 NVIDIA BlueField-4為推理上下文記憶存儲平臺提供強大支持
NVIDIA BlueField-4為推理上下文記憶存儲平臺提供強大支持

來源:NVIDIA英偉達網絡
隨著代理式 AI 工作流將上下文窗口擴展到數百萬個 token,并將模型規模擴展到數百萬億個參數,AI 原生企業正面臨著越來越多的擴展挑戰。這些系統目前依賴于智能體長期記憶來存儲跨多輪、工具和會話持續保存的上下文,以便智能體能夠基于先前的推理進行構建,而不是每次請求都從頭開始。
隨著上下文窗口的增加,KV 緩存(鍵值緩存)容量需求也相應增長,而重新計算歷史記錄的計算需求增長得更快,這使得 KV 緩存復用和高效存儲對于性能和效率至關重要。
這增加了現有內存層級結構的壓力,迫使 AI 提供商在稀缺的 GPU 高帶寬內存(HBM)和針對持久性、數據管理和保護而優化的通用存儲層級之間做出選擇,而不是為短暫的 AI 原生 KV 緩存提供服務,從而推高了功耗,增加了每個 token 的成本,并導致昂貴的 GPU 未得到充分利用。
NVIDIA Rubin 平臺支持 AI 原生企業擴展推理基礎設施,滿足智能體時代的需求。該平臺將 AI 基礎設施組織成計算 Pod,這些 Pod 包括 GPU 的多機架單元,NVIDIA Spectrum-X 以太網網絡和存儲,是 AI 工廠橫向擴展的基礎構建模塊。
在每個 Pod 中,NVIDIA 推理上下文記憶存儲(ICMS)平臺提供了一種專為大規模推理而設計的全新 AI 原生存儲基礎設施。NVIDIA Spectrum-X 以太網提供可預測、低延遲和高帶寬的 RDMA 連接,確保對大規模共享 KV 緩存具有一致、低抖動的數據訪問。
在 NVIDIA BlueField-4 數據處理器的支持下,Rubin 平臺構建了一個優化的上下文記憶層,通過保持延遲敏感、可復用的推理上下文并對其進行預加載來提高 GPU 利用率,從而增強現有的網絡對象和文件存儲。它提供額外的上下文存儲,使每秒 token(TPS)提高了 5 倍,并且比傳統存儲的能效提高了 5 倍。
本文介紹了不斷增長的代理式 AI 工作負載和長上下文推理如何給現有內存和存儲層級帶來越來越大的壓力,并介紹了 NVIDIA 推理上下文記憶存儲(ICMS) 平臺作為 Rubin AI 工廠中的全新上下文層,從而提供更高的吞吐量、更高的能效和可擴展的 KV 緩存復用。
全新的推理范式和上下文存儲挑戰
隨著模型從簡單的聊天機器人演變為復雜的多輪智能體工作流,企業面臨著新的可擴展性挑戰。如今,基礎模型的參數數量已達到數萬億,上下文可容納數百萬個 token,三大 AI 擴展定律(預訓練、后訓練和推理時擴展)正在推動計算密集型推理的激增。智能體不再是無狀態的聊天機器人,而是依賴于對話、工具和中間結果的長期記憶,這些記憶可跨服務共享,并能隨時間推移被反復調取。
在基于 Transformer 架構的模型中,長期記憶以推理上下文的形式實現,也稱為 KV 緩存。KV 緩存能夠保存推理階段的上下文信息,從而避免模型為生成每個新 Token 而重復計算歷史數據。隨著序列長度的增加,KV 緩存的規模會呈線性增長,迫使其在更長的會話中持續保存,并可在多個推理服務之間實現共享。
