 AI?時代來襲,手機芯片面臨哪些新挑戰?
AI?時代來襲,手機芯片面臨哪些新挑戰?

本文翻譯自Semiengineering
邊緣AI、生成式AI(GenAI)以及下一代通信技術正為本已面臨高性能與低功耗壓力的手機帶來更多計算負載。
領先的智能手機廠商正努力應對本地化生成式AI、常規手機功能以及與云之間日益增長的數據傳輸需求所帶來的計算與功耗挑戰。
除了人臉識別等邊緣功能以及各種本地應用,手機還必須持續適配新的通信協議以及系統和應用更新。更重要的是,這一切都要在單次電池充電下完成,同時確保設備在用戶手中或貼近面部時保持低溫。
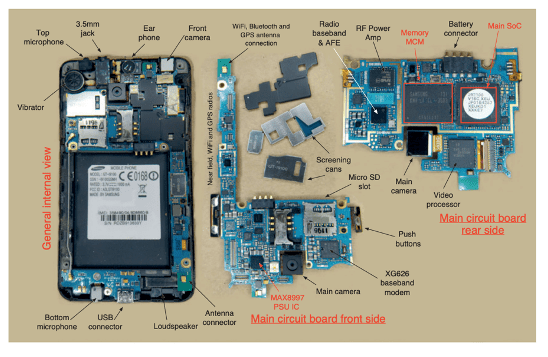
圖1:移動電話主板,右上為SoC(系統級芯片),包含Arm CPU及其他組件。
圖片來源:Arm
“如果你查看任何一款高端手機的配置,你會發現所有的SoC都采用異構架構,不同的模塊處理不同的任務,同時又協同工作。”Imagination Technologies細分市場戰略與產品管理高級總監Vitali Liouti表示,“從系統角度來看,所有移動SoC廠商都會以平臺的方式同時考慮硬件和軟件的協同設計。”
Cadence公司硅解決方案事業部Tensilica DSP產品管理與市場營銷總監Amol Borkar表示,AI網絡的快速演進和模型需求的多樣化使得移動SoC設計變得日益復雜。“與傳統工作負載不同,AI模型——尤其是大語言模型(LLMs)和變換器(Transformer)變體——在架構、規模和計算需求上都在不斷變化。這對芯片設計者來說是一個移動靶,因為芯片一旦投片就無法更改,但他們仍需預置未來AI能力的支持。更復雜的是,芯片還必須兼顧云端的大型模型與本地推理的小型高效模型(如TinyLlama)。這些小型LLM對于移動和嵌入式設備至關重要,因為它們需要在極低功耗與存儲限制下實現智能功能。”
除了從系統角度整體規劃外,AI也正在推動單個處理器架構和任務分配的變革。
“當前的變化主要體現在兩個方向。”Synaptics物聯網與邊緣AI處理器部門副總裁兼總經理John Weil表示,“一是Arm和RISC-V生態系統中的CPU架構持續增強,人們正在為Transformer模型添加矢量數學單元以加速各類數學運算;二是神經處理器(NPU)的改進,它們類似GPU,但專用于邊緣AI模型加速,基本上也是矢量計算單元,用于加速模型內部的各種算子。如果查看Arm的TOSA(Tensor Operator Set Architecture)規范,里面定義了各種AI操作,開發者也在為其編寫類似GPU的OpenGL加速程序。”
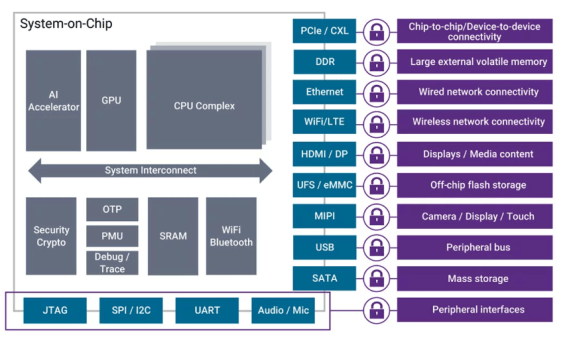
圖2:移動SoC設計示意圖,AI加速器可以是GPU、NPU或高端ASIC。圖片來源:Synopsys
過去幾年,GPU和NPU的設計都經歷了快速演進以適應新應用場景。Imagination的Liouti指出,在高端手機中,GPU通常占芯片面積的約25%,而NPU的體積也持續擴大以承擔更多工作負載。“具體在哪個模塊上運行任務取決于模型。例如某些層適合NPU執行,而有些則需要GPU配合。NPU已成為低功耗任務的關鍵,尤其適用于‘始終在線’(Always-On)的場景。同時,還必須搭配高性能CPU,因為它承擔初始加載和任務管理。如果CPU性能不足,再強大的GPU或NPU也難以發揮作用。”
