 沐曦攜手ABACUS推動國產科學計算新發展
沐曦攜手ABACUS推動國產科學計算新發展

長期以來,在科學計算這一關鍵領域,核心軟件與硬件大多依賴國外生態體系。這一現狀,不僅在性能優化上存在掣肘,也讓國產科研面臨“算力不可控”的現實挑戰。如何讓國產軟件在國產硬件上高效運行,構建真正自主可控的科學計算生態,成為科研界與產業界共同關注的焦點課題。
最近,國產開源密度泛函理論軟件——原子算籌(ABACUS)發布了最新迭代版v3.9.0.14和v3.9.0.15。值得關注的是,在這些更新中,沐曦科學計算團隊首次以開發者身份正式加入 ABACUS 社區。
這不僅是一項功能優化的升級,更是國產 GPGPU 與國產科學計算軟件深度融合的重要體現,標志著國產算力生態正在走向新的發展階段。
1沐曦 —— 賦能科學計算的國產 GPGPU
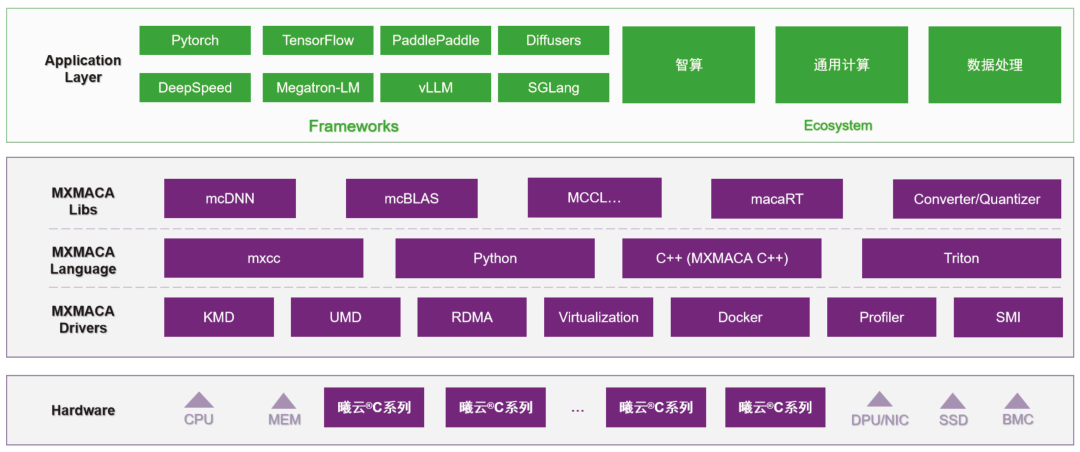
圖 1 MXMACA軟件棧
(高度兼容國際主流GPU軟件生態)
沐曦專注于高性能通用 GPU(GPGPU)的研發,致力于打造完整、自主可控的國產科學計算生態[1]。在軟件生態層面,沐曦推出了兼容國際主流GPU軟件生態的MXMACA 軟件棧:
兼容國際主流GPU軟件生態
使原代碼應用能夠輕松在沐曦GPGPU 上運行,為國產科學計算軟件的遷移和適配提供便利。
自研高性能數學庫
包括mcBLAS、mcFFT等,為科學計算提供核心算力保障。
AI4Science支撐[2]
依托MXMACA,在AI4Materials[3]領域,沐曦已覆蓋從第一性原理計算、分子動力學到 AI 融合的材料科學應用場景,為 AI4Materials 提供全面支持。更多AI4Science場景請點擊下方【閱讀原文】。
憑借出色的軟件生態兼容性與深厚的團隊開發和優化能力,沐曦正在加速推動科學計算領域的國產化進程。
2ABACUS —— 開源開放的國產電子結構軟件
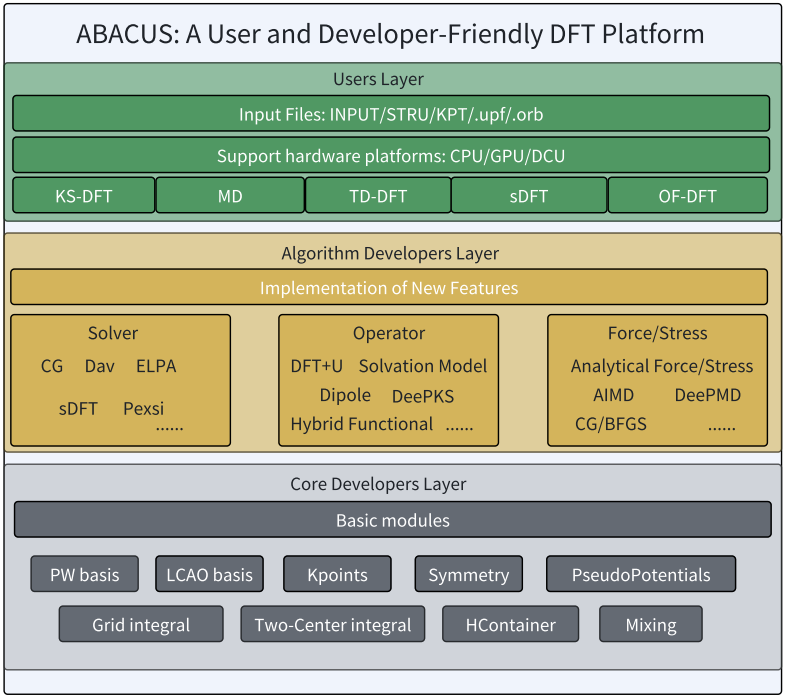
圖 2 ABACUS軟件的框架
來源:ABACUS: An Electronic Structure Analysis Package for the AI Era
ABACUS(中文名:原子算籌)[4,5]作為一款基于第一性原理方法的開源材料計算平臺,由中國科學技術大學、中科院物理研究所、北京大學、北京科學智能研究院、合肥綜合性科學中心人工智能研究院等多家單位共同開發維護,擁有完全自主的知識產權,主要面向凝聚態材料及高溫高壓物質模擬計算功能支持:
平面波基組與數值原子軌道基組;
電子結構優化、原子結構弛豫、分子動力學模擬等功能;
從小體系到上千原子的材料模擬計算。
ABACUS 還具備良好的擴展性:
可與DeePMD-kit、DeePKS-kit、DP-GEN、DeepTB、DeepH、HammGNN、Hefei-NAMD、PYATB、APEX、LibRI、LibCOMM、Multiwfn、Candela、ASE、Phonopy、Wannier90、TB2J、ShengBTE、Atomkit、PEXSI、等軟件聯動[6];
