 為什么一段式端到端自動駕駛很難落地?
為什么一段式端到端自動駕駛很難落地?

[首發于智駕最前沿微信公眾號]自動駕駛技術在過去十年中經歷了從基礎輔助駕駛到高度自動化系統的快速演進。在這一進程中,技術架構的選擇始終是決定行業走向的核心命題。傳統的自動駕駛系統被設計為模塊化結構,將感知、預測、規控等任務拆分為相互獨立的子系統。然而,隨著深度學習技術的突破,端到端的新興技術架構開始占據討論的中心。
在這一架構中,一段式端到端主張將傳感器輸入直接映射為駕駛動作輸出,力求通過單一的神經網絡模型實現對復雜交通環境的理解與響應。盡管這種路徑在提高駕駛平順性和處理某些復雜場景方面展示了驚人的潛力,但在真正的商業化落地過程中,一段式端到端架構依然面臨著很多挑戰。
一段式端到端的優勢
一段式端到端自動駕駛的核心理念在于極度簡化系統鏈路。在傳統的模塊化架構中,信息在感知、融合、預測、決策、規劃和控制等多個環節之間傳遞。這種設計雖然職責明確,但存在嚴重的傳遞效應誤差。每一個模塊的輸出都只是對真實物理世界的一種抽象和簡化,而這種簡化不可避免地會導致信息的損耗。

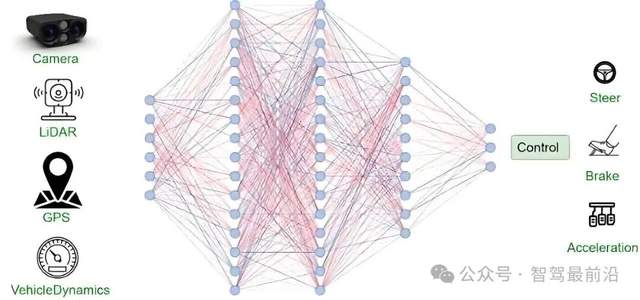
一段式端到端示意圖,圖片源自:網絡
例如,感知模塊可能只識別出了前方車輛的坐標和速度,卻丟失了該車剎車燈閃爍的微弱光影變化或車輪壓線的細微趨勢,這些被過濾掉的非結構化信息往往包含駕駛意圖的關鍵線索。相比之下,一段式端到端架構通過單一的深層神經網絡,試圖實現信息的無損傳遞,讓模型可以直接從原始的視頻流或點云數據中提取對駕駛任務最有用的特征。
這種架構的優越性在復雜交通環境中表現得尤為明顯。傳統基于規則的系統在面對從未被定義的特殊場景時,會因為找不到匹配的代碼邏輯而陷入癱瘓或觸發緊急制動。
一段式端到端模型通過對海量人類駕駛數據的模仿學習,能夠學到人類司機的駕駛常識和直覺反應。在實際測試中,車輛在處理無保護左轉、繞行違停車輛以及與行人互動時可以表現出擬人化的平順感,這正是數據驅動架構帶來的紅利。這種架構從底層邏輯上顛覆了自動駕駛的研發模式,主機廠不再需要編寫成千上萬行復雜的判斷語句,而是可以將精力集中在數據質量的提升和模型結構的優化上。
| 架構維度 | 傳統模塊化架構 | 一段式端到端架構 | 技術影響分析 |
| 信息流轉 | 結構化抽象數據傳輸 | 原始特征流無損傳輸 | 一段式減少了模塊間的信息過濾與損失 |
| 優化目標 | 各模塊獨立優化局部指標 | 全局統一優化駕駛任務 | 一段式能實現整體性能的最優平衡 |
| 邏輯實現 | 手寫規則與邏輯判斷 | 神經網絡自動提取特征 | 一段式降低了人工維護代碼的復雜度 |
| 系統靈活性 | 模塊間解耦,易于局部更換 | 模塊間解耦,易于局部更換 | 一段式架構在迭代時面臨更大的技術負擔 |
一段式端到端不得不面對的黑盒和誤差積累
一段式端到端架構雖然在理論上提高了性能上限,卻也模糊了系統的邊界。在傳統架構中,如果感知錯了,可以清晰地看到是哪個算法模塊沒識別出目標;而在一段式模型中,感知、預測和規劃被揉合在一起,這種深度耦合意味著任何局部的微調都可能引發不可預見的全局波動。系統的優化目標也從各個模塊的局部指標轉向了全局的駕駛表現,這在提升系統效率的同時,也極大地增加了訓練的復雜度和對高質量數據的依賴程度。
在一個包含數億甚至數十億參數的深層神經網絡中,很難追蹤某個特定的控制指令究竟是由哪個輸入像素或哪一層神經元的激活引起的。這種特性在安全敏感的自動駕駛領域會引發巨大的問題。當系統在路測中出現一次嚴重的違章或事故苗頭時,將無法像模塊化架構那樣通過查看代碼邏輯發現錯誤原因,傳統的針對性單元測試在面對這種黑盒模型時也幾乎失去了效用。
這種技術黑盒還帶來了級聯誤差問題,這在閉環測試中表現得尤為突出。模型在實際行駛中若產生一個微小偏差,如果沒有及時的反饋修正機制,會在隨后的時間步中不斷累積,最終導致嚴重的駕駛事故。這是因為一段式模型在訓練時僅采用專家軌跡作為參照,但在實際部署中,它不僅要處理外部環境的變化,還要應對自身動作引發的連鎖反應。如果模型未能學會如何從偏離狀態中自我恢復,這種積累的誤差將成為系統崩潰的導火索。

