") DeepSeek-R1本地部署指南,開啟你的AI探索之旅
DeepSeek-R1本地部署指南,開啟你的AI探索之旅

春節(jié)期間突然被DeepSeek刷屏了,這熱度是真大,到處都是新聞和本地部署的教程,等熱度過了過,簡單記錄下自己本地部署及相關(guān)的內(nèi)容,就當(dāng)電子寵物,沒事喂一喂:D,不過有能力的還是閱讀論文和部署完整版的進(jìn)一步使用。
論文鏈接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
1|0一、什么是 DeepSeek R1
2025.01.20 DeepSeek-R1 發(fā)布,DeepSeek R1 是 DeepSeek AI 開發(fā)的第一代推理模型,擅長復(fù)雜的推理任務(wù),官方對標(biāo)OpenAI o1正式版。適用于多種復(fù)雜任務(wù),如數(shù)學(xué)推理、代碼生成和邏輯推理等。
DeepSeek-R1 發(fā)布的新聞:https://api-docs.deepseek.com/zh-cn/news/news250120

根據(jù)官方信息DeepSeek R1 可以看到提供多個版本,包括完整版(671B 參數(shù))和蒸餾版(1.5B 到 70B 參數(shù))。完整版性能強(qiáng)大,但需要極高的硬件配置;蒸餾版則更適合普通用戶,硬件要求較低
DeepSeek-R1官方地址:https://github.com/deepseek-ai/DeepSeek-R1
完整版(671B):需要至少 350GB 顯存/內(nèi)存,適合專業(yè)服務(wù)器部署
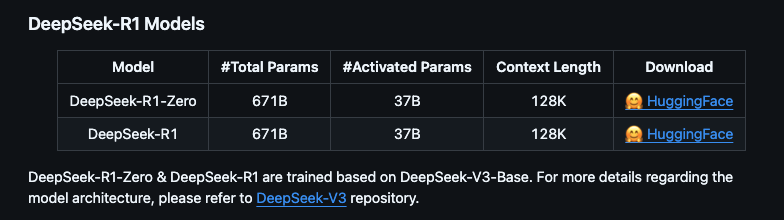
蒸餾版:基于開源模型(如 QWEN 和 LLAMA)微調(diào),參數(shù)量從 1.5B 到 70B 不等,適合本地硬件部署。
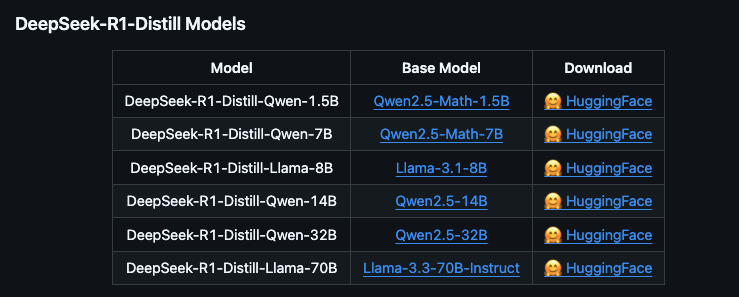
蒸餾版與完整版的區(qū)別
| 特性 | 蒸餾版 | 完整版 |
|---|---|---|
| 參數(shù)量 | 參數(shù)量較少(如 1.5B、7B),性能接近完整版但略有下降。 | 參數(shù)量較大(如 32B、70B),性能最強(qiáng)。 |
