 深入解析NVIDIA Nemotron 3系列開放模型
深入解析NVIDIA Nemotron 3系列開放模型

這一全新開放模型系列引入了開放的混合 Mamba-Transformer MoE 架構,使多智能體系統能夠進行快速長上下文推理。
代理式AI系統日益依賴協同運行的智能體集合,包含檢索器、規劃器、工具執行器、驗證器等,它們需在大規模上下文上長時間協同工作。這類系統需要能夠提供快速吞吐、高推理精度及大規模輸入持續一致性的模型。它們也需要一定的開放性,使開發者能夠在任意運行環境定制、擴展和部署模型。
NVIDIANemotron3系列開放模型(Nano、Super、Ultra)、數據集和技術專為在新時代構建專業代理式AI而設計。
該系列引入了異構Mamba-Transformer混合專家(mixture-of-experts,MoE)架構、交互式環境強化學習(reinforcement learning,RL),以及原生100萬token上下文窗口,可為多智能體應用提供高吞吐量、長時推理能力。
Nemotron3的新特性
Nemotron3引入了多項創新技術,可精準滿足代理式系統需求:
混合Mamba-TransformerMoE主干提供出色的測試時效率與長程推理能力。
圍繞真實世界代理式任務設計的多環境強化學習。
100萬token上下文長度支持深度多文檔推理與長時間智能體記憶。
開放透明的訓練管道,包含數據、權重及方案。
Nemotron3 Nano現已推出并附帶現成使用指南。Super與Ultra將于稍晚發布。
簡單提示示例
Nemotron3模型的核心技術
混合Mamba-TransformerMoE架構
Nemotron3將三種架構整合成一個主干:
Mamba層:實現高效序列建模
Transformer層:保障推理精度
MoE路由:實現可擴展計算效率
Mamba層擅長以極低顯存開銷追蹤長程依賴,即使處理數十萬token仍能保持穩定的性能。Transformer層通過精細注意力機制對此進行了補充,捕捉例如代碼操作、數學推理或復雜規劃等任務所需的結構與邏輯關聯。
MoE組件在不增加密集計算開銷的前提下提升了有效參數數量。每個token僅激活一部分專家,從而降低了延遲并提高了吞吐量。該架構特別適合需要同時運行大量輕量級智能體的集群場景,每個智能體都生成計劃、檢查上下文或執行基于工具的工作流。
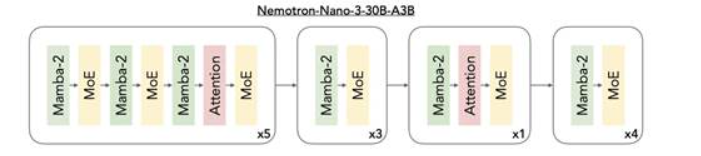
圖1:Nemotron3混合架構。該模型通過交錯部署Mamba-2與MoE層,輔以少量自注意力層,在保持領先精度的同時實現推理吞吐量最大化。
多環境強化學習(RL)訓練
為使Nemotron3契合真實代理式行為,該模型在NeMoGym(一個用于構建和擴展RL環境的開源庫)中通過跨多種環境的強化學習進行后訓練。這些環境評估模型執行連續動作序列的能力(不僅是單次響應),例如生成正確的工具調用、編寫功能性代碼,或生成滿足可驗證標準的多步驟計劃。
這種基于軌跡的強化學習帶來了在多步驟工作流中表現穩定的模型,減少推理漂移,并能處理代理式管道中常見的結構化操作。由于NeMoGym是開源的,開發者可在為特定領域任務定制模型時復用、擴展甚至創建自己的環境。