這種演進將 KV 緩存定位為一種由特定二元性定義的獨特 AI 原生數據:它對性能是至關重要的,但本質上又是短暫的。在智能體系統中,KV 緩存已然成為模型的長期記憶,可以在多個步驟中被復用與擴展,而不是在單次提示響應后即被丟棄。
與不可篡改的企業記錄不同,推理上下文是派生的且可重新計算的,因此需要一種存儲架構,該架構更優先考慮能效、成本效益以及速度和可擴展性,而非傳統的數據持久性。在現代 AI 基礎設施中,這意味著每兆瓦的電力最終都取決于它能提供多少有用的 token。
要滿足這些需求,已經使現有的內存和存儲層達到極限。因此,各企業正在重新思考如何在 GPU 內存、主機內存和共享存儲之間保存上下文。
為了厘清這一技術鴻溝,我們不妨先審視一下推理上下文目前是如何在 G1–G4 層級結構中的流轉機制(圖 1)。AI 基礎設施團隊使用各種編排框架,例如 NVIDIA Dynamo 來幫助管理這些存儲層級之間的上下文:
G1(GPU HBM):用于正在執行生成過程中的訪問頻率較高且延遲敏感的 KV 緩存
G2(系統 RAM):用于暫存和緩存從 HBM 移出的 KV 緩存
G3(本地 SSD):用于存儲可短期被復用的、訪問頻率適中的 KV 緩存
G4(共享存儲):用于存儲訪問頻率較低的數據資產、歷史記錄和運算結果,此類數據需滿足持久性要求,但不處于即使關鍵業務路徑上
G1 針對訪問速度進行了優化,而 G3 和 G4 則針對持久性進行了優化。隨著上下文的增長,KV 緩存會迅速耗盡本地存儲容量(G1-G3),同時將部分數據存儲到企業級存儲(G4),這會帶來難以接受的性能開銷,并導致成本和功耗的攀升。
圖 1 展示了這種權衡關系,顯示了 KV 緩存在內存和存儲層級中遠離 GPU 的同時,其使用成本是如何隨之持續攀升的。
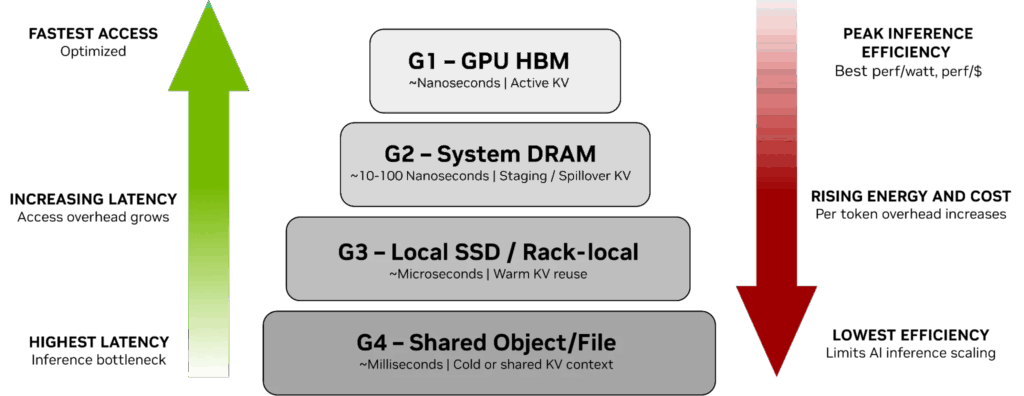
圖 1. 從 GPU 內存(G1)到共享存儲(G4), KV 緩存存儲層級結構
在整個存儲層級架構的頂層,GPU HBM(G1)可提供納秒級訪問和超高效率,使其成為直接用于 token 生成的活躍 KV 緩存。隨著上下文超出 HBM 的物理限制,KV 緩存會擴展到系統 DRAM(G2)和本地/機架內存儲(G3)中,此時訪問延遲會增加,每個 token 的能耗和成本開始上升。雖然這些層級擴展了有效容量,但每向下遷移一個層級,都會產生額外的開銷,從而降低整體效率。
在整個存儲層級架構的底層,共享對象和文件存儲(G4)可提供持久性和存儲容量,但延遲將達到毫秒級,推理效率也是最低的。雖然它適用于存儲訪問頻率較低的或共享的數據資產,但將活躍或頻繁復用的 KV 緩存保存到此層級會增加功耗,并直接限制 AI 擴展的成本效益。
核心結論可總結為——延遲和效率緊密相關:隨著推理上下文遠離 GPU,訪問延遲將增加,能耗和每個 token 的成本將會上升,整體效率將會下降。性能優化內存和容量優化存儲之間日益擴大的差距,迫使 AI 基礎設施團隊重新思考如何在整個系統中存儲、管理和擴展不斷增長的 KV 緩存上下文。
AI 工廠需要一個互補的、專門構建的上下文層,將 KV 緩存視為其自身的 AI 原生數據類型,而不是將其強制存儲于稀缺的 HBM 或通用企業級存儲之中。
NVIDIA 推理上下文記憶存儲平臺
