") Arm技術(shù)助力Google Axion處理器加速AI工作負(fù)載推理
Arm技術(shù)助力Google Axion處理器加速AI工作負(fù)載推理

作者:Arm 基礎(chǔ)設(shè)施事業(yè)部高級(jí)產(chǎn)品經(jīng)理 Ashok Bhat
由 Arm Neoverse V2 平臺(tái)賦能的 Google Axion 處理器已在 Google Cloud 上正式上線,其中,C4A 是首款基于 Axion 的云虛擬機(jī),為基于 CPU 的人工智能 (AI) 推理和通用云工作負(fù)載實(shí)現(xiàn)了顯著的性能飛躍。
Axion CPU 延續(xù)了 Google Cloud 的定制芯片計(jì)劃,旨在提高工作負(fù)載性能和能效,標(biāo)志著在重塑 AI 云計(jì)算格局方向上的重大進(jìn)步。Google 選擇 Arm Neoverse 平臺(tái)是因?yàn)樗邆涓咝阅堋⒏吣苄Ш蛣?chuàng)新靈活性,而且有著強(qiáng)大的軟件生態(tài)系統(tǒng)和廣泛的行業(yè)應(yīng)用,可確保與現(xiàn)有應(yīng)用的輕松集成。
Neoverse V2 平臺(tái)引入了新的硬件擴(kuò)展,例如 SVE/SVE2、BF16 和 i8mm,與上代 Neoverse N1 相比,顯著增強(qiáng)了機(jī)器學(xué)習(xí)性能。這些擴(kuò)展增強(qiáng)了向量處理、BFloat16 運(yùn)算和整數(shù)矩陣乘法,使得基于 Neoverse V2 的 CPU 每周期執(zhí)行的 MAC 運(yùn)算次數(shù)比 N1 提高最多四倍。
從生成式 AI 到計(jì)算機(jī)視覺:加快 AI 工作負(fù)載推理速度并提升性能
