") 格靈深瞳視覺(jué)基礎(chǔ)模型Glint-MVT的發(fā)展脈絡(luò)
格靈深瞳視覺(jué)基礎(chǔ)模型Glint-MVT的發(fā)展脈絡(luò)

此前,8月28-30日,2025百度云智大會(huì)在北京舉辦。在算力平臺(tái)專(zhuān)題論壇上,格靈深瞳技術(shù)副總裁、算法研究院院長(zhǎng)馮子勇分享了《視覺(jué)基座:通向世界模型之路——格靈深瞳Glint-MVT讓AI看懂世界》主題演講,從熱點(diǎn)話(huà)題“世界模型”引入,介紹格靈深瞳自研視覺(jué)基礎(chǔ)模型Glint-MVT的發(fā)展脈絡(luò)和技術(shù)亮點(diǎn),講述視覺(jué)模型基座如何讓AI理解復(fù)雜世界。
此次分享的主角:Glint-MVT(Margin-based pretrained Vision Transformer),是格靈深瞳靈感實(shí)驗(yàn)室自研的視覺(jué)基礎(chǔ)模型。自2023年發(fā)布MVT v1.0以來(lái),模型逐步迭代,在今年7月發(fā)布了MVT v1.5,同時(shí)MVT v2.0也籌備中。
MVT的誕生:引入間隔Softmax函數(shù)
MVT最大的技術(shù)創(chuàng)新性在于,團(tuán)隊(duì)?wèi)?yīng)用基于間隔的Softmax損失函數(shù)進(jìn)行模型訓(xùn)練。Softmax損失函數(shù)主要應(yīng)用于分類(lèi)訓(xùn)練,而基于間隔的Softmax(Margin-based Softmax),可以讓模型提取的特征更具區(qū)分度,提升視覺(jué)編碼器的能力。
靈感團(tuán)隊(duì)將這一函數(shù)特性應(yīng)用在視覺(jué)基礎(chǔ)模型訓(xùn)練上,推出MVT v1.0,構(gòu)建起視覺(jué)理解的堅(jiān)實(shí)基礎(chǔ)。
在MVT v1.0訓(xùn)練過(guò)程中,團(tuán)隊(duì)通過(guò)特征聚類(lèi)的方法,為4億無(wú)標(biāo)注圖片打上偽標(biāo)簽,形成100萬(wàn)個(gè)類(lèi)別。為解決偽標(biāo)簽類(lèi)別太多和標(biāo)簽噪聲的問(wèn)題,團(tuán)隊(duì)提出了標(biāo)簽采樣的方法,不僅大量減少卡間通信時(shí)延,還降低了標(biāo)簽噪聲對(duì)訓(xùn)練精度的影響,帶來(lái)訓(xùn)練效果和模型性能的雙重提升。
從MVT v1.0到 v1.1:突破單標(biāo)簽限制
在圖像識(shí)別過(guò)程中,一幅圖像通常包含多個(gè)物體,對(duì)應(yīng)著多個(gè)標(biāo)簽。因此,格靈深瞳將單標(biāo)簽升級(jí)為多標(biāo)簽,提升圖像編碼器的表達(dá)能力,由此得到MVT v1.1。
MVT v1.1可識(shí)別圖像中的多個(gè)物體,這一能力提升源自損失函數(shù)的優(yōu)化。靈感團(tuán)隊(duì)在1.0版softmax公式的基礎(chǔ)上進(jìn)行簡(jiǎn)單修改,讓多個(gè)正標(biāo)簽參與計(jì)算;在工程上,由讀取一個(gè)正類(lèi)別的中心特征變成讀取固定多個(gè)正類(lèi)別的中心特征。
MVT v1.5:局部和文字特征再增強(qiáng)
