") 國(guó)產(chǎn)InfiniBand網(wǎng)絡(luò)有多強(qiáng)?從此中國(guó)架起AI高速網(wǎng)絡(luò)!
國(guó)產(chǎn)InfiniBand網(wǎng)絡(luò)有多強(qiáng)?從此中國(guó)架起AI高速網(wǎng)絡(luò)!

隨著AI大模型訓(xùn)練與高通量推理計(jì)算需求持續(xù)擴(kuò)大,萬(wàn)卡級(jí)乃至更大規(guī)模的算力集群正成為主流形態(tài)。研究表明,在大規(guī)模分布式訓(xùn)練中,網(wǎng)絡(luò)通信耗時(shí)占比已達(dá)到30-50%,網(wǎng)絡(luò)性能直接影響算力系統(tǒng)的整體效率。
算力網(wǎng)絡(luò)是智算集群的核心基礎(chǔ)條件之一。超高帶寬、極低延時(shí)、無(wú)損傳輸和擴(kuò)展是超大規(guī)模智算集群對(duì)網(wǎng)絡(luò)提出的新要求。
中科曙光自2022年開始進(jìn)行RDMA的技術(shù)研究,在近日宣布實(shí)現(xiàn)國(guó)產(chǎn)高端原生RDMA技術(shù)重大突破,正式發(fā)布首款全棧自研400G無(wú)損高速網(wǎng)絡(luò)——scaleFabric。該產(chǎn)品基于原生RDMA架構(gòu),從底層的112G SerDes IP、硬件設(shè)備到上層的管理軟件實(shí)現(xiàn)100%自研,填補(bǔ)了國(guó)內(nèi)數(shù)據(jù)中心高速網(wǎng)絡(luò)領(lǐng)域的空白,以比肩國(guó)際頂尖同類產(chǎn)品的性能表現(xiàn),為超大規(guī)模智算集群鋪就了一條高帶寬、低時(shí)延、真無(wú)損、超可靠的“算力大動(dòng)脈”。
尤其在大規(guī)模AI訓(xùn)練系統(tǒng)中,網(wǎng)絡(luò)互聯(lián)能力已成為影響算力利用率的關(guān)鍵變量。scaleFabric的發(fā)布,標(biāo)志著國(guó)產(chǎn)智算網(wǎng)絡(luò)在高端RDMA領(lǐng)域?qū)崿F(xiàn)重大突破。
自研112G SerDes IP、兩款高速網(wǎng)絡(luò)芯片、三款網(wǎng)卡/交換機(jī)
中科曙光scaleFabric是國(guó)內(nèi)首款原生無(wú)損RDMA高速網(wǎng)絡(luò),面向超大規(guī)模智算集群設(shè)計(jì),從核心關(guān)鍵IP、交換芯片、網(wǎng)卡到交換機(jī)、驅(qū)動(dòng)與管理軟件均實(shí)現(xiàn)自主研發(fā),構(gòu)建起從硬件到軟件的完整技術(shù)體系。
scaleFabric的核心是自主研發(fā)的兩顆高速網(wǎng)絡(luò)芯片即scaleFabric400網(wǎng)卡芯片和交換芯片。主要涵蓋三款產(chǎn)品scaleFabric400單口標(biāo)準(zhǔn)網(wǎng)卡,scaleFabric400 1U800G液冷交換機(jī),以及scaleFabric400 2U 800G風(fēng)冷交換機(jī)。

性能方面,scaleFabric400網(wǎng)卡基于PCIe5.0接口,端口帶寬達(dá)400Gbps,端到端通信時(shí)延低至0.9微秒;scaleFabric400交換機(jī)單端口帶寬達(dá)800Gbps,整機(jī)交換容量可達(dá)雙向64Tbps,交換時(shí)延約260納秒,支持800Gbps×40或400Gbps×80端口擴(kuò)展。這一性能組合,可充分滿足萬(wàn)卡級(jí)AI訓(xùn)練集群對(duì)高帶寬、低時(shí)延網(wǎng)絡(luò)的極致需求。
穩(wěn)定性與擴(kuò)展能力上,產(chǎn)品采用基于信用的無(wú)損流控機(jī)制,從根源規(guī)避擁塞丟包風(fēng)險(xiǎn),鏈路故障恢復(fù)時(shí)間小于1毫秒,已支撐近萬(wàn)卡集群持續(xù)穩(wěn)定運(yùn)行驗(yàn)證超10個(gè)月。
與英偉達(dá)NDR相比,交換機(jī)端口密度提升25%,網(wǎng)卡最大QP數(shù)支持提升100%。

