 NVIDIA在ISC 2025分享最新超級計算進展
NVIDIA在ISC 2025分享最新超級計算進展

從 NVIDIA DGX Spark 到 NVIDIA BlueField-4 DPU,新一代網絡和量子技術實現了飛躍。在 SC25 上展示的加速系統突顯了全球超級計算和 AI 的進展。
在 SC25 (全球超級計算大會) 上,NVIDIA 展示了在 NVIDIA BlueField DPU、新一代網絡、量子計算、科學研究、AI 物理等領域的進展。加速系統正推動 AI 超級計算的新篇章。
作為加速吉瓦 (Gigascale – 十億瓦) 級 AI 基礎設施的 BlueField 全棧平臺的一部分,NVIDIA 還重點介紹了 NVIDIA BlueField-4 DPU 帶來的存儲創新。
此外,還詳細介紹了 NVIDIA Quantum-X Photonics InfiniBand CPO 網絡交換機,此交換機如何助力 AI 工廠大幅降低能耗和運營成本,TACC、Lambda 和 CoreWeave 均計劃采用此交換機。
NVIDIA 創始人兼首席執行官黃仁勛驚喜現身 St. Louis 活動現場,并向出席 SC25 的觀眾分享了 NVIDIA 最新的超級計算進展。
“今年的重磅消息當屬 Grace Blackwell 平臺,大家或許已經關注到,我們第二代 Grace 平臺量產進展十分順利,”黃仁勛說,“可以說,我們現在制造超級計算機就像生產口香糖一樣。”
黃仁勛還帶來了一份特別禮物,NVIDIA DGX Spark AI 超級計算機,這是迄今為止全球最小的超級計算機。
黃仁勛說:“這就是 DGX Spark。你們當中有十位幸運兒將贏得這臺設備。這要是放在圣誕樹下作為禮物,是不是很酷?”
上個月,NVIDIA 開始交付 DGX Spark。這款是迄今為止全球最小的 AI 超級計算機。DGX Spark 將每秒千萬億次的 AI 性能和 128GB 統一內存集成于緊湊的臺式機外形中,使開發者能夠在多達 2000 億個參數的模型上運行推理,并在本地對模型進行微調。DGX Spark 基于 Grace Blackwell 架構打造,集成了 NVIDIA GPU、CPU、網絡、CUDA 庫和完整的 NVIDIA AI 軟件堆棧。
DGX Spark 的統一內存和 NVIDIA NVLink-C2C 互連提供了是 PCIe Gen5 的 5 倍帶寬,可實現更快的 GPU-CPU 數據交換。這提高了大型模型的訓練效率,降低了延遲,并支持無縫微調工作流程,所有這些都在桌面外形規格內完成。
最新的 AI 物理開放模型系列 NVIDIA Apollo 正式發布
NVIDIA 在 SC25 上還推出了面向 AI 物理的開放模型系列NVIDIA Apollo。Applied Materials、Cadence、LAM Research、Luminary Cloud、KLA、PhysicsX、Rescale、西門子和 Synopsys 等行業領先企業正采用這些開放模型來模擬和加速電子設備自動化和半導體、計算流體動力學、結構力學、電磁學、氣象等多個領域的設計流程。
該開放模型系列利用 AI 物理領域的最新成果,將神經運算符、Transformer 和擴散技術等領先的機器學習架構,與特定領域的知識相結合。Apollo 將提供用于訓練、推理和基準測試的預訓練檢查點和參考工作流,使開發者根據其特定需求集成和自定義模型。
NVIDIA Warp 助力物理模擬
NVIDIA Warp是一個專門構建的開源 Python 框架,可將計算物理和 AI 的 GPU 加速提升高達 245 倍。
NVIDIA Warp 為仿真、機器人和機器學習工作負載提供了一種結構化方法,它結合了 Python 的易用性以及與原生 CUDA 代碼相當的性能。
Warp 支持創建 GPU 加速的 3D 仿真工作流,這些工作流可與 PyTorch、JAX、NVIDIA PhysicsNeMo 和 NVIDIA Omniverse 中的機器學習(ML)工作流集成。這使開發者無需離開 Python 編程環境,即可運行復雜的仿真任務并大規模生成數據。
通過提供 CUDA 級性能和 Python 級生產力,Warp 簡化了高性能仿真工作流的開發。它旨在通過降低 GPU 編程的門檻來加速 AI 研究和工程,使高級仿真和數據生成更高效、更易于使用。
西門子、Neural Concept、Luminary Cloud 等公司正在采用 NVIDIA Warp。
