 Arm KleidiAI與XNNPack集成實現AI性能提升
Arm KleidiAI與XNNPack集成實現AI性能提升

作者:Arm 工程部首席軟件工程師 Gian Marco Iodice
自 Arm KleidiAI 首次集成到 XNNPack 已過去整整一年。KleidiAI 是一款高度優化的軟件庫,旨在加速 Arm CPU 上的人工智能 (AI) 推理。在過去一年中,從推出 INT4 矩陣乘法 (matmul) 優化以增強 Google Gemma 2 模型性能開始,到后續完成多項底層技術增強,Arm 在 XNNPack 上實現了顯著的性能提升。
而更值得注意的是,開發者對此無需做任何改動。所有這些提升均實現了完全透明化,既不用修改代碼,也無需額外的依賴項。只需像往常一樣基于 XNNPack 構建并運行應用,就能自動享受到 Arm 通過 KleidiAI 引入的最新底層優化。
本文就將為你詳細介紹最新的增強功能。
XNNPack 中的最新 KleidiAI 優化
面向 SDOT 和 i8mm 的 F32 x INT8 矩陣乘法
在先前 INT4 優化基礎上,此次優化聚焦于通過動態量化加速 INT8 矩陣乘法,拓寬性能提升的覆蓋范圍,以支持各類 AI 模型。從卷積神經網絡到前沿的生成式 AI 模型(例如 2025 年 5 月發布的 Stable Audio Open Small),這項優化帶來了切實可見的性能提升。例如,該優化使擴散模塊 (diffusion module) 的性能提升了 30% 以上。
與此前的 INT4 增強功能一樣,INT8 優化借助 SDOT 指令和 i8mm 指令,在各類 CPU 上提升了動態量化性能。
面向 F32、F16 和 INT8 矩陣乘法的 SME2 優化
近期最令人振奮的進展之一,是 Armv9 架構上對可伸縮矩陣擴展 (SME2)的支持。這為 F32 (Float32)、F16 (Float16) 和 INT8 矩陣乘法帶來了顯著的性能躍升,為新的高性能應用鋪平道路。因此,無論是對于當前還是未來的 AI 工作負載,都能從一開始實現無縫加速,且無需任何額外投入。
什么是 SME2?
SME2 是 Armv9-A CPU 架構中引入的一項全新 Arm 技術。SME2 基于可伸縮向量擴展 (SVE2) 技術構建,并通過可惠及 AI、計算機視覺、線性代數等多個領域的特性拓展了其應用范圍。
SME2 的一項突出特性是矩陣外積累加 (Matrix Outer Product Accumulate, MOPA) 指令,該指令能夠實現高效的外積運算。如下圖所示,外積與點積的區別在于,點積的運算結果是一個標量,而外積則由兩個輸入向量生成一個矩陣。
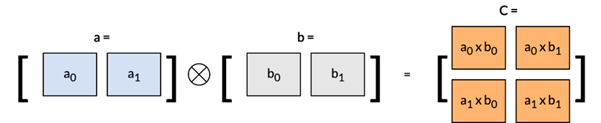
通過以下矩陣乘法示例來直觀理解這一區別:
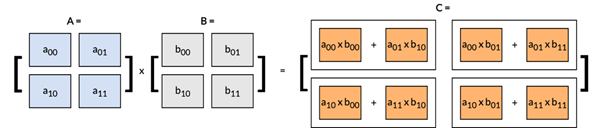
該矩陣乘法可分解為一系列外積運算,如下圖所示:
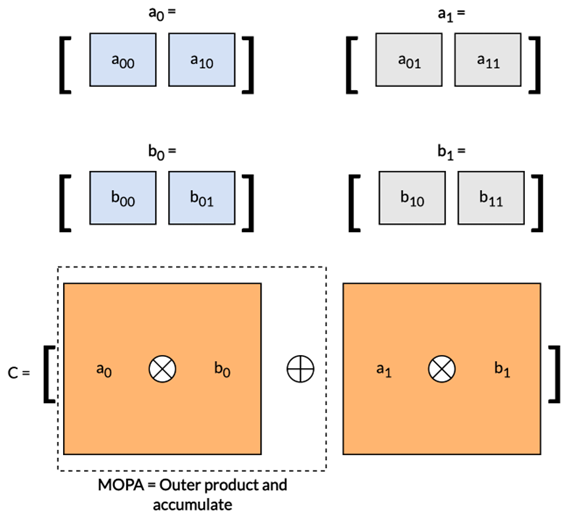
明確這一概念后,再來深入探討構成優化的矩陣乘法例程核心的 SME2 匯編指令:
FMOPA za0.s, p0/m, p1/m, z1.s, z3.s
各操作數的含義如下:
