 NVIDIA攜手中科創達助力打造AI定義智能座艙
NVIDIA攜手中科創達助力打造AI定義智能座艙

隨著座艙屏幕數量和算力趨近用戶感知上限,智能座艙的競爭焦點正由硬件堆疊轉向智能體驗。真正的變革在于座艙系統能否成為貼心伙伴——不僅能聽懂指令,更能理解意圖;不僅能識別環境,更能洞察場景;不僅能執行操作,更具情感共鳴與主動服務能力。
縱觀智能座艙的發展脈絡,行業正經歷從早期的功能集成 (將導航、音樂、車控等功能匯集一屏),到當前的場景服務 (如“會議”“小憩”“長途”等模式),再到綜合情感交互的三階段演進。未來的智能座艙將具備情景理解、全乘客意圖判斷與主動服務能力,真正成為有溫度、有智慧、懂用戶的艙內智能空間。而實現這一目標,需要在車端計算單元部署更強大的多模態、全模態 AI,并克服以下核心挑戰:
確定性的超低延遲響應:無論是語音打斷還是自然語言的交流反饋,響應必須在百毫秒級且穩定可預測,這是端側部署 AI Agent 的核心優勢,且直接關系到終端用戶的體驗與爽感。
高效的解碼生成能力:當前端側大模型推理的瓶頸往往在于文本輸出生成階段,若解碼速度不足,用戶將明顯感受到回復卡頓、中斷,嚴重影響對話的自然度與體驗的連貫性。
多模態信號的實時檢測:系統需要實時并同步處理來自艙內 DMS、OMS,以及艙外攝像頭、麥克風陣列、語音文本等多路異構輸入信號,需要多模且強大的實時處理能力。
可靠安全的端云協同架構:涉及隱私安全的長期記憶與歷史記憶功能交互依賴本地計算,確保響應可靠;同時,復雜互聯網信息查詢又需要無縫連接云端模型,從而形成安全與智能兼顧的混合架構。
同時,這些挑戰會催生出下一代艙內 AI 智能體的關鍵場景:
艙內外一體化視覺感知:DMS、OMS 正從基礎的疲勞監測,演進為能夠識別艙內駕駛員、乘客身份,手勢表情指令、情緒狀態的綜合感知中樞,并與艙外感知配合,可實現“旅途路書導游”“霧霾自動關窗”“寵物遺留檢測”等主動場景服務。
具有記憶與邏輯連貫性的多輪語音對話:語音助手需構建持續的對話記憶,能準確解析“調暗一點”“給剛才打電話的人回消息”等上下文所指,并處理“如果明天不下雨,就幫我預約洗車”式的復雜條件指令,實現真正類人的連貫交互。
面向 L2+/L3/L4 的高動態人機交互式共駕:系統根據駕駛員及乘客的乘車目的、路況復雜度、艙內場景狀態、駕駛員專注度,動態調整交互策略和信息呈現方式,從而實現“不想回家,去看電影”“去一家我喜歡口味的餐廳”等絲滑駕艙體驗。
NVIDIA TensorRT Edge-LLM——為車載等邊緣端大模型而生的開源推理框架
一、框架概述
NVIDIA TensorRT Edge-LLM是專為邊緣端大模型部署打造的輕量級推理框架,面向智能汽車等實時端側應用場景。框架針對邊緣部署的核心訴求進行了深度優化:
