需要寫(xiě)進(jìn)寄存器文件,直接傳給加法單元處理,加法單元的結(jié)果也是這樣直接傳遞給乘法單元,最后輸出到內(nèi)存。所以VLIW管線會(huì)更長(zhǎng),但是由于略去了操作的中間步驟,整合后更加高效。
普通CPU會(huì)通過(guò)復(fù)雜的硬件設(shè)計(jì),動(dòng)態(tài)調(diào)度要執(zhí)行的指令來(lái)提高單線程性能,比如并行執(zhí)行和亂序執(zhí)行。VLIW卻是通過(guò)在編譯階段,依靠編譯器靜態(tài)調(diào)度各個(gè)操作填充到VLIW指令的單元中。所以很多早期的GPU包括桌面和移動(dòng)的,為了簡(jiǎn)化硬件降低功耗,都采用VLIW來(lái)加強(qiáng)ILP。但是這種設(shè)計(jì)對(duì)編譯器要求很高。如何調(diào)度Shader里的操作以充分利用一條指令里的所有操作單元決定了硬件的執(zhí)行效率。當(dāng)然Shader本身的邏輯也決定了有沒(méi)有足夠可以并行的操作。這些都是ILP發(fā)展方向的限制條件。
好在圖形計(jì)算是一個(gè)天生的數(shù)據(jù)并行良好的鄰域——有大量的圖元需要計(jì)算,而且每個(gè)圖元的計(jì)算可以獨(dú)立進(jìn)行,不依賴(lài)其他圖元。所以每個(gè)圖元的計(jì)算都可以作為一個(gè)線程,繪制出一幀畫(huà)面就是跑完這成千上萬(wàn)個(gè)線程的工作。利用大量的線程,獲得很多可以并行執(zhí)行的操作,不用很復(fù)雜的調(diào)度就能達(dá)到很高的硬件利用率,這就是GPU里TLP設(shè)計(jì)的出發(fā)點(diǎn)。
從Bifrost架構(gòu)開(kāi)始,ARM在單處理器內(nèi)部也引入了TLP。方法是將大量線程每4個(gè)一組(后來(lái)擴(kuò)展為8、16個(gè)),然后一組一組在單個(gè)處理器中運(yùn)行。同組的線程執(zhí)行相同的指令,類(lèi)似于SIMD。這樣就不需要為每個(gè)線程都準(zhǔn)備一套完整的處理器設(shè)計(jì),而是可以多個(gè)線程共享除了執(zhí)行器和寄存器以外的部分。再乘上核心數(shù),同時(shí)運(yùn)行的線程數(shù)量大大增加。
而且為了隱藏一些操作比如內(nèi)存訪問(wèn)的延遲,還有一個(gè)線程組的池,里面可以準(zhǔn)備執(zhí)行到不同指令的幾十組線程,在一組線程因?yàn)閿?shù)據(jù)訪問(wèn)等依賴(lài)無(wú)法馬上執(zhí)行時(shí),硬件調(diào)度器可以掛起這組線程執(zhí)行另一組的線程。也算是利用線程數(shù)量的例子。
不過(guò)Bifrost架構(gòu)里依然有很多ILP的設(shè)計(jì),比如句式(Clause)指令(圖二):將很多串行指令組成一個(gè)指令塊——句子,句子是硬件調(diào)度器調(diào)度的最小單位。句子內(nèi)部可以有一些加速操作,比如當(dāng)一個(gè)加法指令輸出是一個(gè)減法指令輸入的時(shí)候,可以不通過(guò)寄存器文件直接傳遞數(shù)據(jù)。而且單個(gè)指令雖然減少了單元數(shù)量,但還是有三個(gè)計(jì)算單元。所以編譯器還是需要考慮單指令單元填充以及多指令組成句子的問(wèn)題。
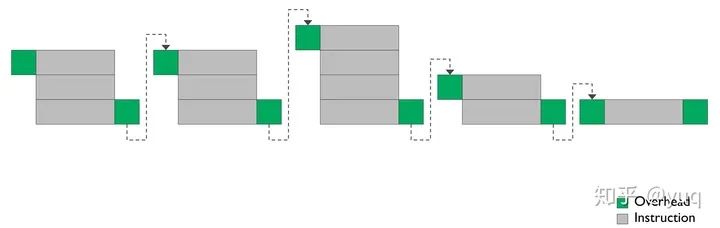
圖二:Bifrost句式指令【4】
Valhall架構(gòu)就更加依賴(lài)TLP來(lái)提升性能了,為此放棄了句式指令和多單元指令這些依賴(lài)軟件的ILP特性,減小了調(diào)度粒度的同時(shí)也縮短了處理器管線。如圖三所示,Valhall的處理器有三個(gè)計(jì)算單元,包括一個(gè)FMA(Fused-Multiply-Add),一個(gè)CVT(Convert)和一個(gè)SFU(Special Function Unit),線程組調(diào)度器可以在線程組池里找出三個(gè)當(dāng)前指令使用不同計(jì)算單元的線程組,讓他們?cè)谒膫€(gè)時(shí)鐘周期內(nèi)同時(shí)在三個(gè)計(jì)算單元內(nèi)執(zhí)行。而B(niǎo)ifrost雖然也有三個(gè)計(jì)算單元,但是他們屬于一條長(zhǎng)指令,而且ADD和Table排在FMA下游,是一個(gè)串行結(jié)構(gòu),這一條管線需要八個(gè)時(shí)鐘周期。
對(duì)比來(lái)看Valhall再次加強(qiáng)了TLP,一個(gè)處理器最多可以同時(shí)運(yùn)行三個(gè)線程組,而B(niǎo)ifrost最多只有一個(gè)。反過(guò)來(lái)看Valhall將三個(gè)Bifrost處理器壓縮為一個(gè),減少了控制邏輯,就可以有更多的空間增加處理器的數(shù)量,也是增加了TLP。

