 使用NVIDIA Nemotron模型構建語音驅動RAG智能體
使用NVIDIA Nemotron模型構建語音驅動RAG智能體

構建智能體不僅僅是“調用API”,而是需要將檢索、語音、安全和推理組件整合在一起,使其像一個統一并互相協同的系統一樣運行。每一層都有自己的接口、延遲限制和集成挑戰,一旦跨過簡單的原型就會開始感受到這些挑戰。
在本教程中,您將學習如何使用2026年CES發布的最新NVIDIANemotron語音、RAG、安全和推理模型,去構建一個帶有護欄的語音驅動RAG智能體。最終您將擁有具備如下功能的一個智能體:
聽取語音輸入
使用多模態RAG將智能體錨定在您的數據之上
長上下文推理
在響應之前應用護欄規則
以音頻的形式返回安全答案
您可以在本地GPU上進行開發,然后將相同的代碼部署到可擴展的NVIDIA環境中,無論是托管的GPU服務、按需云工作區,還是生產就緒的API運行時,都無需更改工作流。
先決條件
在開始這次教程之前,您需要:
用于云托管推理模型的NVIDIA API密鑰(免費獲取)
本地部署需要:
約20GB的磁盤空間
至少24GB顯存的NVIDIA GPU
支持Bash的操作系統(Ubuntu、macOS或Windows Subsystem for Linux)
Python 3.10+環境
一小時的空閑時間
您將構建的內容
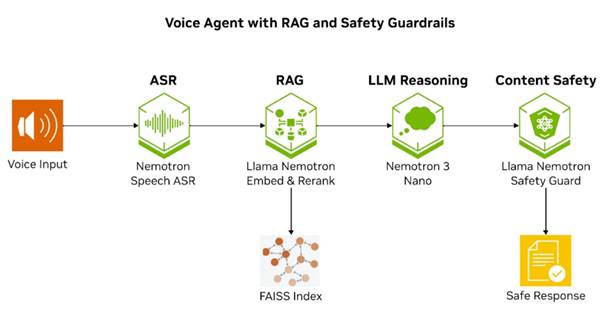
圖1.帶有RAG和安全護欄的語音智能體的端到端工作流。
| 組件 | 模型 | 目的 |
| ASR | nemotron-speech-streaming-en-0.6b | 超低延遲語音輸入 |
| 嵌入 | llama-nemotron-embed-vl-1b-v2 | 文本和圖像的語義搜索 |
| 重排序 | llama-nemotron-rerank-vl-1b-v2 | 將檢索準確率提高6-7% |
| 安全 | llama-3.1-nemotron-safety-guard-8b-v3 | 多語言內容審核 |
| 視覺語言 | nemotron-nano-12b-v2-vl | 根據上下文描述圖像 |
| 推理 | nemotron-3-nano-30b-a3b | 1M token高效推理 |
表1.本教程中用于構建語音智能體的Nemotron模型概覽,包括用于ASR、嵌入、重排序、視覺語言、長上下文推理和內容安全的模型。
步驟1:設置環境
要構建語音智能體,您需要同時運行多個NVIDIANemotron模型(如上所示)。語音、嵌入、重排序和安全模型通過Transformer和NVIDIA NeMo在本地運行,推理模型則使用NVIDIA API。
uvsync--all-extras
配套的Notebook會處理所有的環境配置。設置用于云托管推理模型的NVIDIA API密鑰,即可開始使用。
步驟2:使用多模態RAG構建智能體基座
檢索是可靠智能體的支柱。借助全新的LlamaNemotron多模態嵌入和重排序模型,您可以嵌入文本、圖像(包括掃描文檔),并直接將其存儲在向量索引中,無需額外的預處理。這可以檢索推理模型所依賴的真實上下文,確保智能體參考的是真實企業數據而非產生幻覺。
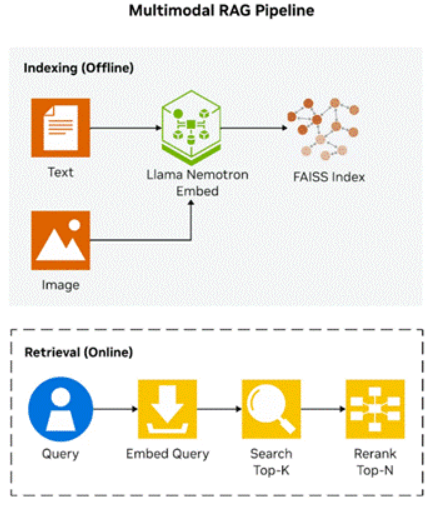
圖2.具有離線索引和在線檢索的多模態RAG管道。
llama-nemotron-embed-vl-1b-v2模型支持三種輸入模式——純文本、純圖像和圖像與文本的組合,讓您能夠對從純文本文檔到幻燈片和技術圖表的各種內容進行索引。在本教程中,我們將嵌入一個同時包含圖像和文本的示例。該嵌入模型通過Transformers加載,并啟用flash attention:
from transformers import AutoModel
model = AutoModel.from_pretrained(
"nvidia/llama-nemotron-embed-vl-1b-v2",
trust_remote_code=True,
device_map="auto"
).eval()
# Embed queries and documents
query_embedding = model.encode_queries(["How does AI improve robotics?"])
