 強化學習中如何高效地與環境互動?如何從經驗中高效學習?
強化學習中如何高效地與環境互動?如何從經驗中高效學習?

強化學習中很多重要的難題都圍繞著兩個問題:我們應該如何高效地與環境互動?如何從經驗中高效學習?在這篇文章中,我想對最近的深度強化學習研究做一些調查,找到解決這兩個問題的方法,其中主要會講到三部分:
分層強化學習
記憶和預測建模
有模型和無模型方法的結合
首先我們快速回顧下DQN和A3C這兩種方法,之后會深入到最近的幾篇論文中,看看它們在這一領域做出了怎樣的貢獻。

回顧DQN和A3C/A2C
DeepMind的深度Q網絡(DQN)是深度學習應用到強化學習中實現的第一個重大突破,它利用一個神經網絡學習Q函數,來玩經典雅達利游戲,例如《乓》和《打磚塊》,模型可以直接將原始的像素輸入轉化成動作。
從算法上來說,DQN直接依賴經典的Q學習技術。在Q學習中,動作對的Q值,或者說“質量”,是根據基于經驗的迭代更新來估計的。從本質上說,在每個狀態采取的行動,我們都能利用接收到的實時獎勵和新狀態的價值來更新原始狀態動作對的價值估計。
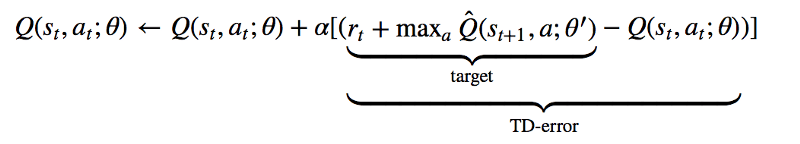
除此之外,DeepMind的A3C(Asynchronous Advantage Actor Critic)和OpenAI的變體A2C,對actor-critic方法來說都是非常成功的深度學習方法。
Actor-critic方法結合了策略梯度方法和學習價值函數。只用DQN,我們只能得到學習價值函數(Q函數),我們跟隨的“策略”也只是簡單的在每一步將Q值達到最大的動作。有了A3C和其他actor-critic方法,我們學習兩種不同的函數:策略(或者“演員”)和價值(或者“評委”)。基于當前估計的優點,策略會調整動作的概率,價值函數也會更新基于經驗和獎勵的優勢。策略如下:

可以看到,降至網絡學習了一個基準狀態值V(si;θv),有了它我們可以將目前的獎勵估計R和得到的優點相比較,策略網絡會根據這些優點用經典強化算法調整對數幾率。
A3C之所以這么受歡迎,主要原因是它結構的平行和不同步性,具體結構不是本文重點討論的內容,感興趣的讀者可以查看DeepMind的IMPALA論文。
DQN和A3C/A2C都是強大的基準智能體,但遇到復雜問題時,它們并不那么好用,比如可能觀察補全或者在動作和獎勵信號之間有延遲。所以,強化學習領域的研究者們一直致力于解決這些問題。
分層強化學習
分層強化學習是強化學習方法的一種,它從策略的多個圖層中學習,每一層都負責控制不同時間下的動作。策略的最下一層負責輸出環境動作,上面幾層可以完成其他抽象的目標。
為什么這種方法如此受歡迎呢?首先,從認知角度來看,長久以來的研究都表示,人類和動物的行為都是有組織的。例如,當我們想做飯的時候,我會把這一任務分成好幾部分完成:洗菜、切菜、燒水煮面等等。我還可以把其中的某一小任務進行替換,比如把煮面換成蒸米飯,也能完成做好一頓飯的總任務。這就說明現實世界中的任務內部是有結構的。
從技術層面來說,分層強化學習能幫助解決上述提到的第二個問題,即如何從經驗中高效地學習,解決方法就是通過長期信用分配和稀疏獎勵信號。在分層強化學習中,由于低層次的策略是從高層次策略分布的任務所得到的內部獎勵學習的,即使獎勵稀疏,也可以學到其中的小任務。另外,高層次策略生成的時間抽象可以讓我們的模型處理信用分配。
說到具體工作原理,實施分層強化學習的方法有很多。最近,谷歌大腦團隊的一篇論文就采取了一種簡易方法,他們的模型稱為HIRO。