圖三:Valhall和Bifrost處理器對(duì)比【5】
結(jié)語(yǔ)
在GPU架構(gòu)歷史上,統(tǒng)一Shader處理器和TLP驅(qū)動(dòng)架構(gòu)設(shè)計(jì)都是趨勢(shì)。各家各代的GPU都或多或少經(jīng)歷了這個(gè)過(guò)程。我們純從架構(gòu)上看后期的GPU都比前期來(lái)的先進(jìn),但是放在當(dāng)時(shí)的環(huán)境下,早期的圖形應(yīng)用Shader負(fù)載不是很復(fù)雜,而且移動(dòng)鄰域處理器對(duì)于面積和功耗方面的嚴(yán)格控制,都是他合理性的來(lái)源。
引用
Mali (GPU):https://zh.wikipedia.org/wiki/Mali_(GPU)
Lima driver status update:https://xdc2019.x.org/event/5/contributions/328/attachments/420/670/lima.pdf
ARM‘s Mali Midgard Architecture Explored:https://www.anandtech.com/show/8234/arms-mali-midgard-architecture-explored
ARM Unveils Next Generation Bifrost GPU Architecture & Mali-G71: The New High-End Mali:https://www.anandtech.com/show/10375/arm-unveils-bifrost-and-mali-g71
Arm’s New Mali-G77 & Valhall GPU Architecture: A Major Leap:https://www.anandtech.com/show/14385/arm-announces-malig77-gpu
Very long instruction word:https://en.wikipedia.org/wiki/Very_long_instruction_wordA4%E5%AD%97
Mali ISA:https://gitlab.freedesktop.org/panfrost/mali-isa-docs/-/tree/master
編輯:jq
-
GP
+關(guān)注
關(guān)注
0文章
31瀏覽量
24059 -
編譯器
+關(guān)注
關(guān)注
1文章
1672瀏覽量
51600 -
TLP
+關(guān)注
關(guān)注
0文章
37瀏覽量
16483 -
GPU架構(gòu)
+關(guān)注
關(guān)注
0文章
15瀏覽量
8654
原文標(biāo)題:ARM Mali GPU架構(gòu)演進(jìn)
文章出處:【微信號(hào):Ithingedu,微信公眾號(hào):安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA RTX PRO 5000 72GB Blackwell GPU現(xiàn)已全面上市

芯源MCU架構(gòu)是不是基本都是ARM架構(gòu)?還有其他的架構(gòu)嗎?
Arm助力MediaTek天璣9500重塑旗艦體驗(yàn)
如何看懂GPU架構(gòu)?一分鐘帶你了解GPU參數(shù)指標(biāo)

Imagination Technologies:面向智能駕艙,打造高安全GPU與AI融合計(jì)算架構(gòu)
適應(yīng)邊緣AI全新時(shí)代的GPU架構(gòu)
什么是ARM架構(gòu)?你需要知道的一切

同一水平的 RISC-V 架構(gòu)的 MCU,和 ARM 架構(gòu)的 MCU 相比,運(yùn)行速度如何?

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】+NVlink技術(shù)從應(yīng)用到原理
GPU架構(gòu)深度解析
ARM Mali GPU 深度解讀
Arm架構(gòu)何以成為現(xiàn)代計(jì)算的基礎(chǔ)
Arm助力開(kāi)發(fā)者加速遷移至Arm架構(gòu)云平臺(tái) Arm云遷移資源分享
iTOP-3588開(kāi)發(fā)板采用瑞芯微RK3588處理器四核心架構(gòu)GPU內(nèi)置獨(dú)立NPU強(qiáng)大的視頻編解碼
智能座艙SoC,急需更強(qiáng)大的GPU IP




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論