少量用戶/低批量推理:面向少量用戶或多攝像頭小批量推理場景設計
離線運行:無云端依賴,本地獨立完成全流程推理
極致性能:最小化延遲、內存與算力占用
高可靠性:滿足高可靠性的生產級部署標準
二、核心特性
| 特性 | 核心價值 |
| 純 C++ 運行時 | 開源代碼,依賴極少,易于集成與生產部署 |
| 超輕量化設計 | 專注嵌入式場景,資源占用最小化 |
| 高性能計算 | 優化的 CUDA 內核與 TensorRT 集成,實現最大吞吐量 |
| 高級能力 | 支持投機解碼、NVFP4 等量化、動態 LoRA 切換,先進的 KV 緩存管理等特性 |
| 統一工具鏈 | 同一推理工具鏈適用于 NVIDIA Drive AGX、Jetson 及 MediaTek Dimensity Auto 座艙平臺 |
更多技術細節請參考:TensorRT Edge-LLM 技術文檔
三、開源意義
NVIDIA 在 GPU 計算領域深耕多年,依托 CUDA、TensorRT 等核心技術構建了成熟的 AI 開發生態,已成為業界事實標準。此次開源 TensorRT Edge-LLM,正是將這一生態優勢向邊緣端延伸的重要舉措。
開源將帶來多重價值:一方面,統一的技術規范能夠有效降低車企等端側廠商的開發門檻與適配成本;另一方面,也為 AI 模型廠商提供了標準化的適配路徑,使模型能夠更便捷地部署至邊緣設備,加速商業化落地。此外,代碼透明有助于提升安全可審計性,更好地滿足生產環境的合規要求;開放的社區模式也將匯聚全球開發者持續貢獻,推動技術快速迭代演進。
通過 TensorRT Edge-LLM 的開源,NVIDIA 旨在進一步完善從云到端的全棧 AI 生態,讓開發者從復雜的底層優化中解放出來,更專注于上層應用創新,助力智能汽車等端側行業加速邁向智能化。 歡迎訪問開源社區參與貢獻:TensorRT Edge-LLM GitHub
中科創達的創新實踐:基于 NVIDIA TensorRT Edge-LLM 的多模態 AI 服務架構
TensorRT Edge-LLM 為車載邊緣AI提供了高性能、輕量化、純 C++ 的推理運行時,是構建車規級推理系統的重要基礎。基于該運行時,中科創達進一步構建了面向座艙業務的多模態 AI 服務架構,將底層推理能力封裝為可調度、可擴展的系統服務。
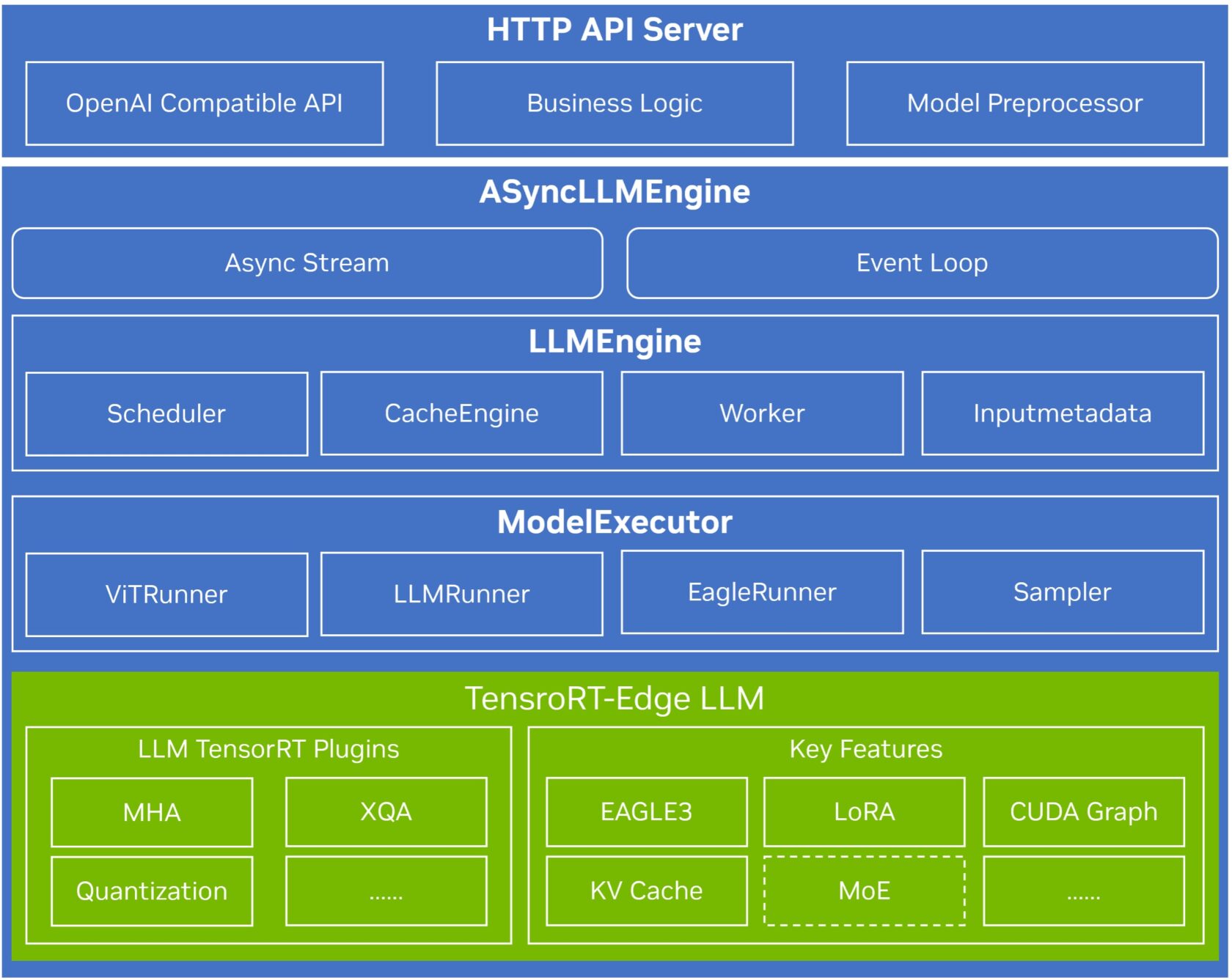
(注:MoE模塊將在后續版本中引入)
*圖片由中科創達提供,如果您有任何疑問或需要使用該圖片,請聯系中科創達
一、該架構特點
統一的 AI 服務接口:
