") 首個科學計算基座大模型BBT-Neutron開源,助力突破大科學裝置數(shù)據(jù)分析瓶頸
首個科學計算基座大模型BBT-Neutron開源,助力突破大科學裝置數(shù)據(jù)分析瓶頸

大語言模型能否解決傳統(tǒng)大語言模型在大規(guī)模數(shù)值數(shù)據(jù)分析中的局限性問題,助力科學界大科學裝置設(shè)計、高能物理領(lǐng)域科學計算?
高能物理是探索宇宙基本組成與規(guī)律的前沿科學領(lǐng)域,研究粒子在極高能量下的相互作用,是揭示宇宙起源、暗物質(zhì)與暗能量等未解之謎的重要手段。高能物理實驗(如粒子對撞實驗、暗物質(zhì)與暗能量實驗等)產(chǎn)生的數(shù)據(jù)量極為龐大且復雜,傳統(tǒng)的數(shù)據(jù)分析方法在處理海量數(shù)據(jù)和復雜物理結(jié)構(gòu)時,面臨計算瓶頸。
2024年12月3日,arxiv上更新了一篇將多模態(tài)基座大模型運用于粒子物理科研場景的最新論文《Scaling Particle Collision Data Analysis》,從粒子對撞實驗出發(fā),探索了大語言模型在大科學裝置數(shù)據(jù)分析與科學計算領(lǐng)域的全新應(yīng)用場景。作者團隊來自超越對稱(上海)技術(shù)有限公司,與中國高能物理研究所(高能所)大對撞機CEPC團隊、北京大學等機構(gòu)的研究人員合作,將其最新研發(fā)的科學基座大模型BBT-Neutron應(yīng)用于粒子對撞實驗。模型應(yīng)用了全新的二進制分詞方法(Binary Tokenization),可實現(xiàn)對多模態(tài)數(shù)據(jù)(包括大規(guī)模數(shù)值實驗數(shù)據(jù)、文本和圖像數(shù)據(jù))的混合預訓練。
論文鏈接:https://arxiv.org/abs/2412.00129
代碼地址:https://github.com/supersymmetry-technologies/bbt-neutron
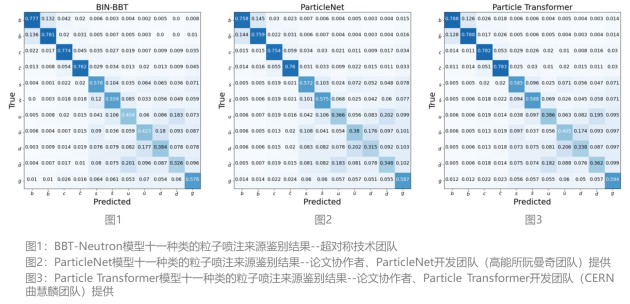
論文中對比了BBT-Neutron的通用架構(gòu)模型與最先進的專業(yè)JoI模型(如ParticleNet和Particle Transformer)在粒子物理領(lǐng)域的Jet Origin Identification(JoI)分類任務(wù)上的實驗結(jié)果。粒子分類的識別準確率(圖1-3)表明,研究表明該通用架構(gòu)的性能與專業(yè)模型持平,這也驗證了基于sequence-to-sequence建模的decoder-only架構(gòu)在學習物理規(guī)律方面的能力。
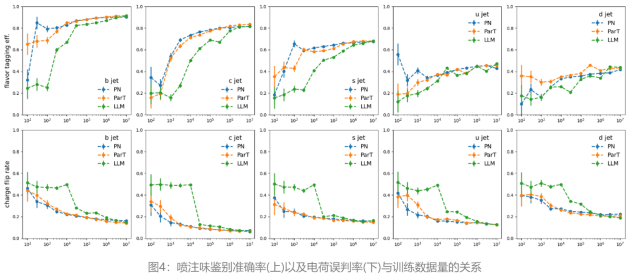
這些模型在數(shù)據(jù)集大小擴展時都顯示出性能提升,Jet Flavor Tagging Efficiency, Charge Flip Rate形成了S曲線。然而,BBT-Neutron和專業(yè)模型之間觀察到不同的擴展行為,S曲線上的關(guān)鍵數(shù)據(jù)閾值表明BBT-Neutron中出現(xiàn)了涌現(xiàn)現(xiàn)象(在專業(yè)架構(gòu)中未出現(xiàn)),不僅打破了傳統(tǒng)觀念認為該架構(gòu)不適用于連續(xù)性物理特征建模的局限,更驗證了通用模型在大規(guī)模科學計算任務(wù)中的可擴展性。