圖片源自:網絡
為了緩解這些問題,行業開始探索輔助性的解釋工具。一些研究嘗試引入注意力圖可視化技術,通過觀察模型在決策時主要關注圖像的哪些區域來反向推論其邏輯。然而,這種方法只能提供定性的參考,無法作為嚴格的安全證明。
還一種常見的做法是在端到端模型外包裹一層基于規則的安全底座,當模型的輸出違反了基礎物理定律或嚴苛的交通準則時,可強制介入并修正指令。但這種方式會破壞端到端架構本來的絲滑感,導致系統在神經網絡的靈活決策與規則層的生硬約束之間產生激烈的沖突。
端到端還會導致因果混淆現象。機器學習模型傾向于尋找輸入與輸出之間的統計相關性,而不是真實的物理規律。舉個例子,模型可能學會前方車輛剎車燈亮起就要減速這么一個行為,卻不知道是因為接近障礙物需要減速。如果在某些特殊環境下這種偽相關性消失了,模型就可能喪失正確的決策能力。這種背答案式的學習方式使得模型在跨區域、跨場景應用時極度吃力,一個在特定城市訓練出的模型,由于路牌樣式、駕駛習慣甚至植被特征的不同,也很難直接搬運到另一個完全不同的環境中。
算力與數據的競爭壁壘及其社會化阻力
一段式端到端架構是典型的重資源投入路徑。它不僅需要車端擁有高算力的AI芯片來保證低延遲推理,更需要云端擁有極其龐大的算力中心來進行模型的高頻迭代。對于許多資金實力有限或缺乏自研芯片能力的企業來說,構建數據閉環系統和采購海量計算卡的成本已經超出了單車利潤的覆蓋范圍。這就形成了一種潛在的技術壟斷,只有擁有數萬塊高端計算卡和海量實時路測數據的頭部玩家,才有資格在這一路徑上進行長期的競賽。這種對算力規模的高度需求,使得一段式端到端技術落地的門檻被無限拉高。
數據的純凈度與分布規律也是限制一段式端到端落地的一個因素。神經網絡極其擅長在數據密集的區域進行模仿,但在數據稀疏的邊緣地帶表現得就非常脆弱。在真實交通場景中,絕大多數的駕駛數據都是在正常的交通流中產生的,而發生事故、極端天氣或罕見路障的數據占比極低。模型在面對這些從未見過的邊緣場景時,可能做出完全不可預測的錯誤決策。

圖片源自:網絡
此外,如果模型無差別地模仿從量產車回傳的人類駕駛數據,它學到的除了高效的駕駛技能,還可能包括強行加塞、不按規定開啟轉向燈等不文明行為,這將導致學習結果與預期不符。因此,如何從海量數據中精準篩選出高質量、符合安全邏輯的駕駛片段,是端到端架構落地的關鍵所在。
在法律與責任認定方面,一段式端到端架構也面臨著前所未有的挑戰。當自動駕駛系統從基于規則的模式轉向基于神經元連接的模式時,現有的責任認定體系將受到巨大沖擊。在傳統系統中,如果發生事故,相關部門可以通過回溯日志發現是因為某個特定的算法模塊失靈,責任判定相對清晰。然而,面對黑盒模型,要向監管機構解釋系統為什么做出某個決策幾乎是不可能的。目前全球范圍內的立法趨勢仍傾向于要求系統具備完備的可觀察性與數據存證能力,端到端這種合規性真空使得監管機構對大規模部署一段式端到端系統保持審慎態度。
最后的話
雖然目前一段式端到端在可解釋性、誤差累積以及社會化定責等方面存在很多的問題,但這些障礙本身也在倒逼自動駕駛算法向更深層次的因果推斷和更高效的數據閉環演進。技術的落地從來不是一蹴而就的,它需要工程實踐的反復錘煉和法律倫理的逐步接納。通過在神經網絡的黑盒中注入確定性的安全邏輯,或者在規則系統的外殼下賦予模型更強的數據感知力,一段式端到端架構終將在性能上限與安全下限之間找到那個完美的支點。
審核編輯 黃宇
-
端到端
+關注
關注
0文章
50瀏覽量
10852 -
自動駕駛
+關注
關注
794文章
14931瀏覽量
180670
發布評論請先 登錄

如何訓練好自動駕駛端到端模型?

西井科技端到端自動駕駛模型獲得國際認可
一文讀懂特斯拉自動駕駛FSD從輔助到端到端的演進
端到端自動駕駛相較傳統自動駕駛到底有何提升?
博世一段式端到端方案打造智能輔助駕駛體驗
一段式端到端在自動駕駛中到底有何優勢?
為什么自動駕駛端到端大模型有黑盒特性?

端到端數據標注方案在自動駕駛領域的應用優勢
自動駕駛中基于規則的決策和端到端大模型有何區別?



 工商網監
工商網監
評論