這些環境和RL數據集連同NeMoGym一起上線,供有意使用這些環境訓練自己模型的用戶使用。
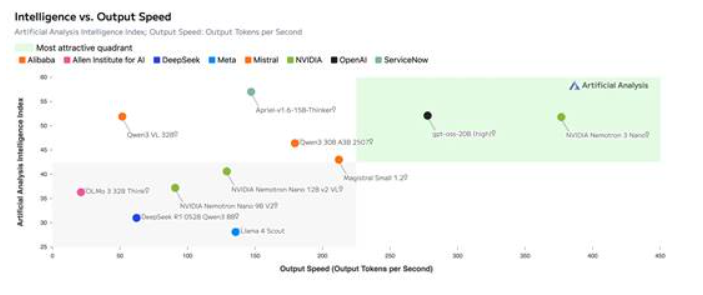
圖2:Nemotron3 Nano通過混合MoE架構實現極高的吞吐效率,并借助NeMoGym的先進強化學習技術達到領先精度
100萬token上下文長度
Nemotron3的100萬token上下文使其能夠在大型代碼庫、長文檔、擴展對話及聚合檢索內容中進行持續推理。智能體無需依賴碎片化的分塊啟發式方法,就可以在單個上下文窗口中完整保留證據集、歷史緩沖及多階段計劃。
這種長上下文窗口得益于Nemotron3的混合Mamba-Transformer架構,它能夠高效處理超大規模的序列。MoE路由也能保持較低的單個token計算成本,使得在推理時處理這些大型序列成為可能。
對于企業級檢索增強生成、合規性分析、多小時智能體會話或整體存儲庫理解等場景,100萬token窗口可顯著加固事實基礎并減少上下文碎片化。
Nemotron3 Super與Ultra的核心技術
潛在MoE
Nemotron3 Super與Ultra引入了潛在MoE,其中專家先在共享潛在表示中運行,然后再將輸出結果投影回token空間。該方法使模型能夠在相同推理成本下調用多達4倍的專家,從而更好地圍繞微妙語義結構、領域抽象或多跳推理模式實現專業化。
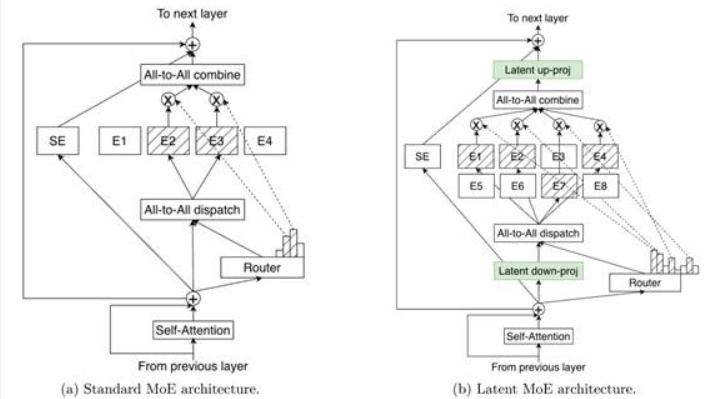
圖3:標準MoE與潛在MoE架構對比。在潛在MoE中,token被投影至更小的潛在維度進行專家路由與計算,在降低通信成本的同時支持更多專家參與,并提高每字節精度。
多token預測(MTP)
MTP使模型能夠在一次前向傳播中預測多個未來token,從而顯著提高長推理序列和結構化輸出的吞吐量。對于規劃、軌跡生成、擴展思維鏈或代碼生成,MTP可降低延遲并提高智能體的響應速度。
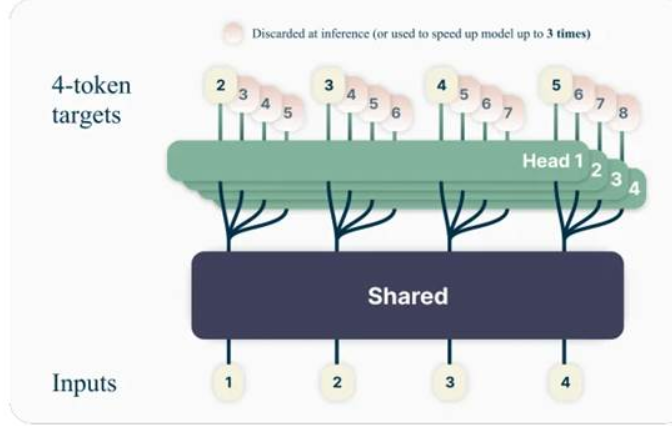
圖4:多token預測(源自論文《通過多token預測實現更優更快的大語言模型》)可同時預測多個未來token,在訓練階段將精度提高約2.4%,在推理階段實現了推測性解碼加速。
NVFP4訓練
Super與Ultra模型采用NVFP4精度進行預訓練,NVIDIA的4位浮點格式可為訓練與推理提供業界領先的成本精度比。我們為Nemotron3設計了更新版NVFP4方案,確保在25萬億token預訓練數據集上能夠實現精準且穩定的預訓練。預訓練過程中的大部分浮點乘加運算均采用NVFP4格式。
持續致力于開放模型
Nemotron3彰顯了NVIDIA對透明度與開發者賦能的承諾。該模型的權重已根據NVIDIA開放模型許可協議(NVIDIA Open Model License)公開發布。NVIDIA的合成預訓練語料庫(近10萬億token)可以被查閱或重用。開發者還可獲取NemotronGitHub庫中的詳細訓練與后訓練方案,實現完全的可復現性與定制化。
Nemotron3 Nano已發布,為高吞吐量、長上下文代理式系統奠定了基礎。Super與Ultra將于2026年上半年發布,將在此基礎上進一步深化推理能力和提高架構效率。
Nemotron3 Nano現已發布
