 摩爾線程MTT S5000率先完成對GLM-5的適配
摩爾線程MTT S5000率先完成對GLM-5的適配

2月11日,智譜正式發布新一代大模型GLM-5。摩爾線程基于SGLang推理框架,在旗艦級AI訓推一體全功能GPU MTT S5000上,Day-0完成了全流程適配與驗證。
憑借MUSA架構廣泛的算子覆蓋與強大的生態兼容能力,摩爾線程成功打通了模型推理全鏈路,并深度釋放MTT S5000的原生FP8加速能力,在確保模型精度的同時顯著降低了顯存占用,實現了GLM-5的高性能推理。此次快速適配,不僅印證了MUSA軟件棧的成熟度,更充分展現了國產全功能GPU對最新大模型即時、高效的支持能力。
GLM-5與MTT S5000的國產雙強聯合,將為開發者帶來可對標國際頂尖模型的極致編程體驗。無論是在函數補全、漏洞檢測還是Debug場景中,該組合均表現卓越,以顯著增強的邏輯規劃能力,從容應對各類復雜的長程任務挑戰。
GLM-5核心特性:
定義Agentic Engineering新高度
作為GLM系列的最新里程碑版本,GLM-5定位為當下頂尖的Coding模型,整體性能較上一代提升20%。其核心突破在于Agentic Engineering(代理工程)能力——不僅具備深厚的代碼功底,更擁有處理復雜系統工程與長程Agent任務的實力,能夠實現從需求到應用的端到端開發。
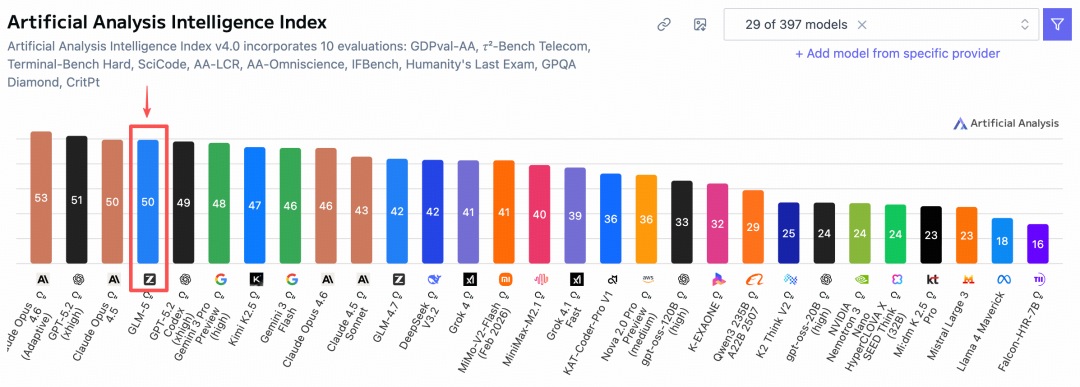
在全球權威的Artificial Analysis榜單中,GLM-5位居全球第四、開源第一。