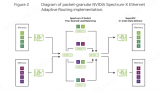
在擴(kuò)展性方面,傳統(tǒng)上InfiniBand的空間能支持到16位,使得其所支持最大的組網(wǎng)規(guī)模只能做到不到5萬(wàn)卡,這難以滿足當(dāng)前算力中心對(duì)于10萬(wàn)卡集群的需求。中科曙光通過(guò)重點(diǎn)優(yōu)化擴(kuò)展性,可以將scaleFabric網(wǎng)絡(luò)規(guī)模支持到11.4萬(wàn)卡,比傳統(tǒng)IB提升2.33倍,同時(shí),也利用端口密度優(yōu)勢(shì),整體組網(wǎng)成本可以下降30%。實(shí)測(cè)數(shù)據(jù),基本上做到和NDR相當(dāng)?shù)乃剑糠謹(jǐn)?shù)據(jù)甚至優(yōu)于NDR系列,在性能上已經(jīng)完全具備和國(guó)際競(jìng)爭(zhēng)水平。


生態(tài)建設(shè)方面,注重與IB的生態(tài)兼容,scaleFabric提供原生接口,可以全面兼容各種通信庫(kù),無(wú)縫兼容各種HPC和AI應(yīng)用、大模型訓(xùn)練,可以在不改代碼的情況下,直接遷移到基于scaleFabric的系統(tǒng)上,做到應(yīng)用無(wú)感。同時(shí),在網(wǎng)絡(luò)管理和維護(hù)方面,都兼容IB用戶的使用習(xí)慣,方便將過(guò)去IB用戶對(duì)于IB的使用經(jīng)驗(yàn)無(wú)縫遷移到scaleFabric。針對(duì)新型智算場(chǎng)景例如IDMA等新型模式,scaleFabric也能做到支持,更好地幫助用戶始終站在AI創(chuàng)新的最前沿。
為何選擇InfiniBand路線?
長(zhǎng)期以來(lái),從高速SerDes IP、核心芯片到IB網(wǎng)卡、IB交換機(jī)等設(shè)備,InfiniBand相關(guān)產(chǎn)業(yè)鏈基本被海外廠商壟斷。隨著AI算力需求快速增長(zhǎng)及數(shù)據(jù)中心網(wǎng)絡(luò)持續(xù)演進(jìn),自主高性能RDMA網(wǎng)絡(luò)正成為產(chǎn)業(yè)關(guān)注焦點(diǎn)。
在大規(guī)模智算集群領(lǐng)域,RDMA(遠(yuǎn)程直接內(nèi)存訪問(wèn))網(wǎng)絡(luò)已成為算力中心的基本需求,憑借零丟包、高帶寬、低延遲等特征,可極大提升通信效率。其中,InfiniBand憑借低時(shí)延與原生無(wú)損傳輸能力,在全球頂級(jí)超算與AI集群中被廣泛采用。根據(jù)TOP500榜單,目前全球約60%的高性能計(jì)算系統(tǒng)采用InfiniBand網(wǎng)絡(luò)架構(gòu)。
中科曙光高級(jí)副總裁李斌表示,當(dāng)前400G端口帶寬網(wǎng)絡(luò)逐漸成為HPC/AI集群網(wǎng)絡(luò)主流,未來(lái)向800G持續(xù)演進(jìn)。在這一領(lǐng)域,RDMA網(wǎng)絡(luò)成為算力中心的基本需求,成為整個(gè)AI網(wǎng)絡(luò)的事實(shí)上的標(biāo)準(zhǔn)。在這一領(lǐng)域,實(shí)際上存在著兩大技術(shù)路線,分別是InfiniBand和RoCE,雖然當(dāng)前有一個(gè)呼聲,由互聯(lián)網(wǎng)大廠推動(dòng)用RoCE取代InfiniBand,但是實(shí)際上InfiniBand的技術(shù)路線在AI/HPC中有不可替代的優(yōu)勢(shì),是真正的無(wú)損網(wǎng)絡(luò),而無(wú)損的特性對(duì)RDMA性能的發(fā)揮具有優(yōu)勢(shì),便于更好對(duì)網(wǎng)絡(luò)進(jìn)行管理。

“在RDMA網(wǎng)絡(luò)中,少量丟包會(huì)造成性巨大的波動(dòng),這也是為什么曙光一直在堅(jiān)持走InfiniBand路線的原因。相比之下,RoCE需要大量的調(diào)優(yōu)等一系列的工作,才能保證達(dá)到無(wú)損的效率。InfiniBand天然的具備無(wú)損性質(zhì)。”因此,scaleFabric采用與InfiniBand相同的基于信用的機(jī)制和鏈路機(jī)制,使得無(wú)論應(yīng)用如何調(diào)整,都可以從理論上證明無(wú)損的狀態(tài),真正做到即插即用。