核心思想如下:我們有兩個策略層,高層策略訓練的目的是為了讓環境獎勵R實現最大化。每一步后,高層策略都會對新動作進行采樣。低層策略訓練的目的是為了采取環境行動,生成與給定的目標狀態相似的狀態。
訓練低層策略時,HIRO用的是深度確定性策略梯度(DDPG)的變體,它的內部獎勵是將目前得到的觀察和目標觀察之間的距離進行參數化:

DDPG是另一種開創新的深度強化學習算法,它將DQN的思想擴展到了持續動作空間中。他也是另一種actor-critic方法,使用策略梯度來優化策略。
不過,HIRO絕不是唯一的分層強化學習方法。FeUdal網絡出現的時間更早,它將經過學習的“目標”表示作為輸入,而不是原始狀態的觀察。另外還有很多方法需要一定程度的手動操作或領域知識,這就限制了其泛化能力。我個人比較喜歡的最近的一項研究成果是基于人口的訓練(PBT),其中他們將內部獎勵看作額外的超參數,PBT在訓練時人口“增長”的過程中對這些超參數進行優化。
如今,分層強化學習是非常火熱的研究對象,雖然它的核心是非常直觀的,但它可擴展、多任務并行、能解決強化學習中的許多基礎性問題。
存儲和注意力
現在讓我們談談另外能解決長期信用分配和稀疏獎勵信號問題的方法。通俗點說,我們想知道智能體如何能擅長記憶。
深度學習中的記憶總是非常有趣,科學家們經歷了千辛萬苦,也很難找到一種結構能打敗經過良好調校的LSTM。但是,人類的記憶機制可不像LSTM。當我們從家開車去超市時,回想的都是原來走過幾百次的路線記憶,而不是怎么從倫敦的一個城市到另一個城市的路線。所以說,我們的記憶是根據情景可查詢的,它取決于我們在哪里、在干什么,我們的大腦知道哪部分記憶對現在有用。
在深度學習中,Neural Turing Machine是外部、關鍵信息存儲方面論文的標桿,這也是我最喜歡的論文之一,它提出通過向量值“讀取”和“寫入”特定位置,利用可區分的外部存儲器對神經網絡進行增強。如果把它用在強化學習上會怎樣?這就是最近的MERLIN結構的思想。
MERLIN有兩個組成部分:基于記憶的預測器(MBP)和一個策略網絡。MBP負責將觀察壓縮成有用的、低維的“狀態變量”,將它們直接儲存在關鍵的記憶矩陣中。
整個過程如下:對輸入觀察進行編碼,并將其輸入到MLP中,輸出結果被添加到先驗分布中,生成后驗分布。接著,后驗分布經過采樣,生成一個狀態變量zt。接著,zt輸入到MBP的LSTM網絡中,輸出結果用來更新先驗,并且進行讀取或書寫。最后,策略網絡運用z_t和讀取輸出生成一個動作。
關鍵細節在與,為了保證狀態表示時有用的,MBP同樣經過訓練需要預測當前狀態下的獎勵,所以學習到的表示和目前的任務要相關。
不過,MERLIN并不是唯一使用外部存儲器的深度強化學習網絡,早在2016年,研究者就在一個記憶Q網絡中運用了這一方法,來解決Minecraft中的迷宮問題。不過這種將存儲用作預測模型的方法有一些神經科學上的阻礙。
MERLIN的基于存儲的預測器對所有觀察進行編碼,將它們與內部先驗結合,生成一個“狀態變量”,可以捕捉到一些表示,并將這些狀態存儲到長期記憶中,讓智能體在未來可以做出相應的動作。
智能體、世界模型和想象力
在傳統強化學習中,我們可以做無模型學習,也可以做基于模型的學習。在無模型的強化學習中,我們學著將原始環境觀察直接映射到某個值或動作上。在基于模型的強化學習中,我們首先會學習一個基于原始觀察的過渡模型,然后用這個模型來選擇動作。

