 Arm Neoverse N2平臺實現DeepSeek-R1滿血版部署
Arm Neoverse N2平臺實現DeepSeek-R1滿血版部署

今年年初,開源大語言模型 (LLM) DeepSeek 在國內外人工智能 (AI) LLM 領域掀起熱議。它在模型架構和訓練、推理方法上實現創新,在性能和工程效率上帶來了顯著提升,并在成本效率方面頗具優勢。Arm 攜手合作伙伴,在 Arm Neoverse N2 平臺上使用開源推理框架 llama.cpp 實現 DeepSeek-R1 滿血版的部署,目前已可提供線上服務。
在基于 Neoverse N2 平臺設計的服務器級 CPU 上,通過對軟硬件架構的合理適配,以及出色調優來充分發揮平臺的計算能力和內存帶寬,能夠以 INT8 的量化版本提供業界可用的詞元 (token) 生成速度,并以更具競爭力的性價比為中小微企業提供業界頂尖的 LLM 服務。
在部署 DeepSeek 大模型過程中,Arm 結合底層架構特性進行了深度優化:模型本身跨多 ?NUMA(非統一內存訪問)節點以交錯 (interleave) 方式加載,以便充分利用所有內存帶寬;除 INT8 量化外,通過開啟 KV 量化,以及激活 Flash Attention 機制,以此進一步降低計算量和壓縮內存占用。通過技術團隊的努力,DeepSeek 滿血版的整體性能相較優化前提升了 67%。工程團隊后續也會持續投入,提高多節點上的計算并發度及帶寬利用率,并通過開發者社區不斷完善 Arm 架構的軟件生態。
細究 DeepSeek 的模型架構創新,它針對大模型運行時的痛點進行計算、內存訪問和算法流水線上的效率提升,比如 MLA 和 FP8 訓練和推理減少了內存占用和帶寬需求,DeepSeekMoE 降低了計算強度、提高計算效率,DualPipe 提高了多計算節點間的通信和計算效率。這些工程優化思維與 Arm 一貫倡導的高能效設計目標不謀而合,也使得在純 CPU 平臺上運行如此大規模的模型成為可能。
Arm 平臺致力于助力合作伙伴提高性能,并降低總體擁有成本 (TCO),在 Neoverse N2 平臺運行 DeepSeek 大模型推理也淋漓盡致地體現了這一原則。在為中小微企業提供大模型服務時,并發需求降低,成本敏感度提高。在基于 Neoverse N2 平臺上運行的 DeepSeek-R1 為他們提供了一個更為均衡的選擇。相較傳統多卡 GPU/加速器平臺,這能極大地降低訂閱服務成本,使用戶能以較低代價快速啟動業務部署。下圖是兩種方案訂閱服務的價格對比:
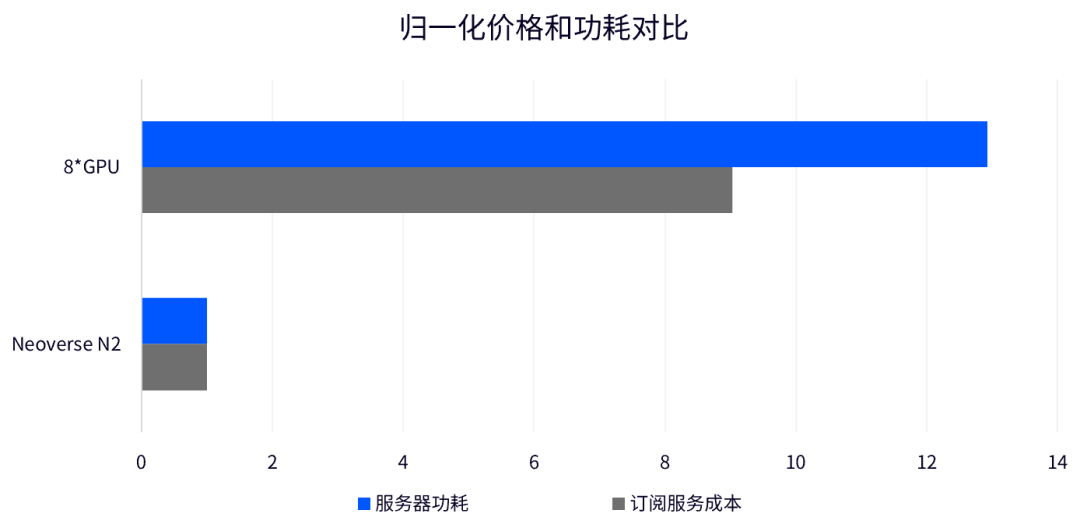
搭載 Neoverse N2 平臺的服務器平臺能把部署成本降低約八倍。此外,對數據中心來說,在 CPU 上部署 LLM 也能充分利用在線的空閑算力,提高整體資源利用率。與此同時,基于 Neoverse N2 平臺的服務器功耗僅為傳統八卡 GPU 服務器的 1/12,能極大地降低數據中心的能耗壓力。
如此大規模的模型(6,710億參數)能夠在數據中心服務器級 CPU 上運行,并迅速上線為客戶提供快速部署,得益于 Neoverse 平臺對 AI 推理負載的一貫思考和設計,包括 2 x 128 位的可伸縮向量擴展 (SVE2) 特性、BF16/INT8 數據格式支持,以及點積和矩陣乘法等指令的支持,加之多通道高帶寬內存配置,和低延遲 CMN 互聯等等。
隨著 AI 領域的飛速發展,LLM 在持續的工程創新和優化之下應用領域不斷變廣。Arm 將持續通過 Neoverse 平臺為行業賦能,并在這一新的技術紀元中引領變革。
-
ARM
+關注
關注
135文章
9573瀏覽量
392910 -
人工智能
+關注
關注
1819文章
50190瀏覽量
266315 -
DeepSeek
+關注
關注
2文章
837瀏覽量
3345
原文標題:在 Arm Neoverse N2 平臺上以更優成本、更低功耗,充分釋放 DeepSeek-R1 滿血版性能
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
百度騰訊搶灘布局!DeepSeek-R1升級和開源背后,國產AI的逆襲之路
如何在Arm Neoverse N2平臺上提升llama.cpp擴展性能
DeepSeek R1 MTP在TensorRT-LLM中的實現與優化

速看!EASY-EAI教你離線部署Deepseek R1大模型

【「DeepSeek 核心技術揭秘」閱讀體驗】--全書概覽
【VisionFive 2單板計算機試用體驗】3、開源大語言模型部署
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄





 工商網監
工商網監
評論