提供友好的開發者文檔、自動化測試與調試工具,方便科研人員快速上手[7]。
ABACUS不僅是一款科學計算軟件,更是國產開源科學計算生態的重要基石。
3沐曦 × ABACUS —— 共筑國產科學計算新生態
在 ABACUS 最新版本(v3.9.0.14和v3.9.0.15)的開發中,沐曦科學計算團隊首次以開發者身份正式加入社區[8-10],并取得了顯著成果:
快速適配
得益于MXMACA 出色的軟件生態兼容性,ABACUS在沐曦GPU上無需改動一行源碼即可順利運行,平面波的CG或Davidson方法求解特征值、LCAO基組求解Kohn-Sham方程等主流算法均已支持。
深度優化
通過沐曦自研求解器實現 DAV 特征值求解,大幅提升求解效率;在沐曦 C 系列硬件的高帶寬架構支持下,性能進一步釋放。
社區貢獻
沐曦科學計算團隊積極提交 PR,不僅帶來性能優化,也完成了部分 Bug 修復,為 ABACUS 的穩定發展貢獻力量。
3.164 GB顯存:單卡承載更大材料體系
在處理超大原子體系時,部分軟件可能因使用 32 位整型(int)作為數組索引或計數器,在體系規模超過一定閾值后觸發整數溢出,進而導致計算崩潰。這一問題通常在顯存容量較大的 GPU 上才會暴露——因為只有當單卡能容納足夠大的體系時,相關數據結構的尺寸才會增長到使 int 索引越界;而在顯存較小的 GPU 上,由于體系規模受限,往往無法觸發該邊界條件,因此問題長期隱藏。
沐曦科學計算團隊不僅協助 ABACUS 團隊定位并修復了這一關鍵 Bug,從根本上消除了大體系計算中的穩定性隱患,更充分發揮沐曦 GPGPU 大顯存(64 GB)容量優勢——單卡即可承載更大規模的體系,無需過早切分到多卡。這不僅顯著降低了對分布式內存和通信的依賴,也讓用戶能在更穩定、更經濟的單機多卡配置下高效完成超大體系的第一性原理模擬。
3.2性能再提速:算子融合 + Batch FFT 優化
在第一性原理計算中,傅里葉變換(FFT)是連接實空間與倒空間的核心操作,貫穿于電子密度構建、勢能計算、波函數更新等多個關鍵步驟。尤其在平面波或數值原子軌道基組框架下,FFT 的調用頻次高、數據規模大,成為影響整體性能的重要瓶頸。為此,沐曦科學計算團隊對 ABACUS 中的 FFT 相關流程進行了深度優化:
引入 Batch FFT 與算子融合技術:將 real_to_recip(實空間到倒空間)和 recip_to_real(倒空間到實空間)等關鍵路徑中的 FFT 運算重構為Batch FFT模式,將原本逐個執行的多個小規模 FFT 合并為一次批量調用,顯著提升了 FFT 部分的計算吞吐與 GPU 利用率。同時,針對這些流程中緊鄰 FFT 的其他計算操作(如數據重排,縮放等),沐曦科學計算團隊實施了算子融合優化,將多個小 kernel 合并為更高效的執行單元。兩項優化協同作用,共同推動 ABACUS 在 沐曦GPGPU 上的整體性能提升。