立足于開源為原則的 AI 具備眾多領(lǐng)先的開源項(xiàng)目。近年來,Arm 一直與合作伙伴開展密切合作,以提高這些開源項(xiàng)目的性能。在許多情況下,我們會(huì)利用 Arm Kleidi 技術(shù)來提高 Neoverse 平臺(tái)上的性能,Kleidi 技術(shù)可通過 Arm Compute Library 和 KleidiAI 庫(kù)訪問。
大語言模型
由 Meta 開發(fā)的 Llama 模型包含一系列先進(jìn)的大語言模型 (LLM),專為各種生成任務(wù)而設(shè)計(jì),模型大小從 10 億到 4,050 億個(gè)參數(shù)不等。這些模型針對(duì)性能進(jìn)行了優(yōu)化,并可針對(duì)特定應(yīng)用進(jìn)行微調(diào),因而在自然語言處理任務(wù)中用途廣泛。
Llama.cpp 是一個(gè) C++ 實(shí)現(xiàn)方案,可以在不同的硬件平臺(tái)上實(shí)現(xiàn)這些模型的高效推理。它支持 Q4_0 量化方案,可將模型權(quán)重減少為 4 位整數(shù)。
為了展示基于 Arm 架構(gòu)的服務(wù)器 CPU 在 LLM 推理方面的能力,Arm 軟件團(tuán)隊(duì)和 Arm 合作伙伴對(duì) llama.cpp 中的 int4 內(nèi)核進(jìn)行了優(yōu)化,以利用這些新的指令。具體來說,我們?cè)黾恿巳N新的量化格式:為僅支持 Neon 的設(shè)備添加了 Q4_0_4_4,為支持 SVE/SVE2 和 i8mm 的設(shè)備添加了 Q4_0_4_8,為支持 SVE 256 位的設(shè)備添加了 Q4_0_8_8。
因此,與當(dāng)前的 x86 架構(gòu)實(shí)例相比,基于 Axion 的虛擬機(jī)在提示詞處理和詞元 (token) 生成方面的性能高出兩倍。
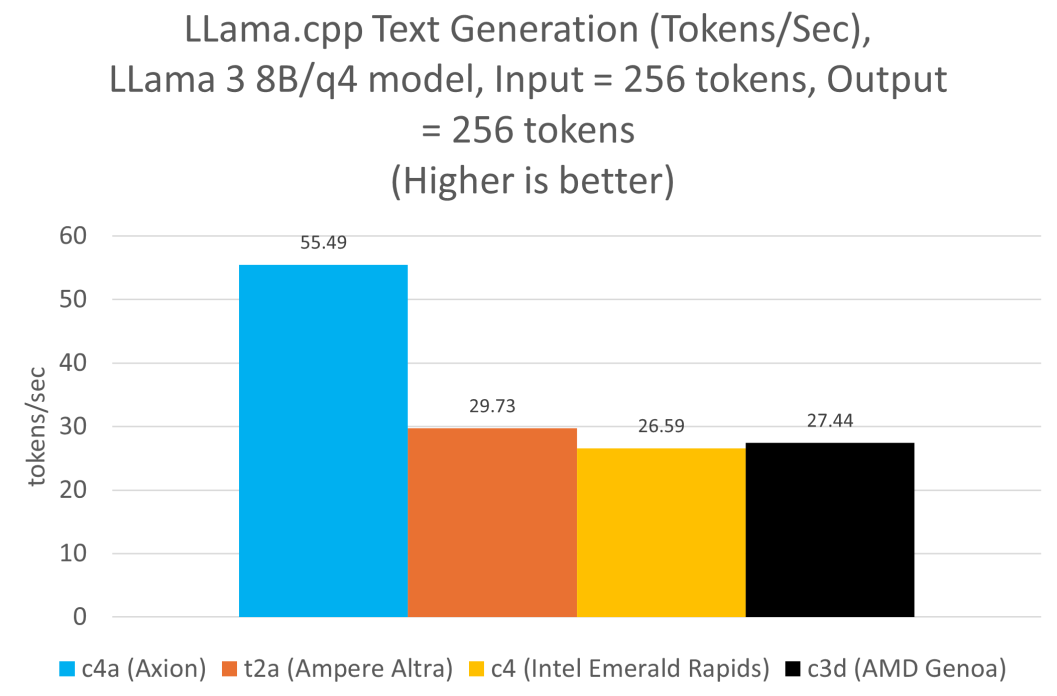