隨著下游任務(wù)對(duì)預(yù)訓(xùn)練模型能力的更高要求,靈感團(tuán)隊(duì)增強(qiáng)了模型對(duì)局部特征和文字特征的表達(dá)能力,推出MVT v1.5。
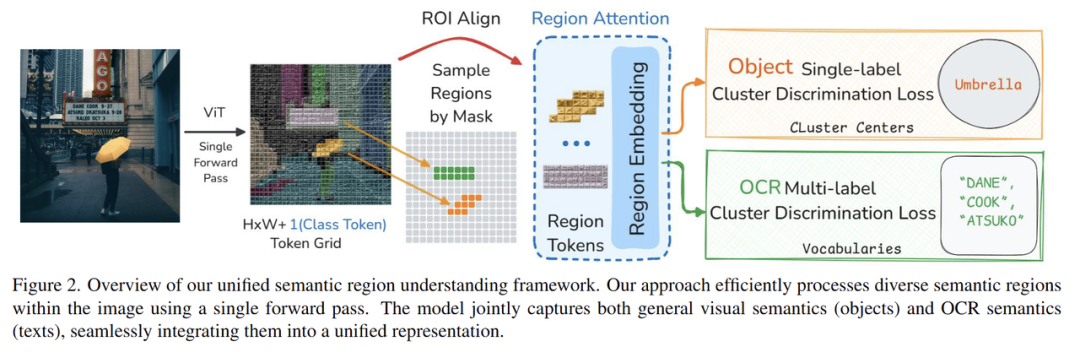
在實(shí)現(xiàn)方法上,團(tuán)隊(duì)利用專(zhuān)家分割模型和OCR模型,生成局部數(shù)據(jù)偽標(biāo)簽,得到20億局部區(qū)域和4億文字區(qū)域。同時(shí),團(tuán)隊(duì)提出了RegionAttention的方法——利用Mask Attention機(jī)制,更高效地提取局部區(qū)域特征。從檢測(cè)、分割等下游任務(wù)表現(xiàn)上看,MVT v1.5的多項(xiàng)分?jǐn)?shù)高于SigLIP等模型。
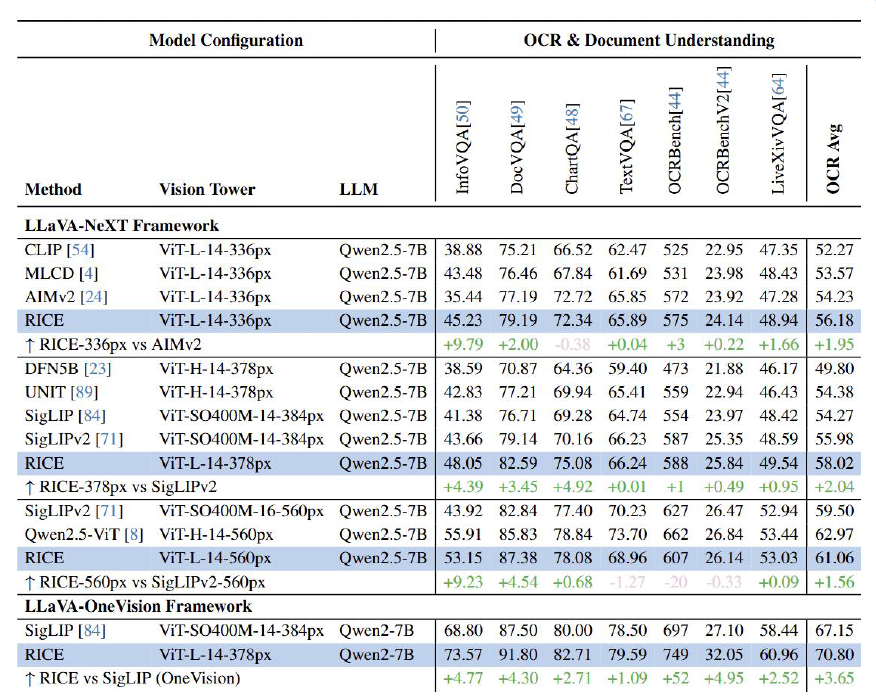
MVT v1.5(RICE)在OCR任務(wù)上的表現(xiàn)
靈感團(tuán)隊(duì)將MVT v1.5應(yīng)用到VLM開(kāi)源框架LLaVA-NeXT和LLaVA-OneVision中。對(duì)比其他視覺(jué)編碼器,如OpenAI的CLIP、谷歌的SigLIP、蘋(píng)果的DFN5B和AIMv2,MVT v1.5在OCR任務(wù)上表現(xiàn)更優(yōu)。這表明MVT v1.5在局部和文字特征上具有更好的表達(dá)能力。
MVT v2.x:圖片視頻統(tǒng)一支持
人類(lèi)和環(huán)境的交互以及任務(wù)完成,不只是一張張離散的圖片,而是一個(gè)時(shí)空連續(xù)的視頻流。下一步,靈感團(tuán)隊(duì)計(jì)劃對(duì)視頻進(jìn)行高效編碼,推出統(tǒng)一支持圖片視頻的視覺(jué)編碼器MVT v2.x,提升視頻特征表達(dá)能力。
-
AI
+關(guān)注
關(guān)注
91文章
40431瀏覽量
302047 -
百度
+關(guān)注
關(guān)注
9文章
2381瀏覽量
95094 -
格靈深瞳
+關(guān)注
關(guān)注
1文章
93瀏覽量
5991
原文標(biāo)題:格靈深瞳如何打造視覺(jué)模型基座?Glint-MVT成長(zhǎng)記
文章出處:【微信號(hào):shentongzhineng,微信公眾號(hào):格靈深瞳】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
格靈深瞳與佳都科技達(dá)成授權(quán)合作協(xié)議
格靈深瞳亮相摩爾線(xiàn)程首屆MUSA開(kāi)發(fā)者大會(huì)
格靈深瞳榮獲量子位2025人工智能年度領(lǐng)航企業(yè)
格靈深瞳受邀參加百度世界2025大會(huì)
格靈深瞳邀您相約百度世界2025大會(huì)
格靈深瞳與奧瑞德達(dá)成戰(zhàn)略合作
格靈深瞳加入海光產(chǎn)業(yè)生態(tài)合作組織
格靈深瞳智慧金融產(chǎn)品家族全新升級(jí)
格靈深瞳視覺(jué)基礎(chǔ)模型Glint-MVT升級(jí)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論