在所有并行處理任務(圖形、通用計算或AI)中,功耗效率始終是核心。“我們對標量單元(ALU)進行了全面重構和調優,以實現更高的能效。”Imagination產品管理副總裁Kristof Beets表示,“接下來我們要將更多NPU技術引入GPU,例如更專用的數據類型和處理管線,以在保持可擴展性的同時提供更強性能。當然,我們也不能忽視開發者社區,如何實現開箱即用、如何進行高效優化與調試,這是我們重點關注的方向。”
如今,將AI集成進芯片的難度已大幅降低。“五年前大家還在問AI到底該怎么做,是不是得雇一整個數據科學家團隊?現在完全不是這樣了。”Infineon IoT、消費及工業MCU部門高級副總裁Steve Tateosian說,“我們擁有一整個DSP博士工程師團隊,他們在調試音頻前端,開發工程師通過AI工具來建模即可。開發流程也變得極為順暢:數據采集、標注、建模、測試、優化——工具鏈已大幅提升,很多專業知識已內嵌其中,讓更多工程師都能上手。”
視覺化、無線化與觸控挑戰
隨著AI應用增長,界面也趨于視覺化,對處理能力的要求更高。
“過去是計算機或基于文本的界面,如今一切都變成了視頻或全圖形界面,而這類界面的計算需求要高得多。”Ansys產品營銷總監Marc Swinnen表示,“無論是屏幕輸入還是1080p等格式的視頻輸出,視頻的輸入輸出管理都需要大量計算資源。”
此外,如今手機中的所有功能幾乎都是無線的,因此模擬電路的比例大幅上升。“現在的手機大約配有六根天線——這太瘋狂了。”Swinnen說,“所有這些高頻通信功能,包括Wi-Fi、5G、藍牙、AirDrop等,都有各自的頻段、芯片和天線。”
通信標準不斷演進的事實,也為SoC設計者帶來了額外挑戰。
“當前的關鍵在于推動AI應用落地,并加速UFS(通用閃存存儲)的標準推進。”Synopsys移動、汽車和消費類IP產品管理執行總監、MIPI聯盟主席Hezi Saar表示,“MIPI聯盟成功將推進時間提前了一年,這大大降低了風險。行業現在正在定義這個規范。SoC和IP廠商需要在規范尚未完全定稿時就開始開發自己的IP。他們需要在規范尚不完整時完成流片、拿到初步的硅片,同時還要為下一版規范做規劃,提前考慮互操作性以及生態系統的構建。這在過去是不可想象的。以前標準的更新是有節奏的,比如每兩年一個版本。但現在節奏被大大壓縮,因為AI更偏向軟件領域,而它對硬件的影響巨大。硬件終究不是軟件。”
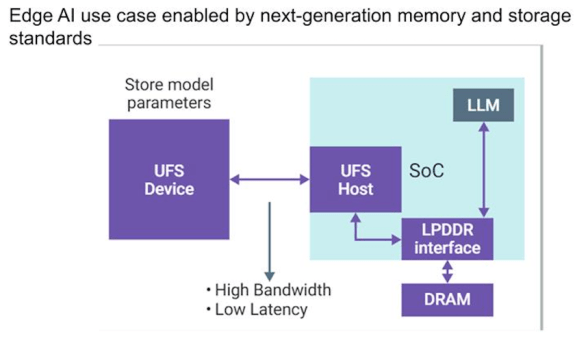
圖3:智能手機中的LLM或AI引擎依賴高效存儲訪問。
圖片來源:Synopsys
“當你啟動設備時,大部分模型需要加載到DRAM中,這意味著從UFS存儲設備到SoC的讀取鏈路必須非常高效。”Saar表示,“這關乎延遲——你不能按下按鈕提問,然后等兩秒鐘。當然,也有其他處理方式,比如你不必讀取整個模型,可以進行部分讀取。但這些系統的核心任務就是將數據快速傳輸到DRAM。我已經在芯片上運行了LLM,比如通過某個加速器,但它需要和DRAM高效連接以完成計算,然后再將結果返回給用戶,比如音頻輸出。在移動設備中,這個流程必須非常高效,功耗尤為關鍵。因此廠商會盡可能減少傳輸次數,并將UFS存儲盡可能多地置于休眠狀態。我預計未來存儲接口和DRAM接口都會發展得非常非常快——遠快于以往。”