我們?cè)谒袑?shí)例上運(yùn)行了 Llama 3.1 8B 模型,并對(duì)每個(gè)實(shí)例使用了推薦的 4 位量化方案。Axion 的數(shù)據(jù)是在 c4a-standard-48 實(shí)例上使用 Q4_0_4_8 量化方案生成的,而 Ampere Altra 的數(shù)據(jù)是在 t2a-standard-48 實(shí)例上使用 Q4_0_4_4 生成的。x86 架構(gòu)的數(shù)據(jù)是在 c4-standard-48 (Intel Emerald Rapids) 和 c3d-standard-60 (AMD Genoa) 上使用 Q4_0 量化格式生成的。在所有實(shí)例中,線程數(shù)始終設(shè)置為 48。
BERT
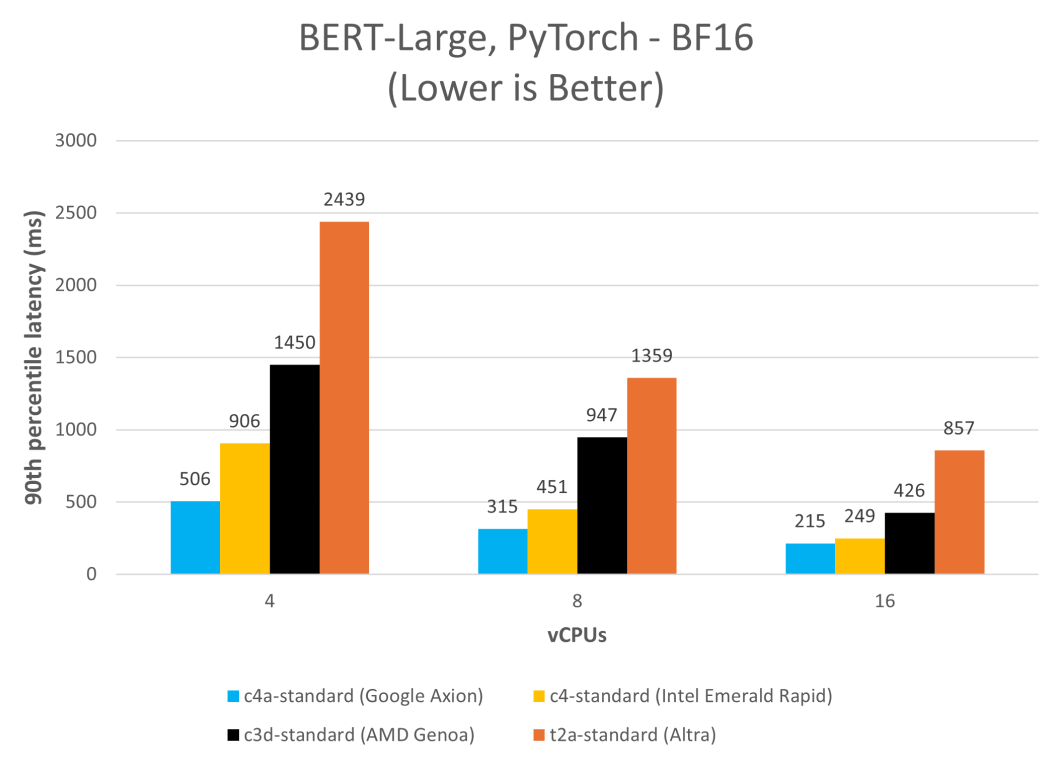
在 C4A 虛擬機(jī)上運(yùn)行 BERT 取得了顯著的速度提升,大幅減少了延遲并提高了吞吐量。此例中,我們?cè)诟鞣N Google Cloud 平臺(tái)實(shí)例上以單流模式(批量大小為 1)使用 PyTorch 2.2.1 運(yùn)行 MLPerf BERT 模型,并測(cè)量第 90 百分位的延遲。
ResNet-50
此外,Google Axion 的功能不僅限于 LLM,還可應(yīng)用于圖像識(shí)別模型,例如 ResNet-50 就能受益于此硬件的先進(jìn)特性。BF16 和 i8mm 指令集成后,實(shí)現(xiàn)了更高的精度和更快的訓(xùn)練速度,展現(xiàn)了 Axion 相較基于 x86 架構(gòu)實(shí)例的性能優(yōu)勢(shì)。
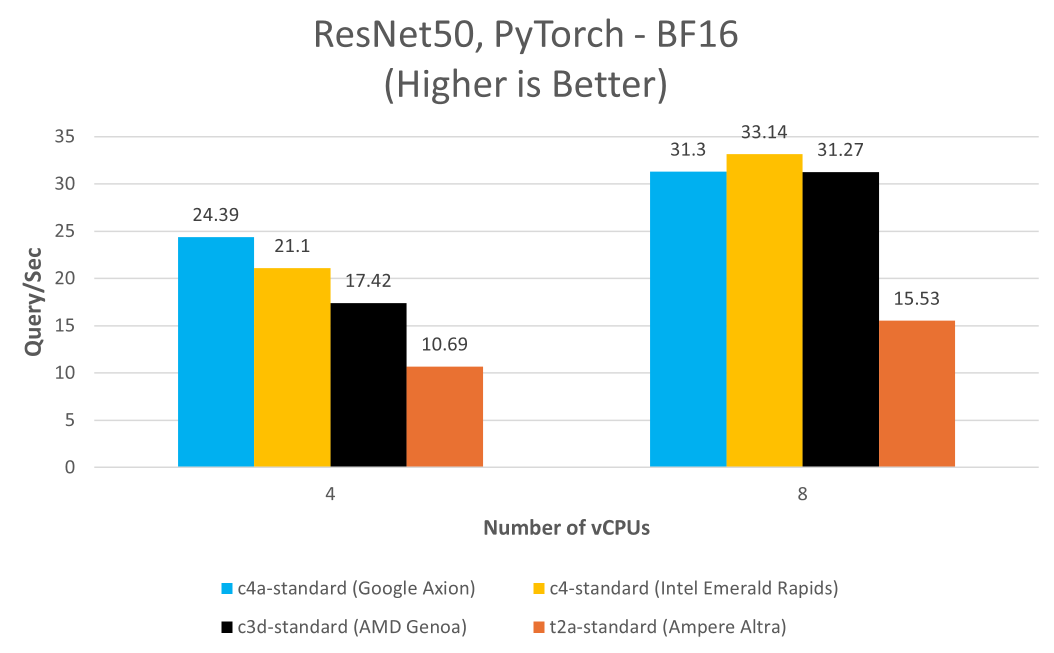
此例中,我們?cè)诟鞣N Google Cloud 平臺(tái)實(shí)例上以單流模式(批量大小為 1)使用 PyTorch 2.2.1 運(yùn)行 MLPerf ResNet-50 PyTorch 模型。
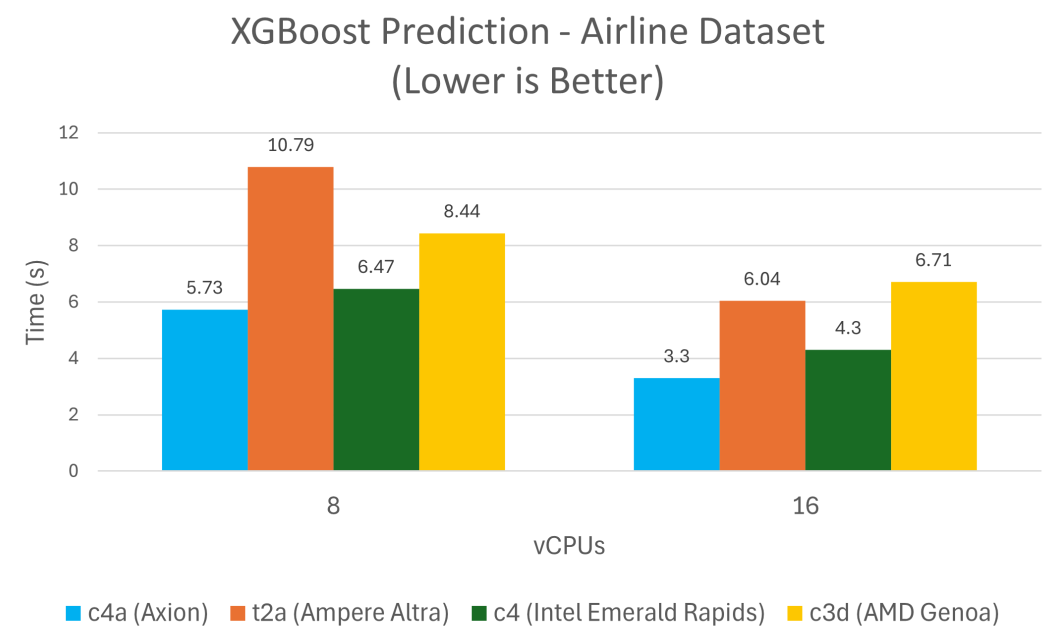
XGBoost