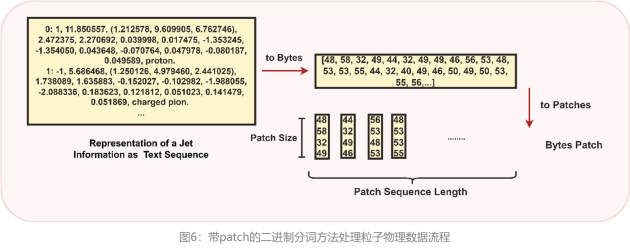
二進制分詞:統(tǒng)一多模態(tài)數(shù)據(jù)處理,突破數(shù)值數(shù)據(jù)分析瓶頸
近年來大語言模型在文本處理、常識問答等任務(wù)上取得了顯著進展,但在處理大規(guī)模數(shù)值數(shù)據(jù)方面依然面臨挑戰(zhàn)。傳統(tǒng)的BPE分詞方法在分詞數(shù)字時可能會引入歧義和不一致,特別是在高能物理、天文觀測等領(lǐng)域,分析復雜的實驗數(shù)據(jù)成為瓶頸。
為了讓大模型更加適配科學計算場景,該研究通過引入一種創(chuàng)新的二進制分詞方法(Binary Tokenization),即利用計算機存儲中使用的二進制表示數(shù)據(jù),實現(xiàn)了數(shù)值數(shù)據(jù)與文本、圖像等多模態(tài)數(shù)據(jù)的統(tǒng)一表示。以使其能夠在無需額外預處理的情況下,通過二進制分詞,實現(xiàn)對所有數(shù)據(jù)類型的統(tǒng)一處理,簡化預處理流程,確保輸入數(shù)據(jù)的一致性。研發(fā)團隊在論文中詳細展示了如何克服傳統(tǒng)BPE方法的局限性及其數(shù)據(jù)處理過程。
BPE方法的局限性
歧義和不一致性
BPE是一種基于頻率的token 化方法,它會根據(jù)上下文將數(shù)字分割成不同的子單元,這可能導致同一數(shù)字在不同上下文中有不同的分割方式。
例如,數(shù)字12345在一個上下文中可能被分割成‘12’、‘34’和‘5’,在另一個上下文中可能被分割成‘1’、‘23’和‘45’。這種分割方式丟失了原始數(shù)值的固有意義,因為數(shù)字的完整性和數(shù)值關(guān)系被破壞了。
token ID的不連續(xù)性
BPE會導致數(shù)值的token ID不連續(xù)。例如,數(shù)字‘7’和‘8’的token ID可能被分配為4779和5014。
這種不連續(xù)性使得管理和處理數(shù)值數(shù)據(jù)變得更加復雜,特別是在需要順序或模式化的token ID時,這種不連續(xù)性會影響模型處理和分析數(shù)值數(shù)據(jù)的能力。
單數(shù)字token化的問題
盡管單數(shù)字token 化方法簡單直接,但它也會導致多位數(shù)數(shù)字的token ID不連續(xù)。例如,數(shù)字15可能會被分解為獨立的token ‘1’和‘5’,每個token 都被映射到獨立的token ID。這種分割可能會破壞數(shù)值信息的連續(xù)性,使得模型更難捕捉多位數(shù)數(shù)字內(nèi)在的結(jié)構(gòu)和關(guān)系。
數(shù)值處理方式
對于文本數(shù)據(jù),使用UTF-8編碼將字符轉(zhuǎn)換為字節(jié)序列。