展示為 AI 工廠操作系統賦能 NVIDIA BlueField-4
在 GTC 華盛頓特區上亮相的 NVIDIA BlueField-4 DPU 正在為 AI 工廠操作系統賦能。通過卸載、加速和隔離網絡、存儲和安全等關鍵的數據中心功能,NVIDIA BlueField-4 DPU 可以釋放 CPU 和 GPU,使其完全專注于計算密集型工作負載。
NVIDIA BlueField-4集成了 64 核 NVIDIA Grace CPU 和NVIDIA ConnectX-9,大幅提升了性能效率和零信任安全性。它支持多租戶環境、快速數據訪問和實時保護,并通過原生集成的NVIDIA DOCA微服務實現可擴展的容器化 AI 操作。這些技術共同推動數據中心向智能的、軟件定義引擎轉型,助力構建萬億級及更高級別 Token (詞元) 的 AI 應用。
隨著 AI 工廠和超級計算中心的規模和功能不斷擴展,需要更快、更智能的存儲基礎設施來管理結構化、非結構化和 AI 原生數據,以進行大規模訓練和推理。
領先的存儲創新企業 (DDN、VAST Data 和 WEKA) 正在采用 BlueField-4 來重新定義 AI 和科學工作負載的性能和效率。
DDN正在構建新一代 AI 工廠,加速數據流水線,以更大限度地提高處理 AI 和 HPC 工作負載的 GPU 利用率。
VAST Data正在通過跨大規模 AI 集群的智能數據傳輸和實時效率來推進 AI 流水線。
WEKA正在 BlueField-4 上推出 NeuralMesh 架構,可直接在 DPU 上運行存儲服務,以簡化和加速 AI 基礎設施。
這些高性能計算存儲領域的領先企業共同展示了 NVIDIA BlueField-4 如何改變數據傳輸和管理,將存儲轉變為下一代超級計算和 AI 基礎設施的性能加速器。
NVIDIA CPO (光電一體化封裝) 技術,提高速度和可靠性
TACC、Lambda 和 CoreWeave 宣布將于明年初在新一代系統中采用 NVIDIA Quantum-X Photonics CPO 交換機。
NVIDIA Quantum-X Photonics 網絡交換機能夠大幅降低 AI 工廠和超級計算中心的能耗和運營成本。NVIDIA 已經實現了融合電路和光通信一體的大規模部署。
隨著 AI 工廠發展到前所未有的規模,網絡必須與時俱進。通過取消傳統插拔式光模塊這一導致工作運行故障的常見原因,NVIDIA Photonics 交換機系統不僅將能效提高了 3.5 倍,而且可靠性提高了 10 倍,使應用能夠在不中斷的情況下運行時間延長 5 倍。
在硅谷舉辦的 GTC 2024 上,NVIDIA 推出了 NVIDIA Quantum-X800 InfiniBand 交換機,專為支持萬億級參數的生成式 AI 模型而打造。得益于 SHARPv4 和 FP8 等創新技術,這些平臺可提供驚人的 800Gb/s 端到端吞吐量,其帶寬是上一代產品的 2 倍,網絡計算能力是前代產品的 9 倍。
隨著 NVIDIA Quantum-X800 在大規模 AI 場景下的廣泛采用,今年早些時候在 GTC 上宣布推出的 NVIDIA Quantum-X Photonics 解決了更大規模部署中面臨的關鍵功率、可靠性和信號完整性的挑戰。通過將光引擎直接集成到交換機上,它可以消除插拔式光模塊帶來的故障和鏈路閃斷等問題,使工作負載能夠不間斷地大規模運行,并確保基礎設施能夠支持新一代計算密集型應用,可靠性相比插拔式光模塊高 5 倍。
Lambda 云基礎設施產品經理 Maxx Garrison 表示:“NVIDIA Quantum-X Photonics 代表了構建高性能、高可靠 AI 網絡的趨勢。這些在能效、信號完整性和可靠性方面的進步將成為支撐客戶高效、大規模工作負載的關鍵。”
SHARPv4 支持網絡內聚合和歸約,大幅減少了 GPU 到 GPU 的通信。SHARPv4 與 FP8 精度相結合,可以降低對通信帶寬和計算的需求,加速萬億級參數模型的訓練,實現更快的收斂和更高的吞吐量,是 NVIDIA Quantum-X800 和 Quantum-X Photonics 交換機的標配。
CoreWeave 聯合創始人兼首席技術官 Peter Salanki 表示:“CoreWeave 正在構建面向 AI 的 Essential Cloud。借助 NVIDIA Quantum-X Photonics,可以提高能效,并進一步增強 CoreWeave 在支持大規模 AI 工作負載方面廣受認可的高可靠性,來幫助我們的客戶充分發揮下一代 AI 的潛力。”