與此同時,本征態求解是第一性原理計算的另一核心挑戰,其算法選擇直接影響收斂速度與計算穩定性。相較于傳統的共軛梯度(CG)方法,Davidson(DAV)算法往往展現出更優的收斂行為。盡管 DAV 算法在實現上會占用更多顯存,但其在 GPU 上的并行潛力巨大。針對這一特點,我們對 DAV 模塊進行了優化:
Davidson 對角化算法全面 GPU 化:將原本運行在 CPU 上的計算邏輯完整遷移至 GPU 端,結合內存訪問優化與自定義融合 kernel,高效實現了梯度計算、向量歸一化等操作。
減少 Host-Device 數據拷貝:關鍵數據全程常駐顯存,避免因 CPU 側輔助計算引發的冗余數據搬運,確保 GPU 計算單元持續滿載。
沐曦科學計算團隊協同 ABACUS 社區修復多項關鍵問題,確保生產環境穩定可靠:
修復 USE_ELPA=OFF 且 BUILD_TESTING=ON 時的編譯錯誤;
解決 Debug 模式下多 GPU 并行因設備上下文管理不當導致的崩潰問題
——現在,調試與生產環境同樣穩健!
4高效協作,源于優秀的開源工程實踐
沐曦科學計算團隊能夠高效、快速地向 ABACUS 貢獻上述優化與修復,離不開 ABACUS 項目本身卓越的軟件工程實踐。其代碼結構清晰、模塊解耦良好,GPU 后端采用高度規范化的模板化設計,接口定義明確,文檔完善,使得新功能集成與性能調優工作得以順暢推進。這種對開發者友好的架構,不僅大幅降低了硬件廠商參與適配的門檻,也為國產科學計算軟件的可持續演進樹立了標桿。正因如此,沐曦科學計算團隊才能在短時間內完成從性能分析、算法優化到代碼提交的完整閉環,并順利合入主干,真正實現“軟硬協同,快速迭代”。這不僅是一次適配與優化,更是國產 GPGPU 與國產軟件深度融合的縮影。
未來,沐曦將繼續攜手 ABACUS,共同推動 “國產軟件 + 國產硬件” 的科學計算新生態,為 AI4Science 時代的突破性研究提供堅實算力支撐。
-
科學計算
+關注
關注
0文章
6瀏覽量
1241 -
GPGPU
+關注
關注
0文章
33瀏覽量
5497 -
沐曦
+關注
關注
1文章
80瀏覽量
1811
原文標題:國產GPGPU × 國產軟件|沐曦攜手 ABACUS,共筑國產科學計算新生態
文章出處:【微信號:沐曦MetaX,微信公眾號:沐曦MetaX】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
沐曦股份CXO預科班2026冬令營圓滿收官
沐曦曦云C600 GPU產品適配階躍星辰基座模型Step 3.5 Flash

沐曦股份正式推出曦索X系列全新GPU品牌與產品線
大曉機器人與沐曦股份簽署戰略合作協議
沐曦股份MXMACA軟件棧3.3.0.X版本技術解析

沐曦股份在上海證券交易所科創板掛牌上市
沐曦股份攜手紅帽共同發布MXAIE解決方案

瀚海量子與沐曦股份達成戰略合作 量子計算軟件領軍者+高性能GPU芯片領軍者
沐曦股份與上海電信完成首期GPU生態專家認證培訓
強強聯合:之江實驗室與沐曦股份共建智算集群聯合實驗室
首款全國產通用GPU芯片發布 沐曦集成推出曦云C600
沐曦曦云C系列產品已支持TileLang




 工商網監
工商網監
評論