對于數(shù)值數(shù)據(jù),提供了雙重策略:一種是當保留數(shù)字的確切格式和任何可能重要的前導零時,數(shù)字被視為字符串,然后使用UTF-8編碼;另一種是在進行算術(shù)運算或處理重要數(shù)值時,數(shù)字被轉(zhuǎn)換成其數(shù)值形式(例如,整數(shù)),然后轉(zhuǎn)換成字節(jié)數(shù)組。 這種方法保證了模型能夠統(tǒng)一且高效地處理各種數(shù)據(jù)類型。
對于科學公式或符號: 復雜的表達式被解析并序列化成字節(jié)序列,捕捉公式的結(jié)構(gòu)和內(nèi)容。 例如,公式E = mc^2被編碼為字節(jié)數(shù)組[69, 61, 109, 99, 94, 50],代表了公式的結(jié)構(gòu)和變量。
對于圖像數(shù)據(jù),使用patch方法將圖像分解為小塊,提高對高密度像素數(shù)據(jù)的處理效率。
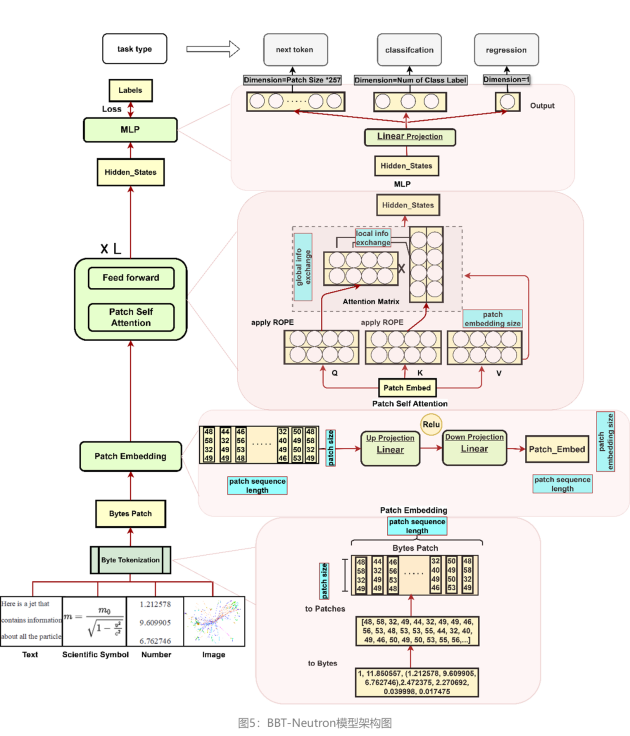
BBT-Neutron模型架構(gòu):高效捕獲數(shù)值關(guān)系與多功能任務(wù)適配
BBT-Neutron模型架構(gòu)主要由三個關(guān)鍵部分組成:Patch Embedding、Patch Self-Attention和LM Head,能夠?qū)⑤斎胄蛄型ㄟ^字節(jié)分詞轉(zhuǎn)換為高維向量,使其具備了包括執(zhí)行分類、回歸任務(wù)在內(nèi)的多種能力。這些任務(wù)在許多科學應(yīng)用中非常常見,目標不一定是生成新序列,也可以是對輸入分類或預測連續(xù)值。
Patch Embedding
包含兩個線性層,第一層將輸入patch投影到高維空間,第二層細化這一表示,產(chǎn)生最終的嵌入向量。
兩層之間引入ReLU激活函數(shù),使模型能夠非線性地表達輸入字節(jié)patch,捕捉patch內(nèi)部byte之間更復雜的結(jié)構(gòu)。與通常只使用單一層線性嵌入的字節(jié)級模型相比,能夠提供更大的靈活性,更好地表示輸入patch的細節(jié)和非線性關(guān)系。
Patch Self-Attention
在patch自注意力機制中,注意力操作在patch層面執(zhí)行,每個patch嵌入包含其所有點的信息,通過矩陣乘法促進不同patch之間的信息交換,同時促進單個patch內(nèi)部字節(jié)之間的交互,使模型能夠有效捕捉局部和全局依賴。
LM Head
輸出維度定義為Patch Size × 257,其中257代表從0到255的字節(jié)值總數(shù),加上由256表示的填充ID,Patch Size是文本序列被劃分的patch數(shù)量。這種設(shè)計允許模型獨立地為每個patch生成預測,保持基于patch方法的效率和有效性。
應(yīng)用于粒子物理對撞數(shù)據(jù)分析:通用架構(gòu)性能達到專業(yè)領(lǐng)域的SOTA
開發(fā)團隊在論文中分享了BBT-Neutron通用架構(gòu)的首次落地實驗結(jié)果,輔助粒子物理學中的關(guān)鍵任務(wù)——噴注來源識別(Jet Origin Identification, JoI),并已取得了突破性成果。