系列首款模型Nemotron3 Nano已于近日發布。這個總參數300億、激活參數30億的模型專為DGX Spark、Hopper GPU及Blackwell GPU設計,讓用戶能夠使用Nemotron3系列中較高效的模型進行開發。
如果您想要了解更多關于Nemotron3 Nano的技術細節,可訪問Hugging Face博客,或閱讀技術報告。
該模型可達到極高的吞吐量效率,在Artificial Analysis Intelligence Index上成績領先,并且在Artificial AnalysisOpenness Index上保持了與NVIDIANemotronNano V2相同的分數。這充分展現了其在多智能體任務中的高效性,同時兼具透明度與可定制性。
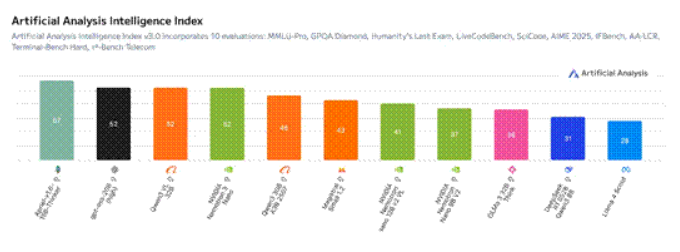
圖5:在Artificial AnalysisIntelligence Indexv3.0上,Nemotron3 Nano的精度(52)領先于同等規模模型。
開發者現可在多種部署與開發工作流中使用Nemotron3 Nano:
通過NVIDIA使用指南啟動模型
我們為多個主流推理引擎提供現成使用指南:
vLLM使用指南:通過高吞吐量連續批處理和流式輸出部署Nemotron3 Nano。
SGLang使用指南:運行專為多智能體工具調用工作負載優化的快速、輕量級推理。
TRT LLM使用指南:部署專為低延遲生產級環境完全優化的TensorRTLLM引擎。
每套使用指南均包含配置模板、性能優化建議及參考腳本,助您在數分鐘內啟動Nemotron3 Nano。
此外,從GeForce RTX臺式電腦/筆記本電腦、RTX Pro工作站到DGX Spark,您可以立即在任意NVIDIA GPU上使用Nemotron,并借助Llama.cpp、LM Studio和Unsloth等頂級框架與工具上手。
使用Nemotron開放訓練數據集進行開發
NVIDIA同時發布了在整個模型開發期間使用的開放數據集,為高性能、可信模型的構建帶來了空前的透明度。
新數據集的特點包括:
Nemotron預訓練:新的3萬億token數據集,通過合成增強與標注管道進行增強,更加全面地覆蓋代碼、數學及推理場景。
Nemotron后訓練3.0:1,300萬樣本語料庫,用于監督式微調與強化學習,為Nemotron3 Nano的對齊與推理能力提供支持。
Nemotron強化學習數據集:精選的強化學習數據集與環境集合,涵蓋工具使用、規劃及多步驟推理。
Nemotron智能體安全數據集:近1.1萬條AI智能體工作流軌跡集合,幫助研究人員評估和減輕代理式系統中的新型安全風險。
配合NVIDIANeMoGym、RL、Data Designer及Evaluator開放庫,這些開放數據集使開發者能夠訓練、增強和評估他們自己的Nemotron模型。
探索NemotronGitHub:預訓練與強化學習方案
NVIDIA維護著一個開放的NemotronGitHub庫,其中包含:
預訓練方案(已發布),展示Nemotron3 Nano的訓練過程
用于多環境優化的強化學習對齊方案
數據處理管道、分詞器配置及長上下文設置
后續更新將加入更多后訓練與微調方案