FMOPA:浮點矩陣外積累加指令。
ZA0.s:用于存儲和累積外積結果的 ZA 寄存器塊。
p0/m 和 p1/m:用于定義有效計算通道(掩碼操作)的 Predicate 寄存器。
z1.s 和 z3.s:參與外積運算的輸入向量。
該指令支持多種數據類型,涵蓋浮點格式(如 F32 和 F16)及整數類型(如 INT8)。得益于 SVE 技術的應用,它具備向量長度無關性,這意味著其能隨硬件向量尺寸自動適配擴展,無需修改任何代碼。
為展現 SME2 的性能潛力,不妨看看它在 Google Gemma 3 模型中通過 INT8 外積指令加速 INT4 矩陣乘法的效果。相比同一設備未啟用 SME2 的情況,當 Gemma 3 模型部署在支持 SME2 的硬件上時,聊天機器人用例的 AI 響應速度最高可提升六倍。
此外,借助單 CPU 核心上的 SME2 加速,Gemma 3 能在一秒內開始對一篇四段文字的文本內容生成摘要,充分印證了該架構在響應速度與運行效率上的提升。
優化所帶來的實際意義
通過這些更新,XNNPack 成為首個支持 SME2 的 AI 推理庫,能夠在 Arm CPU 上進一步實現前所未有的性能表現。
無論是專注于生成式 AI 還是基于 CNN 神經網絡的開發者,都能在無需修改任何代碼的情況下,在其應用上實現顯著的性能提升。
展望 Arm KleidiAI 的未來
過去一年的實踐證明,透明化加速不僅切實可行,更已具備實際應用價值。隨著 KleidiAI 不斷突破 XNNPack 上的性能表現,開發者可專注于打造出色的 AI 體驗,而運行時性能也將持續提升。
-
ARM
+關注
關注
135文章
9573瀏覽量
392889 -
cpu
+關注
關注
68文章
11305瀏覽量
225510 -
AI
+關注
關注
91文章
40431瀏覽量
302038
原文標題:集成一周年,Arm KleidiAI 與 XNNPack 實現無縫且透明性 AI 性能
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

Arm KleidiAI助力提升PyTorch上LLM推理性能
Arm+AWS實現AI定義汽車 基于Arm KleidiAI優化并由AWS提供支持
《電子發燒友電子設計周報》聚焦硬科技領域核心價值 第23期:2025.08.04--2025.08.08
Firefly支持AI引擎Tengine,性能提升,輕松搭建AI計算框架
重大性能更新:Wasm 后端將利用 SIMD指令和 XNNPACK多線程
ARM發布旗艦手機芯片:性能提升、AI性能增強、節能減耗
Arm KleidiAI軟件庫的功能解析
Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機器學習框架
利用Arm Kleidi技術實現PyTorch優化

Arm 與微軟合作,為基于 Arm 架構的 PC 和移動設備應用提供超強 AI 體驗

Arm率先適配騰訊混元開源模型,助力端側AI創新開發
Arm神經技術是業界首創在 Arm GPU 上增添專用神經加速器的技術,移動設備上實現PC級別的AI圖形性能
全新Arm Lumex CSS平臺實現兩位數性能提升




 工商網監
工商網監
評論