噴注來源識別是高能物理實驗中的核心挑戰(zhàn)之一,旨在區(qū)分來自不同夸克或膠子的噴注。在高能碰撞中產(chǎn)生的夸克或膠子會立即產(chǎn)生一束粒子——主要是強子——朝同一方向運動。這束粒子通常被稱為噴注,是碰撞實驗中物理測量的關(guān)鍵對象。識別噴注的起源對于許多物理分析至關(guān)重要,尤其是在研究希格斯玻色子、W和Z玻色子時,這些玻色子幾乎70%會直接衰變?yōu)閮蓚€噴注。此外,噴注是我們理解量子色動力學(QCD,描述原子核、質(zhì)子、中子、夸克的相互作用機制)的基礎(chǔ)。來自不同類型色荷粒子的噴注在它們的可觀測量上只有微小的差異,這使得準確識別噴注的起源極具挑戰(zhàn)性。
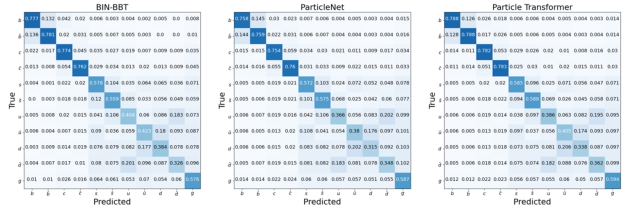
實驗結(jié)果顯示,該研究與最先進的專業(yè)模型(如Particle Transformer和ParticleNet,將專業(yè)物理定律融入GNN架構(gòu)設(shè)計)的最佳性能持平,達到行業(yè)的SOTA(圖1-3)。這個結(jié)果驗證了以sequence to sequence建模方式為基礎(chǔ)的decoder only通用架構(gòu),在學習物質(zhì)世界和物理規(guī)律上具備與專業(yè)模型同等的學習能力。而傳統(tǒng)的觀念認為,seq2seq 建模不適用于時間、空間、能量等具有連續(xù)性特征的物理實在建模,只適合于人類語言這樣的離散符號的建模。而且從左到右具有位置特性的學習方式,不適用于具有時空對稱性的物理結(jié)構(gòu),要讓模型學習專業(yè)物理定律,需要在專業(yè)模型架構(gòu)中融入該領(lǐng)域相關(guān)結(jié)構(gòu)。該論文研究的成果證明了這種觀念的局限性,為表征時間、空間、能量等基礎(chǔ)的物理量提供了一種有效方案,同時也為物理化學等專業(yè)科學領(lǐng)域構(gòu)建一個統(tǒng)一模型提供了基礎(chǔ)。
Scaling分析:發(fā)現(xiàn)涌現(xiàn)行為
文中通過與ParticleNet和Particle Transformer在JoI任務(wù)上的擴展行為的方式進行對比,在數(shù)據(jù)規(guī)模增加下的Scaling行為進行了深入分析。這些訓練數(shù)據(jù)集從100到1000萬事件不等,實驗結(jié)果通過混淆矩陣(confusion matrix)、噴注風味標記效率(jet flavor tagging efficiency)和電荷翻轉(zhuǎn)率(charge flip rate)這三個關(guān)鍵指標來衡量模型的表現(xiàn)。
混淆矩陣(Confusion Matrix)即使用了一個11維的混淆矩陣M11來分類每個噴注,根據(jù)最高預測分數(shù)歸類到相應(yīng)的類別, 塊對角化成2×2的塊,每個塊對應(yīng)特定的夸克種類。混淆矩陣提供了模型分類性能的全面概覽,突出顯示了在各種噴注類別中正確和錯誤預測的情況。