NVIDIA 推理上下文記憶存儲平臺是一套完全集成的存儲基礎設施。該平臺利用 NVIDIA BlueField-4 數據處理器(DPU),構建在 Pod 級別運行的專用上下文記憶層,以彌合高速 GPU 內存和可擴展共享存儲之間的性能差距。這可以加速 POD 內各節點之間的 KV 緩存數據訪問和高速數據共享,從而提高性能并優化功耗,以滿足日益增長的大規模上下文推理需求。
該平臺創建了一個新的 G3.5 層級,這是一個通過以太網連接的閃存層級,專門針對 KV 緩存進行了優化。該層級可以充當 AI 基礎設施 pod 的智能體長期記憶,其容量足夠大,可以為多個智能體存儲共享的且不斷演變的上下文,同時其距離足夠近,可以頻繁地將上下文預先加載回 GPU 和主機內存,而不會遲滯 Decode。
該層級為每個 GPU Pod 提供 PB 級的共享容量,使長上下文工作負載在從 HBM 和 DRAM 中移除后仍能保留歷史記錄。歷史記錄存儲在低功耗的閃存層級中,該層級擴展了 GPU 和主機內存層級結構。G3.5 層級可提供海量聚合帶寬,且效率高于傳統共享存儲。這使得 KV 緩存轉變為共享的高帶寬資源,編排器可以跨智能體和服務進行協作,而無需在每個節點上單獨重新實現。
由于 G3.5 層級現在提供了大部分對延遲敏感的臨時 KV 緩存服務,因此可以將高持久性的 G4 對象和文件存儲空間留給真正需要隨著時間推移而長期保存的數據。其中包括非活躍的多輪 KV 緩存數據、查詢歷史記錄、日志以及其他可能在后續會話中會被調用的多輪推理數據。
這減輕了 G4 的容量和帶寬壓力,同時保留了重要的應用級歷史記錄。隨著推理規模的擴大,G1–G3 KV 緩存容量會隨著 GPU 數量的增加而增長,但其容量太小,故仍然無法滿足所有 KV 緩存的存儲需求。推理上下文存儲平臺(ICMS)填補了 G1–G3 和 G4 之間缺失的 KV 緩存容量。
NVIDIA Dynamo 等推理框架將其 KV 塊管理器與 NVIDIA 推理傳輸庫(NIXL)協同使用,從而編排推理上下文在內存和存儲層級之間的傳輸,并使用 ICMS 作為 KV 緩存的上下文記憶層。這些框架中的 KV 管理器會預先加載 KV 塊,并在 Decode 階段之前將它們從 ICMS 傳輸至 G2 或 G1 內存。
這種可靠的預先暫存機制,得益于 ICMS 具有相較于傳統存儲更高的帶寬和更高的能效,旨在更大限度地減少遲滯和空閑時間,從而使長上下文和智能體工作負載的持續吞吐量(TPS)提升高達 5 倍。當與運行 KV I/O 控制平面的 NVIDIA BlueField-4 處理器結合使用時,該系統可高效替代 NVMe-oF 和對象/RDMA 協議。
下圖顯示了 ICMS 如何融入 NVIDIA Rubin 平臺和 AI 工廠堆棧。
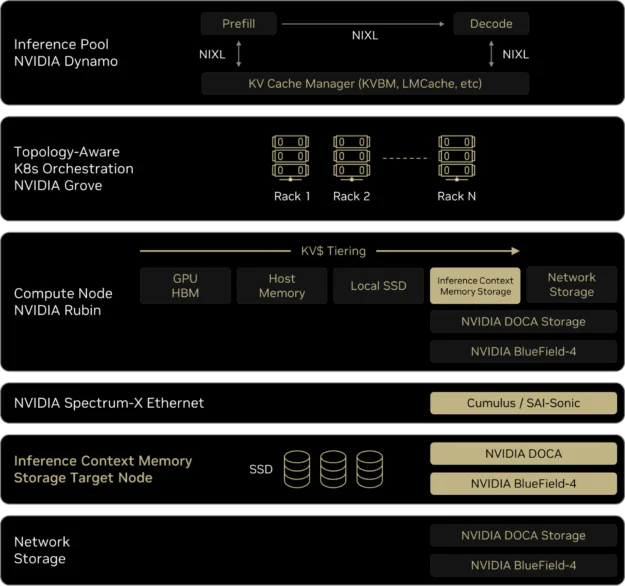
在推理層,NVIDIA Dynamo 和 NIXL 可管理 Prefill、Decode 和 KV 緩存,同時協調對共享上下文的訪問。在該層下,使用 NVIDIA Grove 的拓撲感知編排層將工作負載布置于具有 KV 局部性感知的機架上,從而使工作負載即使在節點之間移動也可以繼續復用上下文。