| 硬件需求 | 顯存和內(nèi)存需求較低,適合低配硬件。 | 顯存和內(nèi)存需求較高,需高端硬件支持。 |
| 適用場景 | 適合輕量級任務(wù)和資源有限的設(shè)備。 | 適合高精度任務(wù)和專業(yè)場景。 |
這里我們詳細(xì)看下蒸餾版模型的特點(diǎn)
| 模型版本 | 參數(shù)量 | 特點(diǎn) |
|---|---|---|
| deepseek-r1:1.5b | 1.5B | 輕量級模型,適合低配硬件,性能有限但運(yùn)行速度快 |
| deepseek-r1:7b | 7B | 平衡型模型,適合大多數(shù)任務(wù),性能較好且硬件需求適中。 |
| deepseek-r1:8b | 8B | 略高于 7B 模型,性能稍強(qiáng),適合需要更高精度的場景。 |
| deepseek-r1:14b | 14B | 高性能模型,適合復(fù)雜任務(wù)(如數(shù)學(xué)推理、代碼生成),硬件需求較高。 |
| deepseek-r1:32b | 32B | 專業(yè)級模型,性能強(qiáng)大,適合研究和高精度任務(wù),需高端硬件支持。 |
| deepseek-r1:70b | 70B | 頂級模型,性能最強(qiáng),適合大規(guī)模計(jì)算和高復(fù)雜度任務(wù),需專業(yè)級硬件支持。 |
進(jìn)一步的模型細(xì)分還分為量化版
| 模型版本 | 參數(shù)量 | 特點(diǎn) |
|---|---|---|
| deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 輕量級模型,適合低配硬件,性能有限但運(yùn)行速度快 |
| deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 平衡型模型,適合大多數(shù)任務(wù),性能較好且硬件需求適中。 |
| deepseek-r1:8b-llama-distill-q4_K_M | 8B | 略高于 7B 模型,性能稍強(qiáng),適合需要更高精度的場景。 |
| deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 高性能模型,適合復(fù)雜任務(wù)(如數(shù)學(xué)推理、代碼生成),硬件需求較高。 |
| deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 專業(yè)級模型,性能強(qiáng)大,適合研究和高精度任務(wù),需高端硬件支持。 |
| deepseek-r1:70b-llama-distill-q4_K_M | 70B | 頂級模型,性能最強(qiáng),適合大規(guī)模計(jì)算和高復(fù)雜度任務(wù),需專業(yè)級硬件支持。 |
蒸餾版與量化版
| 模型類型 | 特點(diǎn) |
|---|---|
| 蒸餾版 | 基于大模型(如 QWEN 或 LLAMA)微調(diào),參數(shù)量減少但性能接近原版,適合低配硬件。 |
| 量化版 | 通過降低模型精度(如 4-bit 量化)減少顯存占用,適合資源有限的設(shè)備。 |
例如:
deepseek-r1:7b-qwen-distill-q4_K_M:7B 模型的蒸餾+量化版本,顯存需求從 5GB 降至 3GB。
deepseek-r1:32b-qwen-distill-q4_K_M:32B 模型的蒸餾+量化版本,顯存需求從 22GB 降至 16GB
我們正常本地部署使用蒸餾版就可以
2|0二、型號和硬件要求
2|12.1硬件配置說明
Windows 配置:
最低要求:NVIDIA GTX 1650 4GB 或 AMD RX 5500 4GB,16GB 內(nèi)存,50GB 存儲空間
推薦配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 內(nèi)存,100GB NVMe SSD
高性能配置:NVIDIA RTX 3090 24GB 或 AMD RX 7900 XTX 24GB,64GB 內(nèi)存,200GB NVMe SSD
Linux 配置:
最低要求:NVIDIA GTX 1660 6GB 或 AMD RX 5500 4GB,16GB 內(nèi)存,50GB 存儲空間
推薦配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 內(nèi)存,100GB NVMe SSD
高性能配置:NVIDIA A100 40GB 或 AMD MI250X 128GB,128GB 內(nèi)存,200GB NVMe SSD
Mac 配置:
最低要求:M2 MacBook Air(8GB 內(nèi)存)