噴注味標記效率(Jet Flavor Tagging Efficiency)定義為每個塊內(nèi)值的總和的一半,不區(qū)分由夸克和反夸克產(chǎn)生的噴注。
電荷翻轉(zhuǎn)率(Charge Flip Rate)定義為塊中非對角線元素與塊總和的比率,代表誤識別夸克和反夸克產(chǎn)生的噴注的概率。
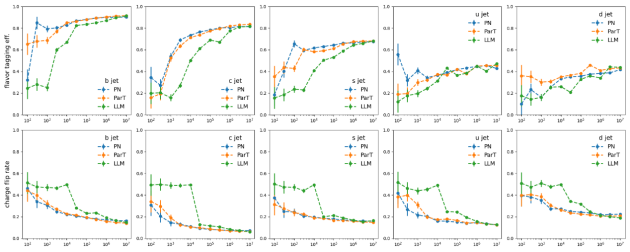
圖4顯示,這些模型在十一種類的粒子噴注來源鑒別的分類問題上表現(xiàn)出相似的性能,并且在數(shù)據(jù)集大小擴展時都顯示出性能提升,Jet Flavor Tagging Efficiency, Charge Flip Rate形成了S曲線。
開發(fā)團隊指出,該模型和專業(yè)模型之間出現(xiàn)了不同的擴展行為。BBT-Neutron的S曲線上的關(guān)鍵數(shù)據(jù)閾值,特別是Charge Flip Rate的數(shù)據(jù)發(fā)生到了性能突變,表現(xiàn)出顯著的涌現(xiàn)現(xiàn)象(Model Emergence),然而該現(xiàn)象在ParticleNet或Particle Transformer中并沒有被觀察到。
可能的原因是這些專業(yè)模型納入了特定領(lǐng)域的結(jié)構(gòu)特征,它們采用專門設(shè)計的架構(gòu)來表示粒子相互作用和分類,這可能導致隨著數(shù)據(jù)規(guī)模的增加,性能提升更快達到飽和。與此相反,研究中的通用架構(gòu)模型,使用統(tǒng)一的數(shù)據(jù)表示來處理所有物理結(jié)構(gòu)。專業(yè)模型架構(gòu)通過消除位置編碼或相關(guān)操作來實現(xiàn)粒子的置換不變性(permutative invariance),BBT-Neutron不依賴置換不變性,而是采用從左到右的序列輸入,這與語言模型的seq2seq范式一致。雖然這種方法需要更大的數(shù)據(jù)集來推斷,但一旦超過臨界數(shù)據(jù)集閾值,它就能實現(xiàn)顯著的性能飛躍,這表明了該模型即使沒有像專業(yè)模型那樣明確在架構(gòu)設(shè)計中納入置換不變性,也能夠通過足量數(shù)據(jù)的學習學到空間對稱性。
通俗而言,當數(shù)據(jù)規(guī)模逐步增加時,該模型在性能上出現(xiàn)了顯著躍遷。這一發(fā)現(xiàn)驗證了通用模型在大規(guī)模科學計算任務(wù)中的可擴展性,即該模型有望成為跨領(lǐng)域的科學計算基座模型。
該論文研究標志著大模型在多模態(tài)數(shù)據(jù)處理與科學計算任務(wù)中的巨大潛力。隨著人工智能技術(shù)與大科學裝置的深度融合,在未來或許能夠加速中國大對撞機CEPC等前沿科研項目的實施落地。該項目參與者、CEPC團隊成員阮曼奇曾評論道,“人工智能技術(shù)將助力大科學設(shè)施的設(shè)計研發(fā),能大幅提高其科學發(fā)現(xiàn)能力,更好地幫助我們探索世界的奧秘、拓寬人類的知識邊界。反過來,通過總結(jié)對比在具體科學問題上觀測到的AI性能差異,也能加深我們對AI技術(shù)本身的理解,更好推動AI技術(shù)的發(fā)展。”