在計算節點層面,KV 分層涵蓋 GPU HBM、主機內存、本地 SSD、ICMS 和網絡存儲,為編排器提供了滿足存儲上下文的連續容量和延遲。Spectrum-X 以太網將 Rubin 計算節點與 BlueField-4 ICMS 目標節點連接起來,提供始終如一的低延遲和高效網絡連接,并將閃存支持的上下文記憶集成到用于訓練和推理的同一 AI 優化結構中。
賦能 NVIDIA 推理上下文記憶存儲平臺
NVIDIA BlueField-4 為 ICMS 提供強大的支持,提供 800Gb/s 的連接速度、64 核 NVIDIA Grace CPU 和高帶寬 LPDDR 內存。其專用硬件加速引擎可提供高達 800Gb/s 的線速加密和 CRC 數據保護。
這些加密和完整性加速器旨在作為 KV 管道的一部分,在不增加主機 CPU 開銷的情況下保護和驗證 KV 數據流。通過利用標準 NVMe 和 NVMe-oF 傳輸協議(包括 NVMe KV 擴展),ICMS 在保持與標準存儲基礎設施的互操作性的同時,還提供 KV 緩存所需的專屬性能。
該架構采用 BlueField-4 來加速 KV I/O 和控制平面操作,實現跨 Rubin 計算節點上的和 ICMS 閃存機箱中控制器上的 DPU 加速,從而減少對主機 CPU 的依賴,并更大限度地減少序列化操作和主機內存復制。此外,Spectrum-X 以太網提供經過 AI 優化的 RDMA 網絡架構,通過可預測的低延遲、高帶寬連接將 ICMS 閃存機箱和 GPU 節點連接起來。
此外,NVIDIA DOCA 框架引入了 KV 通信和存儲層,將上下文緩存視為 KV 管理、共享和保存的一級資源,充分利用 KV 塊和推理模式的獨特屬性。DOCA 與推理框架對接,BlueField-4 實現 KV 緩存與底層閃存介質的高效傳輸。
這種無狀態且可擴展的方法符合 AI 原生 KV 緩存策略,并利用 NIXL 和 Dynamo 實現跨 AI 節點的高級共享,并提高推理性能。DOCA 框架支持用于更廣泛編排的開放接口,為存儲合作伙伴提供了擴展且推理解決方案的靈活性,以涵蓋 G3.5 上下文存儲層。
Spectrum-X 以太網作為高性能網絡結構,支持基于 RDMA 的 AI 原生 KV 緩存訪問,從而為 NVIDIA 推理上下文記憶存儲平臺實現高效的數據共享和檢索。Spectrum-X 以太網專為 AI 而構建,可大規模提供可預測的低延遲、高帶寬的網絡連接。它通過先進的擁塞控制、動態路由和優化的無損 RoCE 來實現這一點,更大限度地降低高負載下的網絡抖動、尾部延遲和丟包。
憑借超高的有效帶寬、深度遙測和硬件輔助性能隔離,Spectrum-X 以太網能夠在大規模多租戶 AI 網絡架構中,實現一致且可重復的性能,同時保持完全基于標準協議并可與開放式網絡軟件兼容行交互操作。Spectrum-X 以太網使 ICMS 能夠以一致的高性能進行擴展,從而更大限度地提高多輪智能體推理工作負載的吞吐量和響應速度。
提供高能效、高吞吐量的 KV 緩存存儲
電力是 AI 工廠擴展的主要制約因素,因此能效是衡量大規模推理的關鍵指標。傳統的通用存儲堆棧犧牲了能效,因為它們在基于 x86 的控制器上運行,并在元數據管理、復制和后臺一致性檢查等功能上消耗大量能源,而這些功能對于暫存和可重構的 KV 數據來說是不必要的。