推薦配置:M2/M3 MacBook Pro(16GB 內(nèi)存)
高性能配置:M2 Max/Ultra Mac Studio(64GB 內(nèi)存)
可根據(jù)下表配置選擇使用自己的模型
| 模型名稱 | 參數(shù)量 | 大小 | VRAM (Approx.) | 推薦 Mac 配置 | 推薦 Windows/Linux 配置 |
|---|---|---|---|---|---|
| deepseek-r1:1.5b | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
| deepseek-r1:7b | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
| deepseek-r1:8b | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
| deepseek-r1:14b | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
| deepseek-r1:32b | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
| deepseek-r1:70b | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
| deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
| deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
| deepseek-r1:8b-llama-distill-q4_K_M | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
| deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
| deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
| deepseek-r1:70b-llama-distill-q4_K_M | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
3|0三、本地安裝 DeepSeek R1
我這里的演示的本地環(huán)境:
機(jī)器:M2/M3/M4 MacBook Pro (16GB RAM+)
模型:deepseek-r1:8b
簡單說下在本地運(yùn)行的好處
隱私:您的數(shù)據(jù)保存在本地的設(shè)備上,不會通過外部服務(wù)器
離線使用:下載模型后無需互聯(lián)網(wǎng)連接
經(jīng)濟(jì)高效:無 API 成本或使用限制
低延遲:直接訪問,無網(wǎng)絡(luò)延遲
自定義:完全控制模型參數(shù)和設(shè)置
之后如果有Windows/Linux的場景需要在后續(xù)進(jìn)行更新。
3|13.1部署工具
部署可以使用Ollama、LM Studio、Docker等進(jìn)行部署
Ollama:
本地大模型管理框架,Ollama 讓用戶能夠在本地環(huán)境中高效地部署和使用語言模型,而無需依賴云服務(wù)
支持 Windows、Linux 和 Mac 系統(tǒng),提供命令行和 Docker 部署方式
使用命令ollama run deepseek-r1:7b下載并運(yùn)行模型
LM Studio:
LM Studio 是一個桌面應(yīng)用程序,它提供了一個用戶友好的界面,允許用戶輕松下載、加載和運(yùn)行各種語言模型(如 LLaMA、GPT 等)
支持 Windows 和 Mac,提供可視化界面,適合新手用戶
Docker:
支持 Linux 和 Windows,適合高級用戶。
使用命令docker run -d --gpus=all -p 11434:11434 --name ollama ollama/ollama啟動容器。
由于需要本地化部署語言模型的場景,對數(shù)據(jù)隱私和自定義或擴(kuò)展語言模型功能有較高要求,我們這里使用Ollama來進(jìn)行本地部署運(yùn)行
如果只有集顯也想試試玩,可以試試下載LM Studio軟件,更適應(yīng)新手,如果有需要后續(xù)更新
3|23.2 安裝 ollama
官方地址:https://ollama.com/
選擇自己的系統(tǒng)版本進(jìn)行下載
安裝完成
控制臺驗(yàn)證是否成功安裝
我們再回到ollama官網(wǎng)選擇模型,選擇需要的模型復(fù)制命令進(jìn)行安裝
可以看到安裝完成