目前BBT-Neutron科學計算基座模型已經(jīng)落地到粒子物理、核聚變、強磁場、石油化工、儲能、鈣鈦礦太陽能、飛行傳感器、基因編輯等真實科研工程難題。
關(guān)于超對稱技術(shù)
超越對稱(上海)技術(shù)有限公司位于上海市徐匯區(qū)漕河涇開發(fā)區(qū)內(nèi),專注于研發(fā)跨學科、跨結(jié)構(gòu)、跨尺度的科學基座大模型 BigBangTransformer[乾元],賦能科學計算、工業(yè)智能、空間智能、醫(yī)療健康等領(lǐng)域,致力于通過大模型技術(shù)攻克物理世界的復雜難題,推動人類邁進“Type II 文明“。
BBT模型發(fā)展歷程
BBT模型歷經(jīng)三代迭代,持續(xù)探索大模型的科學應(yīng)用路徑:
2022年:發(fā)布BBT-1,10億參數(shù)的金融預訓練語言模型;
2023年:推出BBT-2,120億參數(shù)的通用大語言模型;
2024年:發(fā)布BBT-Neutron,1.4億參數(shù)的科學基座大語言模型,實現(xiàn)文本、數(shù)值和圖像數(shù)據(jù)的多模態(tài)統(tǒng)一預訓練
審核編輯 黃宇
-
開源
+關(guān)注
關(guān)注
3文章
4203瀏覽量
46122 -
數(shù)據(jù)處理
+關(guān)注
關(guān)注
0文章
648瀏覽量
29985 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1516瀏覽量
36208 -
大模型
+關(guān)注
關(guān)注
2文章
3648瀏覽量
5179
發(fā)布評論請先 登錄
地平線正式開源HoloBrain VLA基座模型

大科學裝置信號采集處理解決方案
經(jīng)營數(shù)據(jù)分析可以通過哪些方式
提升PLC數(shù)據(jù)采集效率:性能瓶頸分析與實踐

中科曙光推出科學大模型一站式開發(fā)平臺OneScience
利用 Banana Pi BPI-CM5 Pro(ARMSoM CM5 SoM) 加速保護科學
革新科研智造,引領(lǐng)材料未來——高通量智能科研制備工作站
【產(chǎn)品介紹】Altair RapidMiner數(shù)據(jù)分析與人工智能平臺

【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的科學應(yīng)用
中國科學院自動化研究所攜手中科曙光打造高性能工具鏈解決方案
NVIDIA AI助力科學研究領(lǐng)域持續(xù)突破
開源科學計算與系統(tǒng)建模分論壇即將召開
AI數(shù)據(jù)分析儀設(shè)計原理圖:RapidIO信號接入 平板AI數(shù)據(jù)分析儀
NVIDIA驅(qū)動的現(xiàn)代超級計算機如何突破速度極限并推動科學發(fā)展
TDengine 發(fā)布時序數(shù)據(jù)分析 AI 智能體 TDgpt,核心代碼開源



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論