KV 緩存與企業級數據有著本質區別:它是瞬時的派生數據,即使丟失了也可以重新計算。作為推理上下文,它不需要為長期記錄設計的持久性、冗余性或全面的數據保護機制。將這些高負載的存儲服務應用于 KV 緩存會引起不必要的開銷,增加延遲和功耗,同時降低推理效率。通過將 KV 緩存視為一種獨特的 AI 原生數據類型,ICMS 消除了這種額外的開銷,與通用存儲方案相比,能效提高多達 5 倍。
這種效率提升不僅限于存儲層,還延伸至計算網絡結構本身。通過可靠地預加載上下文并減少或避免 Decode 停滯停機,ICMS 可防止 GPU 在空閑周期或重復歷史數據計算上浪費能源,從而將吞吐量(TPS)提高達 5 倍。這種方法可確保將功率直接用于主動推理,而不是基礎設施開銷,從而更大限度地提高整個 AI Pod 的有效每瓦 token 數量。
實現具有更好性能和 TCO 的大規模代理式 AI
基于 BlueField-4 的 ICMS, 為 AI 原生企業提供了一種擴展代理式 AI 的新方法:一個 POD 級上下文層,可擴展有效的 GPU 內存,并將 KV 緩存轉換為跨 NVIDIA Rubin POD 的共享高帶寬長期記憶資源。通過卸載 KV 移動并將上下文視為可復用的非持久數據類型,ICMS 可減少重新計算和 Decode 停滯,從而將更高的每秒 token 數量直接轉化為更多的查詢處理、更多的智能體并發運行、更短的大規模尾部延遲。
綜合上述這些收益可以提高總體擁有成本(TCO),使團隊能夠在一機架、統一機柜排或同一數據中心內部署更多的可用 AI 算力,同時延長現有基礎設施的使用壽命,并圍繞 GPU 算力而非存儲開銷來規劃未來的擴展。
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109719 -
存儲
+關注
關注
13文章
4787瀏覽量
90057 -
AI
+關注
關注
91文章
39755瀏覽量
301361
原文標題:NVIDIA BlueField-4 賦能的推理上下文記憶存儲平臺,引領 AI 邁向新前沿
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
堪稱史上最強推理芯片!英偉達發布 Rubin CPX,實現50倍ROI

NVIDIA DGX SuperPOD為Rubin平臺橫向擴展提供藍圖
NVIDIA BlueField-4數據處理器重塑新型AI原生存儲基礎設施
NVIDIA在CES 2026發布新一代Rubin AI平臺
深入解析NVIDIA Nemotron 3系列開放模型
大語言模型如何處理上下文窗口中的輸入

NVIDIA在ISC 2025分享最新超級計算進展
NVIDIA推出全新BlueField-4 DPU
請問riscv中斷還需要軟件保存上下文和恢復嗎?
米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
今日看點丨華為發布AI推理創新技術UCM;比亞迪汽車出口暴增130%
鴻蒙NEXT-API19獲取上下文,在class中和ability中獲取上下文,API遷移示例-解決無法在EntryAbility中無法使用最新版

S32K在AUTOSAR中使用CAT1 ISR,是否需要執行上下文切換?
NVIDIA 與行業領先的存儲企業共同推出面向 AI 時代的新型企業基礎設施




 工商網監
工商網監
評論