如何保證底層高速信號(hào)的質(zhì)量很關(guān)鍵,必須依靠高速Serdes的能力。因此,中科曙光組建研發(fā)團(tuán)隊(duì),自研高速Serdes IP,從而可以做到在42db衰減下實(shí)現(xiàn)百萬(wàn)分之一誤碼率。scaleFabric面向多樣化的各種復(fù)雜的鏈路環(huán)境下都有保證網(wǎng)絡(luò)穩(wěn)定可靠的底氣。
此外,曙光公司從系統(tǒng)出發(fā),研發(fā)了鏈路故障路由快速恢復(fù)技術(shù),可以將鏈路故障路由恢復(fù)時(shí)間降低到毫秒級(jí),延時(shí)不會(huì)隨著網(wǎng)絡(luò)規(guī)模的增長(zhǎng)而增長(zhǎng),保障應(yīng)用無(wú)感,進(jìn)一步保障網(wǎng)絡(luò)的可用性。
中科曙光已形成“算、存、網(wǎng)”一體方案
在大規(guī)模并行計(jì)算中一個(gè)計(jì)算任務(wù)的完成,涉及計(jì)算、存儲(chǔ)、網(wǎng)絡(luò)三個(gè)環(huán)節(jié)。其中計(jì)算負(fù)責(zé)運(yùn)算數(shù)據(jù),存儲(chǔ)負(fù)責(zé)提供數(shù)據(jù),網(wǎng)絡(luò)負(fù)責(zé)傳輸數(shù)據(jù)。如果任何其中一個(gè)環(huán)節(jié)成為瓶頸,整個(gè)系統(tǒng)的效能都會(huì)下降,尤其在上千節(jié)點(diǎn)、上萬(wàn)核心的計(jì)算規(guī)模下,各種性能瓶頸造成的不均衡狀態(tài)會(huì)被指數(shù)級(jí)放大。
中科曙光高速網(wǎng)絡(luò)互聯(lián)產(chǎn)品部總工程師萬(wàn)偉分析,從理論上看,計(jì)算任務(wù)的時(shí)間由計(jì)算、內(nèi)存訪問(wèn)、網(wǎng)絡(luò)通信,還有IO讀寫時(shí)間組成。因此,計(jì)算系統(tǒng)的效率并不等同于系統(tǒng)的峰值算力。隨著計(jì)算規(guī)模的擴(kuò)大,通信時(shí)間和IO時(shí)間占比會(huì)迅速上升,這實(shí)際上是阿姆達(dá)爾定律在工程系統(tǒng)中的實(shí)際體現(xiàn)。
從能效的角度來(lái)看,當(dāng)網(wǎng)絡(luò)性能不足時(shí)CPU在等待,服務(wù)器在耗電,但計(jì)算單元并沒(méi)有真正工作。算力利用率理論上可以達(dá)到90%以上,但在網(wǎng)絡(luò)瓶頸的情況下,算力利用率可能只有50%左右。也就是說(shuō),有接近一半的算力會(huì)被浪費(fèi)掉。
比如汽車的啟動(dòng)分析、航空仿真等工業(yè)仿真類應(yīng)用,其網(wǎng)絡(luò)規(guī)模巨大,通常會(huì)超過(guò)2億網(wǎng)格。計(jì)算規(guī)模巨大,一般要兩千核以上的資源進(jìn)行并行計(jì)算。數(shù)值規(guī)模巨大,單次任務(wù)產(chǎn)生的數(shù)值可達(dá)10TB以上。并且通信非常頻繁,節(jié)點(diǎn)間的進(jìn)程會(huì)進(jìn)行高頻的數(shù)據(jù)交換。因此,在這種場(chǎng)景下網(wǎng)絡(luò)的性能直接決定仿真的計(jì)算效能。
以工業(yè)界常用的Siemens Star CCM+為例說(shuō)明,隨著并行規(guī)模的擴(kuò)大,通信時(shí)間占比會(huì)迅速增加。當(dāng)規(guī)模達(dá)到2048核的時(shí)候,通信占比接近48%的時(shí)間。也就是說(shuō),我們的CPU有接近一半的算力是無(wú)法操作出來(lái)的。更關(guān)鍵的是,這類應(yīng)用對(duì)網(wǎng)絡(luò)延遲非常敏感,經(jīng)過(guò)測(cè)算,延遲每增加10微秒,其整體效能可能會(huì)下降20%。
