 摩爾線程新一代大語言模型對齊框架URPO入選AAAI 2026
摩爾線程新一代大語言模型對齊框架URPO入選AAAI 2026

近日,摩爾線程在人工智能前沿領域取得重要突破,其提出的新一代大語言模型對齊框架——URPO統一獎勵與策略優化,相關研究論文已被人工智能領域的國際頂級學術會議AAAI 2026收錄。這一成果標志著摩爾線程在大模型基礎技術探索上邁出了關鍵一步,為簡化大模型訓練流程、突破模型性能上限提供了全新的技術路徑。
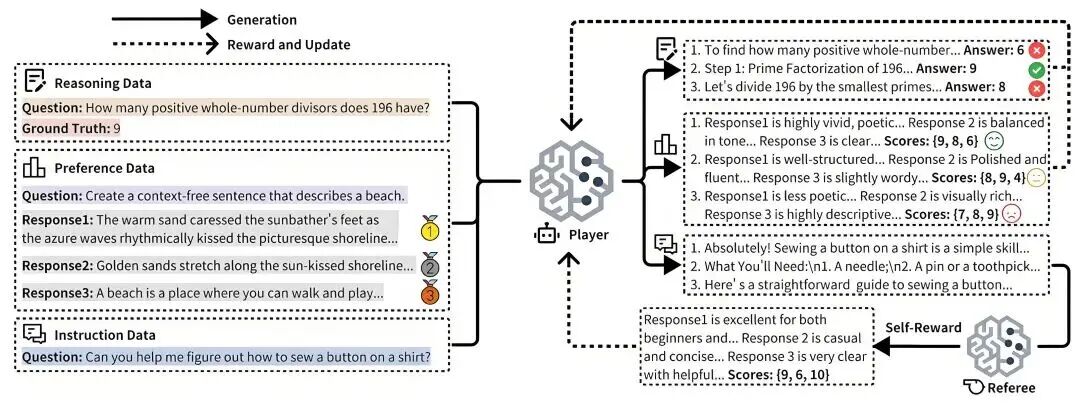
圖示:URPO統一獎勵與策略優化框架
在題為《URPO:A Unified Reward & Policy Optimization Framework for Large Language Models》的論文中,摩爾線程AI研究團隊提出了URPO統一獎勵與策略優化(Unified Reward & Policy Optimization,URPO)框架,創新地將“指令遵循”(選手)和“獎勵評判”(裁判)兩大角色融合于單一模型中,并在統一訓練階段實現同步優化。URPO從以下三方面攻克技術挑戰:
數據格式統一:將異構的偏好數據、可驗證推理數據和開放式指令數據,統一重構為適用于GRPO訓練的信號格式。
自我獎勵循環:針對開放式指令,模型生成多個候選回答后,自主調用其“裁判”角色進行評分,并將結果作為GRPO訓練的獎勵信號,形成一個高效的自我改進循環。
協同進化機制:通過在同一批次中混合處理三類數據,模型的生成能力與評判能力得以協同進化。生成能力提升帶動評判更精準,而精準評判進一步引導生成質量躍升,從而突破靜態獎勵模型的性能瓶頸。
實驗結果顯示,基于Qwen2.5-7B模型,URPO框架顯著超越依賴獨立獎勵模型的傳統基線:在AlpacaEval指令跟隨榜單上,得分從42.24提升至44.84;在綜合推理能力測試中,平均分從32.66提升至35.66。尤為突出的是,作為訓練的“副產品”,該模型內部自然涌現出卓越的評判能力,在RewardBench獎勵模型評測中取得85.15的高分,表現甚至優于其替代的專用獎勵模型(83.55分)。
除了卓越的性能表現,URPO框架在工程落地方面同樣展現出顯著優勢。該技術基于GRPO算法進行輕量化迭代實現,在代碼層面僅需添加少量補丁即可完成部署,大幅降低了技術遷移與應用門檻。目前,URPO已在摩爾線程自研計算卡上實現穩定高效運行,充分發揮軟硬件協同優化的底層優勢;同時,摩爾線程已完成VERL等主流強化學習框架的深度適配,讓這一簡潔高效的對齊方案能快速融入現有研發體系,既保留了技術延續性,又為行業提供了兼具性能、效率與兼容性的一體化解決方案。
URPO框架的成功,是摩爾線程堅持底層技術創新、攻堅大模型核心挑戰的重要成果。該研究不僅提供了一種更簡潔、高效、性能更強的對齊方案,更通過“選手-裁判”一體化的設計,為大模型實現持續自我進化開辟了新路徑。未來,摩爾線程將繼續深耕大模型等前沿技術領域,以堅實的創新成果推動人工智能產業實現跨越式發展。
關于摩爾線程
摩爾線程以全功能GPU為核心,致力于向全球提供加速計算的基礎設施和一站式解決方案,為各行各業的數智化轉型提供強大的AI計算支持。
我們的目標是成為具備國際競爭力的GPU領軍企業,為融合人工智能和數字孿生的數智世界打造先進的加速計算平臺。我們的愿景是為美好世界加速。
-
人工智能
+關注
關注
1817文章
50094瀏覽量
265263 -
摩爾線程
+關注
關注
2文章
279瀏覽量
6449 -
大模型
+關注
關注
2文章
3648瀏覽量
5177
原文標題:摩爾線程大模型對齊研究獲頂會認可:URPO框架入選 AAAI 2026
文章出處:【微信號:moorethreads,微信公眾號:摩爾線程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
摩爾線程快速完成對Qwen3.5模型全面適配
Day-0支持|摩爾線程完成MiniMax M2.5模型極速適配
摩爾線程MTT S5000率先完成對GLM-5的適配

Day-0支持|摩爾線程MTT S5000率先完成對GLM-5的適配

摩爾線程正式開源TileLang-MUSA項目
Nullmax DiffRefiner軌跡預測框架入選AAAI 2026
小鵬汽車與北京大學研究論文成功入選AAAI 2026

摩爾線程新一代GPU架構即將揭曉
地平線五篇論文入選NeurIPS 2025與AAAI 2026

Nullmax端到端軌跡規劃論文入選AAAI 2026
【內測活動同步開啟】這么小?這么強?新一代大模型MCP開發板來啦!
摩爾線程“AI工廠”:五大核心技術支撐,打造大模型訓練超級工廠

摩爾線程“AI工廠”:以系統級創新定義新一代AI基礎設施
摩爾線程GPU成功適配Deepseek-V3-0324大模型

摩爾線程支持阿里云通義千問QwQ-32B開源模型




 工商網監
工商網監
評論