GLM-5在編程能力上實現了對齊Claude Opus 4.5,在業內公認的主流基準測試中取得開源模型SOTA。在SWE-bench-Verified和Terminal Bench 2.0中分別獲得77.8和56.2的開源模型最高分數,性能超過 Gemini 3 Pro。
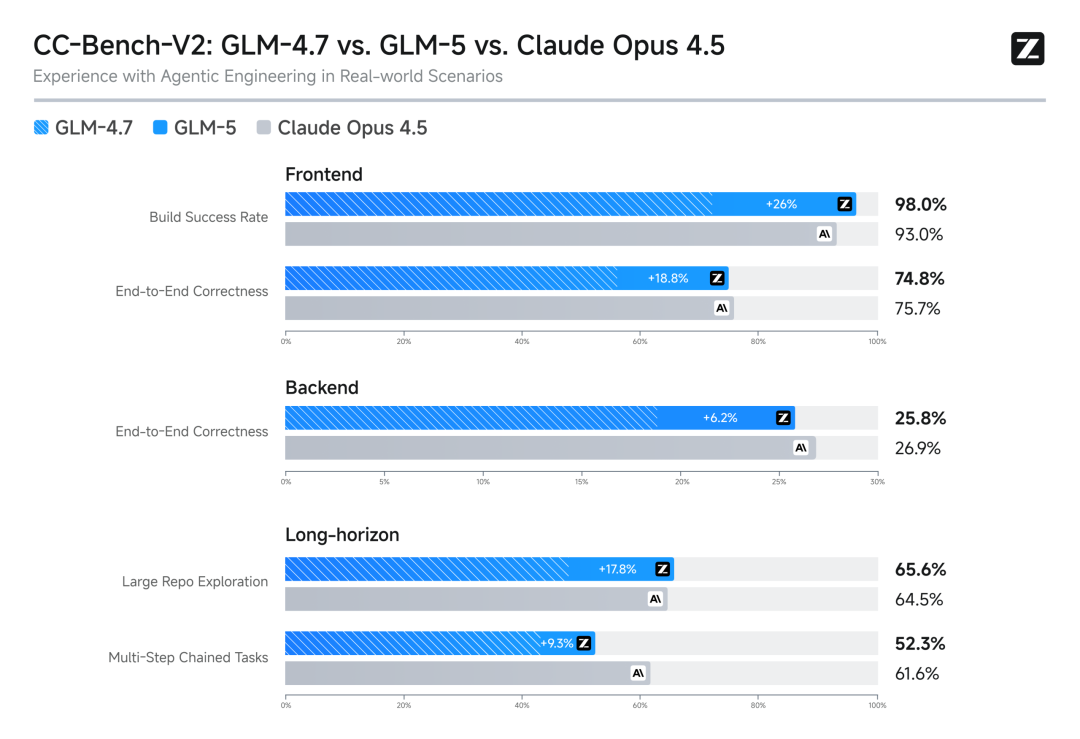
在內部Claude Code評估集合中,GLM-5在前端、后端、長程任務等編程開發任務上顯著超越上一代的GLM-4.7(平均增幅超過20%),能夠以極少的人工干預,自主完成Agentic長程規劃與執行、后端重構和深度調試等系統工程任務,使用體感逼近Opus 4.5。
摩爾線程核心優勢:
軟硬協同的全棧算力底座
MTT S5000是專為大模型訓練、推理及高性能計算而設計的全功能GPU智算卡,基于第四代MUSA架構“平湖”打造。其單卡AI算力最高可達1000 TFLOPS,配備80GB顯存,顯存帶寬達到1.6TB/s,卡間互聯帶寬為784GB/s,完整支持從FP8到FP64的全精度計算。
依托MUSA全棧平臺,MTT S5000原生適配PyTorch、Megatron-LM、vLLM及SGLang等主流框架,助力用戶實現“零成本”代碼遷移。無論是構建萬卡級大規模訓練集群,還是部署高并發、低延遲的在線推理服務,MTT S5000均展現出對標國際主流旗艦產品的卓越性能與穩定性,旨在為行業筑牢堅實、易用的國產算力底座。
此次實現對GLM-5模型的快速支持,正是摩爾線程基于MTT S5000構建的軟硬協同技術能力的集中體現:
▼底層架構與生態兼容:天生適配,極速遷移
針對GLM-5的長序列推理場景,MTT S5000憑借充沛的算力儲備與高計算密度,結合對稀疏Attention的架構級支持,在大規模上下文處理中依然保持高吞吐與低延遲。同時,MUSA軟件棧的敏捷性是實現Day-0適配的關鍵。基于MUSA架構的TileLang原生算子單元測試覆蓋率已超過80%,使得絕大多數通用算子可直接復用,顯著降低移植成本,并能快速跟進前沿模型結構與新特性演進。
▼原生FP8加速:SGLang 框架深度優化
基于高性能的SGLang-MUSA推理引擎及MTT S5000的硬件原生FP8計算單元,摩爾線程實現了推理效率的躍升。與傳統BF16相比,原生FP8在保持GLM-5卓越的代碼生成與邏輯推理能力(精度無損)的同時,大幅降低了顯存占用,并顯著提升了推理吞吐量,為大規模部署提供了更高性價比的方案。
針對大模型分布式推理中的通信痛點,MTT S5000利用獨創的異步通信引擎(ACE),將復雜的通信任務從計算核心中卸載,實現了物理級的“通信計算重疊”。這一機制有效釋放15%的通信被占算力,配合首創的細粒度重計算技術(將開銷降至原有的1/4),全方位提升計算效率與系統吞吐量。
▼超長上下文支持:專為AI Coding打造
通過高效算子融合及框架極致優化,MTT S5000在確保代碼生成質量的同時顯著降低了響應延遲。無論是處理復雜的代碼庫分析,還是運行長周期的智能體(Agent)任務,均能保持首字延遲(TTFT)低、生成速度快的流暢體驗。MTT S5000與GLM-5的軟硬雙強組合,在函數補全、漏洞檢測等核心場景的表現超越同級,充分釋放模型的規劃能力和Debug能力,是執行長程開發任務的理想選擇。
從GLM-4.6、GLM-4.7到GLM-5,摩爾線程已將“發布即適配”化為常態,這種對主流軟件棧的無縫兼容與敏捷響應,充分證明了國產全功能GPU及MUSA軟件棧的成熟度與穩定性,確保開發者能第一時間觸達最新模型能力,從而攜手共建蓬勃發展的國產AI生態。
-
模型
+關注
關注
1文章
3773瀏覽量
52175 -
MUSA
+關注
關注
0文章
6瀏覽量
2175 -
摩爾線程
+關注
關注
2文章
280瀏覽量
6541
原文標題:Day-0支持|摩爾線程MTT S5000率先完成對GLM-5的適配
文章出處:【微信號:moorethreads,微信公眾號:摩爾線程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
摩爾線程業績快報:2025年營收同比增長243.37%,S5000全棧適配SOTA大模型加速釋放商業潛能
摩爾線程MTT S5000全面適配Qwen3.5三款新模型
華為昇騰深度適配智譜AI全新開源模型GLM-5

摩爾線程 × 五一視界|共建全棧國產化的物理AI仿真體系

摩爾線程快速完成對Qwen3.5模型全面適配
Day-0支持|摩爾線程完成MiniMax M2.5模型極速適配
寒武紀實現對GLM-5的Day 0適配
智譜AI正式上線并開源全新一代大模型GLM-5
曦云C系列GPU Day 0 適配智譜全新一代大模型GLM-5

Day-0支持|摩爾線程MTT S5000率先完成對GLM-5的適配

全棧國產AI Coding上線:摩爾線程+硅基流動+智譜,強強聯合!

摩爾線程正式推出AI Coding Plan智能編程服務
華為CANN與智譜GLM端側模型完成適配
疑似摩爾線程S90曝光,對標RTX4060




 工商網監
工商網監
評論