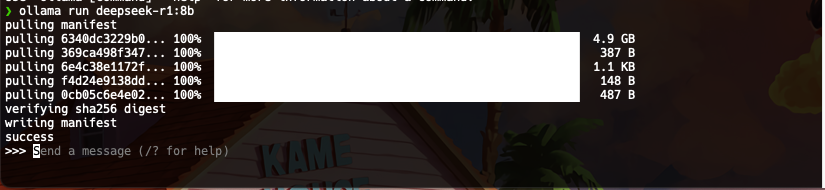
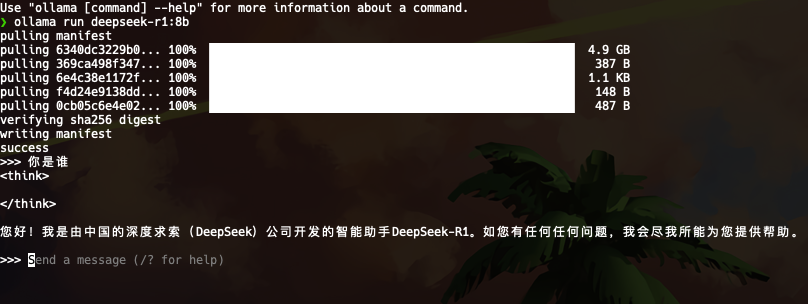

簡單思考下,使用過程中的硬件使用率,GPU飽和,其他使用率不是很高,速度也很快

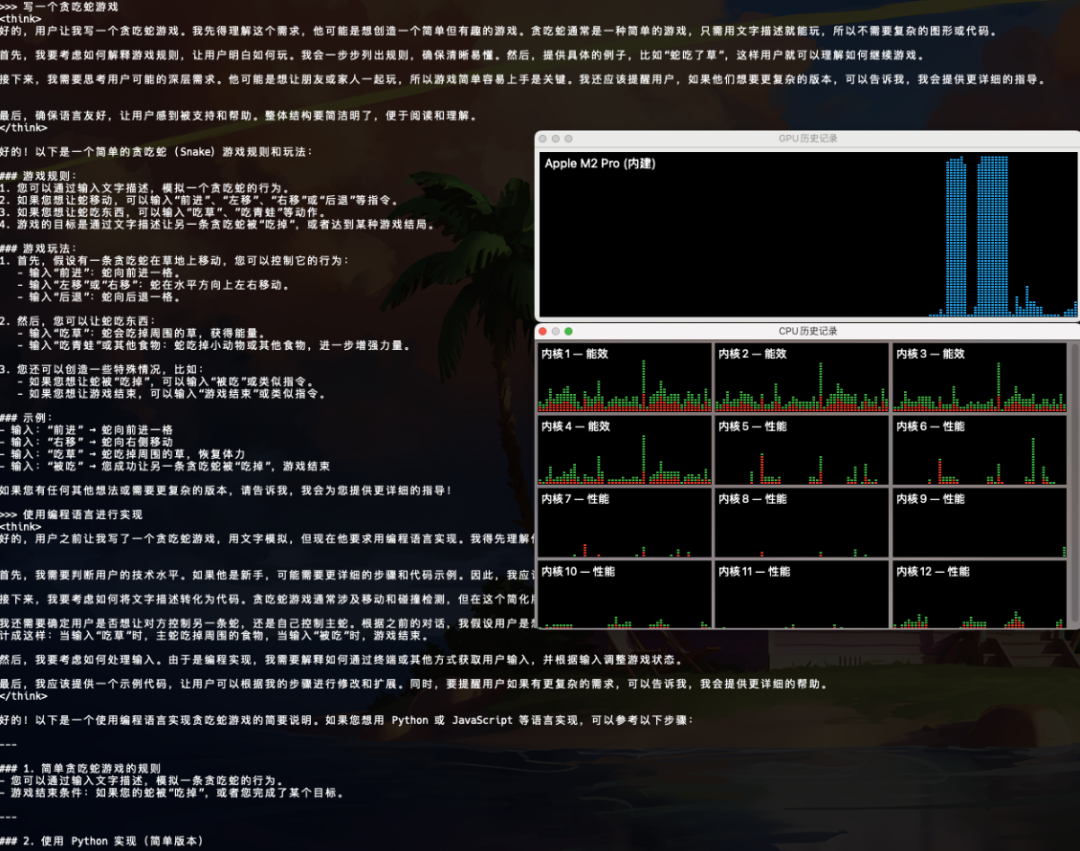
4|0四、可視化界面
這里介紹下Open-WebUI和Dify
Open-WebUI是一款自托管 LLM Web 界面,提供 Web UI 與大模型交互,僅提供 Web UI,不提供 API,適用于個人使用 LLM以及本地運(yùn)行大模型
Dify是LLM 應(yīng)用開發(fā)平臺,不完全是可視化界面,可以快速構(gòu)建 LLM 應(yīng)用(RAG、AI 代理等),提供 API,可用于應(yīng)用集成,支持 MongoDB、PostgreSQL 存儲 LLM 相關(guān)數(shù)據(jù), AI SaaS、應(yīng)用開發(fā),需要構(gòu)建智能客服、RAG 應(yīng)用等
4|14.1 Open-WebUI
Open-WebUI官方地址:https://github.com/open-webui/open-webui
Open-WebUI官方文檔地址:https://docs.openwebui.com/getting-started/
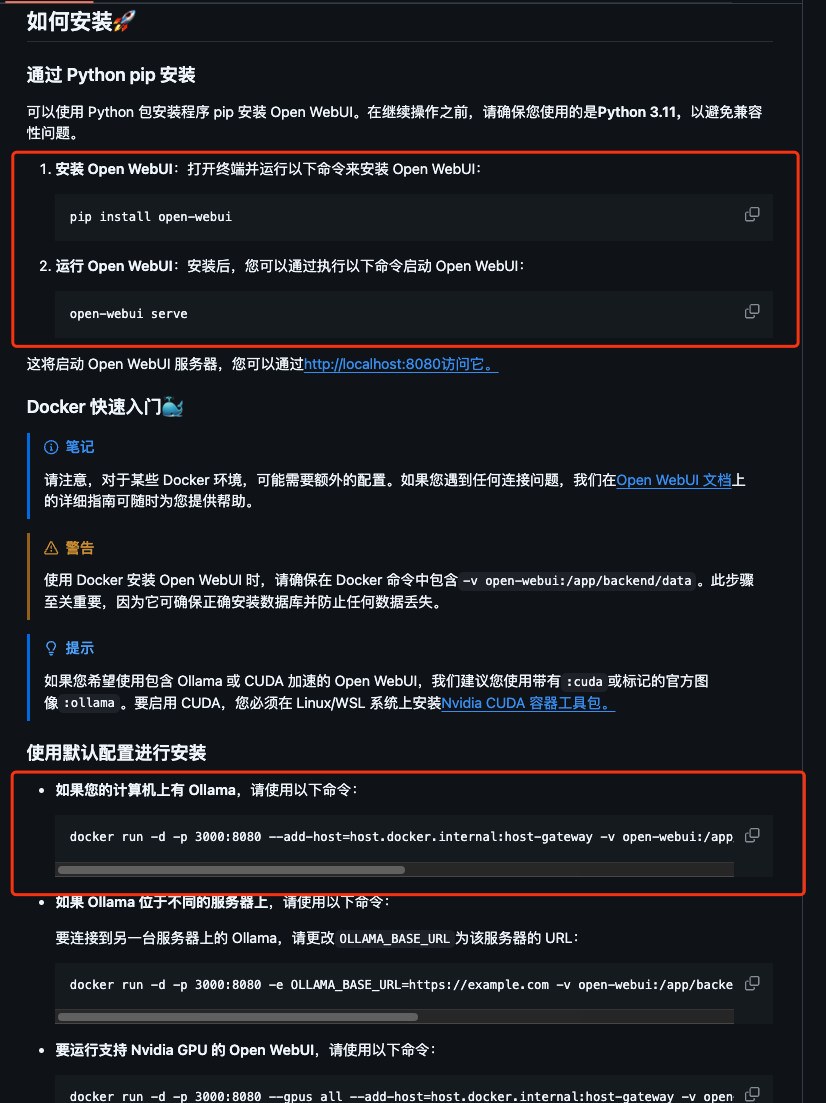
根據(jù)官網(wǎng)文檔可使用pip和docker進(jìn)行安裝,我這里避免影響本地環(huán)境使用docker進(jìn)行安裝
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
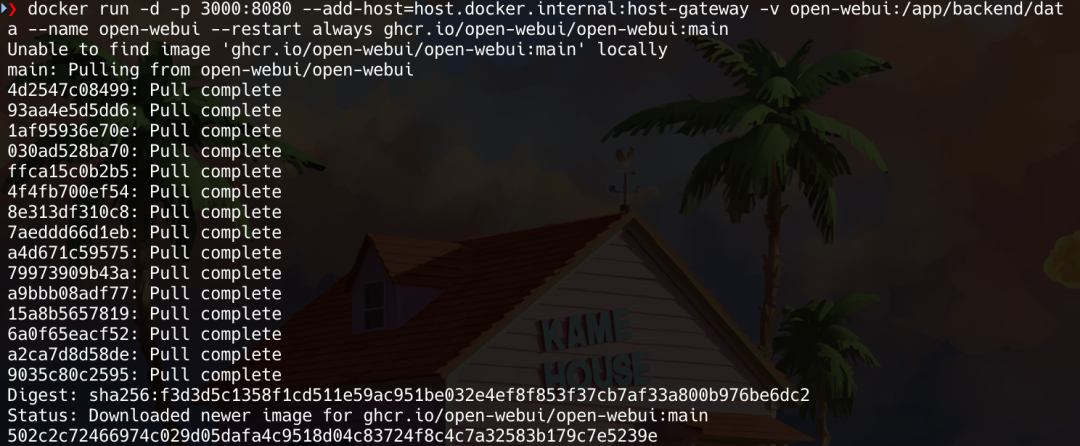
訪問http://localhost:3000/
創(chuàng)建賬號

訪問成功
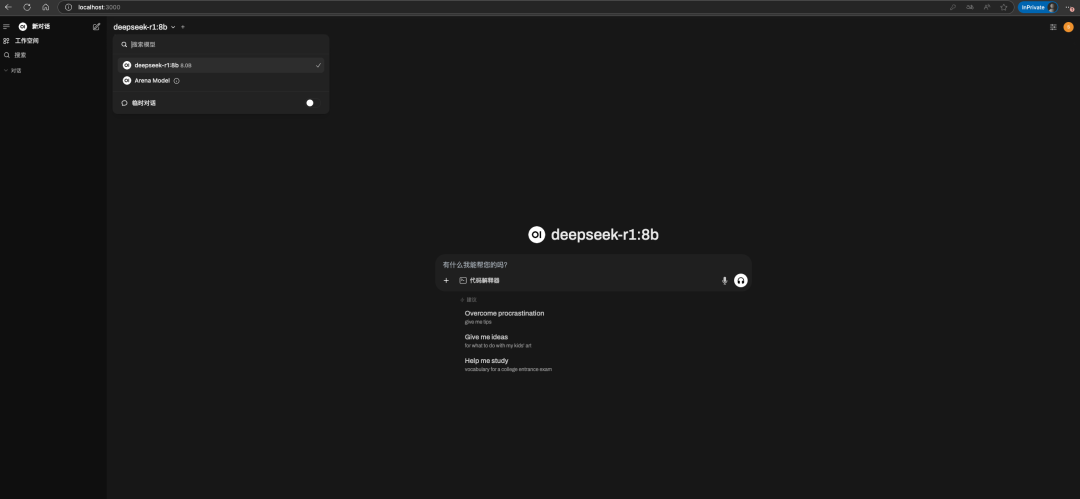
簡單的問下問題,實(shí)際運(yùn)行8b模型給出的代碼是有問題的,根據(jù)報(bào)錯的問題再次思考時間會變長

4|24.2 Dify
Dify官方地址:https://github.com/langgenius/dify
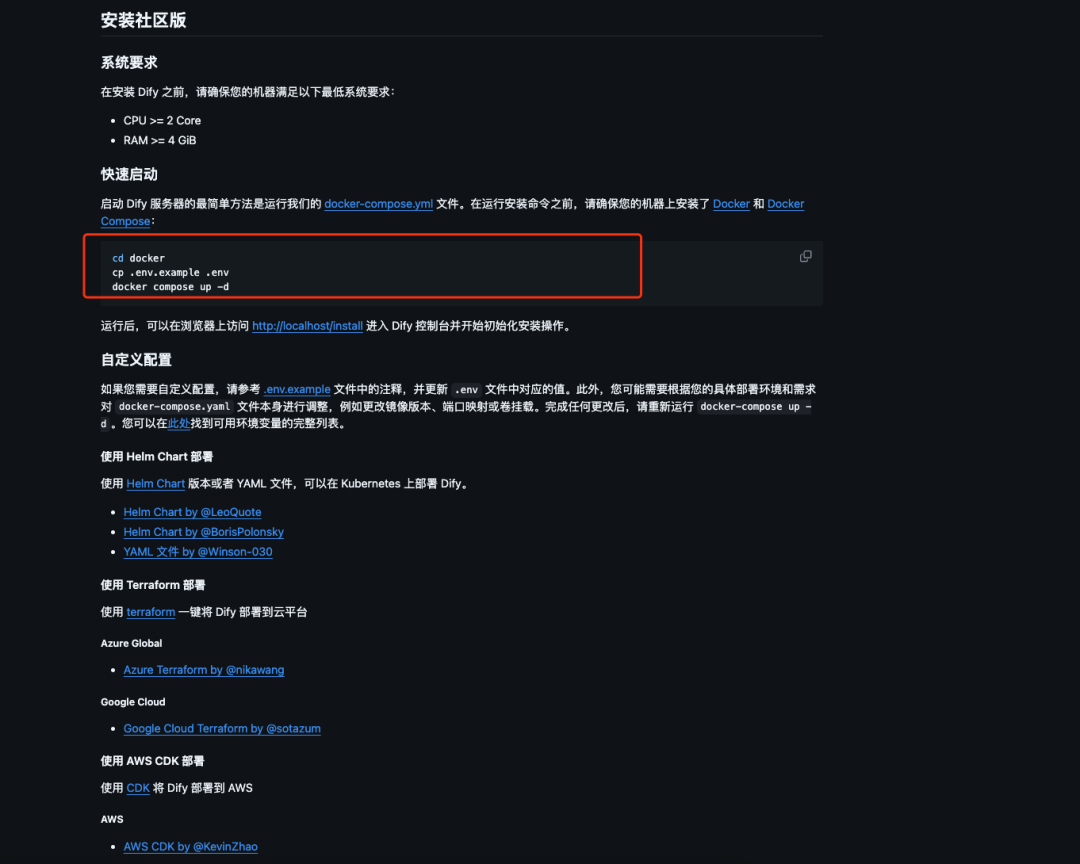