如果您想訓練自己的Nemotron、擴展Nano或創建特定領域的變體,GitHub庫提供了文檔、配置及工具,可從頭至尾重現關鍵步驟。
這種開放性實現了完整閉環:您可以運行、部署模型,查驗模型的構建方式,甚至訓練您自己的模型,全程僅需使用NVIDIA開放資源。
Nemotron3 Nano現已上線。即刻開始使用NVIDIA開放模型、開放工具、開放數據及開放訓練基礎設施,構建長上下文、高吞吐量的代理式系統。
Nemotron模型推理挑戰賽
加速開放研究是Nemotron團隊的核心使命。為此,我們十分高興地宣布一項新的社區競賽,其內容是使用Nemotron的開放模型與數據集提高Nemotron的推理性能。
關于作者
Chris Alexiuk 是 NVIDIA 的深度學習開發者倡導者,負責創建技術資源,幫助開發者使用 NVIDIA 提供的一整套強大 AI 工具。Chris 擁有機器學習和數據科學背景,對大型語言模型的一切充滿熱情。
Shashank Verma 是 NVIDIA 的一名深入學習的技術營銷工程師。他負責開發和展示各種深度學習框架中以開發人員為中心的內容。他從威斯康星大學麥迪遜分校獲得電氣工程碩士學位,在那里他專注于計算機視覺、數據科學的安全方面和 HPC 。
Chintan Patel是NVIDIA的高級產品經理,致力于將GPU加速的解決方案引入HPC社區。 他負責NVIDIA GPU Cloud注冊表中HPC應用程序容器的管理和提供。 在加入NVIDIA之前,他曾在Micrel,Inc.擔任產品管理,市場營銷和工程職位。他擁有圣塔克拉拉大學的MBA學位以及UC Berkeley的電氣工程和計算機科學學士學位。
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109719 -
AI
+關注
關注
91文章
39755瀏覽量
301362 -
模型
+關注
關注
1文章
3751瀏覽量
52099
原文標題:深入解析 NVIDIA Nemotron 3:使其高效精準的技術、工具與數據
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
面向科學仿真的開放模型系列NVIDIA Apollo正式發布
英偉達開源Nemotron-4 340B系列模型,助力大型語言模型訓練
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

NVIDIA推出開放式Llama Nemotron系列模型
NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺

ServiceNow攜手NVIDIA構建150億參數超級助手
歐洲借助NVIDIA Nemotron優化主權大語言模型
NVIDIA Nemotron Nano 2推理模型發布

利用NVIDIA Cosmos開放世界基礎模型加速物理AI開發
使用NVIDIA Nemotron RAG和Microsoft SQL Server 2025構建高性能AI應用
NVIDIA推動面向數字與物理AI的開源模型發展
NVIDIA 推出 Nemotron 3 系列開放模型




 工商網監
工商網監
評論