NVIDIA Quantum-X Photonics 平臺包括 NVIDIA Quantum Q3450 CPO InfiniBand 交換機和 ConnectX-8 SuperNIC,專為需要顯著降低功耗、提高可靠性和降低延遲的高性能環境而設計。
全球超級計算中心采用 NVQLink
全球十余個頂尖科學計算中心正在采用NVQLink,這是一種連接加速計算和量子處理器的通用互連技術。
NVIDIA 加速計算業務副總裁兼總經理 Ian Buck 表示:“在 SC 上,我們宣布正在與全球各地的超級計算中心合作。這些中心致力于構建新一代量子 GPU、CPU GPU 超級計算機,以及如何將它們連接到其特定研究領域或量子計算部署平臺。”
NVQLink 可將量子處理器與 NVIDIA GPU 相連接,從而實現由 CUDA-Q 軟件平臺提供支持的大規模工作流。NVQLink 的開放式架構為全球超級計算中心整合各類量子處理器提供了關鍵紐帶,同時在 FP4 精度下提供 40 PetaFLOPS的 AI 性能。
未來,每臺超級計算機都將利用量子處理器來擴展其可以解決的問題范圍,并且每臺量子處理器都將依賴于 GPU 超級計算機來實現正常運行。
量子計算公司 Quantinuum 推出的新型 Helios QPU 已通過 NVQLink 與 NVIDIA GPU 集成,實現了全球首個可擴展 qLDPC 量子糾錯碼的實時解碼。得益于 NVQLink 微秒級的低延遲,該系統保持了 99% 的保真度,而在未進行校正的情況下,該系統保持了 95% 的保真度。
借助 NVQLink,科學家和開發者在量子硬件和經典硬件之間架起了通用橋梁,使可擴展的糾錯、混合應用和實時量子 GPU 工作流變得切實可行。
NVQLink 已被亞太地區、歐洲和中東地區以及美國的眾多研究中心、超級計算中心和實驗室采用。
開發現實世界的混合應用
采用 NVQLink 的 Quantinuum Helios QPU 提供:
使用 NVQLink 校正時,保真度約為 99%,而不使用 NVQLink 校正時,保真度約為 95%
NVQLink 將量子處理器與 GPU 超級計算相結合,實現可擴展的糾錯和混合應用。科學家可以通過 CUDA-Q API 獲得統一的編程環境。開發者可以實時構建和測試量子 – GPU 工作流。
借助 NVQLink,全球超級計算中心正在為實用的量子經典系統奠定基礎,以前所未有的速度和規模將不同的量子處理器與 NVIDIA 加速計算單元相連接。
NVIDIA 和 RIKEN 推動科學前沿發展
NVIDIA 和 RIKEN 正在構建兩臺新的 GPU 加速超級計算機擴大當地在科學和量子計算 AI 領域的領導地位。
用于 AI for Science的 系統:1600 塊 Blackwell GPU 將為生命科學、材料科學、氣候和天氣預報、制造和實驗室自動化領域的研究提供支持。
量子計算系統:540 塊 Blackwell GPU 將加速量子算法、混合模擬和量子經典方法。
在 RIKEN 與 Fujitsu 和 NVIDIA 的合作基礎上,還將共同設計 Fugaku 超級計算機的后續產品 FugakuNEXT。預計到 2030 年,FugakuNEXT 將把應用性能提高100 倍,,并集成生產級的量子計算機。
這兩個新的 RIKEN 系統預計將于 2026 年春季投入使用。
Arm 采用 NVIDIA NVLink Fusion
AI 正在重塑數據中心,每瓦效率成為衡量成功的關鍵。核心驅動力是 Arm Neoverse,其部署核心數已超過 10 億。預計到 2025 年在超大規模市場的份額將達到 50%。AWS、Google、微軟、Oracle 和 Meta 在內的各大提供商都基于 Neoverse 構建,這凸顯了 Neoverse 在支持大規模 AI 方面的作用。
為了滿足激增的需求,Arm 正在通過 NVIDIA NVLink Fusion 擴展 Neoverse,這是 Grace Blackwell 率先推出的高帶寬、一致性互連技術。NVLink Fusion 將 CPU、GPU 和加速器連接到一個統一的機架級架構中,消除了限制 AI 性能的內存和帶寬瓶頸。借助 Arm 的 AMBA CHI C2C 協議連接,可確保基于 Arm 的 CPU 與合作伙伴首選加速器之間實現無縫數據傳輸。