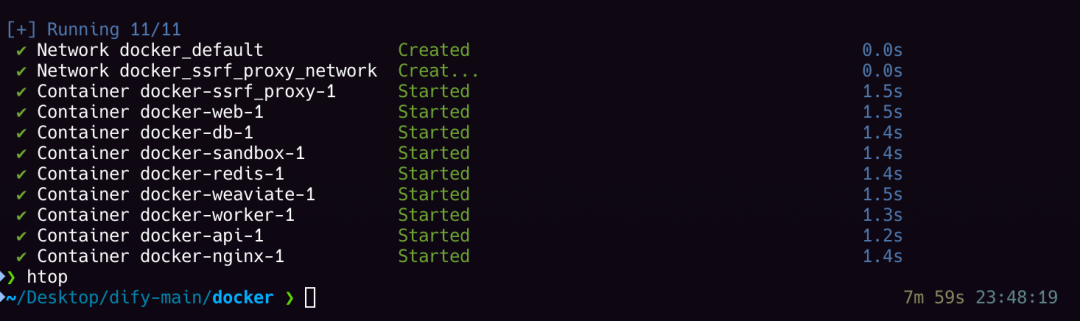
啟動成功,localhost訪問
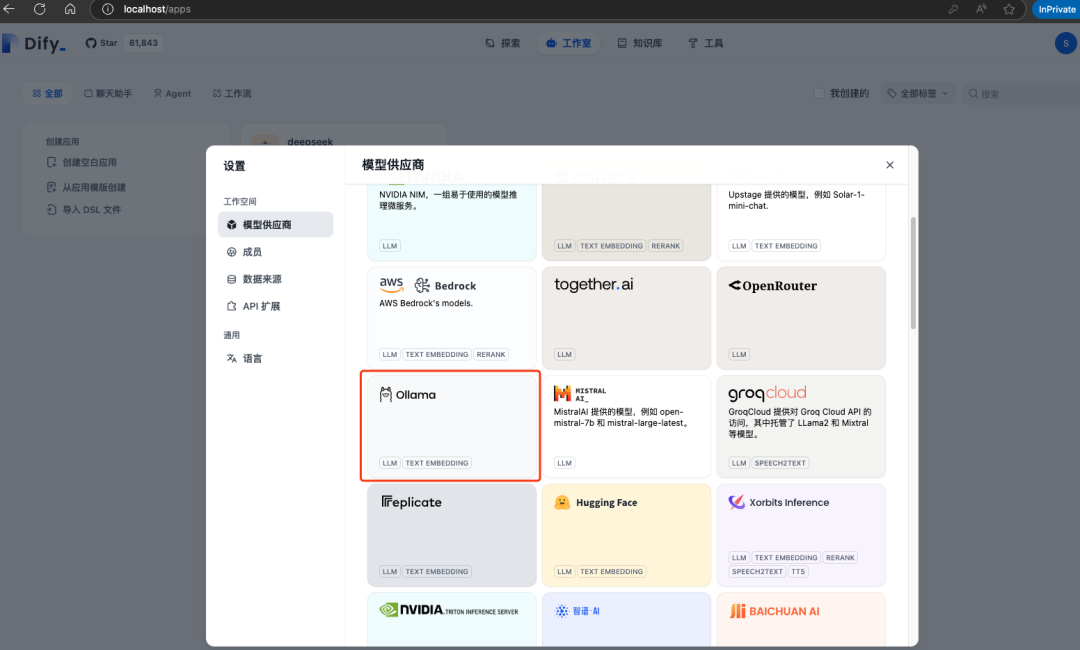
登錄成功選擇Ollama進(jìn)行添加模型模型供應(yīng)商,如果Ollama和Dify是同機(jī)部署,并且Dify是通過Docker部署,那么填http://host.docker.internal:11434即可
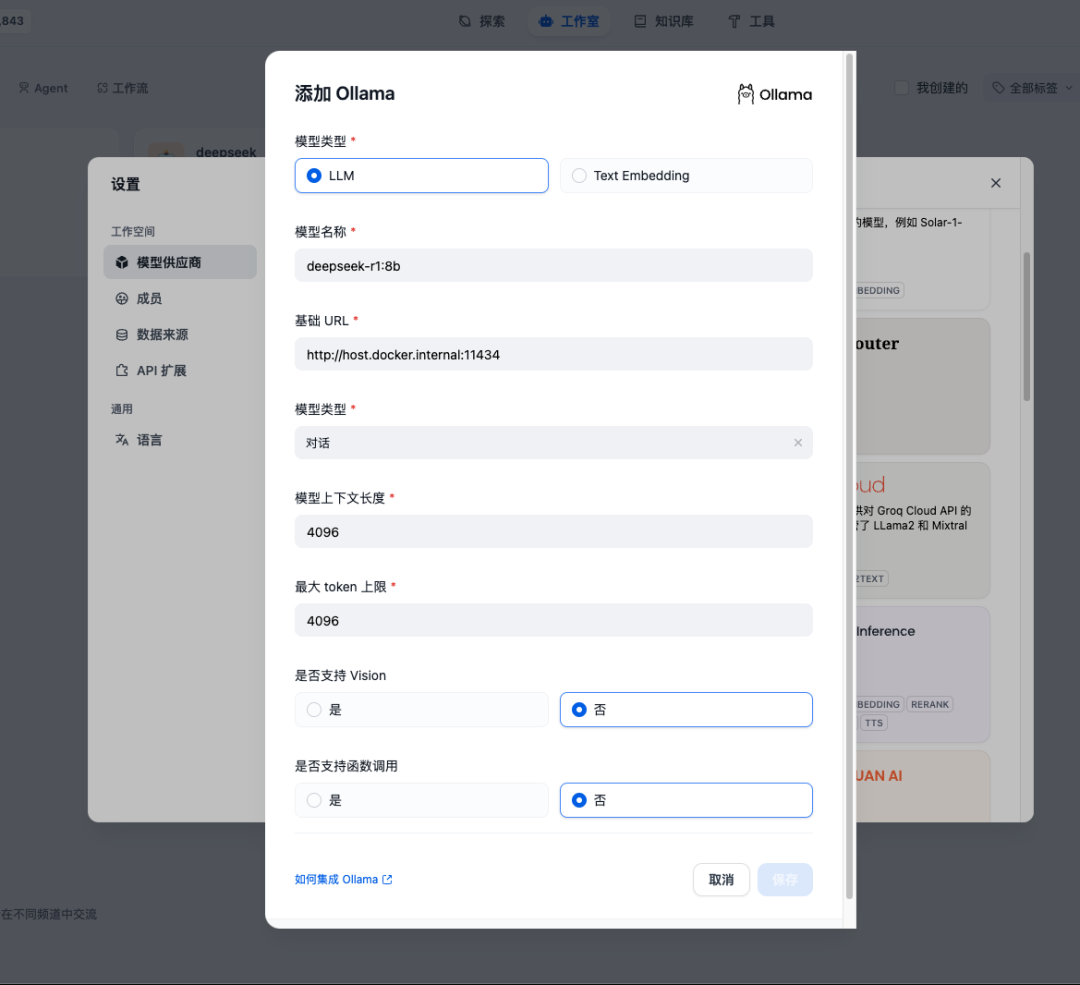
接下來創(chuàng)建應(yīng)用使用之前安裝好的DeepSeek R1模型
可以看到右上角已經(jīng)使用deepseek-r1:8b的模型了
簡單的問個問題可以看到已經(jīng)正常使用
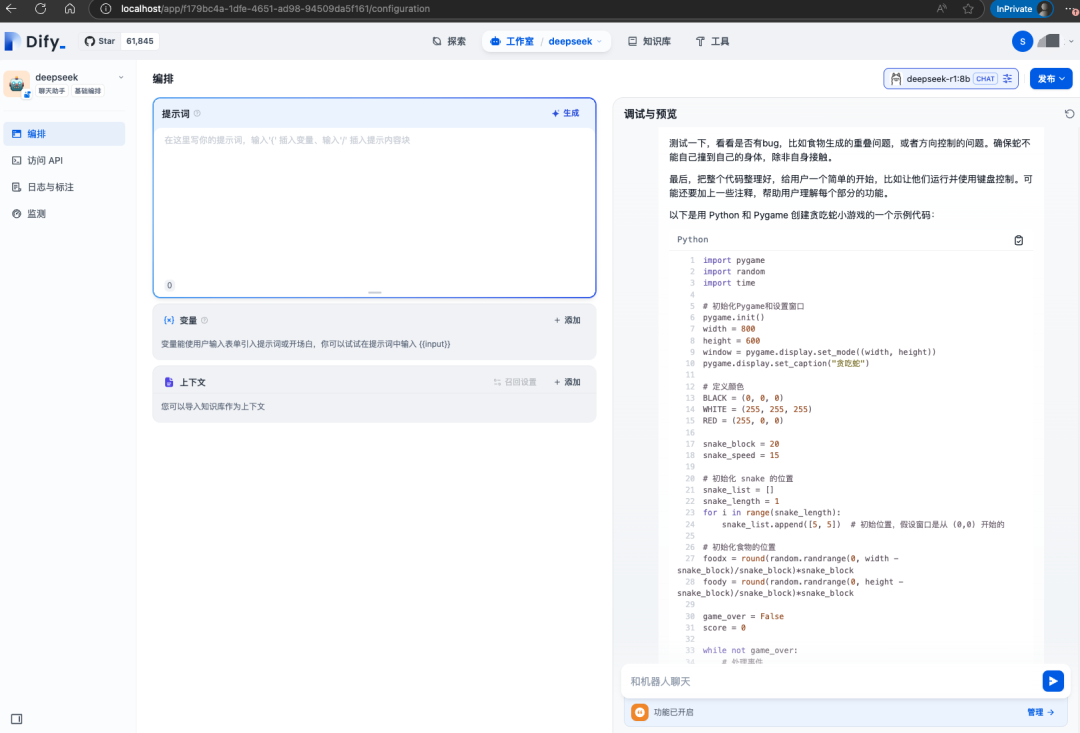
Dify不只是對話,其他功能可以自行探索下,后續(xù)有使用我也會更新
以上就是簡單本地部署Deepseek- R1的過程
5|0五、關(guān)于Deepseek的使用
最后在本地部署蒸餾版的體驗(yàn)中對于回答的代碼內(nèi)容有些不盡人意,不過文字以及思考過程的能力還是可以的
如果想在后續(xù)體驗(yàn)完整版的Deepseek,還沒有高性能的硬件,那么直接使用deepseek官方的服務(wù)吧,api是真的便宜
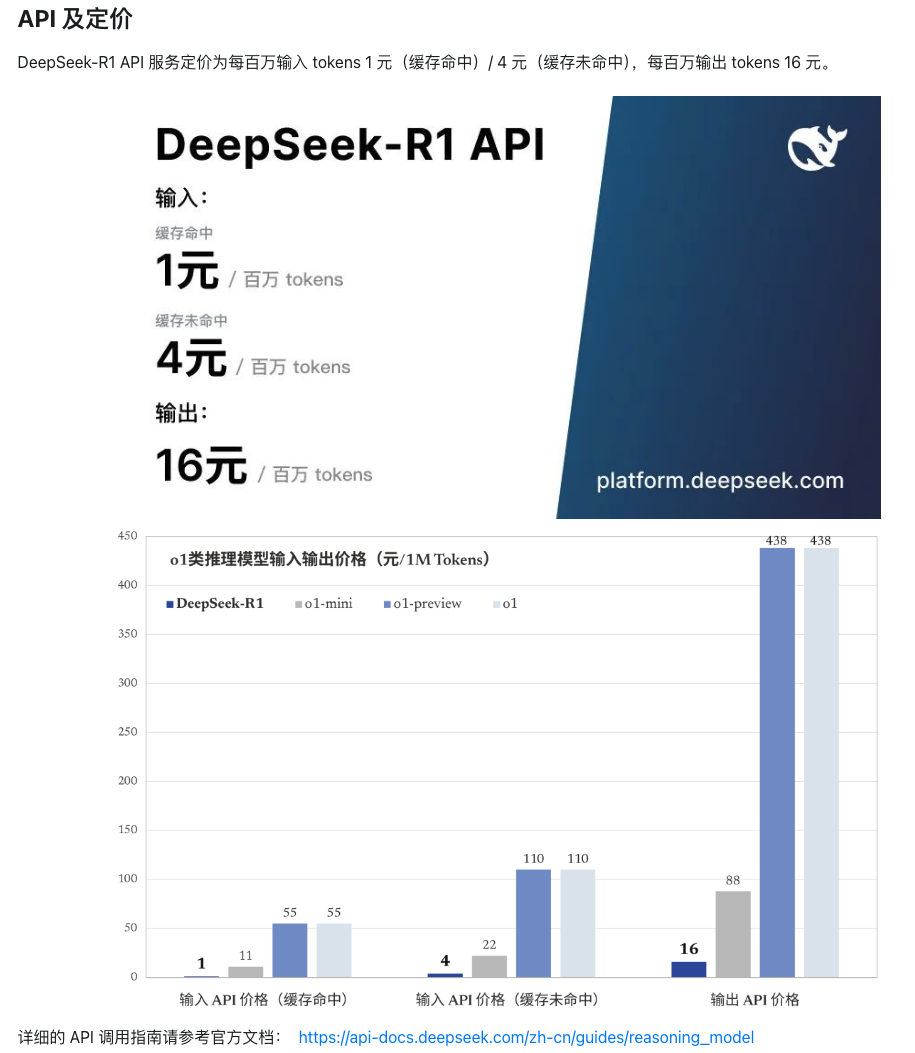
Deepseek剛出現(xiàn)的時候就有在體驗(yàn)過包括使用API,Deepseek火了之后也總出現(xiàn)了服務(wù)器繁忙請稍后再試,API的地址也無法使用,不過之前使用的API卻還可以正常使用,希望盡快修復(fù)吧

在vs code中通過Continue插件使用Deepseek的API,也可以在Open-WebUI接入API
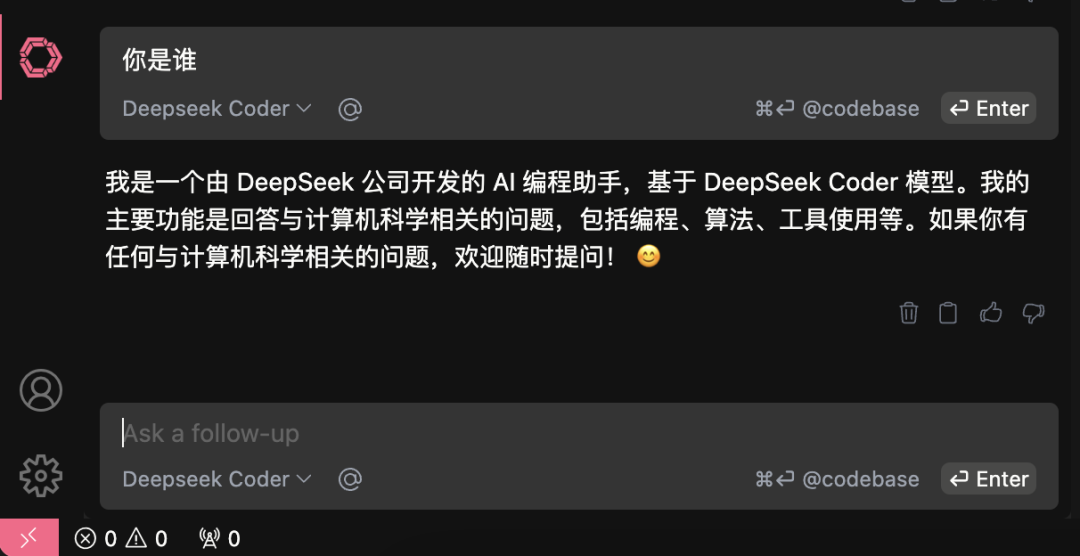
在使用過程中感覺到有些上下文聯(lián)系不是很緊密,不過思考過程確實(shí)很驚艷,在某些方面o1可能還是好些
后來發(fā)現(xiàn)chatgpt、kimi這些也推出了推理功能:D,
對于在日常使用中Deepseek和GPT4O的對比各有千秋,可根據(jù)使用場景切換使用,但不得不說Deepseek確實(shí)很棒。