因此,計(jì)算系統(tǒng)的性能不是單點(diǎn)的算力問(wèn)題,而是計(jì)算、存儲(chǔ)、網(wǎng)絡(luò)三要素的協(xié)同效率問(wèn)題。未來(lái)的高性能計(jì)算,本質(zhì)上是一項(xiàng)系統(tǒng)工程,只有三者協(xié)同優(yōu)化,系統(tǒng)才能發(fā)揮出真正的性能。
圍繞系統(tǒng)效能問(wèn)題,曙光在核心硬件層面進(jìn)行了系統(tǒng)布局。目前已經(jīng)完成了四款核心國(guó)產(chǎn)芯片的部署,包括國(guó)產(chǎn)CPU處理器、國(guó)產(chǎn)GPU加速器、P3E交換芯片以及片間的互聯(lián)芯片。這些芯片構(gòu)成了完整的國(guó)產(chǎn)算力技術(shù)結(jié)構(gòu)。
在網(wǎng)絡(luò)方面,中科曙光實(shí)現(xiàn)了核心能力的全棧自研,包括400G網(wǎng)卡芯片、800G交換芯片以及全面自研固件、驅(qū)動(dòng)軟件技管理軟件。在并行計(jì)算中,國(guó)產(chǎn)IB的效率達(dá)到85%左右,而傳統(tǒng)的RoCE方案效率只有65%。在實(shí)際CFD軟件應(yīng)用測(cè)試中,IB網(wǎng)絡(luò)通信在各節(jié)點(diǎn)規(guī)模下保持較高效率,即使節(jié)點(diǎn)增加到64節(jié)點(diǎn)以上,scaleFabric效率仍保持70%-80%,遠(yuǎn)高于RoCE的方案。總的來(lái)說(shuō),IB網(wǎng)絡(luò)是處理復(fù)雜計(jì)算網(wǎng)絡(luò)的一個(gè)理想選擇。
在存儲(chǔ)方面,目前曙光做了分布式自研存儲(chǔ)系統(tǒng),主要特點(diǎn)包括高穩(wěn)定性、低延時(shí)和高吞吐。同時(shí)實(shí)現(xiàn)了5級(jí)緩存加速體系,可以實(shí)現(xiàn)計(jì)算節(jié)點(diǎn)的內(nèi)存到緩存到全棧存儲(chǔ)。對(duì)整個(gè)數(shù)值路徑進(jìn)行了優(yōu)化,最終帶來(lái)的效果,IO性能最高提高到20倍左右。

為了實(shí)現(xiàn)存算傳的協(xié)同,中科曙光重點(diǎn)突破了四項(xiàng)關(guān)鍵技術(shù)。第一,高速互連網(wǎng)絡(luò)加高帶寬內(nèi)存。第二,并行分布式文件系統(tǒng)。第三,GPU直連網(wǎng)絡(luò)通信。第四,NUMA的拓?fù)鋬?yōu)化。通過(guò)這些技術(shù),可以大幅降低通信延遲、訪問(wèn)延遲以及訪問(wèn)沖突,從而提升系統(tǒng)的整體效能。
基于算存?zhèn)鞯?a href="http://www.3532n.com/tags/耦合/" target="_blank">耦合架構(gòu),從系統(tǒng)層面進(jìn)行協(xié)同優(yōu)化,實(shí)現(xiàn)20倍的IO性能提升,GPU算力利用率最高可以提升30%,同時(shí)網(wǎng)絡(luò)帶寬提升2倍,網(wǎng)絡(luò)延遲降低3倍,整體可以實(shí)現(xiàn)1+1+1大于3的效果。
為了將這些技術(shù)真正落地,曙光公司推出scaleX超集群系統(tǒng),將計(jì)算、互聯(lián)和散熱進(jìn)行了深度的一體化集成。在scaleX中,單機(jī)柜可以集成640張GPU加速卡,并通過(guò)全鏈互聯(lián)的正交網(wǎng)絡(luò)架構(gòu),實(shí)現(xiàn)超帶寬、低延遲的節(jié)點(diǎn)間通信。同時(shí),整套系統(tǒng)采用浸沒(méi)式相變液冷技術(shù),最高可以支持860千瓦級(jí)的功率密度,可以顯著提升數(shù)據(jù)中心的能效水平。可以說(shuō)scaleX超集群不僅是算力設(shè)備,更是曙光面向未來(lái)智能計(jì)算的系統(tǒng)級(jí)的架構(gòu)創(chuàng)新。