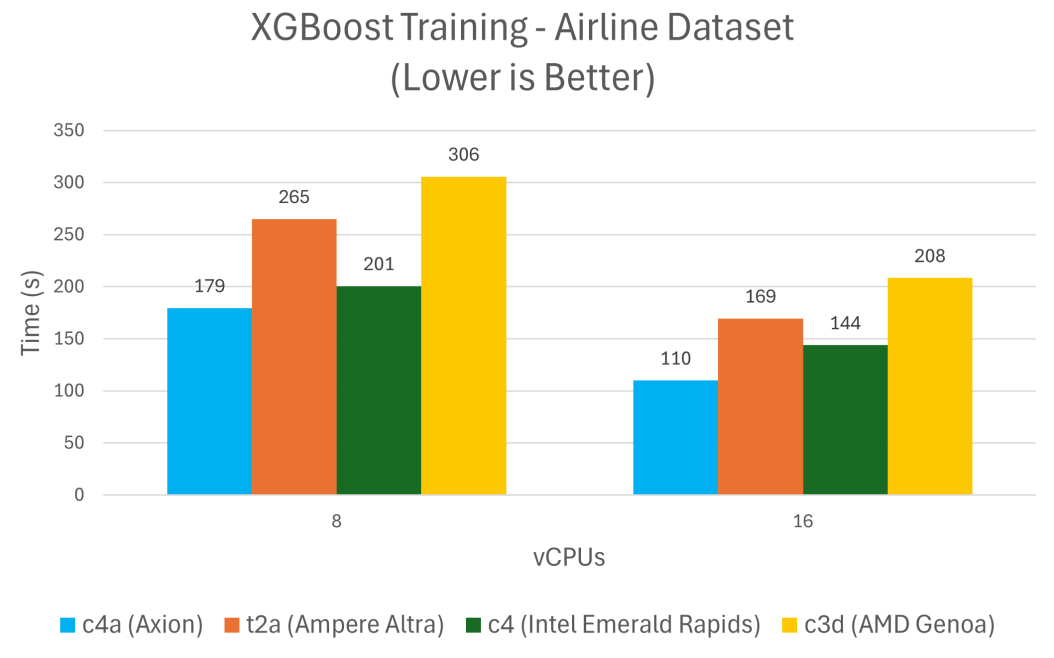
XGBoost 是一個(gè)領(lǐng)先的機(jī)器學(xué)習(xí)算法庫(kù),用于解決回歸、分類和排序問題,與 Google Cloud 上類似的 x86 架構(gòu)實(shí)例相比,在 Axion 上訓(xùn)練和預(yù)測(cè)所需的時(shí)間減少了 24% 到 48%。
結(jié)論
從上述結(jié)果,可以發(fā)現(xiàn)基于 Axion 的虛擬機(jī)在性能方面超越了上一代基于 Neoverse N1 的虛擬機(jī)和 Google Cloud 上其他的 x86 架構(gòu)替代方案。Google Cloud C4A 虛擬機(jī)能夠處理從 XGBoost 等傳統(tǒng)機(jī)器學(xué)習(xí)任務(wù)到 Llama 等生成式 AI 應(yīng)用的各類工作負(fù)載,是AI 推理的理想之選。
Arm 資源:助力云遷移
為了提升 Google Axion 的使用體驗(yàn),Arm 匯集了各種資源:
[1] 通過 Arm Learning Paths 遷移到 Axion:依照詳細(xì)的指南和最佳實(shí)踐,簡(jiǎn)化向 Axion 實(shí)例的遷移。
[2] Arm Software Ecosystem Dashboard:獲取有關(guān) Arm 的最新軟件支持信息。
[3] Arm 開發(fā)者中心:無論是剛接觸 Arm 平臺(tái),還是正在尋找開發(fā)高性能軟件解決方案的資源,Arm 開發(fā)者中心應(yīng)有盡有,可以幫助開發(fā)者構(gòu)建更卓越的軟件,為數(shù)十億設(shè)備提供豐富的體驗(yàn)。歡迎開發(fā)者在 Arm 不斷壯大的全球開發(fā)者社區(qū)中,下載內(nèi)容、交流學(xué)習(xí)和討論。
-
ARM
+關(guān)注
關(guān)注
135文章
9580瀏覽量
393249 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7827瀏覽量