能在模型上進行計劃比單純的試錯法更高效,但是,學習一個好的模型通常很困難,所以早期很多深度強化學習的成功都是無模型的(例如DQN和A3C)。
這就表示,無模型和有模型的強化學習之間的界線很模糊。現在,一種新的“Imagination-augmented Agents”算法出現了,將這兩種方法結合了起來。
在Imagination-Augmented Agents(I2A)中,最終策略是一個無模型模塊和有模型模塊并存的函數。有模型的模塊可以看做智能體對環境的“想象”,其中包含了智能體內部想象的活動軌跡。但是,關鍵是有模型模塊在終點處有一個編碼器,它可以聚集想象軌跡,并將它們進行編譯,讓智能體在必要的時候忽略那些想象。所以,當智能體發現它的內部模型在進行無用或不精確的想象時,它可以學習忽略模型,用無模型部分繼續工作。
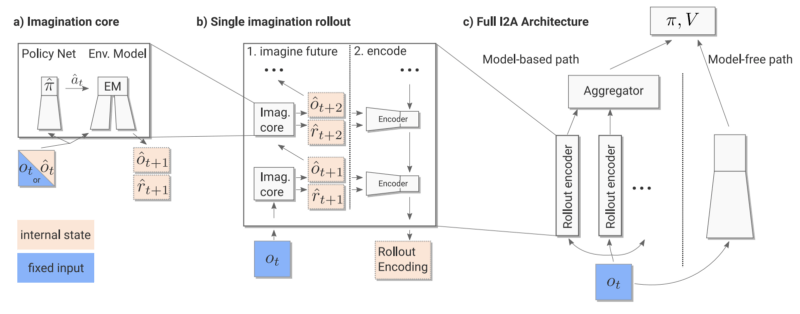
I2A的工作流程
和A3C以及MERLIN類似,該策略也是通過一個標準策略梯度損失進行訓練,如下:

I2A之所以如此受歡迎的原因之一是,在某些情況下,這也是我們在現實中處理情況的方法。我們總是根據所處的環境下,目前的精神想法對未來做計劃和預測,但我們知道,我們的精神模型可能不完全準確,尤其是當我們來到一個陌生環境中時。在這種情況下,我們就會進行試錯法,就像無模型方法一樣,但同時我們還會利用這一段新體驗對內在精神環境進行更新。
除此之外,還有很多研究結合了有模型和無模型兩種方法,例如伯克利的Temporal Difference Model等,這些研究論文都有著相同目標,即達到像無模型方法一樣的性能,同時具有和基于模型方法相同的高效采樣率。
結語
深度強化學習模型非常難以訓練,但是正是因為這樣的難度,我們想到了如此多種的解決方案。這篇文章只是對深度強化學習的不完全調查,除了本文提到了方法,還有很多針對深度強化學習的解決方案。但是希望文中所提到的關于記憶、分層和想象的方法對該領域中所遇到的挑戰和瓶頸有所幫助。最后,Happy RL hacking!
-
函數
+關注
關注
3文章
4417瀏覽量
67504 -
深度學習
+關注
關注
73文章
5599瀏覽量
124398 -
強化學習
+關注
關注
4文章
270瀏覽量
11969
原文標題:除了DQN/A3C,還有哪些高級強化學習成果
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中常提的離線強化學習是什么?

強化學習會讓自動駕駛模型學習更快嗎?

多智能體強化學習(MARL)核心概念與算法概覽

上汽別克至境E7首發搭載Momenta R6強化學習大模型
SAW 聲表濾波器系統化學習路線:從物理原理到 PCB 實戰

今日看點:智元推出真機強化學習;美國軟件公司SAS退出中國市場
自動駕駛中常提的“強化學習”是個啥?

如何在Ray分布式計算框架下集成NVIDIA Nsight Systems進行GPU性能分析
FPGA在機器學習中的具體應用
NVIDIA Isaac Lab可用環境與強化學習腳本使用指南

SUNON高效節能商用冷藏EC風扇
繪王Kamvas Slate系列平板電腦,開啟高效智能辦公學習新體驗

【書籍評測活動NO.61】Yocto項目實戰教程:高效定制嵌入式Linux系統
智慧教室互動平板:賦能未來教育的新利器

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現




 工商網監
工商網監
評論