多模態模型和像Stable Diffusion這樣的生成式AI工具也加大了系統的復雜性。這類模型將文本、圖像,甚至音頻處理集成到統一架構中。Cadence的Borkar表示:“這些模型需要一種靈活高效的計算架構,能夠處理多樣的數據類型和執行模式。為了在快速演進的AI環境中保持韌性,AI子系統在設計時必須具備面向未來的可擴展性。這通常意味著在NPU旁邊集成可編程IP塊,使SoC能在芯片量產后仍能適配新模型和新負載。支持如此廣泛的AI應用場景,要求SoC不僅性能強大、能效高,還要具備高度的架構靈活性,這也讓AI中心化芯片設計成為移動計算領域最具挑戰性的前沿方向之一。”
算法在手機上的另一個典型應用是判斷哪些觸控是有效的,哪些不是,無論是傳統的“糖塊機”還是折疊屏手機。后者由于屏幕極薄,挑戰更大。
“屏幕變得很薄時,觸控層必須貼得非常接近帶噪聲的顯示層。”Synaptics產品營銷總監Sam Toba表示,“我們需要處理來自單個像素的大量顯示噪聲。這在超薄顯示器中是個問題。背景層越薄,電容板之間越接近,整體電容就越高。而觸控本身依賴檢測非常微小的電容變化,在背景電容極高的情況下,識別出有效手指信號就變得更加困難。”
這種超低功耗芯片必須在本地判斷哪些信號是有效的,只有在確認是有效觸控后才喚醒主SoC。“如果由主控芯片來識別觸控信號,它就必須持續運行,這將導致巨大的功耗。因此,大部分無效觸控必須在本地就被過濾掉。”
本地AI處理與模型部署
手機中集成了眾多AI應用,且數量還在持續增加。Ansys的Swinnen指出,在可能的情況下,AI推理應盡量在本地完成,僅將精簡過的信息上傳至云端。例如,人臉識別或圖像處理等機器學習功能應靠近攝像頭完成處理。
即便是像ChatGPT或具備智能代理功能的GenAI模型,其推理過程也可本地完成。Synopsys的Saar表示,AI模型現在更高效也更緊湊,大小從幾兆到幾十兆不等,完全可以部署在設備本地,視具體模型與設備而定。
在本地處理AI帶來諸多優勢。Siemens Digital Industries Software的網絡解決方案專家Ron Squiers指出:“將AI硬件集成到移動設備中,可以直接在本地運行大語言模型的推理,不再需要將數據發回云端處理。這帶來的好處是雙重的:延遲更低,響應更及時,閉環控制性能更好;同時還可提升數據隱私,因為數據不會離開設備。”
Infineon的Tateosian也表示贊同:“數據不再上傳云端,這降低了功耗和成本。有些邊緣AI應用甚至可以在不引入連接成本的前提下提升智能水平,或者減少對連接的依賴——這意味著減少云端通信和終端設備的整體功耗。”
Imagination的Liouti指出,如今是一個“極致優化(hyper-optimization)”的時代,設計者必須消除一切“技術債務”,從而榨取設備更多性能:“數據搬移消耗了約78%的功耗。我們工作的重點是如何減少這些數據移動。這可以通過GPU實現,也是我們主要發力的地方,但也可以在平臺級或SoC層面優化。我們需要開發非常先進的技術來解決這個問題。而對于神經網絡尤其是大型模型而言,數據搬運的挑戰會更大。”