93401 -
AI
+關(guān)注
關(guān)注
91文章
40715瀏覽量
302357 -
Neoverse
+關(guān)注
關(guān)注
0文章
17瀏覽量
4998
原文標(biāo)題:基于 Arm Neoverse 的 Google Axion 以更高性能加速 AI 工作負(fù)載推理
文章出處:【微信號(hào):Arm社區(qū),微信公眾號(hào):Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
使用NORDIC AI的好處
Arm Neoverse平臺(tái)賦能新一代Google Axion實(shí)例
瑞芯微SOC智能視覺AI處理器
d-Matrix與Andes晶心科技合作打造下一代AI推理加速器
瑞薩電子RZ/V系列微處理器助力邊緣AI開發(fā)

華為亮相2025金融AI推理應(yīng)用落地與發(fā)展論壇
今日看點(diǎn)丨華為發(fā)布AI推理創(chuàng)新技術(shù)UCM;比亞迪汽車出口暴增130%
Arm KleidiAI與XNNPack集成實(shí)現(xiàn)AI性能提升

研華科技推出緊湊型邊緣AI推理系統(tǒng)AIR-120
信而泰×DeepSeek:AI推理引擎驅(qū)動(dòng)網(wǎng)絡(luò)智能診斷邁向 “自愈”時(shí)代
Arm Kleidi助力輕松加速AI工作負(fù)載
如何在基于Arm Neoverse平臺(tái)的Google Axion處理器上構(gòu)建RAG應(yīng)用

解讀基于Arm Neoverse V2平臺(tái)的Google Axion處理器
光子 AI 處理器的核心原理及突破性進(jìn)展
谷歌第七代TPU Ironwood深度解讀:AI推理時(shí)代的硬件革命




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論