在實(shí)際應(yīng)用層面,scaleFabric目前已部署于位于鄭州的國(guó)家超算互聯(lián)網(wǎng)核心節(jié)點(diǎn),支撐三套萬(wàn)卡級(jí)scaleX智算集群上線運(yùn)行,總規(guī)模達(dá)3萬(wàn)卡。整個(gè)網(wǎng)絡(luò)部署只用了36個(gè)小時(shí),目前累計(jì)1萬(wàn)個(gè)客戶和10萬(wàn)+的作業(yè)。
隨著產(chǎn)品在超大規(guī)模智算集群中的落地應(yīng)用,國(guó)產(chǎn)原生RDMA技術(shù)路線正逐步走向成熟,圍繞其形成的高性能網(wǎng)絡(luò)產(chǎn)業(yè)生態(tài)也正在加速形成。
開放生態(tài),打造大規(guī)模普惠的高速網(wǎng)絡(luò)產(chǎn)品
曙光信息產(chǎn)業(yè)(北京)有限公司副總裁李柳表示,我們將牽頭成立光合組織高性能計(jì)算專委會(huì)AIDC高速網(wǎng)絡(luò)工作組,未來(lái)以開放的姿態(tài)聯(lián)合更多的國(guó)內(nèi)合作伙伴建立技術(shù)標(biāo)準(zhǔn),基于這個(gè)平臺(tái)打造生態(tài)適配系統(tǒng),同時(shí)聯(lián)合國(guó)內(nèi)的一些科研力量,形成產(chǎn)學(xué)研體系,共同探索產(chǎn)業(yè)應(yīng)用與發(fā)展。
萬(wàn)偉認(rèn)為,從技術(shù)路線上來(lái)說(shuō),我們有ScaleUp互聯(lián),ScaleOut互聯(lián),特別是超大規(guī)模系統(tǒng)上的性能和擴(kuò)展性等方面做了考量。未來(lái)還將探索包括不同協(xié)議的融合,例如可能在原生RDMA上兼容RoCE等。另外,針對(duì)不同芯片的兼容性,和不同計(jì)算芯片的互聯(lián),將探索更高效的方式,比如計(jì)算芯片通過(guò)專有協(xié)議到網(wǎng)卡、芯片互聯(lián)協(xié)議的共享,與其他芯片直通等等。
李斌表示,面向未來(lái),我們有信心把scaleFabric打造成國(guó)內(nèi)大規(guī)模廣泛使用且非常普惠的高速網(wǎng)絡(luò)產(chǎn)品。不僅是技術(shù)和產(chǎn)品保持國(guó)際競(jìng)爭(zhēng)力,更重要的是秉持開放的態(tài)度,集合國(guó)內(nèi)算力廠商、系統(tǒng)集成、整機(jī)廠商等,串連整個(gè)產(chǎn)業(yè)鏈上下游的合作伙伴,在定義標(biāo)準(zhǔn)、接口、協(xié)議、以及商業(yè)模式等方面展開全方位的開放合作。
發(fā)布評(píng)論請(qǐng)先 登錄
國(guó)產(chǎn)網(wǎng)絡(luò)變壓器廠家迭代:從國(guó)產(chǎn)替代到自主創(chuàng)新
重大突破!中科曙光scaleFabric國(guó)產(chǎn)原生RDMA高速網(wǎng)絡(luò)首發(fā)

中國(guó)移動(dòng)聯(lián)合華為榮獲GSMA GLOMO“最佳AI使能網(wǎng)絡(luò)解決方案獎(jiǎng)”
華為和中國(guó)移動(dòng)聯(lián)合發(fā)布2025年度高階示范區(qū)AI+網(wǎng)絡(luò)實(shí)踐成果
GlobalData與華為探討AI對(duì)網(wǎng)絡(luò)基礎(chǔ)設(shè)施的機(jī)遇與挑戰(zhàn)
AI賦能6G與衛(wèi)星通信:開啟智能天網(wǎng)新時(shí)代
AI網(wǎng)絡(luò)國(guó)產(chǎn)化破局未來(lái)可期
睿海光電 200G 有源光纜:AI 時(shí)代高速互聯(lián)的技術(shù)標(biāo)桿與場(chǎng)景實(shí)踐
睿海光電以高效交付與廣泛兼容助力AI數(shù)據(jù)中心800G光模塊升級(jí)
華為網(wǎng)絡(luò)智能體NetMaster榮獲2025 AI網(wǎng)絡(luò)技術(shù)“智驅(qū)應(yīng)用標(biāo)桿獎(jiǎng)”
行業(yè)AI先鋒,為何網(wǎng)絡(luò)先行?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論