doc_embeddings = model.encode_documents(texts=documents)
在初始檢索后,llama-nemotron-rerank-vl-1b-v2模型會結合文本和圖像對結果進行重新排序,以確保檢索后的準確性更高。在基準測試中,添加重排序可將準確率提高約6-7%,這在精度要求較高的場景中是一項顯著的提升。
步驟3:使用NemotronSpeech ASR添加實時語音功能
錨定完成后,下一步是通過語音實現自然交互。
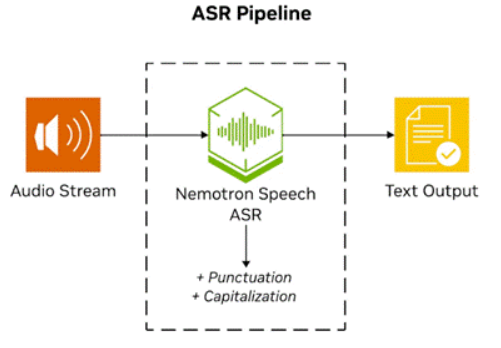
圖3.基于NVIDIANemotronSpeech ASR的ASR管道
Nemotron Speech ASR是一個流式模型,基于Granary數據集中數萬小時的英語音頻及多種公開語音語料庫進行訓練,同時經過優化實現超低延遲的實時解碼。開發者將音頻流式傳輸到ASR服務,在收到文本結果后,將輸出直接輸入到RAG管道中。
import nemo.collections.asr as nemo_asr
model = nemo_asr.models.ASRModel.from_pretrained(
"nvidia/nemotron-speech-streaming-en-0.6b"
)
transcription = model.transcribe(["audio.wav"])[0]
該模型具備可配置的延遲設置,在80毫秒的最低延遲設置下,平均字詞錯誤率(Word Error Rate, WER)為8.53%,延遲為1.1秒時,WER進一步降低至7.16%,這一表現顯著低于語音助手、現場工具和免提工作流所要求的一秒關鍵閾值。
步驟4:使用Nemotron內容安全和PII模型強制執行安全措施
跨地區和跨語言運行的AI智能體不僅必須理解有害內容,還必須理解文化細微差別和上下文相關的含義。
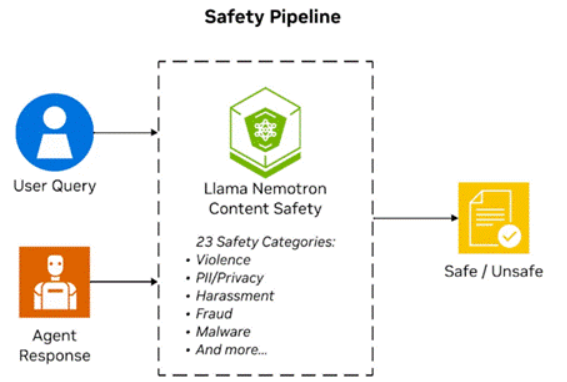
圖4.使用NVIDIA LlamaNemotronSafety Guard模型的安全管道,檢測安全或不安全內容。
llama-3.1-nemotron-safety-guard-8b-v3模型可提供20多種語言的多語言內容安全,并可對23個安全類別進行實時PII檢測。
該模型通過NVIDIA API提供,無需額外托管基礎設施,即可輕松添加輸入和輸出過濾。它可以基于語言、方言和文化背景區分含義不同但表達相似的短語,這在處理可能受到干擾或非正式的實時ASR輸出時尤為重要。
from langchain_nvidia_ai_endpoints import ChatNVIDIA
safety_guard = ChatNVIDIA(model="nvidia/llama-3.1-nemotron-safety-guard-8b-v3")
result = safety_guard.invoke([
{"role": "user", "content": query},
{"role": "assistant", "content": response}
])
步驟5:使用Nemotron3 Nano添加長上下文推理功能
NVIDIANemotron3 Nano為智能體提供推理能力,結合了高效的混合專家(MoE)機制和混合Mamba-Transformer架構,支持1M token上下文窗口。這使得模型能夠在單個推理請求中合并檢索到的文檔、用戶歷史記錄和中間步驟。
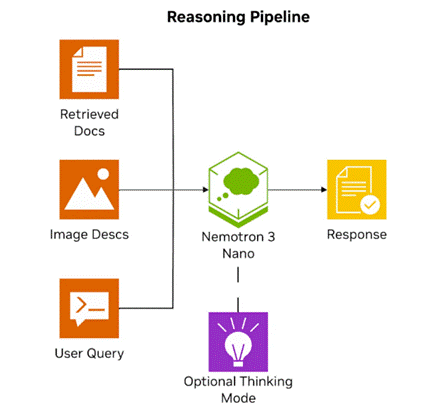
圖5.使用NVIDIANemotron3 Nano的推理管道。
當檢索到的文檔包含圖像時,智能體首先使用NemotronNano VL來描述這些圖像,然后將所有信息傳遞給Nemotron3 Nano以獲得最終的響應。該模型支持可選的思考模式,可用于更復雜的推理任務:
completion = client.chat.completions.create(
model="nvidia/nemotron-3-nano-30b-a3b",
messages=[{"role": "user", "content": prompt}],
extra_body={"chat_template_kwargs": {"enable_thinking": True}}
)