在 TensorRT Edge-LLM 之上實現支持 LLM、VLM 及混合輸入的 HTTP 推理服務,滿足語音、視覺及多模態交互的統一接入需求。
支持 Continuous Batching (多請求動態合并) 與Streaming 推理 (流式輸出),在提升 GPU 利用率的同時降低單請求感知時延,在多并發場景下吞吐量提高 2.4 倍。
支持跨 SoC 平臺的快速適配:
構建統一的推理后端抽象層,實現從特定平臺推理框架到 TensorRT Edge-LLM 的平滑遷移,顯著降低底層適配成本,提升整體開發效率。
在平臺層提供標準化的模型定義與接入機制,使新模型能夠快速完成適配、部署與調優,避免為每個模型重復進行工程開發,加速多模型在座艙場景中的規模化應用。
面向業務負載的推理任務調度和優化:
推理服務可與座艙內語音、視覺、HMI 等模塊協同運行,支持實際業務中的并發請求和實時交互需求。支持根據業務優先級對推理任務進行掛起與恢復,使高優先級交互請求能夠獲得確定性的響應時間。針對特定模型與應用場景,對推理邏輯進行針對性工程優化,使系統在滿足業務約束的前提下獲得更優的端到端性能表現,在 Qwen2.5-VL-7B 模型上,針對單并發多圖輸入場景 (9×448×364 圖像 + 1000 text tokens + 30 output tokens),相比基線方案實現 1.59 倍推理加速。
與算法訓練團隊協同工作:具備自主訓練 EAGLE3 draft model 及 LoRA 微調能力,從模型訓練、推理策略到系統工程形成閉環,充分釋放 TensorRT Edge-LLM 在推理加速、Speculative Decoding 等特性上的整體潛力。
二、客戶合作案例
案例 A:重構 AI 座艙交互——基于 NVIDIA DRIVE AGX Orin 的端側算力與優化視覺大模型融合實踐
基于DRIVE AGX Orin平臺,中科創達與某頭部車企攜手,成功打造并全球首發了新一代 AI 座艙。其核心成果在于:充分利用 DRIVE AGX Orin 平臺的極致AI算力,深度融合經中科創達深度優化的本地 Qwen2.5-VL-7B 視覺大模型,真正兌現了“AI 座艙”的感知與決策能力,并將關鍵 AI 場景的端到端推理延遲降至業界領先水平,為用戶帶來顛覆性的瞬時響應體驗。
性能成果:將關鍵 AI 場景的端到端推理延遲降至秒級——AI增強哨兵場景 2.6s,AI迎賓場景 0.6s,下車安全場景 0.7s,停車記憶場景 0.8s。
行業突破:中科創達成功解鎖了 AIBOX (DRIVE AGX Orin) A 樣的量產能力,實現了全球首次交付。這一里程碑標志著 AI 座艙相關智能場景進入了新的發展階段。
案例B:面向下一代車載自然交互的端側大模型記憶實踐