盡管本地AI推理正在快速發展,但由于電池和功耗的限制,仍有部分任務需要依賴云端。“你總要有所取舍。”Liouti說,“這只是一個旅程的開始,幾年后情況會截然不同。我們現在還只是剛剛起步。我認為transformer是未來更大系統的基礎模塊。目前,我們需要將炒作和現實區分開。以本地運行圖像生成模型為例,雖然現在手機上也能跑,但性能遠不如你在PC上用Midjourney生成的圖像。不過幾年后,情況就會變了。”
更強大的GPU也將成為解決方案的一部分。“在移動平臺上,我們可以把省下來的功耗轉化為更高的主頻和更強的性能,同時依然保持在同一個功耗與熱預算范圍內。”Imagination的Kristof表示。
不過Infineon的Tateosian也指出,盡管設備每一代的性能和內存都在增長,但用戶實際體驗變化不大。“因為軟件的增長完全吞噬了這些性能提升。”
結語
移動SoC設計正受到多項關鍵趨勢的驅動。
“模擬部分的增長、一切內容視頻化與AI化,再加上當今應用對高性能計算(HPC)的需求,使得芯片必須具備極強的算力。”Ansys的Swinnen表示,“這些因素正在推動SoC的演進,但手機制造商面臨的限制在于,他們必須保持低功耗和小尺寸設計,同時相比于像NVIDIA這樣的GPU公司,他們在成本上受到更嚴格的限制。NVIDIA可以優先考慮性能,即使成本略高也無妨。但手機芯片不一樣,它必須能以極低成本大規模量產。”
芯片設計者必須從軟硬件協同的角度出發來設計SoC。“任何忽視這點的人,最終都會失敗。”Imagination的Liouti強調,“我們必須將語言模型的層級、操作類型等問題納入考慮。聽起來簡單,但實際上并不容易。你必須找到一種方式,最大化利用硬件來完成數學運算,從而確保你的解決方案在競爭中脫穎而出,因為我們面對的是行業巨頭。必須進行軟硬件協同設計,而這絕非一個工程師就能獨立完成的任務,而是需要多個學科背景的專家共同合作,其中有些領域甚至看起來毫不相關。”
原文鏈接:https://semiengineering.com/mobile-chip-challenges-in-the-ai-era/
-
手機芯片
+關注
關注
9文章
375瀏覽量
50813 -
AI
+關注
關注
91文章
40493瀏覽量
302088
發布評論請先 登錄
手機SoC邁入“百TOPS”時代!蘋果、高通和聯發科新芯前瞻,誰是真香之選?

估值700億,國產智能手機芯片第一股沖擊IPO!
芯片可靠性面臨哪些挑戰

光計算芯片面世了,但怎么給它“灌入靈魂”?

今日看點:高通發布云端AI芯片;艾為電子推出低功耗Hyper-Hall?芯片 高通發布云端AI芯片 近日,美國高通公
AI賦能6G與衛星通信:開啟智能天網新時代
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片到AGI芯片
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+半導體芯片產業的前沿技術
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片的需求和挑戰
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+內容總覽
【書籍評測活動NO.64】AI芯片,從過去走向未來:《AI芯片:科技探索與AGI愿景》

手機芯片:從SoC到Multi Die




 工商網監
工商網監
評論