鏈接:https://www.cnblogs.com/shook/p/18700561
-
AI
+關(guān)注
關(guān)注
91文章
40696瀏覽量
302335 -
DeepSeek
+關(guān)注
關(guān)注
2文章
837瀏覽量
3370
原文標(biāo)題:一鍵部署,輕松上手!DeepSeek-R1本地部署指南,開啟你的AI探索之旅!
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
百度騰訊搶灘布局!DeepSeek-R1升級和開源背后,國產(chǎn)AI的逆襲之路
廣和通成功部署DeepSeek-R1-0528-Qwen3-8B模型
DeepSeek R1 MTP在TensorRT-LLM中的實(shí)現(xiàn)與優(yōu)化

速看!EASY-EAI教你離線部署Deepseek R1大模型

【「DeepSeek 核心技術(shù)揭秘」閱讀體驗(yàn)】書籍介紹+第一章讀后心得
信而泰×DeepSeek:AI推理引擎驅(qū)動網(wǎng)絡(luò)智能診斷邁向 “自愈”時代
Arm Neoverse N2平臺實(shí)現(xiàn)DeepSeek-R1滿血版部署

NVIDIA Blackwell GPU優(yōu)化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀(jì)錄

【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術(shù):DeepSeek 核心技術(shù)揭秘
ElfBoard技術(shù)實(shí)戰(zhàn)|ELF 2開發(fā)板本地部署DeepSeek大模型的完整指南

SAP實(shí)施專家解答:如何用DeepSeek-R1實(shí)現(xiàn)需求溝通效率倍增
誠邁信創(chuàng)電腦實(shí)現(xiàn)本地部署DeepSeek,開啟智慧辦公新體驗(yàn)

【幸狐Omni3576邊緣計(jì)算套件試用體驗(yàn)】CPU部署DeekSeek-R1模型(1B和7B)
DeepSeek R1模型本地部署與產(chǎn)品接入實(shí)操



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論