Arm 和 NVIDIA 共同為 AI 基礎設施設定了新標準,使生態系統合作伙伴能夠構建差異化、高能效的系統,加速整個 AI 時代的創新。
Buck 表示:“無論是構建自己的 ARM CPU 還是使用 ARM IP ,都可以訪問 NVLink Fusion,將 ARM CPU 與 NVIDIA GPU 或 NVLink 生態系統的其他部分連接,這一切都發生在機架和縱向擴展的基礎設施上。”
為加速計算提供更智能的動力
隨著 AI 工廠規模的擴大,能源成為新的瓶頸。NVIDIA Domain Power Service (DPS)將這一限制轉化為機會,將電力轉化為一種動態、可協調的資源。DPS 作為 Kubernetes 服務運行,能夠對從機架到房間再到設施的整個數據中心的能源使用情況進行建模和管理。它使運營商能夠通過智能地限制電力來提高每兆瓦的性能,在不擴展基礎設施的情況下提高吞吐量。
DPS 與用于設計和運營新一代數據中心的平臺NVIDIA Omniverse DSX Blueprint緊密集成。它與 Power Reservation Steering 等技術配合使用,以平衡整個設施的工作負載,并與 Workload Power Profile 解決方案配合使用,以根據特定工作的需求調整 GPU 的功率。它們共同構成了 DSX Boost,一個能源感知控制層,可在實現性能目標的同時更大限度地提高效率。
DPS 還延伸到數據中心之外。借助面向電網的 API,它支持自動減負和需求響應,幫助公共事業公司在用電高峰事件期間穩定電網。最終打造出一個具有彈性的電網交互式 AI 工廠,將每一瓦電力都轉化為可衡量的進程。
NVIDIA 與 CoreWeave 獲得 Graph500 BFS基準測試冠軍,性能較此前紀錄提升翻倍
NVIDIA 在第 30 期 Graph500 寬度優先搜索 (BFS) 榜單中獲得第一名,使用部署在 CoreWeave 達拉斯數據中心的 8,192 塊 NVIDIA Hopper GPU,取得了每秒遍歷 410 萬億條邊 (TEPS) 的成績,性能較此前最優紀錄提升超兩倍。
該基準測試用于衡量系統處理超大規模圖數據集的能力。在此次測試中,NVIDIA 使用了包含 2.2 萬億個頂點和 35 萬億條邊的圖數據。
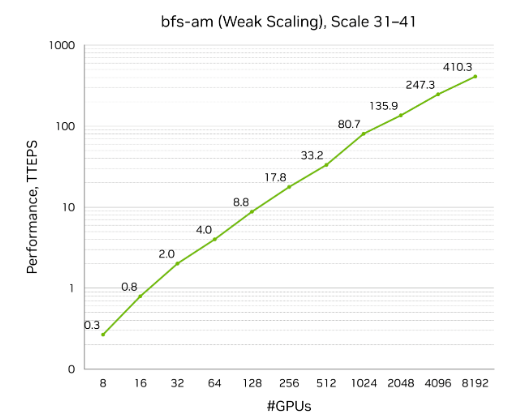
NVIDIA 基于搭載 8192 塊 Hopper GPU 的 CoreWeave 集群提交的測試,位居第 30 期 Graph500 BFS 榜首。
這一成績得益于 NVIDIA Hopper GPU 架構、NVIDIA Quantum-2 InfiniBand 網絡、NVIDIA 與 CoreWeave 的協作,以及基于眾多 NVIDIA 技術構建的定制化軟件實現。其中包括 CUDA 平臺、NVSHMEM 并行編程接口、InfiniBand GPUDirect Async 技術,以及專為高性能 GPU 間主動消息傳遞構建的庫。
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109721 -
交換機
+關注
關注
23文章
2904瀏覽量
104463 -
AI
+關注
關注
91文章
39756瀏覽量
301366 -
超級計算
+關注
關注
1文章
45瀏覽量
11552
原文標題:SC25 | 加速計算和網絡推動 AI 時代的超級計算
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA擴大與微軟合作推動AI超級工廠建設
中航光電亮相2025全球超級計算大會
NVIDIA NVQLink技術被全球十余家超級計算中心廣泛采用
NVIDIA DGX Spark助力構建自己的AI模型

中航光電邀您共赴2025全球超級計算大會

雷曼拓享亮相2025香港國際秋季燈飾展
NVIDIA AI網絡閃耀2025云棲大會
NVIDIA助力AI超級計算機Isambard-AI投入使用
NVIDIA驅動的現代超級計算機如何突破速度極限并推動科學發展
Blue Lion超級計算機將在NVIDIA Vera Rubin上運行
NVIDIA技術賦能歐洲最快超級計算機JUPITER
NVIDIA助力全球最大量子研究超級計算機
NVIDIA GTC2025 亮點 NVIDIA推出 DGX Spark個人AI計算機

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機




 工商網監
工商網監
評論