輸出在返回之前會通過安全過濾器,將您的檢索增強型查找轉換為具有完整推理能力的智能體。
步驟6:使用LangGraph將所有內容連接起來
LangGraph將整個工作流編排為一個有向圖。每個節點處理一個階段,即轉錄、檢索、圖像描述、生成和安全檢查,組件之間有清晰的切換:
VoiceInput→ASR→Retrieve→Rerank→DescribeImages→Reason→Safety→Response
智能體狀態流經每個節點,并在過程中積累上下文。這種結構簡化了添加條件邏輯、重試失敗步驟或基于內容類型進行分支。配套Notebook中的完整實現展示了如何定義每個節點,并將其連接到生產就緒型管道中。
步驟7:部署智能體
智能體能夠在本地機器上穩定運行后,您就可以將其部署到任意位置。在需要分布式攝取、嵌入生成或大規模批量向量索引時,可使用NVIDIA DGX Spark。Nemotron模型可以進行優化、打包并作為NVIDIANIM運行(一套預構建的GPU加速推理微服務,專為在NVIDIA基礎設施上部署AI模型而設計),并可直接從Spark調用以進行可擴展的處理。當您需要按需的GPU工作空間且無需系統設置直接運行Notebook,同時還希望獲得可與團隊輕松共享的Spark集群遠程訪問時,可以選擇使用NVIDIA Brev。
如果您想查看適用于物理機器人助手的相同部署模式,請查看基于Nemotron和DGX Spark的ReachyMini個人助理教程。
兩個環境都使用相同的代碼路徑,因此您可以由實驗階段平穩過渡到生產環境,所需的修改極少。
您所構建的內容
現在,您擁有一個由Nemotron驅動的智能體核心結構,該結構由四個核心組件組成:用于語音交互的語音ASR、用于實現信息真實性的多模態RAG、考慮文化差異的多語言內容安全過濾,以及用于長上下文推理的Nemotron3 Nano。相同的代碼適用于本地開發到生產級GPU集群運行。
| 組件 | 目的 |
| 多模態RAG | 在真實的企業數據中錨定響應 |
| 語音ASR | 實現自然語音交互 |
| 安全 | 跨語言和文化背景識別不安全內容 |
| 長上下文LLM | 通過推理生成準確的響應 |
表2.用于構建基于Nemotron的語音智能體的四個組件概覽——多模態RAG、語音ASR、多語言內容安全和長上下文推理。
本教程中的每個部分都與Notebook中的相應部分直接對應,因此您可以逐步實施和測試該流程。一旦端到端工作正常,相同的代碼即可擴展到生產部署。
關于作者
Chris Alexiuk 是 NVIDIA 的深度學習開發者倡導者,負責創建技術資源,幫助開發者使用 NVIDIA 提供的一整套強大 AI 工具。Chris 擁有機器學習和數據科學背景,對大型語言模型的一切充滿熱情。
Isabel Hulseman 是 NVIDIA 的綜合營銷經理,專注于人工智能軟件。她的興趣領域包括用于構建、定制和部署大型語言模型和生成人工智能應用程序的加速推理和解決方案。
-
NVIDIA
+關注
關注
14文章
5667瀏覽量
109985 -
模型
+關注
關注
1文章
3781瀏覽量
52200 -
智能體
+關注
關注
1文章
522瀏覽量
11628
原文標題:CES 2026 | 如何使用 RAG 和安全護欄構建語音智能體
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「基于大模型的RAG應用開發與優化」閱讀體驗】+第一章初體驗
【「基于大模型的RAG應用開發與優化」閱讀體驗】RAG基本概念
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

NVIDIA推出開放式Llama Nemotron系列模型
NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺

企業使用NVIDIA NeMo微服務構建AI智能體平臺
ServiceNow攜手NVIDIA構建150億參數超級助手
NVIDIA Nemotron Nano 2推理模型發布

使用NVIDIA Nemotron RAG和Microsoft SQL Server 2025構建高性能AI應用
NVIDIA Nemotron如何助力企業構建專業AI智能體
NVIDIA 推出 Nemotron 3 系列開放模型




 工商網監
工商網監
評論