中科創達與某全球頭部車企合作的 Innovation Project 中,在車規級高性能 AI 算力底座上,部署并深度優化了 Qwen3-VL-4B 視覺語言模型,使其滿足車載環境的苛刻要求。基于此,成功實現了“長聆聽” (Long-Context Listening) 與“端側主動記憶” (On-Device Proactive Memory) 兩大原型功能,為探索無界面的自然交互奠定了基礎。
三、核心價值
基于 DRIVE AGX Orin 的強大算力以及 TensorRT Edge-LLM 優秀的推理任務調度管理方案,實現端側人人對話、主動記憶、Non-workflow 的智能任務編排范式,與客戶共同探索車載 AI 場景技術的創新能力邊界。
智能座艙的競爭已經進入下半場,決勝的關鍵不再是單純的配置堆疊,而是考驗在嚴苛車規級環境下能否提供穩定、高效且確定性的用戶體驗輸出。此外,智能座艙的演進從來不是單點技術的突破,而是完整生態系統的協同進化升級。在這一關鍵進程中,NVIDIA 和中科創達基于各自的核心能力,形成了深度互補的合作,共同為行業提供從底層算力到上層應用的全棧解決方案。NVIDIA 開源的 TensorRT Edge-LLM 框架將專業級邊緣AI推理能力全面開放給開發者,而中科創達則憑借深厚的座艙軟件全棧能力,將TensorRT Edge-LLM 深度集成至座艙AI系統,將AI能力封裝為智能且可復用的場景服務模塊,從而共同推動智能座艙進入“AI 定義”時代。
面向未來,雙方將合作聚焦于三個維度:基于量產數據和用戶反饋持續優化 DRIVE 平臺上的性能表現;共同開發支持個性化服務與座艙 AI Agent 框架;為車企提供從模型選型、量化優化到 Agent 部署集成的完整工具鏈與參考框架,助力打造可持續進化的AI定義座艙。中科創達非常期待通過 NVIDIA 開放的底層能力與中科創達成熟的集成經驗,與更多開發者共同創建創新可靠的智能汽車軟件生態,真正實現從功能定義到AI定義的范式變革。
獲取核心框架、工具鏈以及模型部署示例:https://github.com/NVIDIA/TensorRT-Edge-LLM
-
NVIDIA
+關注
關注
14文章
5678瀏覽量
110062 -
AI
+關注
關注
91文章
40746瀏覽量
302387 -
中科創達
+關注
關注
1文章
368瀏覽量
13806 -
智能座艙
+關注
關注
4文章
1323瀏覽量
17351
原文標題:NVIDIA 與中科創達推動智能座艙進入“AI 定義”時代
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄



 工商網監
工商網監
評論